1 集合框架
1.1 Collection
1.1.1 集合框架概述
Java 集合框架是一组实现了常见数据结构(如列表、树集和哈希表等)的类和接口,用于存储一组数据。
开发者在使用Java的集合类时,不必考虑数据结构和算法的具体实现细节,根据场景需要直接选择并使用这些集合类,调用相应的方法即可,从而提高开发效率。
例如,开发者可以创建一个基于数组结构的集合对象,然后调用该对象的add方法向集合中添加元素,或者调用该对象的get方法从集合中获取某个已添加的元素。

Java的集合中存储的都是引用类型的元素,由于引用类型变量实际上存储的是对象的“地址”,集合中实际上只存储了元素对象在堆中的地址,而并不是将对象本身存入了集合中。

Java所有的集合类都位于java.util包中,按照存储结构可以分为两大类,即单列集合和双列集合。单列集合是指集合中的元素是单个对象,双列集合是指集合中的元素以键值对(key-value pair)的形式存在。Collection是单列集合的根接口,Map是双列集合的根接口,各自还派生出一些子接口或实现类。
1.1.2 Collection集合体系
Collection集合体系的架构图如下图所示:

Collection接口有3个子接口:
- List接口:有序且可以重复的集合
- Set接口:无序且不可重复的集合
- Queue接口:队列集合,用来存储满足FIFO(First In First Out)原则的容器
有序和无序:指集合中的元素是否能保存元素的添加顺序。例如,将3个整型元素5、3、9添加到集合中,List集合能够保证按照5、3、9的顺序访问元素,而Set集合无法保证能按这一顺序访问。
是否可重复:指集合中是否允许有重复的元素,重复元素指的并非是同一个元素,而是指equals方法比较为true的元素。
1.1.3 Collection接口的主要方法
在Collection中定义了单列集合的一些通用方法,使用这些方法可以操作所有的单列集合。

1.1.4 【案例】add方法示例
编写代码,测试Collection的add方法。代码示意如下:
import java.util.ArrayList;
import java.util.Collection;
public class CollectionDemo1 {public static void main(String[] args) {Collection c = new ArrayList();System.out.println(c); // []c.add("张亚峰");c.add("刘苍松");c.add(666);System.out.println(c); // [张亚峰, 刘苍松, 666]}
}1.1.5 contains方法
contains() 方法用于判断给定的元素是否被包含在集合中。语法如下:
boolean contains(Object o)若包含则返回true,否则返回false。
这里需要注意的是,集合在判断元素是否被包含在集合中是根据每个元素的equals() 方法进行比较后的结果。因此,通常有必要重写 equals() 保证 contains() 方法返回合理的结果。
1.1.6 【案例】contains方法示例
编写代码,测试Collection的contains方法。代码示意如下:
import java.util.ArrayList;
import java.util.Collection;
public class CollectionDemo2 {public static void main(String[] args) {Collection c = new ArrayList();c.add(new String("hello"));// List集合contains方法和对象的equals方法相关boolean flag = c.contains("hello");System.out.println("flag: " + flag); // flag: trueSystem.out.println("flag: " + c.contains("hell")); // flag: false}
}1.1.7 size、clear、isEmpty方法
Collection集合还有3个常用的方法:
- int size():该方法用于返回当前集合中的元素总数
- void clear():该方法用于清空当前集合
- boolean isEmpty():该方法用于判断当前集合中是否不包含任何元素
1.1.8 【案例】size、clear、isEmpty方法示例
编写代码,测试Collection的size、clear和isEmpty方法。代码示意如下:
import java.util.ArrayList;
import java.util.Collection;
public class CollectionDemo3 {public static void main(String[] args) {Collection c = new ArrayList();System.out.println(c.isEmpty()); // truec.add("java");c.add("c++");c.add("php");c.add("c#");c.add("python");// isEmpty:false, size: 5System.out.println("isEmpty:" + c.isEmpty() + ",size: " + c.size());// 清空集合c.clear();// isEmpty:true, size: 0System.out.println("isEmpty:" + c.isEmpty() + ", size: " + c.size());}
}1.1.9 addAll与containsAll 方法
如果需要将一个集合加入另一个集合,可以使用 addAll() 方法:
boolean addAll(Collection<? extends E> c)该方法需要传入一个集合,并将该集合中的所有元素添加到当前集合中。如果此 collection 由于调用而发生更改,则返回 true。
如果希望判断当前集合是否包含给定集合中的所有元素,可以使用containsAll() 方法:
boolean containsAll(Collection<?> c)若包含则返回 true。
1.1.10 【案例】addAll与containsAll方法示例
编写代码,测试Collection的addAll和containsAll方法。代码示意如下:
import java.util.ArrayList;
import java.util.Collection;
public class CollectionDemo4 {public static void main(String[] args) {Collection passedStudentList = new ArrayList(); // 考试通过的学生名单passedStudentList.add("Alice");passedStudentList.add("Bob");passedStudentList.add("Lucy");passedStudentList.add("Lily");Collection groupAList = new ArrayList<>(); // A组学生名单groupAList.add("Bob");groupAList.add("Tony");// A组学生是否都通过了考试boolean passed = passedStudentList.containsAll(groupAList);if (passed) {System.out.println("A组全部通过了考试!");} else {System.out.println("A组没有全部通过了考试!");}// B组学生名单Collection groupBList = new ArrayList<>(); groupBList.add("Tom");groupBList.add("Jerry");// 将B组学生名单添加到考试通过的学生名单中passedStudentList.addAll(groupBList);}
} 1.2 Iterator迭代器
1.2.1 迭代器概述
迭代器(Iterator)接口是Java集合框架中的一员,诞生于JDK 1.2版本,主要用于迭代访问(即遍历)Collection中的元素,因此,Iterator对象也被称为迭代器。
获取迭代器的方式是使用Collection定义的iterator方法:

