概述
前几篇咱们讲了es的语法、存储的优化、常规运维等等,今天咱们看下如何备份数据和恢复数据。
在传统的关系型数据库中我们有多种备份方式,常见有热备、冷备、全量+定时增量备份、通过开发程序备份等等,其实在es中是一样的。
官方建议采用snapshot方式进行备份与恢复(它是有点冷备的意思,采用直接物理copy的方式,适合大数据量情况下),民间开源的有elasticsearch-dump方式进行备份但是这种方式只适用于小数据量的情况下,它是基于scroll语法进行的备份操作。
咱们今天就一起看下如何操作snapshot。es支持把快照保存到远端s3、hdfs、azure、gcs、本地磁盘,前4中需用安装插件和第三方能力,而本地磁盘的方式呢相对来说成本较小,我们今天就以本地磁盘的方式作为案例带大家看下。
单节点案例
首先我们看下单节点的情况下,我们首先需要在配置文件中配置好本地磁盘:
path.repo:["/opt/elasticsearch-cluster/snapshot_repo"]可以配置多个仓库,如果刚开始没有配置这个需要配置后重启es,通过http方式来注册一个仓库:
PUT http://192.168.11.14:9200/_snapshot/testbackup{"type": "fs","settings": {"location": "/opt/elasticsearch-cluster/snapshot_repo/my_backup"}}
注册成功以后咱们需要验证下是否可以正常访问该仓库:
POST http://192.168.11.14:9200/_snapshot/testback/_verify{"nodes" : {"mDRki1qVRBGnJiGEHUNlpg" : {"name" : "node-1"}}}
节点可以正常读写当前仓库,只有这个时候才可以执行备份操作,那么咱们现在执行下全库备份:
PUT http://192.168.11.14:9200/_snapshot/testback/snapshot_2{"accepted" : true}
如果数据量很小这个直接就是秒级的,如果数据量达到一定程度即便是物理copy也是需要很长一定时间的,那么这个时候就可以查看当前备份的任务状态:
GET http://192.168.11.14:9200/_snapshot/testback/snapshot_2/_status{"snapshots" : [{"snapshot" : "snapshot_2","repository" : "testback","uuid" : "O7YoR7dSQKueRff3jI4yow","state" : "SUCCESS","include_global_state" : true,"shards_stats" : {"initializing" : 0,"started" : 0,"finalizing" : 0,"done" : 54,"failed" : 0,"total" : 54},"stats" : {,,,,},"indices" : {,,,,, # 备份的索引信息}}]}
备份好了以后我们看下如何进行恢复,有些系统级的索引是没必要恢复的,此时我们就可以仅仅恢复业务索引:
POST http://192.168.11.14:9200/_snapshot/testback/snapshot_2/_restore{"indices": "log-server-*", #通过通配字符可以恢复批量索引"ignore_unavailable": true,"include_global_state": false}
单节点的基本操作就说完了,咱们看下集群中的恢复案例应该如何搞,有没有什么不一样的地方。
集群案例
咱们以2个节点的集群作为案例,那么我们需要考虑一个事情,仓库配置的话是需要每个节点都配置么?备份的时候是每个节点下的仓库都有一部分数据么?恢复的时候怎么读取所有节点上的快照数据呢?
假设只需要在master节点上配置仓库即可,咱们启动后注册一个仓库看下结果:
PUT http://192.168.11.14:9200/_snapshot/my_backup
{"type": "fs", "settings": {"location": "/opt/elasticsearch-cluster/snapshot_repo/my_backup" }
}{"error" : {"root_cause" : [{"type" : "repository_verification_exception","reason" : "[my_backup] [[NI3uZdOPSBCybjAZVFd2Lg, 'RemoteTransportException[[node-2][192.168.11.14:9300][internal:admin/repository/verify]]; nested: RepositoryMissingException[[my_backup] missing];']]"}],"type" : "repository_verification_exception","reason" : "[my_backup] [[NI3uZdOPSBCybjAZVFd2Lg, 'RemoteTransportException[[node-2][192.168.11.14:9300][internal:admin/repository/verify]]; nested: RepositoryMissingException[[my_backup] missing];']]"},"status" : 500
