深度解析基于模糊数学的C均值聚类算法
- 模糊C均值聚类 (FCM)
- 聚类步骤:
- FCM Python代码:
模糊C均值聚类 (FCM)
在数据挖掘和聚类分析领域,C均值聚类是一种广泛应用的方法。模糊C均值聚类(FCM)是C均值聚类的自然升级版。相对于硬划分的K均值聚类,FCM引入了模糊的隶属度概念,使数据点能够同时隶属于不同聚类中心,更灵活地捕捉数据的复杂结构。

聚类步骤:
- 初始化: 使用k-means++方法确定初始聚类中心,确保选择最优解。
- 隶属度计算: 计算各点对各聚类中心的隶属度u(i,j),其中m为加权指数。
u(i,j) = (sum(distance(point(j), center(i)) / distance(point(j), center(k)))^(1/(m-1)))^-1 - 聚类中心更新: 根据隶属度更新新的聚类中心,同时标记聚类中心变化轨迹。
v(i) = sum(u(i,j)^m * point(j)) / sum(u(i,j)^m) - 收敛判断: 判断聚类中心变化幅值是否小于给定的误差限。若不满足条件,返回步骤2,否则退出循环。
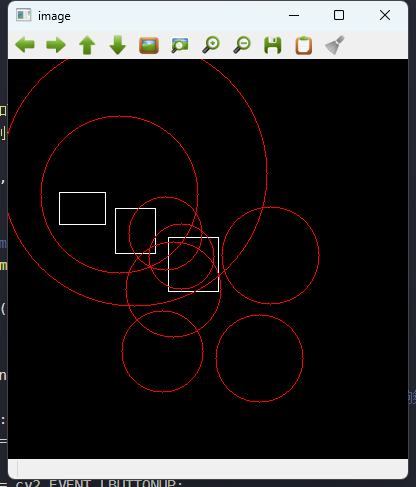
- 结果展示: 输出聚类中心轨迹和最终聚类结果。
FCM Python代码:
# 初始化聚类中心
def initialize_centers(data, k):# (代码部分省略)# 计算隶属度矩阵
def calculate_membership(data, centers, m):# (代码部分省略)# 更新聚类中心
def update_centers(data, membership, m):# (代码部分省略)# 判断是否收敛
def is_converged(centers, new_centers, epsilon):# (代码部分省略)# 聚类结果展示
def display_results(centers, trajectory):# (代码部分省略)
该算法的特点包括:
- 与普通的k均值聚类相似。
- 要求完全聚类,不能区分噪声点。
- 聚类中心符合度更高,但计算效率相对较低。
- 采用平滑参数和隶属度的概念,使各点并不直接隶属于单个聚类中心。
以上代码中各函数的作用包括初始化聚类中心、计算隶属度矩阵、更新聚类中心、判断是否收敛以及展示聚类结果。



![[C#]使用纯opencvsharp部署yolov8-onnx图像分类模型](https://img-blog.csdnimg.cn/direct/59cc41476aee453b8193aad6247e2fc7.jpeg)



![[Flutter]WebPlatform上运行遇到的问题总结](https://img-blog.csdnimg.cn/direct/16c604b5d4d34f0aa6d1e0fc3cab99fe.png)
