JavaScript:正则表达式
- 什么是正则表达式
- 正则表达式语法
- 定义正则表达式
- 判断是否有匹配的字符串
- 查找匹配的字符串
- 正则表达式匹配法则
- 元字符
- 边界符
- 量词
- 字符类
什么是正则表达式
正则表达式用于匹配字符串中字符的组合模式。
正则表达式会依据其自身语法,来对字符串进行限制,并判断字符串是否满足限制。
就好比在人群中找出一个指定目标,我们可以依据限制条件:黑皮肤,戴眼镜,长发等等来找出符合要求的一个或多个人。而正则表达式就是用于规定限制条件的。
在JavaScript中,正则表达式会被当作一个对象。
正则表达式语法
定义正则表达式
JavaScript提供了两种方法创建正则表达式,在此我只讲解使用多的那种:
语法:
let/var/const 变量名 = /正则表达式/
赋值符号左侧,用关键字定义了一个变量,这个变量最终就是这个正则表达式的对象了。
赋值符号右侧,是两个斜杠引起的内容,在斜杠内部写正则表达式。
示例:
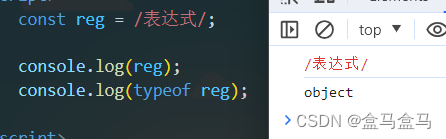
可以看到,虽然直接输出reg没有得到对象,但是其类型确实为object。
想要使用这个正则表达式,要通过这个对象的方法:
判断是否有匹配的字符串
test()方法可以检测一个字符串是否符合正则表达式的规则,其返回值为布尔值。
语法:
Object.test(被检测的字符串)
Object是正则表达式的对象,被检测到的字符串放在函数的参数里。
首先讲解一个基本的正则表达式匹配法则:当正则表达式中只有一个字符串时,只要在被检测的字符串中出现正则表达式中的字符串,就算匹配成功。
案例:
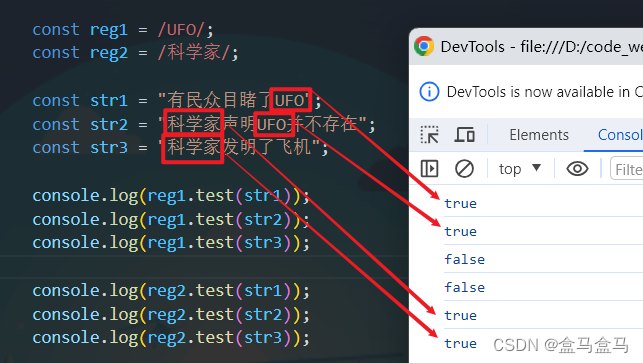
在案例中,创建了两个正则表达式的对象,其中reg1要求语句中出现UFO,而reg2要求语句中出现科学家。
于是在reg1.test()下,含有UFO的字符串输出了true;在reg2.test()下,含有科学家的字符串输出了true。
查找匹配的字符串
exec()方法可以匹配搜索符合正则表达式要求的子字符串的位置和值。
语法:
Object.exec(被检测的字符串)
这个函数的返回值是一个数组,数组内部存储了匹配到的子字符串,匹配到的位置,输入的字符串等信息。
案例:
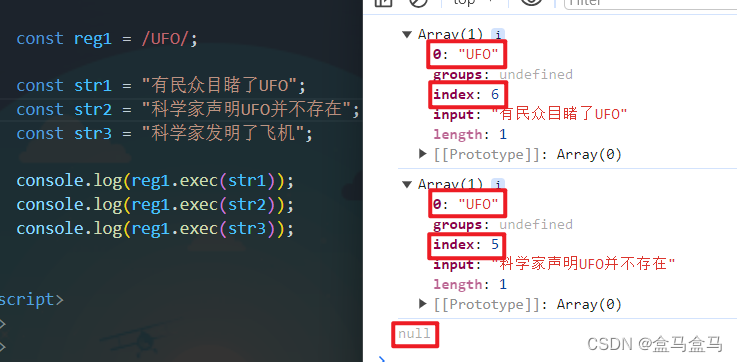
可以看到,当字符串符合要求时,就会返回一个数组,数组中第一个元素就是匹配到的子字符串,而第三个元素则是匹配到的子字符串的起始下标;当字符串不符合要求时,返回值就是空。
以上就是JavaScript中的正则表达式基本使用方法,接下来讲解正则表达式本身的匹配法则:
正则表达式匹配法则
元字符
在正则表达式中,字符被分为普通字符和元字符:
普通字符:这种字符只能描述它们自身,例如所有的字母,数字。
元字符:元字符是一种具有特殊含义的字符,它可以描述一大类字符。
比如:
规定用户只能填入26个英文字母,那么我们就需要在正则表达式中输入abcdefg......xyz,把26个字母全部输入一遍,这就很麻烦了。但是有一个元字符:[a-z]可以表示a-z的所有小写字母,这样就把原先的26个字符压缩成了5个字符,极大提高了书写效率。
元字符有非常多,大致可以分为三类:边界符,量词,字符类。接下来我们一一讲解:
边界符
正则表达式中,边界符用于提示字符所处的位置。
最常用边界符:
| 边界符 | 含义 |
|---|---|
| ^ | 表示匹配行首的文本(以谁开始) |
| $ | 表示匹配行尾的文本(以谁结束) |
案例:

可以看到/^科学家/只匹配以科学家开头的字符串,而/UFO$/只匹配以UFO结尾的字符串。
此外还有一个语法,那就是正则表达式以^开头的同时以$结尾的结构,比如/^abc$/这样的正则表达式,其时什么含义?
