0. 简介
作为基于视觉感知的基本任务,3D占据预测重建了周围环境的3D结构。它为自动驾驶规划和导航提供了详细信息。然而,大多数现有方法严重依赖于激光雷达点云来生成占据地面真实性,而这在基于视觉的系统中是不可用的。之前我们介绍了《经典文献阅读之–RenderOcc(使用2D标签训练多视图3D Occupancy模型)》。这里本文《OccNeRF: Self-Supervised Multi-Camera Occupancy Prediction with Neural Radiance Fields》提出了一种名为OccNeRF的方法,用于自监督多相机3D占用预测。该方法通过参数化重建的占用场来表示无限空间,并通过神经渲染将占用场转换为多相机深度图。为了提供几何和语义监督,该方法利用多帧图像之间的光度一致性进行监督。代码可在Github找到。

图1. OccNeRF概述。为了表示无界场景,我们提出了一个参数化坐标,将无限空间压缩到有界的占据场。在不使用任何标注标签的情况下,我们利用时间光度约束和预训练的开放词汇分割模型,提供几何和语义监督。
1. 主要贡献
- 我们使用2D骨干来提取多摄像头的2D特征。为了节省内存,我们直接插值2D特征,以获取3D体积特征,而不是使用繁重的跨视图注意力。
- 我们设计了特定的采样策略,将参数化占用场转换为具有神经渲染的多摄像头深度图。我们利用时间光度损失作为监督信号,这在自监督深度估计方法中常用 [21, 22, 46, 82, 89]。为了更好地利用时间线索,我们执行多帧光度约束
- 对于语义占用,我们提出了三种策略,将类名映射到提示词,这些提示词被馈送到预训练的开放词汇分割模型 [33, 43],以获取2D语义标签。
2. 概述
图2显示了我们方法的流程。利用多摄像头图像 { I i } i = 1 N \{I^i\}^N_{i=1} {Ii}i=1N作为输入,我们首先利用2D主干提取N个摄像头的特征 { X i } i = 1 N \{X^i\}^N_{i=1} {Xi}i=1N。然后,将2D特征插值到3D空间,利用已知的内参 { K i } i = 1 N \{K^i\}^N_{i=1} {Ki}i=1N和外参 { T i } i = 1 N \{T^i\}^N_{i=1} {Ti}i=1N获得体积特征。正如第3节所讨论的,为了表示无界场景,我们提出了坐标参数化方法,将无限范围缩小到有限的占用区域。进行体积渲染,将占用区域转换为多帧深度图,由光度损失进行监督。第4节详细介绍了这一部分。最后,第5节展示了我们如何使用预训练的开放词汇分割模型获取2D语义标签。
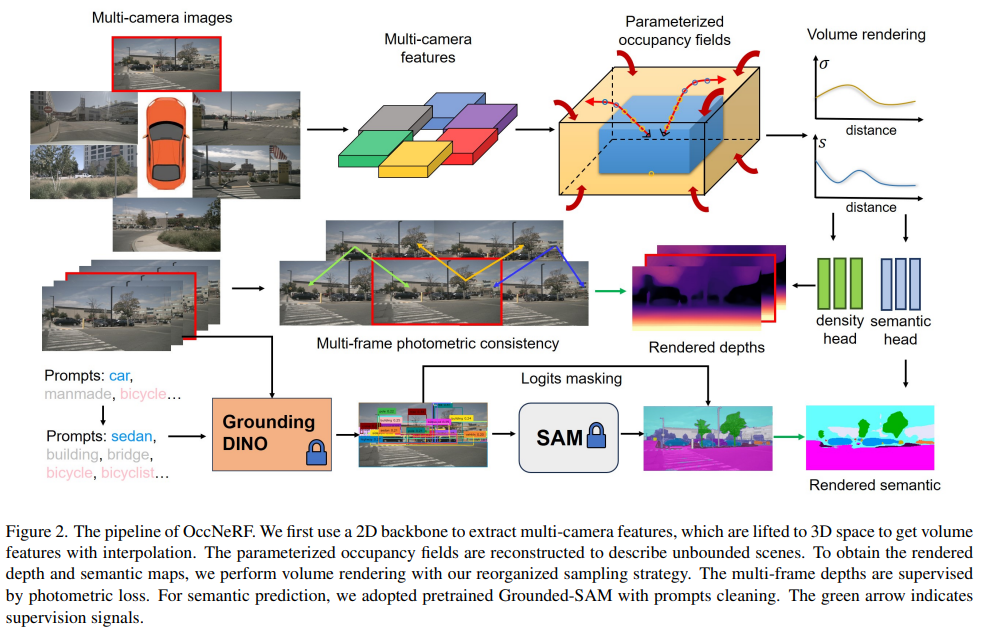
图2. OccNeRF的流程。我们首先使用2D主干网络提取多摄像头特征,然后将这些特征提升到3D空间,通过插值得到体积特征。参数化的占据场被重建以描述无界场景。为了获得渲染的深度和语义地图,我们采用了重新组织的采样策略进行体积渲染。多帧深度受光度损失监督。对于语义预测,我们采用了预训练的Grounded-SAM模型,并进行提示清理。绿色箭头表示监督信号。
3. 参数化占据场