迭代器Iterator是一个接口,集合在覆盖Collection的iterator()方法时提供了迭代器的具体实现。
1.2.2 迭代器接口的主要方法
迭代器(Iterator)接口中定义了4个方法。
最常用的方法为:
- hasNext:用于判断当前迭代中是否有更多元素
- next:返回当前迭代中的下一个元素
- remove:从集合中移除最近一次调用next方法时返回的那个元素,与next方法搭配使用
三个方法的操作示意如下图所示:
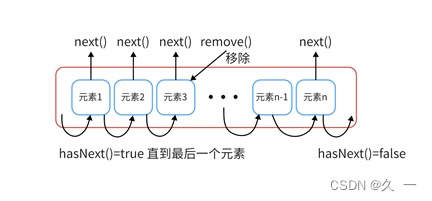
注意:
- 遍历过程中不能直接通过Collection的 remove() 方法删除集合元素,否则会抛出并发更改异常
- 在调用 迭代器的remove() 方法前必须通过迭代器的 next() 方法迭代过元素,那么删除的就是这个元素
- 调用一次next()方法后只能调用一次remove()方法
1.2.3 【案例】Iterator示例
编写代码,测试Iterator的hasNext、next和remove方法。代码示意如下:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class IteratorDemo1 {public static void main(String[] args) {Collection c = new ArrayList();// 向集合中添加1到10for (int i = 1; i <= 10; i++){c.add(i);}System.out.println(c);// 获取集合的迭代器对象Iterator itr = c.iterator();// 通过迭代器遍历集合while (itr.hasNext()) {int i = (int)itr.next();System.out.print(i + " ");// 通过迭代器删除集合中的元素if (i % 2 != 0){itr.remove();}}System.out.println();// 输出集合中的元素System.out.println(c);}
}1.2.4 增强for循环
增强for循环是Java 1.5之后推出了一个新的特性,用于简化集合的遍历操作。语法如下:
for(元素类型 e : 集合或数组){循环体
}增强for循环会按照从头到尾的顺序逐个访问集合或数组中的元素,变量e的值与集合或数组中当前访问的元素的值相同。例如,使用增强for循环访问一个包含了“a”,“b”“c”三个元素的集合,第一次循环时,e的值为“a”,第二次循环时,e的值为“b”,以此类推。
增强for循环并非新的语法,而是在编译过程中,编译器会将增强for循环转换为迭代器模式。所以增强for循环本质上是迭代器。
1.2.5 【案例】增强for循环示例
编写代码,测试增强的for循环的使用。代码示意如下:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class IteratorDemo2 {public static void main(String[] args) {Collection c = new ArrayList();// 向集合中添加1到10for (int i = 1; i <= 10; i++){c.add(i);}// 使用增强for循环遍历集合中的元素for(Object o : c){System.out.print(o +" ");}System.out.println();// 也可用于遍历数组String[] array = {"Tom", "Bob", "Jerry"};for(String s: array){System.out.println(s);}}
}1.3 泛型机制
1.3.1 泛型概述
泛型(Generic)是Java从JDK 1.5开始引入的,可以帮助用户建立类型安全的集合。泛型的本质就是“数据类型的参数化”。可以把泛型理解为数据类型的一个占位符(形式参数),即在编写代码时将数据类型定义成参数,这些类型参数在使用或调用时传入具体的类型。
在JDK 1.5之前,为了实现参数类型的任意化,都是通过Object类型来处理的。但这种处理方式的缺点是需要进行强制类型转换,这种强制类型转换不仅使代码臃肿,还要求开发者必须在已知实际使用的参数类型的情况下才能进行,否则容易引起ClassCastException异常。
使用泛型的好处是在程序编译期间会对类型进行检查,捕捉类型不匹配错误,以免引起ClassCastException异常;在使用了泛型的集合中,遍历时不必进行强制类型转换,数据类型都是自动转换的。

