目录
一、Servlet概述
演示
创建JavaWeb项目(2017版本为例)
1. 打开 IntelliJ IDEA
2. 选择项目类型
3. 配置框架
二、Servlet初识(熟练)
1.servlet说明
2.Servlet 接口方法
3.创建Servlet
4.JavaWeb请求响应流程
编辑
编辑
5.servlet生命周期
Servlet 基础
Servlet 接口方法
Servlet 生命周期
Servlet 实例管理
Tomcat 的角色
总结
三、HttpServlet(精通)
1.HttpServlet介绍
2.Http请求方法
3.创建HttpServlet
第一种:创建一个类继承HttpServlet
第二种:IDEA直接创建servlet
4.servlet创建顺序
总结
一、Servlet概述
JavaWeb 三大组件:Servlet、Filter(过滤器)、Listener(监听器)。
其中Servlet是JavaWeb三大组件之一,它是我们学习JavaWeb最为基本的组件,必须100%掌握。
Servlet 作用:处理用户请求。客户端请求由 Tomcat 找到对应的 Servlet 来处理,例如登录请求由登录 Servlet 处理。

【基本流程:JavaWeb项目部署在Tomcat,Tomcat启动就会立即加载web.xml,每写一个Servlet,就会在web.xml里面配置一个servlet】
接下来用idea创建JavaWeb项目来演示一下:
演示
创建JavaWeb项目(2017版本为例)
1. 打开 IntelliJ IDEA
启动 IntelliJ IDEA 2017,并选择 “Create New Project” 来创建一个新的项目。
2. 选择项目类型
在创建项目时,选择 “Java Enterprise” 模板。这是用于创建 Java Web 项目的模板。
在左侧栏中选择 “Java Enterprise”。
在右侧的选项中,确保选中 “Web Application” 功能模块(即勾选 “Web Application”)。

3. 配置框架
普通JavaWeb项目架构:
MyJavaWebProject/
├── src/ # Java 源代码
├── web/ # Web 资源
│ ├── WEB-INF/ # Web 应用配置
│ │ └── web.xml # 部署描述符
│ └── index.jsp # 默认页面
└── lib/ # 依赖的 JAR 文件所以是需要我们手动去配置WEB-INF目录和web.xml文件:

这里web.xml里面的约束也需要我们手动添加(由于web.xml里面的约束都是一样的,所以我们可以去直接复制任意其他项目里web.xml里的约束来用)
在这里提供了3.1版本的约束:
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaeehttp://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"version="3.1">
</web-app>部署tomcat:

如果以前没有设置过的话请参见这篇博客中的步骤:部署JavaWeb项目(Ⅱ)-CSDN博客
运行项目:
项目会先加载web.xml文件,然后显示的下面结果是默认存在的index.jsp(由于没做任何编写处理,所以这里显示的是初始的界面内容。)

题外话 :
因为2017版本的idea版本较低,所以像maven这种架构的项目里面的基础目录并不会自动生成,需要手动添加。
如下是maven的架构:
MyJavaWebProject/ ├── src/ │ ├── main/ │ │ ├── java/ # 存放 Java 源代码 │ │ ├── resources/ # 存放资源文件(如配置文件) │ │ └── webapp/ # 存放 Web 资源(如 JSP、HTML、CSS) │ │ ├── WEB-INF/ # Web 应用配置 │ │ │ └── web.xml │ │ └── index.jsp └── lib/ # 存放依赖的 JAR 文件配置项目结构
在 IntelliJ IDEA 中,需要手动配置这些目录的用途:
打开项目结构设置
点击 “File” > “Project Structure”(快捷键:
Ctrl + Alt + Shift + S)。在 “Project Settings” 中,选择 “Modules”。
配置目录用途
在 “Sources” 标签页中:
将
src/main/java标记为 “Sources”(蓝色)。将
src/main/resources标记为 “Resources”。将
src/main/webapp标记为 “Resources”。
如果没有
src/main/webapp目录,可以手动创建:
右键点击
src/main,选择 “New” > “Directory/Package”,并命名为webapp。然后在 “Project Structure” 中将其标记为 “Resources”。
当然,上面是maven架构的手动配置情况,而我们在此演示的JavaWeb用不到这么多。

