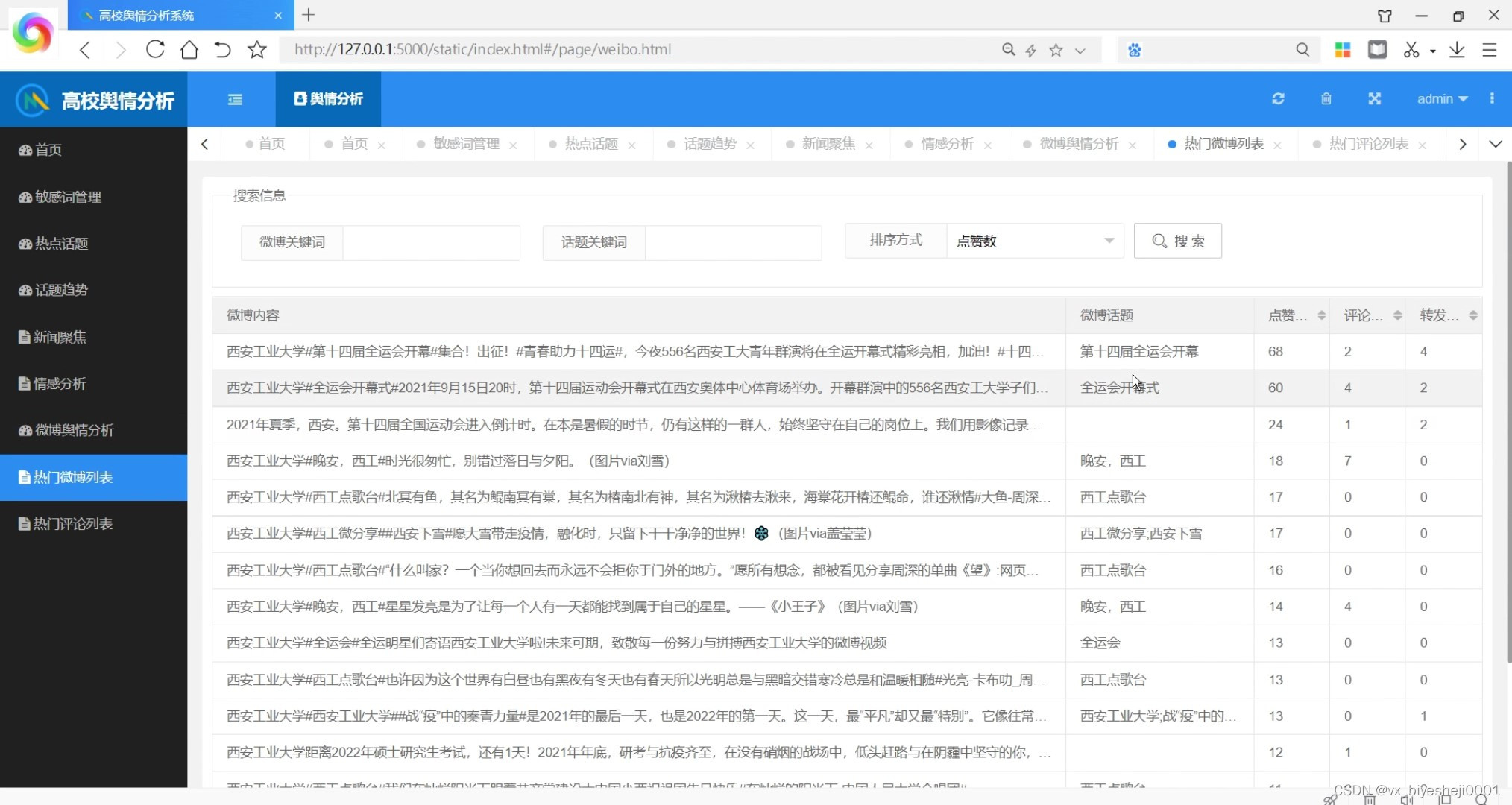
目录
一、Flume简介
(一)Flume定义
(二)Flume作用
二、Flume组成架构
三、Flume安装配置
(一)下载Flume
(二)解压安装包
(三)配置环境变量
(四)查看Flume版本信息
四、Flume的运行
(一)Telnet准备工作
(二)使用Avro数据源测试Flume
(三)使用netcat数据源测试Flume
五、Flume作为Spark Streaming数据源
(一)Spark准备工作
(二)使用Flume作为Spark Streaming数据源
一、Flume简介
数据流 :数据流通常被视为一个随时间延续而无限增长的动态数据集合,是一组顺序、大量、快速、连续到达的数据序列。通过对流数据处理,可以进行卫星云图监测、股市走向分析、网络攻击判断、传感器实时信号分析。
(一)Flume定义
Apache Flume是一种分布式、具有高可靠和高可用性的数据采集系统,可从多个不同类型、不同来源的数据流汇集到集中式数据存储系统中。Flume 基于流式架构,灵活简单。
(二)Flume作用
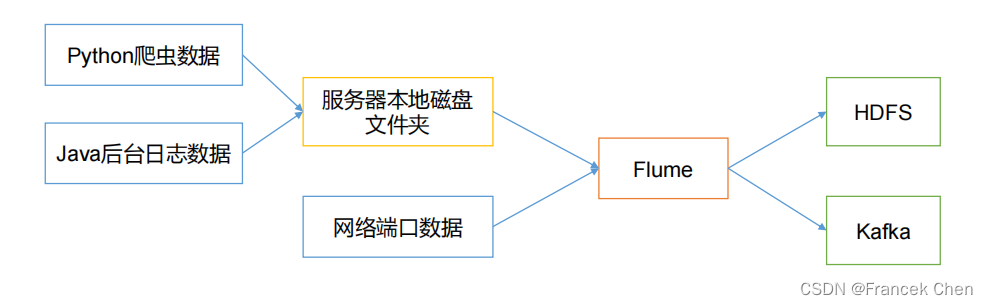
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,可将日志采集后传输到HDFS、Hive、HBase、Kafka等大数据组件。
二、Flume组成架构

