之——GRU
目录
之——GRU
杂谈
正文
1.重置门和更新门
2.候选隐藏状态
3.新的隐状态
长短期记忆网络LSTM
1.候选记忆单元
2.记忆单元
3.隐状态
杂谈
关注一个序列,不是每个观察都同等重要,传统RNN会一直在Whh中隐含所有以前的信息,包括了很多不必要的信息。
门控神经网络就是设计一定的控制单元,使得模型只关注相关需要的,忘记不相关的。
正文
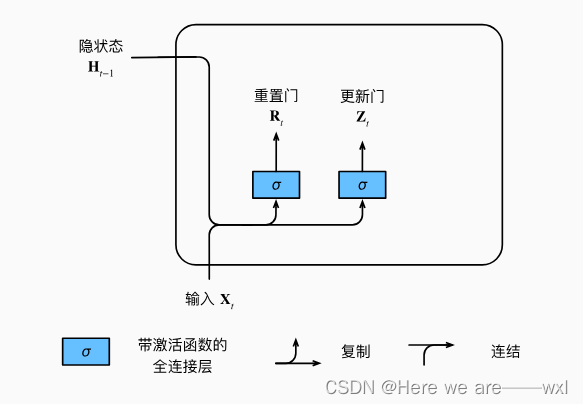
1.重置门和更新门
输入是由当前时间步的输入和前一时间步的隐状态给出。 两个门的输出是由使用sigmoid激活函数的两个全连接层给出。
公式:

门有自己的权重,同时接受隐变量的输出。 门的输出是被激活函数控制在0~1的范围空间的。
2.候选隐藏状态
使用重置门构建候选隐藏状态:

具体公式:
这一操作可以削减Ht-1的状态影响,因为Rt是0~1的,也就是一定程度上削减以往状态的影响。
3.新的隐状态
然后使用更新门更新隐状态:
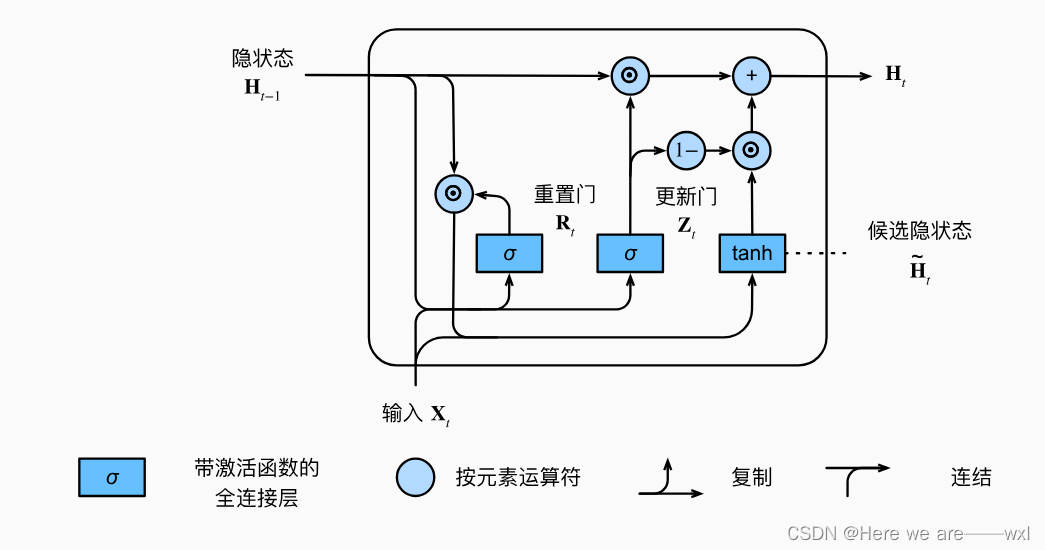
具体计算为:

这一操作进一步决定了更新的依据权重。
长短期记忆网络LSTM
LSTM其实是门控的前身,但为啥要这样设计也不是很明白,和上述的GRU很像,稍微多一点东西,要实现的效果是一样的,就是通过现在与过去的权衡来完成更长时间的迭代学习。
和门控类似,但这里设置了三个门:

就是三个连接方式,通过MLP的形式让他们自己去学习权重:

1.候选记忆单元
除了以上三个门以外,还有一个候选记忆单元的设计,没有用到其他gait:

2.记忆单元
记忆单元结合了上一个时间的记忆单元和遗忘门的交互,以及这个时间的候选记忆单元和输入门的交互,所以记忆单元会不断地接受以前和现在做一个信息储存和更新。
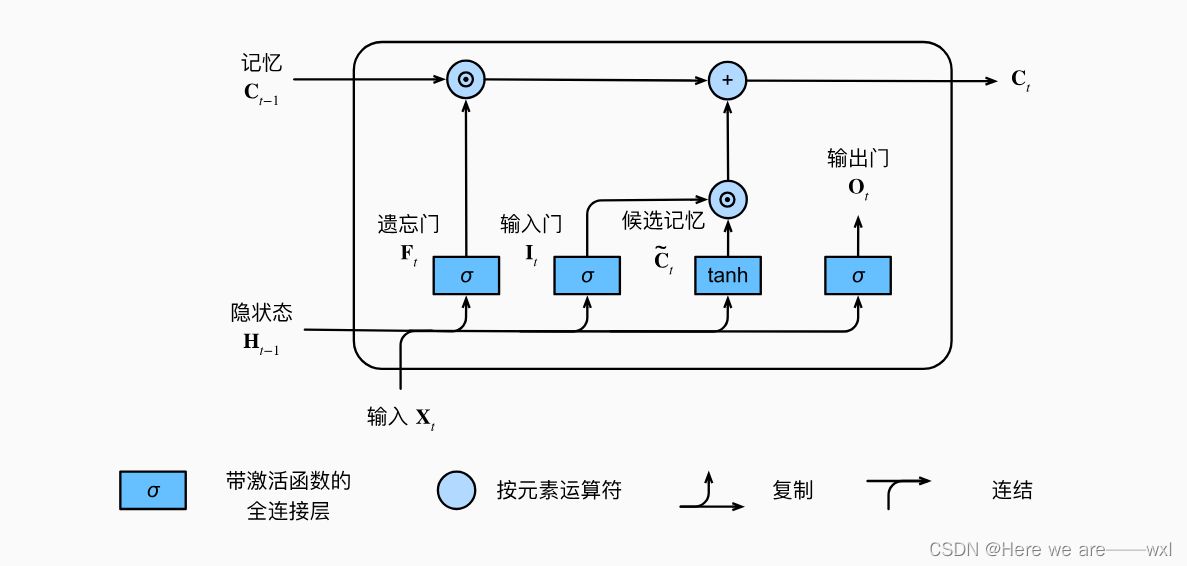
注意这里面的激活函数是为了控制数值范围。
3.隐状态
输出门会和记忆单元交互得到新的隐状态。

总结
长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)都是用于解决循环神经网络(Recurrent Neural Network,RNN)中长序列依赖性问题的变体。它们在处理序列数据时相较于传统的RNN模型表现更好,因为它们能够更有效地捕捉和利用序列中的长期依赖关系。
以下是LSTM和GRU的主要特点和区别:
长短期记忆网络(LSTM):
结构: LSTM引入了三个门(输入门、遗忘门和输出门)以及一个记忆单元来处理长期依赖关系。
门控机制:
- 输入门(Input Gate): 控制有多少新信息可以流入记忆单元。
- 遗忘门(Forget Gate): 控制有多少过去的记忆可以被遗忘。
- 输出门(Output Gate): 决定记忆单元的输出。
记忆单元: LSTM包含一个记忆单元,它可以保存和提取信息,并通过时间步骤传递信息。
应用: 由于其较复杂的结构,LSTM常常在需要处理长期依赖性的任务中表现良好,如机器翻译、语音识别等。
门控循环单元(GRU):
结构: GRU相对于LSTM结构更为简单,只包含两个门(更新门和重置门)。
门控机制:
- 更新门(Update Gate): 控制有多少过去的记忆被保留。
- 重置门(Reset Gate): 决定多少过去的信息应该被忽略。
记忆单元: GRU没有显式的记忆单元,而是直接传递隐藏状态作为记忆。
应用: GRU在一些轻量级的序列建模任务中表现良好,同时也因其简单的结构而更容易训练。
共同点:
门控机制: LSTMs和GRUs都引入了门控机制,以便网络可以自适应地决定在每个时间步骤中保留或丢弃信息。
应对梯度消失问题: 两者都设计得更好地应对了RNN中常见的梯度消失问题,使得它们更适合处理长序列。
选择使用LSTM还是GRU通常取决于任务的性质和规模。在某些情况下,LSTM可能由于其更强大的建模能力而更为适用,而在其他情况下,GRU的简单性和较小的参数量可能更有优势。










![HLS 2017.4 导出 RTL 报错:ERROR: [IMPL 213-28] Failed to generate IP.](https://img-blog.csdnimg.cn/direct/dd34ed34b085400ca264f79a55f172e7.png)