二、Servlet初识(熟练)
1.servlet说明
定义:Servlet 是运行在 Web 服务器(如 Tomcat)中的小型 Java 程序,用于处理通过 HTTP 协议接收到的客户端请求。
实现:Servlet 需要实现 javax.servlet.Servlet 接口,并在 web.xml 文件中进行部署,以便 Web 服务器能够识别和调用。
2.Servlet 接口方法
javax.servlet.Servlet 接口定义了以下五个方法,用于控制 Servlet 的生命周期和请求处理:
| 方法签名 | 描述 | 调用时机 |
|---|---|---|
void init(ServletConfig config) | 初始化 Servlet 实例。用于执行 Servlet 的初始化工作。 | Servlet 实例被创建后立即调用一次。 |
void service(ServletRequest req, ServletResponse res) | 处理客户端请求。负责接收请求和返回响应。 | 每次处理请求时调用。 |
void destroy() | 销毁 Servlet 实例。用于释放资源和执行清理工作。 | Servlet 实例被销毁前调用一次。 |
ServletConfig getServletConfig() | 获取 Servlet 配置信息。返回一个 ServletConfig 对象。 | 需要时调用,通常在 init() 方法中保存。 |
String getServletInfo() | 获取 Servlet 信息。返回一个描述 Servlet 的字符串。 | 需要时调用,通常用于获取 Servlet 描述。 |
引申问题:什么是初始化?
一个“一开始就要干的事”,e.g 进游戏前的登录 e.g 去自习室时开灯(不管是谁都要先完成的动作),那么就将这个方法编写进初始化里面,即一调用这个类,初始化里的方法就会完成。
3.创建Servlet
第一步:常见HelloServlet实现Servlet的接口,实现接口中的方法;
package cn.tx.servlet;import javax.servlet.*;
import java.io.IOException;public class Servlet1 implements Servlet { //实现servlet接口@Overridepublic void init(ServletConfig servletConfig) throws ServletException {}@Overridepublic ServletConfig getServletConfig() {return null;}@Overridepublic void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {}@Overridepublic String getServletInfo() {return null;}@Overridepublic void destroy() {}
}第二步:配置servlet的访问路径;
在约束里面编写:
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"version="3.1"><servlet><servlet-name>hello</servlet-name><servlet-class>cn.tx.servlet.Servlet1</servlet-class></servlet><servlet-mapping><servlet-name>hello</servlet-name><url-pattern>/hello</url-pattern></servlet-mapping>
</web-app>4.JavaWeb请求响应流程

接着:

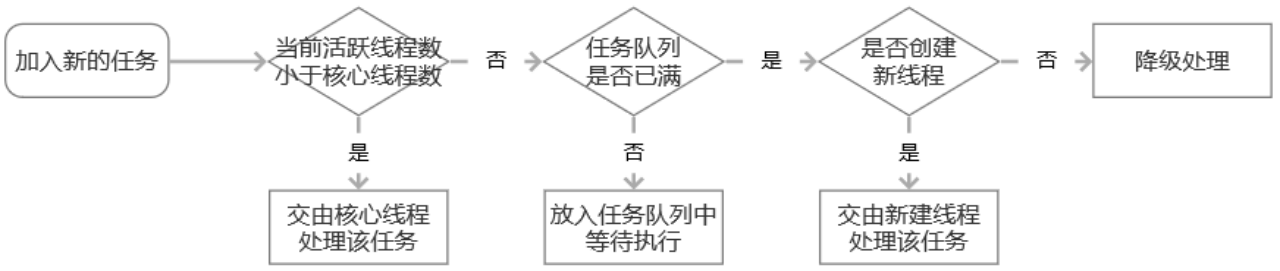
当 Tomcat 接收到请求(如 http://localhost:8080/servlet_pro/logon),它会查找项目中的 web.xml 文件,通过请求路径(如 /logon)匹配 <url-pattern> 来定位相应的 Servlet。
Tomcat 找到匹配的 <servlet-mapping>,确定 <servlet-name>(如 login)。
根据 <servlet-name>,在 <servlet> 配置中找到对应的 <servlet-class>(如 com.rl.servlet.LoginServlet)。
接下来:
如果 Servlet 实例已存在,Tomcat 直接使用它处理请求。
如果不存在,Tomcat 通过反射创建实例,并将其存入 Servlet 池中,然后调用 service() 方法处理请求。
5.servlet生命周期
Servlet 基础
-
定义:Servlet是服务器端的Java程序,用于处理HTTP请求和生成响应。
-
接口:必须实现
javax.servlet.Servlet接口。 -
部署:需要在
web.xml文件中配置,以便Tomcat等服务器识别和调用。
Servlet 接口方法
Servlet接口包含以下三个核心方法,定义了Servlet的生命周期:
-
init(ServletConfig config)-
作用:初始化Servlet。
-
生命周期:在Servlet实例创建后调用一次。
-
-
service(ServletRequest request, ServletResponse response)-
作用:处理客户端请求。
-
生命周期:每次请求时调用。
-
-
destroy()-
作用:销毁Servlet实例。
-
生命周期:在Servlet实例销毁前调用一次。
-
Servlet 生命周期
Servlet的生命周期由以下三个阶段组成:
-
初始化阶段:调用
init()方法进行初始化。 -
请求处理阶段:调用
service()方法处理客户端请求。 -
销毁阶段:调用
destroy()方法进行销毁。
Servlet 实例管理
-
实例创建:默认情况下,Servlet实例在第一次被请求时由Tomcat创建。
-
实例销毁:当Tomcat决定不再需要Servlet实例时(如服务器关闭或重新部署应用),会销毁实例。
Tomcat 的角色
Tomcat作为Servlet容器,负责以下任务:
-
创建、调用和销毁Servlet实例。
-
调用Servlet的生命周期方法(
init()、service()、destroy())。 -
管理Servlet的生命周期和请求处理。
总结
Servlet的生命周期由Tomcat管理,开发者通过实现javax.servlet.Servlet接口中的方法来控制Servlet的行为。开发者需要关注的主要方法是init()、service()和destroy(),这些方法在Servlet的生命周期中由Tomcat自动调用。开发者需要在web.xml中配置Servlet,以便Tomcat能够识别和调用。
三、HttpServlet(精通)
1.HttpServlet介绍
因为现在我们的请求都是基于HTTP协议的,所以我们应该专门为HTTP请求写一个Servlet做为通用父类。

由上图我们可以看出,以后再写Servlet 可以直接继承HttpServlet
- Servlet 一个标准
- GenericServlet 是Servlet接口子类
- HttpServlet 是GenericServlet子类,一个专门处理Http请求的Servlet
2.Http请求方法
| 方法 | 描述 |
|---|---|
| GET | 通过请求的 URI 获取资源。 |
| POST | 向服务器提交新内容,通常用于创建新资源。 |
| PUT | 修改指定的资源。 |
| DELETE | 删除指定的资源。 |
| CONNECT | 用于代理服务器进行 SSL 传输(如建立 SSL 隧道)。 |
| OPTIONS | 询问服务器关于目标资源的通信选项。 |
| PATCH | 对资源进行部分修改。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| HEAD | 类似于 GET 请求,但不返回响应主体内容,用于获取元数据。 |
3.创建HttpServlet
第一种:创建一个类继承HttpServlet
package cn.tx.servlet;import javax.servlet.http.HttpServlet;public class Servlet2 extends HttpServlet{}配置Servlet映射路径:
<servlet><servlet-name>hello2</servlet-name><servlet-class>cn.tx.servlet.Servlet2</servlet-class>
</servlet><servlet-mapping><servlet-name>hello2</servlet-name><url-pattern>/hello2</url-pattern>
</servlet-mapping>第二种:IDEA直接创建servlet

填写servlet名称:

创建完成,自己填写映射路径

4.servlet创建顺序
有些Servlet需要在Tomcat启动时就被创建,而不是第一次访问时被创建,那么可以在web.xml文件中配置<servlet>元素。
在<servlet>元素中添加子元素<load-on-startup>元素!
<servlet><servlet-name>hello</servlet-name><servlet-class>cn.tx.servlet.Servlet1</servlet-class><load-on-startup>1</load-on-startup>
</servlet>
总结
-
加载顺序:Servlet 的加载顺序由
<load-on-startup>元素的值决定,值越小,越早加载。 -
应用启动加载:所有指定了
<load-on-startup>的 Servlet 将在 Web 应用启动时被加载,而不是在第一次请求时。 -
日志验证:可以通过在
init()方法中添加日志输出来验证 Servlet 的加载顺序。