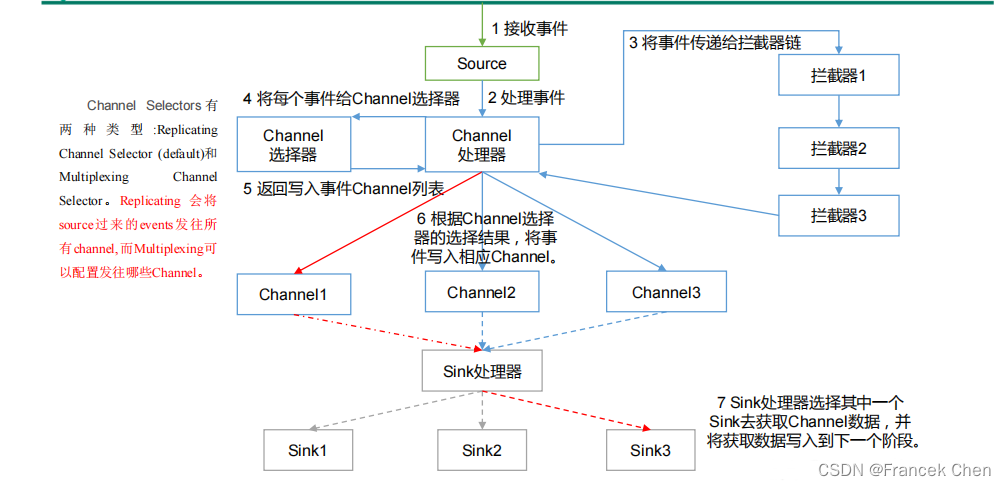
1、Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的,是 Flume 数据传输的基本单元。Agent 主要有 3 个部分组成,Source、Channel、Sink。
2、Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
3、Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
4、 Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个 Flume Agent,Sink 就利用 Channel 提交事务。事务一旦被提交,该 Channel 从自己的内部缓冲区删除事件。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
5、Event
传输单元,Flume 数据传输的基本单元,以事件的形式将数据从源头送至目的地。
Flume Agent 内部原理:
三、Flume安装配置
(一)下载Flume
到Flume官网下载Flume1.7.0安装文件,下载地址如下:
http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
下载完成后上传到虚拟机的“/usr/local/uploads”目录下。
(二)解压安装包
首先进入到“uploads”目录下。将压缩包解压到“/usr/local”目录下
[root@bigdata zhc]# cd /usr/local/uploads
[root@bigdata uploads]# tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /usr/local

