Q1:什么是软件设计模式?
A:软件设计模式,又称设计模式。它是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性、程序的重用性。综上:设计模式就是泛指一系列编程的思想,是代码设计经验的总结,基于设计模式来开发代码可以使得程序更加稳定,拓展性更强。
Q2:为什么要学习设计模式?
A:在以往的项目开发中,不管是 ftp服务器 还是 图像识别智能垃圾桶 又或者更之前的智能小车项目,都没有一个固定的代码开发格式,更多的是根据需求一个个实现功能,虽然有了分文件编程的思想,但是代码整体还是缺乏规整度。尤其是在开发过程中,一个功能的实现经常会导致其他功能出现问题,所以需要学习设计模式,使得代码更加健壮和格式化。
Q3:算法 VS 设计模式?
A: 注意,算法不是设计模式,因为算法是使用逻辑来解决某些特定的问题,其致力于解决问题而非设计问题
设计模式的分类
软件设计模式共有23种,总体来说可以被分为三大类:
- 五种创建型模式:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式
- 七种结构型模式:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式
- 十一种行为型模式:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
而我接下来着重学习的是创建型模式中的“工厂(方法)模式”
类 & 对象
设计模式通常描述了一组相互紧密作用的类与对象:
小插曲:
类和对象其实在java中是一个更常见的概念(这也是为什么java被称为“面向对象”的语言),但是“类和对象”在设计模式中也被提到。值得注意的是,设计模式可以使用C语言来实现,所以C语言也可以实现”面向对象“的编程,但是相比java来说可能没那么直接,所以C语言还是被笼统的称为“面向过程”的语言,这不代表C语言就完全无法“面向对象”。
- 类:是一种用户自定义的引用数据类型,也称类类型 --> C语言的结构体的定义
struct student{int age;float score; //成员属性void (*s_slogan)(); //成员方法
};- 对象:类的一种具象 --> C语言结构体类型的变量
struct student MJM;
struct student MMJ; //MJM,MMJ就是对象结构体对象定义的补充
C语言的结构体, 共用体(联合体)_一个结构体里有两个共用体-CSDN博客
在以前学习结构体的博文中,介绍了几种常见结构体对象的定义方法:
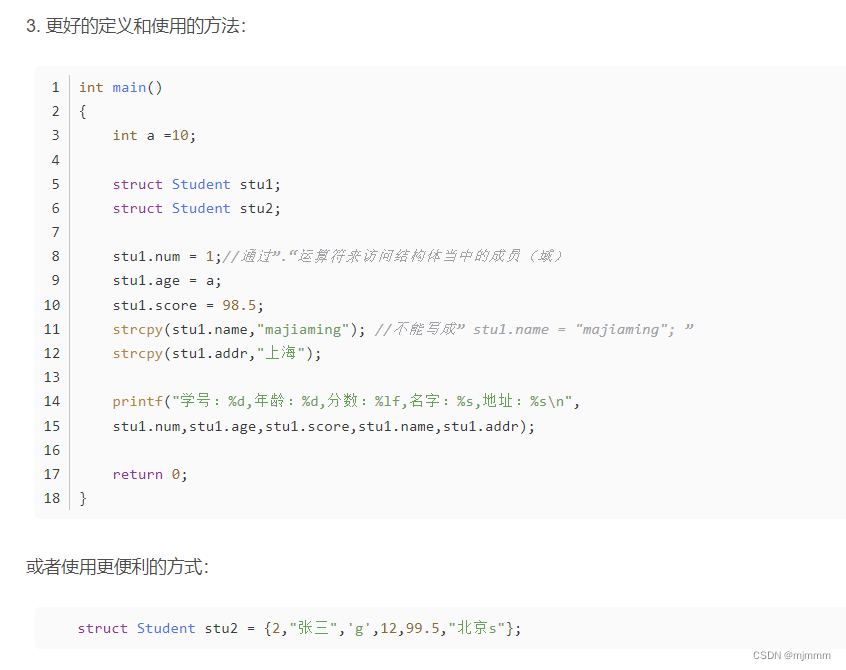
现在,假设有一个结构体:
struct student{int age;float score; //成员属性void (*s_slogan)(); //成员方法
};而我现在想要定义一个名为“stu1”的该结构体对象,并且我只想对其的“score”和“s_slogan”赋值而不管其他两个成员,那么就可以使用如下的定义方法:
struct student stu1 = {.score = 67.5, //注意,是逗号.s_slogan = stu1_slogan, //最后一项的逗号可加可不加
};oop_test.c:
#include <stdio.h>struct student{int age;float score; //成员属性void (*s_slogan)(); //成员方法
};void stu1_slogan()
{printf("stu1: I will be no.1!\n");
}void stu2_slogan()
{printf("stu2: I want to make my parent proud!\n");
}int main(){struct student stu1 = {.score = 97.5,.s_slogan = stu1_slogan, //函数名等于其地址,所以此处是地址的赋值};struct student stu2 = {.score = 87,.s_slogan = stu2_slogan,};printf("score of stu1:%f\n",stu1.score);stu1.s_slogan();printf("score of stu2:%f\n",stu2.score);stu2.s_slogan();return 0;
}实现效果:

工厂模式
工厂模式(Factory Pattern)是Java中最常见的设计模式之一,也可以使用C来实现。刚刚就提到过,这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方法。
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
使用SourceInsight编写代码
之前学习的使用SourceInsight查看源码的博文:
香橙派配合IIC驱动OLED & 使用SourceInsight解读源码_香橙派5 驱动屏幕-CSDN博客
学到现在,其实已经接触过多种编写代码的方式:
- 使用windows的Notepad++来编写:界面简单,但是缺乏和linux的交互
- 使用linux的vi来编写:最简单的一种,适合linux开发,但是vi界面并不友好
- 使用VS Code远程连接linux编程:界面友好,适合linux开发,但是对单片机内存占用较大
现在,尝试使用SourceInsight来编写代码!
- 使用SourceInsight来编写:适合多文件编程,界面友好,且编写完成后可以方便的查看跳转,但是缺乏和linux的交互
工厂模式的代码涉及大量 分文件编程 的思路,故可以使用SourceInsight来编写代码。但也如上所说,SourceInsight缺乏和linux的交互,所以在代码编写完成后需要发送到单片机进行编译和运行。
但是,这不代表必须要使用SourceInsight来编写分文件编程的代码,任何能编写C语言的工具理论上都可以使用,我也完全可以使用以前使用的任何一种方法来编写代码,只不过现在作为学习阶段目的是多接触一些不同的方式;并且SourceInsight也适合进行多文件的编程,仅此而已。
在windows下新建一个“factory_test”文件夹用于保存测试代码:
然后创建一个在“factory_test”下创建一个“stu1.c”:

然后打开SourceInsight,先点击左上方 Project -> Close Project来关闭之前打开的项目;
然后点击左上方 File -> Open -> 选择要编写的代码,此处选择stu1.c:

然后,就可以开始编写代码了,同样的步骤,可以使用SourceInsight打开stu2.c; stu3.c; stu.h; main.c:
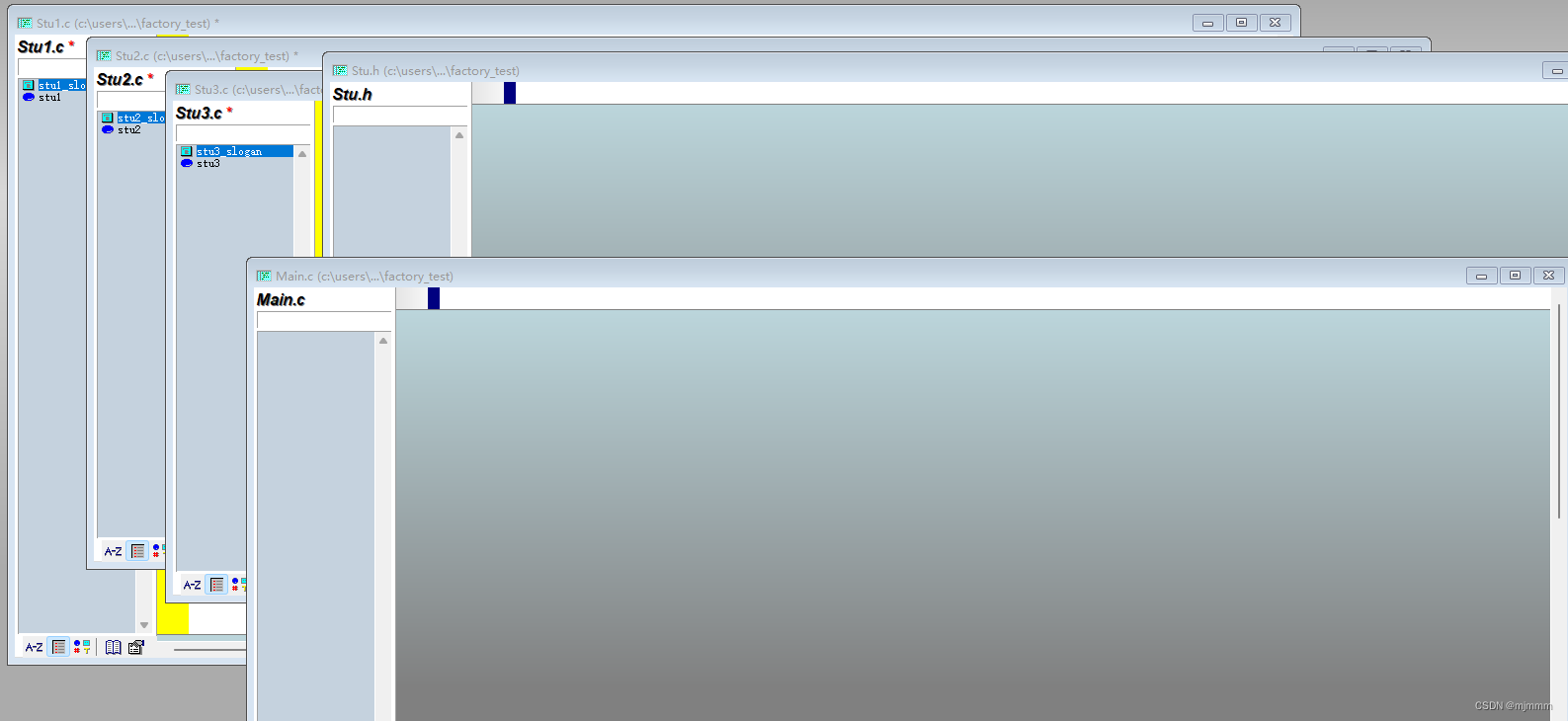
(可见,SourceInsight的界面就很适合多个C文件的同时编辑)
stu1.c:
#include "stu.h"void stu1_slogan()
{printf("stu1: I will be no.1!\n");
}struct student stu1 = {.name = "stu1",.score = 97.5,.s_slogan = stu1_slogan, //函数名等于其地址,所以此处是地址的赋值
};struct student* putS1inLink(struct student *head)
{struct student *p = head; if(p == NULL){head = &stu1;}else{stu1.next = head;head = &stu1;}return head;
}stu2.c:
#include "stu.h"void stu2_slogan()
{printf("stu2: I want to make my parent proud!\n");
}struct student stu2 = {.name = "stu2",.score = 87.5,.s_slogan = stu2_slogan, //函数名等于其地址,所以此处是地址的赋值
};struct student* putS2inLink(struct student *head)
{struct student *p = head; if(p == NULL){head = &stu2;}else{stu2.next = head;head = &stu2;}return head;}stu3.c:
#include "stu.h"void stu3_slogan()
{printf("stu3: I want to be a PC-game master!\n");
}struct student stu3 = {.name = "stu3",.score = 57.5,.s_slogan = stu3_slogan, //函数名等于其地址,所以此处是地址的赋值
};struct student* putS3inLink(struct student *head)
{struct student *p = head; if(p == NULL){head = &stu3;}else{stu3.next = head;head = &stu3;}return head;}stu.h:
#include <stdio.h>struct student{char* name;int age;float score; //成员属性void (*s_slogan)(); //成员方法struct student *next; //链表
};struct student* putS1inLink();
struct student* putS2inLink();
struct student* putS3inLink();
main.c:
#include "stu.h"
#include <string.h>struct student* findSTUinLink(char *name, struct student *phead)
{struct student *p = phead;while(p != NULL){if(strcmp(p->name,name)==0){return p;}p = p->next;}return NULL;
}int main()
{struct student *phead = NULL;struct student *pfind = NULL;char name[64] = {'\0'};phead = putS1inLink(phead);phead = putS2inLink(phead);phead = putS3inLink(phead);if(phead == NULL){printf("Link Insert Error!\n");return 1;}while(1){printf("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\n");printf("who do you want to look up?\n (pls insert 'stu1' OR 'stu2' OR 'stu3')\n");scanf("%s",name);if(strcmp(name,"stu1")==0 ||strcmp(name,"stu2")==0 || strcmp(name,"stu3")==0){pfind = findSTUinLink(name,phead);if(pfind != NULL){printf("name:%s;score:%f\n",pfind->name,pfind->score);pfind->s_slogan();}else{printf("can't find in link!\n");}}else{printf("unknown cmd!\n");}memset(name,'\0',strlen(name));}return 0;
}在代码都编写好之后,可以全部关闭,在“factory_test”文件夹中创建一个“si”文件夹用于保存SourceInsight工程:

然后回到SourceInsight点击左上角的Project -> New Project,并选择刚刚的“si”文件夹:

然后点击两次OK,直到出现这个界面:
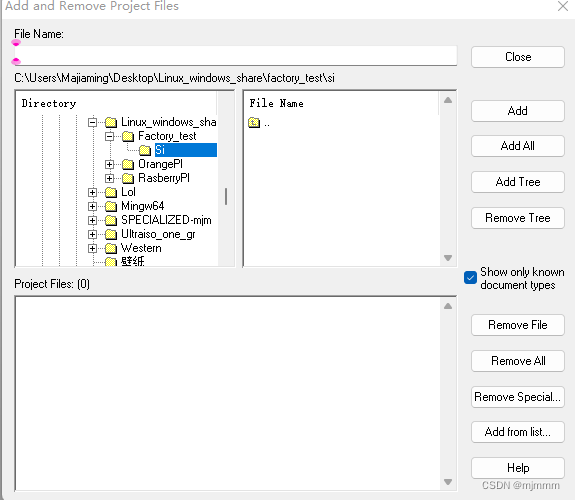
点击上一级的“factory_test” -> “Add All”/“Add Tree”:

最后再次点击左上角的Project -> Synchronize Files 来同步一下:

现在之前写的代码就集合成了一个工程的形式可以在SourceInsight中查看了(按住CTRL点击函数名就可以进行跳转)

并且,此时也可以继续修改代码
代码的编译和运行
现在,将“factory_test”文件夹中的代码全部发送给树莓派:

然后运行以下指令编译并运行:
1. gcc *.c -o fac
2. ./fac 
可见,代码运行成功!
综上,这就是一个典型的工厂模式代码设计。对于“main.c”,相比于整体其代码量并不多,且不会向用户暴露创建逻辑。
- 结构体“student”就是一个“工厂”,是一个类;stu1,2,3作为对象以链表的形式存在在“工厂”中。
- main函数需要做的就是将“工厂”中的“模块”组装起来,然后想用哪个就去找到哪个就可以。
从上面的代码结构不难看出,使用工厂模式使得代码更稳定且拓展性更强,如果需要一个新的模块,只需要再创建一个如“stu4.c”,并将其插入结构体student中就可以,十分的方便且不会影响到其他的模块。