泛型也经常在类、接口和方法的定义中使用,这部分内容将在后续的课程中进行讲解。
1.3.2 【案例】泛型示例
编写代码,测试泛型的使用。代码示意如下:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class GenericDemo1 {public static void main(String[] args) {// 使用泛型指定集合中元素为Integer类型Collection<Integer> c = new ArrayList<>();c.add(123);// c.add("abc"); // 编译时报错,类型不匹配Iterator<Integer> itr = c.iterator();while (itr.hasNext()) {// 无需类型转换int i = itr.next();System.out.print(i + " ");}}
} 2 List集合
2.1 List接口
2.1.1 List接口概述
List接口继承自Collection接口,是单列集合的一个重要分支;将实现了List接口的对象称为List集合。List接口的特点可简单总结为“有序可重复”。
List接口不但继承了Collection接口中的全部方法,而且增加了一些操作集合的特有方法:

2.2 ArrayList
2.2.1 ArrayList概述
ArrayList是List接口的一个实现类,是程序中最常见的一种集合。在ArrayList内部封装了一个长度可变的数组对象,当存入的元素超过数组长度时,ArrayList会在内存空间中创建一个更大的数组来存储这些元素。

ArrayList的主要特点如下:
1、动态大小:ArrayList的大小是可以动态增长和缩小的。与普通的数组相比,ArrayList不需要指定初始大小,并且可以根据需要自动调整容量。
2、随机访问:ArrayList通过索引来访问集合中的元素。由于ArrayList使用了数组实现,因此可以通过索引以常量时间复杂度(O(1))来获取元素。这使得ArrayList非常适合需要频繁随机访问元素的场景。
3、允许重复元素:ArrayList可以包含重复的元素。这意味着可以多次添加相同的元素到ArrayList中。
4、支持动态修改:ArrayList提供了一系列方法来修改集合中的元素,如添加、删除、插入和替换等操作。通过这些方法,可以方便地对集合进行修改。
5、迭代和遍历:ArrayList实现了Iterable接口,因此可以使用迭代器(Iterator)或者增强型for循环来遍历集合中的元素。
2.2.2 ArrayList常用方法
除了从Collection接口间接继承的方法外,ArrayList中还包含以下常用方法。
1、void add(int index, E element):将给定的元素插入到指定位置,原位置及后续元素都顺序向后移动。