将解压的文件修改名字为flume,简化操作。把/usr/local/flume目录的权限赋予当前登录Linux系统的用户。
[root@bigdata uploads]# cd /usr/local
[root@bigdata local]# mv apache-flume-1.7.0-bin flume
[root@bigdata local]# chown -R zhc:zhc ./flume

(三)配置环境变量
首先,修改/etc/profile配置文件:
[root@bigdata local]# vi /etc/profile

export FLUME_HOME=/usr/local/flume
export PATH=$PATH:$FLUME_HOME/bin
export FLUME_CONF_DIR=$FLUME_HOME/conf使文件生效:
[root@bigdata local]# source /etc/profile下面修改 flume-env.sh 配置文件:
[root@bigdata local]# cd /usr/local/flume/conf
[root@bigdata conf]# cp flume-env.sh.template flume-env.sh
[root@bigdata conf]# vi flume-env.sh

在文件中增加一行内容,用于设置JAVA_HOME变量:
export JAVA_HOME=/usr/local/servers/jdk
然后,保存flume-env.sh文件,并退出vim编辑器。
(四)查看Flume版本信息
[root@bigdata conf]# cd /usr/local/flume
[root@bigdata flume]# ./bin/flume-ng version
然后就会发现如下报错: “错误: 找不到或无法加载主类”
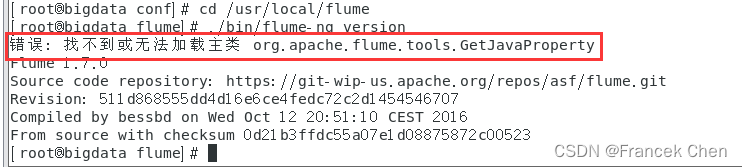
原因分析:
(1)jdk 冲突
(2)安装了HBase就会报着个错
解决方法:
到“/usr/local/flume/bin”目录下修改flume-ng文件。
[root@bigdata flume]# cd /usr/local/flume/bin
[root@bigdata bin]# vi flume-ng
在文件中加入以下内容:
2>/dev/null | grep hbase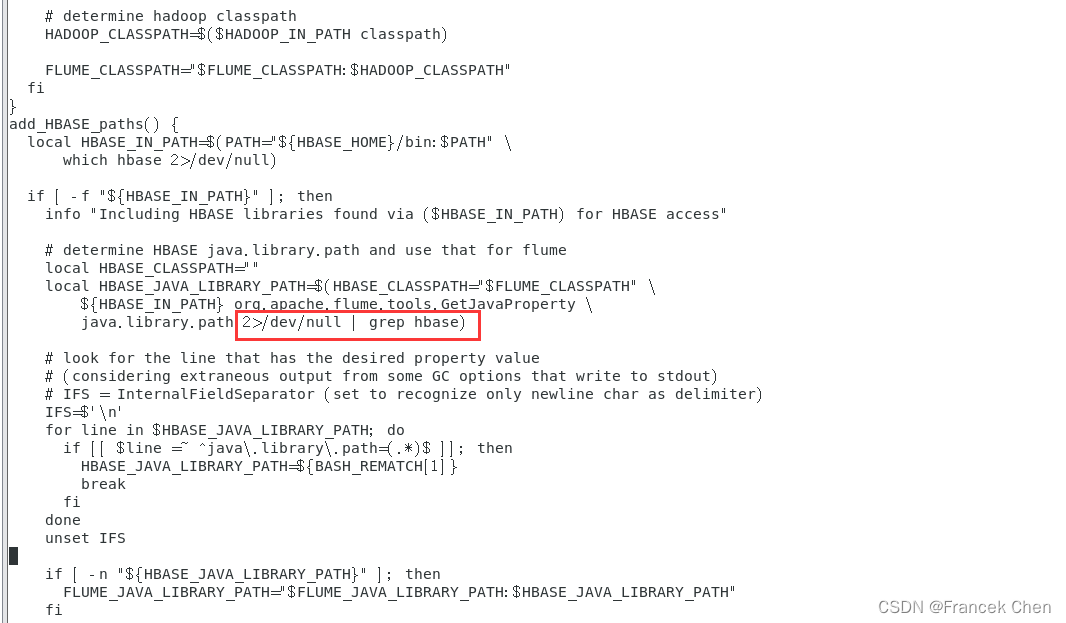
再次查看flume版本信息。