与之前的研究[78, 86]不同,我们需要在自监督设置中考虑无界场景。一方面,我们应该保留内部区域的高分辨率(例如[-40m, -40m, -1m, 40m, 40m, 5.4m]),因为这部分涵盖了大部分感兴趣的区域。另一方面,外部区域是必要的,但信息较少,应该在收缩空间内表示,以减少内存消耗。受[3]的启发,我们提出了一个具有可调兴趣区域和收缩阈值的变换函数,以参数化每个体素网格的坐标 r = ( x , y , z ) r = (x, y, z) r=(x,y,z)。

在这段文字中, r ’ = r / r b r’ = r/r_b r’=r/rb 是输入 r r r的归一化坐标,而 f ( r ) ∈ ( − 1 , 1 ) f(r) ∈ (−1, 1) f(r)∈(−1,1)表示归一化参数化坐标。 r b r_b rb是内部区域的边界,对于x、y、z方向是不同的。 α ∈ [ 0 , 1 ] α ∈ [0, 1] α∈[0,1]代表参数化空间中感兴趣区域的比例。较高的 α α α表示我们使用更多的空间来描述内部区域。请注意,在方程1中,当 r = r b r = r_b r=rb时,两个函数具有相同的值和梯度。有关推导细节,请参考补充材料。
为了从2D视图中获得3D体素特征,我们首先在参数化坐标系中为每个体素生成相应的点 P p c = [ x p c , y p c , z p c ] T P_{pc} = [x_{pc}, y_{pc}, z_{pc}]^T Ppc=[xpc,ypc,zpc]T,然后将它们映射回到自车坐标系中:
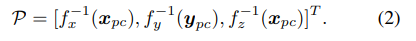
然后我们将这些点投影到2D图像特征平面上,并使用双线性插值来获取2D特征:
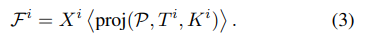
在这段文字中,proj是将3D点 P P P投影到由相机外参 T T T和内参 K i K_i Ki定义的2D图像平面的函数, ⟨ ⟩ ⟨⟩ ⟨⟩是双线性插值运算符, F i F_i Fi是插值结果。为了简化聚合过程并减少计算成本,我们直接对多相机的2D特征进行平均以获得体积特征,这与[17, 24]中使用的方法相同。最后,我们使用3D卷积网络来提取特征并预测最终的占用输出。
4. 多帧深度估计
为了将占据场投影到多摄像头深度图中,我们采用了体积渲染[48],这在基于NeRF的方法中被广泛使用[2, 49, 84]。为了渲染给定像素的深度值,我们从摄像机中心 o o o沿着指向像素的方向 d d d发射一条射线。该射线由 v ( t ) = o + t d v(t) = o + td v(t)=o+td表示,其中 t ∈ [ t n , t f ] t ∈ [t_n, t_f] t∈[tn,tf]。然后,在3D空间中沿着射线采样 L L L个点 { t k } k = 1 L \{t_k\}^L_{k=1} {tk}k=1L,以获取密度 σ ( t k ) σ(t_k) σ(tk)。对于所选的 L L L个积分点,相应像素的深度通过以下公式计算:
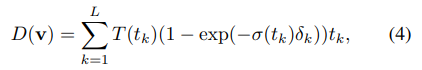