2、E remove(int index):删除给定位置的元素,并将被删除的元素返回。

3、E get(int index):获取集合中指定下标对应的元素,下标从0开始。
4、E set(int index, E element):将给定的元素存入给定位置,并将原位置的元素返回。
2.2.3 【案例】ArrayList方法示例
编写代码,测试ArrayList的使用。代码示意如下:
import java.util.ArrayList;
import java.util.List;
public class ArrayListDemo1 {public static void main(String[] args) {// 使用泛型ArrayList集合ArrayList<String> mylist = new ArrayList<>();// 向集合中添加3个元素mylist.add("one");mylist.add("two");mylist.add("three");System.out.println("此列表元素包括:"+mylist);System.out.println("------");// E get(int i) 返回集合中指定下标的元素String s = mylist.get(2);System.out.println("索引号为2的元素是:"+s);System.out.println("------");// E set(int index,E e)将给定位置的元素替换成// 新元素,并返回被替换的元素String old = mylist.set(2, "3");System.out.println("被替换的元素:"+old);System.out.println("此列表元素包括:"+mylist);System.out.println("------");// void add(int index,E e)向指定位置插入元素mylist.add(1,"2");System.out.println(mylist);System.out.println("------");// E remove(int index)删除并返回指定位置的元素// 删除索引号为1的元素old = mylist.remove(1);System.out.println(old);System.out.println(mylist);System.out.println("------");// List取子集List subList(int start,int end)// 包括0号元素,不包括2号元素List<String> subList = mylist.subList(0, 2);System.out.println("子集元素包括:"+subList);System.out.println("------");// 使用foreach语句遍历for (String e: mylist){System.out.print(e+' ');}}
}2.2.4 【案例】ArrayList应用示例
案例背景:
1、在本地D:/data文件夹中存放了两个csv文件,分别是subject.csv文件和exam.csv文件,分别存储科目信息和考试信息,文件内容如下图所示。

案例需求:
1、创建Subject类,用于封装科目信息。创建Exam类,用于封装考试信息。两个类的属性设计如下所示。
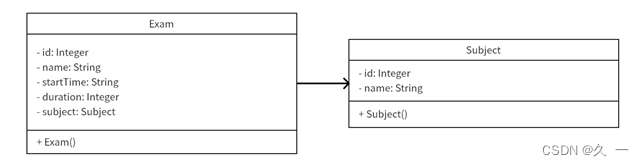
2、使用IO流读取subject.csv文件,解析其中的数据,每行数据封装成一个Subject对象,存储到ArrayList<Subject>集合subjectList中。
3、使用IO流读取exam.csv文件,解析其中的数据,每行数据封装成一个Exam对象,存储到ArrayList<Exam>集合examList中。在Exam对象中需要根据subject_id列的值,关联对应的Subject对象。
4、从examList中筛选出考试时间在10点之后的数据,将考试信息输出到控制台。
输出结果如下图所示。