这可不是表示既要以abc开头,又要以abc结尾。而是表示精确匹配,即这个字符串只能和abc一模一样才可以匹配。
案例:
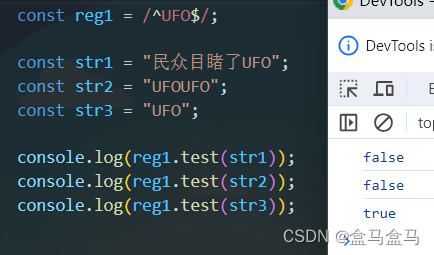
案例中,不论是同时以UFO开头结尾,或者出现了UFO的语句都无法匹配,只有目标字符串就是UFO三个字母时才能匹配。
在实战中,使用的几乎都是精确匹配,到目前为止其看起来只能匹配一种字符串,但是结合后面得到量词和字符类,精确匹配也可以匹配不同类型的字符串。
量词
量词用于设定某个模式出现的次数。
常见量词:
| 量词 | 说明 |
|---|---|
| * | 重复零次或者更多次 |
| + | 重复一次或者更多次 |
| ? | 重复零次或者一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或者更多次 |
| {n,m} | 重复n到m次 |
如果被重复的部分超过了一个字符,需要用括号括起来,否则只重复量词紧挨着的字符。
我们接下来用一个案例看看用法:
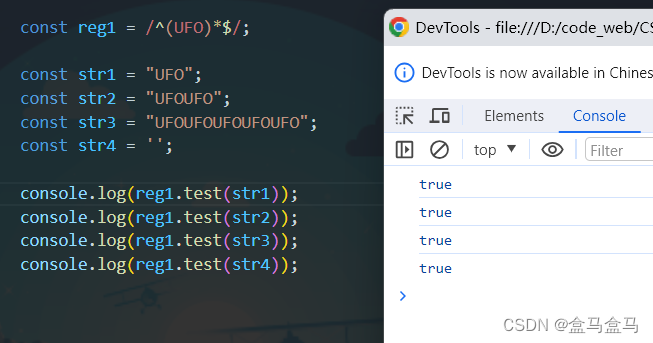
案例中,正则表达式设置为了/^(UFO)*$/即UFO这个整体要重复出现0次或更多次,所以哪怕是一个空字符串,由于UFO出现了0次,依然符合要求。
那么后面的就是一样的规则了,我再讲解一个{n,m}的案例:
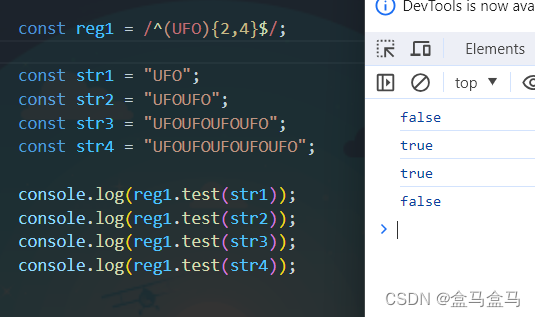
案例中,只有重复次数在[2,4]区间内的字符串才满足匹配要求。
注意:{n,m}之间不允许出现任何空格,必须连着写
在以上案例中,我们使用了精确匹配,精确匹配的要求是,必须完全符合内部表达式,我为大家解释几个正则表达式的含义,为大家加深一下精确匹配的作用:
/^(UFO){2,4}$/,字符串必须是由UFO重复2-4次才可以匹配
/^(UFO){2,4}/,字符串必须由UFO重复2-4次开头,(实际作用是:必须以UFO重复两次及以上开头)
/(UFO){2,4}$/,字符串必须由UFO重复2-4次结尾,(实际作用是:必须以UFO重复两次及以上结尾)
/(UFO){2,4}/,字符串中必须出现2-4个UFO连在一起,(实际作用是:字符串中必须有两个UFO连在一起)
为何后三者的实际作用与语法上看起来不同?
这是因为后三者的匹配规则是,只要目标字符串的子字符串符合要求,那么其就可以和正则表达式匹配。
比如/^(UFO){2,4}/对于这个正则表达式,请问UFOUFOUFOUFOUFO被发现可以匹配吗?