}我们可以看到直接报错了,提示和node-2上的仓库访问出现异常,那么我们把另外一个节点也配置上仓库再看下效果:
PUT http://192.168.11.14:9200/_snapshot/my_backup
{"type": "fs", "settings": {"location": "/opt/elasticsearch-cluster/snapshot_repo/my_backup" }
}{"error" : {"root_cause" : [{"type" : "repository_verification_exception","reason" : "[my_backup] [[NI3uZdOPSBCybjAZVFd2Lg, 'RemoteTransportException[[node-2][192.168.11.14:9300][internal:admin/repository/verify]]; nested: RepositoryVerificationException[[my_backup] a file written by master to the store [/opt/elasticsearch-cluster/snapshot_repo/my_backup"] cannot be accessed on the node [{node-2}{NI3uZdOPSBCybjAZVFd2Lg}{hmw7r2S0S7GB7y3vWvLHzQ}{192.168.114.14}{192.168.114.14:9300}{cdhilmrstw}{ml.machine_memory=33382490112, xpack.installed=true, transform.node=true, ml.max_open_jobs=20}]. This might indicate that the store [/home/app/es/backup] is not shared between this node and the master node or that permissions on the store don't allow reading files written by the master node]; nested: NoSuchFileException[/home/app/es/backup/tests-8N681uUdQeiPuaxhj8tNag/master.dat];']]"}],"type" : "repository_verification_exception","reason" : "[my_backup] [[NI3uZdOPSBCybjAZVFd2Lg, 'RemoteTransportException[[node-2][192.168.14.14:9300][internal:admin/repository/verify]]; nested: RepositoryVerificationException[[my_backup] a file written by master to the store [/opt/elasticsearch-cluster/snapshot_repo/my_backup"] cannot be accessed on the node [{node-2}{NI3uZdOPSBCybjAZVFd2Lg}{hmw7r2S0S7GB7y3vWvLHzQ}{192.168.114.14}{192.168.114.14:9300}{cdhilmrstw}{ml.machine_memory=33382490112, xpack.installed=true, transform.node=true, ml.max_open_jobs=20}]. This might indicate that the store [/home/app/es/backup] is not shared between this node and the master node or that permissions on the store don't allow reading files written by the master node]; nested: NoSuchFileException[/home/app/es/backup/tests-8N681uUdQeiPuaxhj8tNag/master.dat];']]"},"status" : 500
}
可以看到此时错误又变了,提示无法读取主节点上的仓库,这是因为啊2个节点之间的仓库没有做共享,这个时候我们只需要把所有节点的备份仓库做nas共享即可,至于恢复的时候和单节点是一样的,
总结
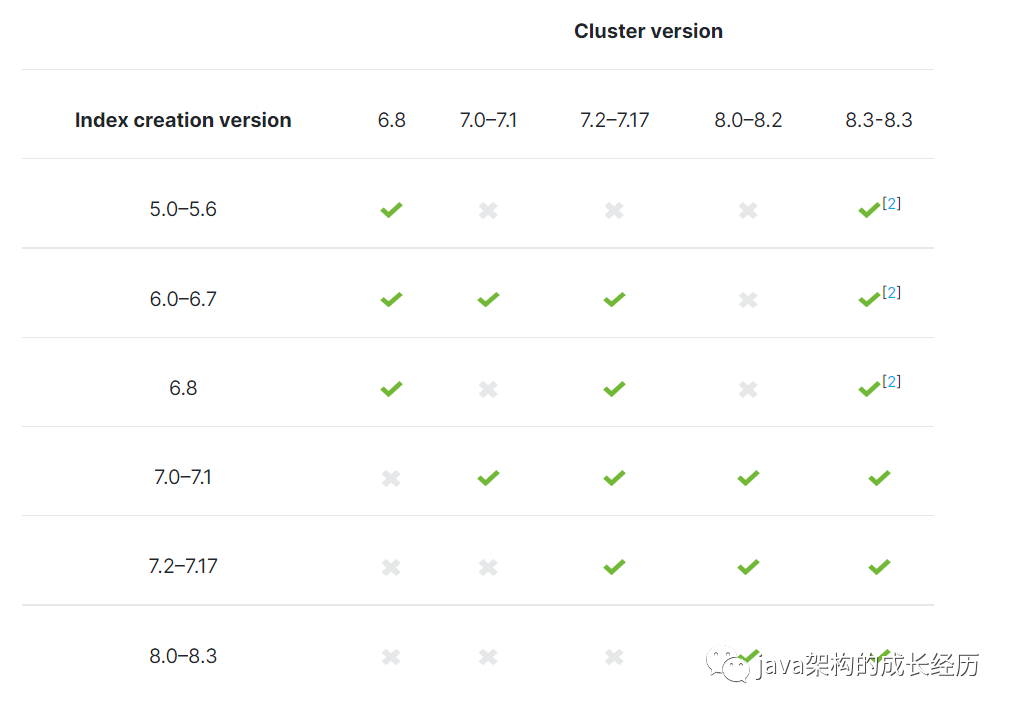
至此我们的恢复与备份就说完了,除了以上的问题大家还需要关注下各个版本之间的数据差异,是否可以跨版本恢复,es的版本更新速度还是很快的,所以大家一定要关注下,以下是官方给的一个版本限制:
Elasticsearch系列经典文章
-
elasticsearch列一:索引模板的使用
-
elasticsearch系列二:引入索引模板后发现数据达到一定量还是慢怎么办?
-
elasticsearch系列三:常用查询语法
-
Elasticsearch 底层存储原理解密
-
Elasticsearch优化建议
-
干货 | Elasticsearch 8.X 节点角色划分深入详解