上一篇博客介绍了style gan 原理,但是 style gan 的结果会有水珠伪影,作者实验后发现是 Adain 导致的,AdaIN对每一个feature map的通道进行归一化,这样可能破坏掉feature之间的信息。当然实验证明发现,去除AdaIN的归一化操作后,水珠就消失了。因此 style gan2 中主要优化改善了这个问题。
Adain计算公式如下:
![]()
网络结构如下图所示。
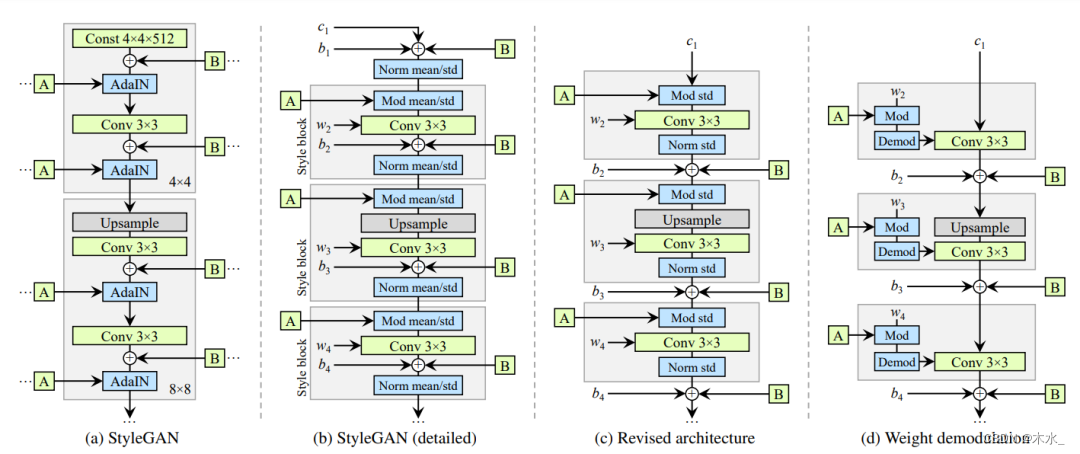
- 图a是原始的 styleGAN1 的结构图;
- 图b是 styleGAN1 的细节图,把 AdaIN 拆分成了 Norm mean/std 和 Mod mean/std 两部分,Norm 是做的归一化操作,而 Mod 则是从 latent code 计算 shift 和 scal e参数的步骤。
- 图c,现在我们修改一下模型,我们去除对于 mean 的 norm 和 mod 的操作,只留下对方差的操作。
- 图d则是在c的基础上,进一步提出了 weight demodulation 的操作。
那为什么要 weight demodulation呢?因为文中作者指出 style modulation 可能会放大某些特征的影像,所以 style mixing 的话,我们必须明确的消除这种影像,否则后续层的特征无法有效的控制图像。如果他们想要牺牲 scale-specific 的控制能力,他们可以简单的移除 normalization,就可以去除掉水滴伪影,这还可以使得FID有着微弱的提高。现在他们提出了一个更好的替代品,移除伪影的同时,保留完全的可控性。这个就是 weight demodulation。
modulation 可以影响着卷积层的输入特征图。所以,其实 Mod 和卷积是可以继续融合的。比方说,input先被Mod放大了3倍,然后在进行卷积,这个等价于input直接被放大了3倍的卷积核进行卷积。Modulation和卷积都是在通道维度进行操作。所以有如下公式(隐层码w仿射变换为s,而后乘在卷积核参数w上):
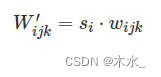
接下来的norm部分也做了修改:
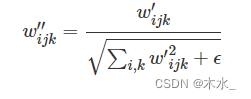
这里替换了对特征图做归一化,而是去卷积的参数做了一个归一化,先前有研究提出,这样会有助于GAN的训练。
至此,我们发现,Mod和norm部分的操作,其实都可以融合到卷积核上。
style gan2 的其他优化点以后再说。