在UFOUFOUFOUFOUFO被发现这个字符串中,是以5个UFO开头的,好像不满足/^(UFO){2,4}/这个表达式,但是其子字符串满足要求。
我们可以将UFOUFOUFOUFOUFO被发现拆分为以下情况:
UFOUFO+UFOUFOUFO被发现,以两个UFO重复开头,满足/^(UFO){2,4}/要求
UFOUFOUFO+UFOUFO被发现,以三个UFO重复开头,满足/^(UFO){2,4}/要求
UFOUFOUFOUFO+UFO被发现,以四个UFO重复开头,满足/^(UFO){2,4}/要求
可以发现,/^/只要求以xxx开头,所以我们可以拆分出很多符合要求的开头,就算有多余的UFO超过了重复次数的限制,那就不把它当作开头。所以最后的效果就是:必须以UFO重复两次及以上开头。
后两者也就是一个意思了。
字符类
[]匹配字符集
匹配字符集可以用于对某个字符进行多样匹配,比如[abc]表示一个字符可以是abc中的任何一个。
案例:
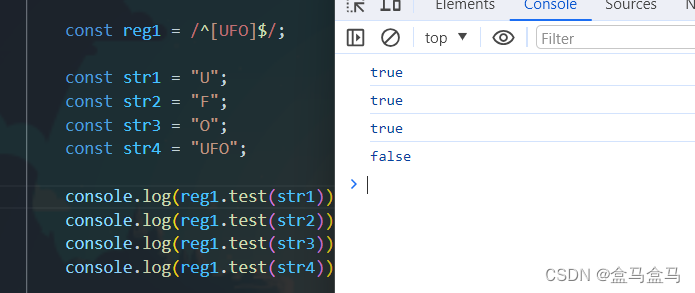
/^[UFO]$/这个正则表达式中,要求一个字符是UFO三者中的任意一个,所以前三个字符串都输出了true。
那为什么第四个UFO却输出了false?
这是因为一个[]只能匹配一个字符,对于/^[UFO]$/这个正则表达式,由于精确匹配的原因,其实际含义为:只能出现一个字符,且这个字符必须是UFO三者之一。
如果想要使用[]匹配字符,那就需要结合前面的量词一起使用。
比如:
/^[UFO]*$/表示一个字符串中,只能有UFO三种字母构成,长度不限;
再来一个稍微复杂点的:
/^[UFO]{2,4}[科学家]?$/
这串正则表达式可以拆分为两个部分:
[UFO]{2,4}以及[科学家]?
[UFO]{2,4}表示必须存在2-4个字符,且这2-4个字符必须由UFO三个字符组合成
[科学家]?表示必须存在0或1个字符,且必须由科学家三个字符组合成
最后这个正则表达式从左往右判断就是:
一开始必须存在2-4个字符,且这2-4个字符必须由UFO三个字符组合成,然后必须存在0或1个字符,且必须由科学家三个字符组合成
我再分析以下下面这个输出结果帮助大家理解:
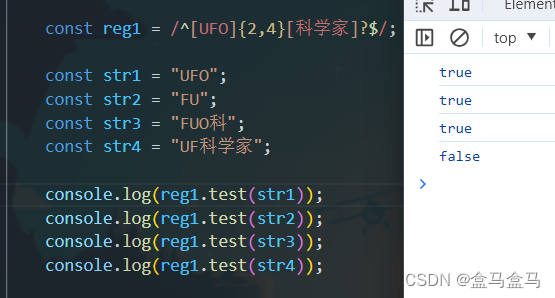
UFO:
一开始存在三个字符,且都是UFO之一,符合[UFO]{2,4}要求;
接着没有字符了,即存在0个字符,符合[科学家]?要求;
F:
一开始存在一个字符,是UFO之一,不符合[UFO]{2,4}的数量要求;
FUO科:
一开始存在三个字符,且都是UFO之一,符合[UFO]{2,4}的数量要求;
接着存在一个字符‘科’,符合[科学家]?要求;
UF科学家:
一开始存在两个字符,且都是UFO之一,符合[UFO]{2,4}要求;
接着存在三个个字符‘科学家’,不符合[科学家]?的数量要求;
可以发现精确表达也可以通过量词的限定,来实现匹配不同长度的字符串。
[-]范围表示匹配字符集
上述匹配字符集[]是以枚举的形式,其实我们也可以给定一个范围,匹配范围内的字符。
常用值:
| 字符类 | 作用 |
|---|---|
| [a-z] | 匹配所有小写的字母 |
| [a-zA-Z] | 匹配所有的大小写字母 |
| [0-9] | 匹配0-9的数字 |
^取反符号
在正则表达式的一开始,我们提到^表示以xxx开始,但是那是在//之间的情况下;
当^在[]之间,表示取反,即:匹配除了xxx以外的字符。
比如:/^[^a-z]$/表示匹配除了a-z以外的所有字符、
.匹配除换行符以外的所有单个字符
如果你在某个字符的位置,不想限制用户的输入,任其自由发挥,你就可以使用 . 这个字符类。
注意:一个 . 只匹配一个字符,如果想让多个字符随意输入,需要加量词。
- 预定义
预定义是指某些常见模式的简写形式。
| 预定类 | 说明 |
|---|---|
| \d | [0-9]的简写形式 |
| \D | [^0-9]的简写形式 |
| \w | [A-Za-z0-9_]的简写形式 |
| \W | [^A-Za-z0-9_]的简写形式 |
| \s | 匹配空格(包括换行符,空格符,制表符等) |
| \S | 匹配非空格 |