在这里, T ( t k ) = e x p ( − ∑ k ′ = 1 k − 1 σ ( t k ) δ k ) T(t_k) = exp(-\sum_{k′=1}^{k-1} σ(t_k)δ_k) T(tk)=exp(−∑k′=1k−1σ(tk)δk),其中 δ k = t k + 1 − t k δ_k = t_{k+1} − t_k δk=tk+1−tk是采样点之间的间隔。
一个关键问题是如何在我们提出的坐标系中对 { t k } k = 1 L \{t_k\}^L_{k=1} {tk}k=1L进行采样。在深度空间或视差空间中进行均匀采样将导致参数化网格的内部或外部区域中出现不平衡的点序列,这将对优化过程产生不利影响。假设o在坐标系的原点附近,我们直接从 U [ 0 , 1 ] U[0, 1] U[0,1]中对参数化坐标进行采样 L ( r ) L(r) L(r)个点,并使用方程1的逆函数来计算 { t k } k = 1 L ( v ) \{t_k\}^{L(v)}_{k=1} {tk}k=1L(v)。对于一条射线,特定的 L ( v ) L(v) L(v)和 r b ( v ) r_b(v) rb(v)计算如下:
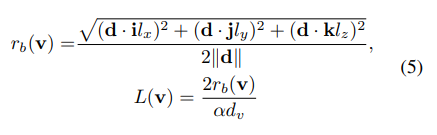
在这里, i 、 j 、 k i、j、k i、j、k分别是 x 、 y 、 z x、y、z x、y、z方向的单位向量, l x 、 l y 、 l z l_x、l_y、l_z lx、ly、lz分别是内部区域的长度, d v d_v dv是体素大小。为了更好地适应占据表示,我们直接预测渲染权重而不是密度。
传统的监督方法是计算渲染的RGB图像与原始RGB图像之间的差异,这在NeRF [49]中被采用。然而,我们的实验结果表明这种方法效果不佳。可能的原因是,对于NeRF来说,大规模场景和少量视图监督很难收敛。为了更好地利用时间信息,我们采用了[21, 89]中提出的光度损失。具体来说,我们根据渲染的深度和给定的相对姿态,将相邻帧投影到当前帧上。然后我们计算投影图像与原始图像之间的重建误差:
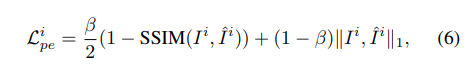
在这里, “ i ” “i” “i”是指投影图像, β = 0.85 β=0.85 β=0.85。此外,我们采用了[21]中介绍的技术,即每像素最小重投影损失和自动遮罩静止像素。对于每个摄像头视角,我们渲染一个短序列而不是单帧,并执行多帧光度损失。
5. 开放词汇语义监督
在这段文本中,作者讨论了使用多相机图像的2D语义标签来提供语义3D占用预测的像素级语义监督。这有助于网络捕捉几何一致性和体素之间的空间关系。为了获得2D标签,之前的研究将3D激光雷达点投影到图像空间,以避免注释密集的3D占用的昂贵成本。然而,作者的目标是在完全以视觉为中心的系统中预测语义占用,并且仅使用2D数据。为此,他们利用了预训练的开放词汇模型GroundedSAM来生成2D语义分割标签。没有任何2D或3D地面真实数据,预训练的开放词汇模型使他们能够获得与给定类别名称语义密切匹配的2D标签。这种方法可以轻松扩展到任何数据集,使他们的方法高效且具有普适性。