import java.io.BufferedReader;
import java.io.FileReader;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.*;
public class ArrayListDemo2 {public static void main(String[] args) {String subjectPath = "d:/data/subject.csv";String examPath = "d:/data/exam.csv";ArrayList<Subject> subjects = readSubjects(subjectPath);System.out.println(subjects); // 打印科目信息ArrayList<Exam> exams = readExams(examPath, subjects);System.out.println(exams); // 打印考试信息// 筛选出考试时间在10点之后的考试信息DateTimeFormatter formatter =DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");for (Exam exam : exams) {LocalDateTime ldt = LocalDateTime.parse(exam.getStartTime(),formatter);if (ldt.getHour()>9){System.out.println(exam);}}}/*** 读取文件中的数据,每行生成一个考试对象,存储到集合中* @param path* @param subjects* @return*/public static ArrayList<Exam> readExams(String path, ArrayList<Subject> subjects) {List<String> lines = readLines(path);ArrayList<Exam> exams = new ArrayList<>();for (String line : lines) {String[] arr = line.split(",");Exam exam = new Exam();exam.setId(Integer.parseInt(arr[0]));exam.setName(arr[1]);exam.setStartTime(arr[2]);exam.setDuration(Integer.parseInt(arr[3]));// 遍历科目数据,获取科目对象for (Subject subject : subjects) {if (subject.getId() .equals(Integer.parseInt(arr[4]))) {exam.setSubject(subject);break;}}exams.add(exam);}return exams;}/*** 读取文件中的数据,每行生成一个科目对象,存储到集合中* @param path* @return*/public static ArrayList<Subject> readSubjects(String path){List<String> lines = readLines(path);ArrayList<Subject> subjects = new ArrayList<>();for(String line : lines){String[] arr = line.split(",");Subject subject = new Subject();subject.setId(Integer.parseInt(arr[0]));subject.setName(arr[1]);subjects.add(subject);}return subjects;}/*** 读取文件中的数据,每行生成一个字符串,存储到集合中* @param path* @return*/public static ArrayList<String> readLines(String path){ArrayList<String> lines = new ArrayList<>();try(FileReader fr = new FileReader(path);BufferedReader br = new BufferedReader(fr);){String line = br.readLine();line = br.readLine(); // 跳过第一行while(line != null){lines.add(line);line = br.readLine();}}catch (Exception e){e.printStackTrace();}return lines;}
}2.2.5 ArrayList的扩容机制
ArrayList的扩容机制是指在容量不足以容纳新元素时,自动增加ArrayList的容量,即ArrayList使用的内部数组的长度,以便能够容纳更多的元素。
ArrayList类中定义了一个变量elementData,代表实际存储数据的数组。ArrayList的容量,指的就是这个数组的容量。

1、初始容量
ArrayList中的初始容量分为2种情况:未指定初始长度和手动指定初始长度。
首先来看未指定初始长度的情况。
ArrayList类中定义了一个空的Object类型数组,如下所示。

在创建ArrayList对象时,如果没有指定初始容量,ArrayList会使用该数组作为内部数组,此时内部数组的长度为0。

当第一次向该ArrayList对象中添加一个元素时,ArrayList会先初始化一个默认长度的内部数组,再将元素添加到该数组中。这个默认长度由ArrayList中的一个静态常量指定,如下所示。

因此,ArrayList的初始容量为0,在添加第一个元素时动态扩容为10。
接下来,我们来看手动指定初始长度的情况。
手动指定初始长度是指通过ArrayList的带参构造器ArrayList(int initialCapacity)来创建ArrayList对象。此时,ArrayList会使用传入的值作为新建的内部数组的长度,源码入下图所示。

