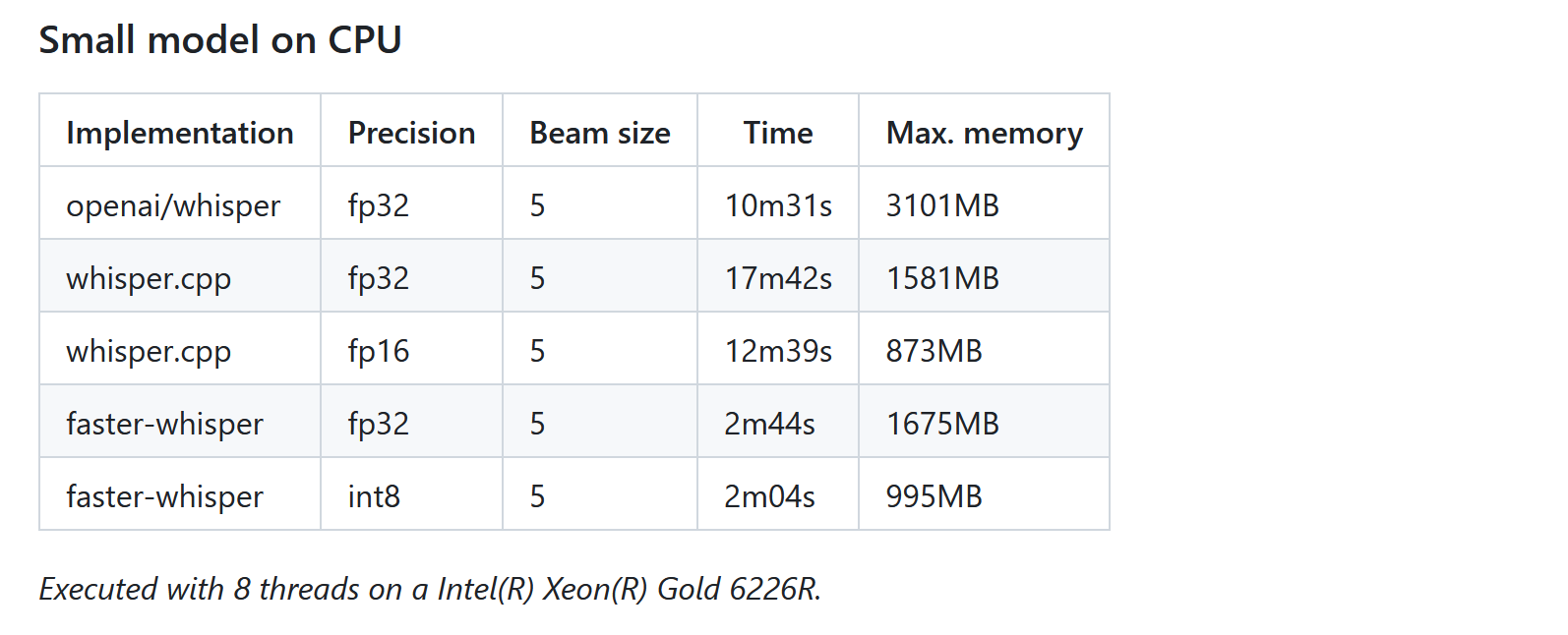
先放一张ViT的网络图
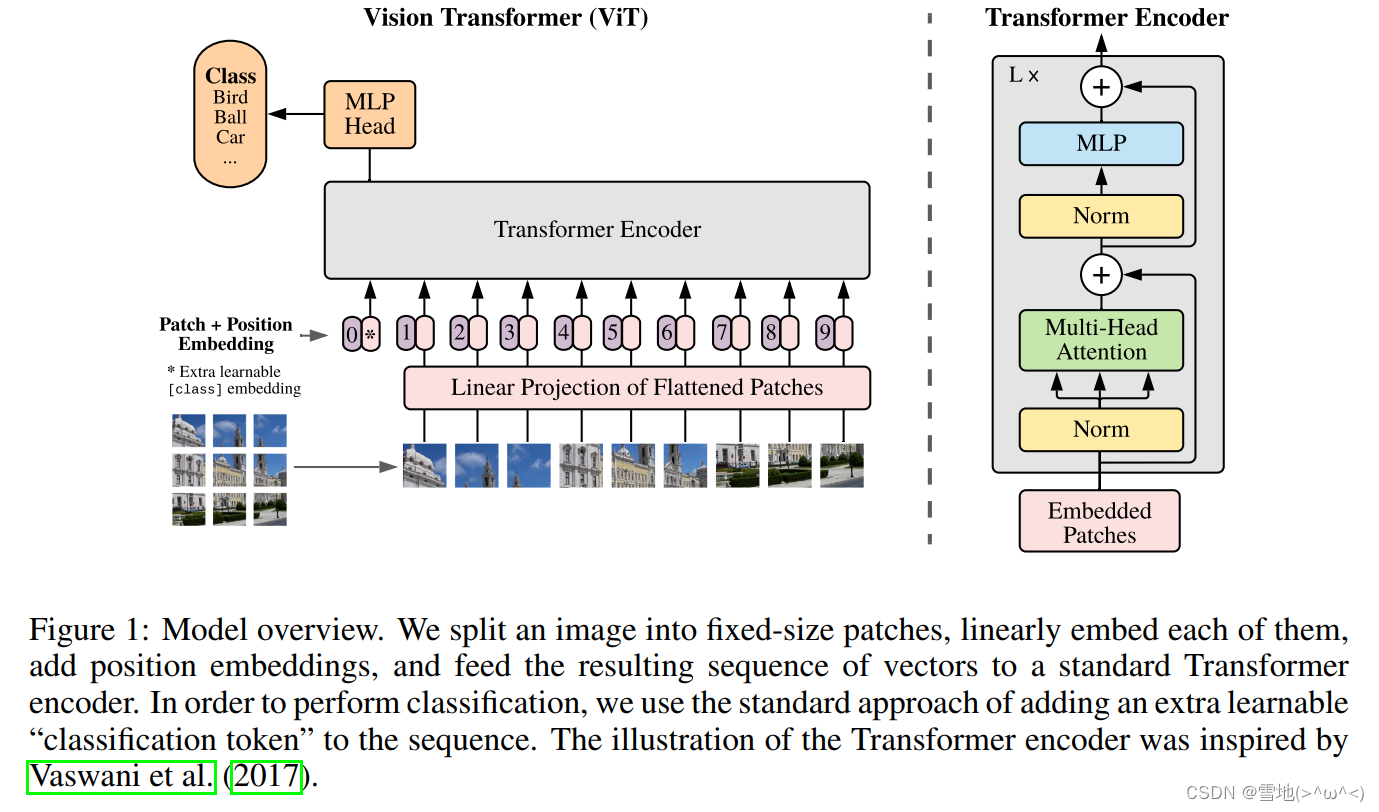
可以看到是把图像分割成小块,像NLP的句子那样按顺序进入transformer,经过MLP后,输出类别。每个小块是16x16,进入Linear Projection of Flattened Patches, 在每个的开头加上cls token和位置信息,也就是position embedding。
去掉数据读取部分,直接上一个极简的ViT代码:
import torch
from torch import nnfrom einops import rearrange, repeat
from einops.layers.torch import Rearrange# helpersdef pair(t):return t if isinstance(t, tuple) else (t, t)# classesclass PreNorm(nn.Module):def __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout = 0.):super().__init__()self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)class Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.attend = nn.Softmax(dim = -1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):qkv = self.to_qkv(x).chunk(3, dim = -1)## 对tensor张量分块 x :1 197 1024 qkv 最后是一个元祖,tuple,长度是3,每个元素形状:1 197 1024q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scaleattn = self.attend(dots)out = torch.matmul(attn, v)out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn xclass ViT(nn.Module):def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):super().__init__()image_height, image_width = pair(image_size) # 224*224patch_height, patch_width = pair(patch_size) # 16 * 16assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'num_patches = (image_height // patch_height) * (image_width // patch_width)patch_dim = channels * patch_height * patch_widthassert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'self.to_patch_embedding = nn.Sequential(# (b,3,224,224) -> (b,196,768) 14*14=196 16*16*3=768Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),nn.Linear(patch_dim, dim), # (b,196,1024))self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))self.cls_token = nn.Parameter(torch.randn(1, 1, dim))self.dropout = nn.Dropout(emb_dropout)self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)self.pool = poolself.to_latent = nn.Identity()self.mlp_head = nn.Sequential(nn.LayerNorm(dim),nn.Linear(dim, num_classes))def forward(self, img):x = self.to_patch_embedding(img) # img 1 3 224 224 输出形状x : 1 196 1024b, n, _ = x.shape # 1 196cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b) # (1,1,1024)x = torch.cat((cls_tokens, x), dim=1) # (1,197,1024)x += self.pos_embedding[:, :(n + 1)] # (1,197,1024)x = self.dropout(x) # (1,197,1024)x = self.transformer(x) # (1,197,1024)x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0] # (1,1024)x = self.to_latent(x) # (1,1024)return self.mlp_head(x) # (1,1000)if __name__ == '__main__':v = ViT(image_size = 224,patch_size = 16,num_classes = 1000,dim = 1024,depth = 6,heads = 16,mlp_dim = 2048,dropout = 0.1,emb_dropout = 0.1)img = torch.randn(1, 3, 224, 224)preds = v(img) # (1, 1000)print(preds.shape)
去掉cls和最后的全连接分类头,变成即插即用的模块:
import torch
from torch import nnfrom einops import rearrange
from einops.layers.torch import Rearrange# helpersdef pair(t):return t if isinstance(t, tuple) else (t, t)# classesclass PreNorm(nn.Module):def __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout = 0.):super().__init__()self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)class Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.attend = nn.Softmax(dim = -1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):qkv = self.to_qkv(x).chunk(3, dim = -1)## 对tensor张量分块 x :1 197 1024 qkv 最后是一个元祖,tuple,长度是3,每个元素形状:1 197 1024q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scaleattn = self.attend(dots)out = torch.matmul(attn, v)out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn xclass ViT(nn.Module):def __init__(self, *, image_size, patch_size, dim = 1024, depth = 3, heads = 16, mlp_dim = 2048, dim_head = 64, dropout = 0.1, emb_dropout = 0.1):super().__init__()channels, image_height, image_width = image_size # 256,64,80patch_height, patch_width = pair(patch_size) # 4*4assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'num_patches = (image_height // patch_height) * (image_width // patch_width) # 16*20patch_dim = 64 * patch_height * patch_width # 64*8*10self.conv1 = nn.Conv2d(256, 64, 1)self.to_patch_embedding = nn.Sequential(# (b,64,64,80) -> (b,320,1024) 16*20=320 4*4*64=1024Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),nn.Linear(patch_dim, dim), # (b,320,1024))self.to_img = nn.Sequential(# b c (h p1) (w p2) -> (b,64,64,80) 16*20=320 4*4*64=1024Rearrange('b (h w) (p1 p2 c) -> b c (h p1) (w p2)', \p1 = patch_height, p2 = patch_width, h = image_height // patch_height, w = image_width // patch_width),nn.Conv2d(64, 256, 1), # (b,64,64,80) -> (b,256,64,80))# 位置编码self.pos_embedding = nn.Parameter(torch.randn(1, num_patches, dim))self.dropout = nn.Dropout(emb_dropout)self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)def forward(self, img):x = self.conv1(img) # img 1 256 64 80 -> 1 64 64 80x = self.to_patch_embedding(x) # 1 320 1024b, n, _ = x.shape # 1 320x += self.pos_embedding[:, :(n + 1)] # (1,320,1024)x = self.dropout(x) # (1,320,1024)x = self.transformer(x) # (1,320,1024)x = self.to_img(x)return x # (1 256 64 80)if __name__ == '__main__':v = ViT(image_size = (256,64,80), patch_size = 4)img = torch.randn(1, 256, 64, 80)preds = v(img) # (1, 256, 64, 80)print(preds.shape)