因此,如果手动指定了长度,ArrayList的初始容量即为指定的长度。
2、容量增长
当添加元素导致ArrayList的大小超过当前容量时,ArrayList会自动进行容量增长。容量增长的策略是通过创建一个新的更大容量的数组,并将原有元素复制到新数组中。
当需要增加容量时,ArrayList会根据一定的增量大小(通常为当前容量的一半)计算新的容量。
新容量的计算公式为:newCapacity = oldCapacity + (oldCapacity >> 1)。
例如,一个已经添加了10个元素的ArrayList,在添加第11个元素时,容量会扩容到10 + (10 >>1) =15。
3、复制元素
在进行容量增长时,ArrayList会创建一个新的数组,并将原有的元素复制到新数组中。
![]()
复制元素的操作可能会导致一定的性能开销,特别是在ArrayList中存储大量元素时。例如,向ArrayList中依次添加128个元素,会导致ArrayList进行7次动态扩容。
因此,集合操作的一项重要的最佳实践是:当事先知道要存储的总元素数量时,应使用ArrayList的带参构造器来创建ArrayList,以减少动态扩容带来的性能开销。
2.2.6 ArrayList的缩容操作
与自动扩容机制不同,ArrayList并不会在删除元素时进行自动缩容操作。但是ArrayList提供了trimToSize方法,用于手动实现缩容的效果。
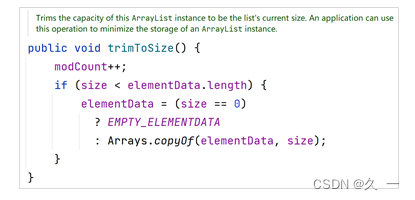
2.2.7 ArrayList与数组的区别
这是一道常见的面试题,可以从以下几个方面回答。
1、大小的固定性:数组一旦创建,大小是固定的,无法改变;ArrayList的大小是可变的,可以根据需要动态增长或缩小。
2、对象类型和原始类型:数组可以存储对象类型和原始类型的值,例如,int[]可以存储整数,String[]可以存储字符串;ArrayList只能存储对象类型,不能直接存储原始类型,需要使用对应的包装类。
3、功能和灵活性:数组的功能相对有限,仅提供了基本的操作,如访问和赋值;ArrayList提供了丰富的方法来插入、删除、替换和访问元素。
2.2.8 ArrayList与数组的转换
1、集合转为数组
使用 toArray() 方法将集合转换为数组,有两种形式:
- Object[] toArray()
- <T>T[] toArray(T[] a)
其中,第二种比较常用:可以传入一个指定类型的数组,该数组的元素类型应与集合的元素类型一致,返回值则是转换后的数组,该数组会保存集合中所有的元素。
2、数组转为集合
Arrays类的静态方法 asList() 可以将一个数组转换为对应的 List 集合:
static <T>List<T> asList<T… a>返回的 List 的集合元素类型由传入的数组的元素类型决定。
注意:对于返回的集合,不能对其增删元素,否则会抛出异常;并且对集合的元素进行修改会影响数组对应的元素。
2.2.9 【案例】ArrayList与数组的转换示例
请使用AI工具生成一个测试,并在开发工具中测试该示例,练习ArrayList和数组之间的转换。
2.3 LinkedList
2.3.1 LinkedList概述
LinkedList是另一个常用的List接口实现类,内部维护了一个双向链表。
LinkedList在常用API方面与ArrayList非常相似,只是在性能上有一定的差别,学习LinkedList的重点是掌握它内部的数据结构以及这种结构带来的优点和缺点。
LinkedList集合中的每个数据节点中都有两个指针,分别指向前一个节点和后一个节点。如下图所示:
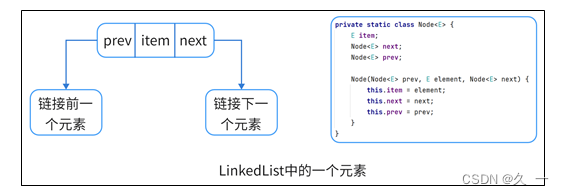
集合中有多个元素之间的关系如下图所示:

当插入一个新元素时,只需要修改元素之间的这种引用关系,删除一个节点也是如此。如下图所示:

由图可以看出:LinkedList集合对于元素的增、删操作快捷方便。但是LinkedList集合不支持随机取值,每次都只能从一端或双向链表中的某节点开始遍历,直到找到查询的对象再返回,由于无法保存上一次的查询位置,因此实现查询操作的效率低下。
2.3.2 LinkedList的特点
LinkedList的主要特点如下:
1、链表结构:LinkedList使用双向链表的数据结构来存储和操作元素。
2、动态大小:LinkedList不需要指定初始大小,并且可以根据需要自动调整容量。
3、高效的插入和删除操作:由于LinkedList使用链表结构,插入和删除元素的性能相对较好。
4、不支持随机访问: LinkedList不支持通过索引直接访问元素,需要从头节点或尾节点开始遍历链表。
5、遍历操作:LinkedList实现了Iterable接口,因此可以使用迭代器(Iterator)或者增强型for循环来遍历链表中的元素。
2.3.3 【案例】LinkedList与ArrayList比较示例
编写代码,测试LinkedList与ArrayList两种集合,在头部插入、中部插入和尾部插入时的效率。代码示意如下:
import java.util.ArrayList;
import java.util.LinkedList;
public class ListPerformanceComparison {public static void main(String[] args) {int iterations = 100000; // 迭代次数// 测试ArrayListArrayList<Integer> arrayList = new ArrayList<>();long arrayListStartTime = System.currentTimeMillis(); // 开始时间for (int i = 0; i < iterations; i++) {arrayList.add(0, i); // 头部插入}long arrayListEndTime = System.currentTimeMillis(); // 结束时间long arrayListDuration = arrayListEndTime - arrayListStartTime; // 执行时间// 测试LinkedListLinkedList<Integer> linkedList = new LinkedList<>();long linkedListStartTime = System.currentTimeMillis(); // 开始时间for (int i = 0; i < iterations; i++) {linkedList.addFirst(i); // 头部插入}long linkedListEndTime = System.currentTimeMillis(); // 结束时间long linkedListDuration = linkedListEndTime - linkedListStartTime; // 执行时间System.out.println("ArrayList 头部插入耗时: " + arrayListDuration + " 毫秒");System.out.println("LinkedList 头部插入耗时: " + linkedListDuration + " 毫秒");// 清空列表arrayList.clear();linkedList.clear();// 测试ArrayListarrayListStartTime = System.currentTimeMillis(); // 开始时间for (int i = 0; i < iterations; i++) {arrayList.add(i / 2, i); // 中部插入}arrayListEndTime = System.currentTimeMillis(); // 结束时间arrayListDuration = arrayListEndTime - arrayListStartTime; // 执行时间// 测试LinkedListlinkedListStartTime = System.currentTimeMillis(); // 开始时间for (int i = 0; i < iterations; i++) {int index = linkedList.size() / 2;linkedList.add(index, i); // 中部插入}linkedListEndTime = System.currentTimeMillis(); // 结束时间linkedListDuration = linkedListEndTime - linkedListStartTime; // 执行时间System.out.println("ArrayList 中部插入耗时: " + arrayListDuration + " 毫秒");System.out.println("LinkedList 中部插入耗时: " + linkedListDuration + " 毫秒");// 清空列表arrayList.clear();linkedList.clear();// 测试ArrayListarrayListStartTime = System.currentTimeMillis(); // 开始时间for (int i = 0; i < iterations; i++) {arrayList.add(i); // 尾部插入}arrayListEndTime = System.currentTimeMillis(); // 结束时间arrayListDuration = arrayListEndTime - arrayListStartTime; // 执行时间// 测试LinkedListlinkedListStartTime = System.currentTimeMillis(); // 开始时间for (int i = 0; i < iterations; i++) {linkedList.add(i); // 尾部插入}linkedListEndTime = System.currentTimeMillis(); // 结束时间linkedListDuration = linkedListEndTime - linkedListStartTime; // 执行时间System.out.println("ArrayList 尾部插入耗时: " + arrayListDuration + " 毫秒");System.out.println("LinkedList 尾部插入耗时: " + linkedListDuration + " 毫秒");}
}2.3.4 ArrayList和LinkedList的区别
ArrayList和LinkedList都是List接口的实现类,用于存储单列数据。ArrayList和LinkedList在数据结构、随机访问性能、插入和删除操作性能等方面有所区别。
首先,ArrayList底层基于数组存储数据,可以看成是一个大小可变的数组。LinkedList底层基于双向链表存储数据。
ArrayList支持使用下标(索引)随机访问集合中的元素,随机访问的性能较好。LinkedList不能根据下标直接访问元素,需要从头部或尾部开始遍历链表,随机访问性能较差。
ArrayList在尾部进行插入和删除的性能较好,但在中间或头部进行插入和删除操作时,需要移动其他元素,性能较差。LinkedList在头尾进行插入和删除的性能较好。
注意:以上的对比都是在数据量很大或者操作很频繁的情况下的对比,如果数据和运算量很小,上述对比将失去意义。