四、Flume的运行
(一)Telnet准备工作
后面的步骤中要用到telnet,在这里先安装:
[root@bigdata zhc]# yum install telnet

(二)使用Avro数据源测试Flume
Avro可以发送一个给定的文件给Flume,Avro 源使用AVRO RPC机制。请对Flume的相关配置文件进行设置,从而可以实现如下功能:在一个终端中新建一个文件helloworld.txt(里面包含一行文本“Hello World”),在另外一个终端中启动Flume以后,可以把helloworld.txt中的文本内容显示出来。
1、创建agent配置文件
[root@bigdata zhc]# cd /usr/local/flume/conf
[root@bigdata conf]# vi avro.conf
在文件中加入以下内容:
#/usr/local/flume/conf/avro.confa1.sources = r1a1.sinks = k1a1.channels = c1# Describe/configure the sourcea1.sources.r1.type = avroa1.sources.r1.channels = c1a1.sources.r1.bind = 0.0.0.0a1.sources.r1.port = 4141#注意这个端口名,在后面的教程中会用得到# Describe the sinka1.sinks.k1.type = logger# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1上面Avro Source参数说明如下:
Avro Source的别名是avro,也可以使用完整类别名称org.apache.flume.source.AvroSource,因此,上面有一行设置是a1.sources.r1.type = avro,表示数据源的类型是avro。
bind绑定的ip地址或主机名,使用0.0.0.0表示绑定机器所有的接口。a1.sources.r1.bind = 0.0.0.0,就表示绑定机器所有的接口。
port表示绑定的端口。a1.sources.r1.port = 4141,表示绑定的端口是4141。
a1.sinks.k1.type = logger,表示sinks的类型是logger。
2、启动flume agent a1
[root@bigdata conf]# /usr/local/flume/bin/flume-ng agent -c . -f /usr/local/flume/conf/avro.conf -n a1 -Dflume.root.logger=INFO,console
这个终端不要关闭。

3、创建指定文件
新建一个终端,输入以下命令:
[root@bigdata mycode]# cd /home/zhc
[root@bigdata zhc]# cd /home/zhc/mycode
[root@bigdata mycode]# mkdir flume
[root@bigdata mycode]# cd flume
[root@bigdata flume]# echo "Hello World">> ./helloworld.txt
[root@bigdata flume]# /usr/local/flume/bin/flume-ng avro-client --conf conf -H localhost -p 4141 -F /home/zhc/mycode/flume/helloworld.txt
执行之后,我们就可以在前面不让关闭的那个终端看到Hello World了:

(三)使用netcat数据源测试Flume
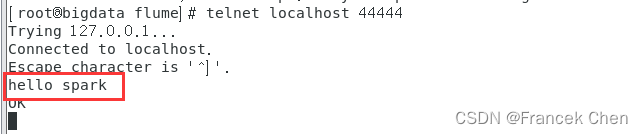
请对Flume的相关配置文件进行设置,从而可以实现如下功能:在一个Linux终端(这里称为“Flume终端”)中,启动Flume,在另一个终端(这里称为“Telnet终端”)中,输入命令“telnet localhost 44444”,然后,在Telnet终端中输入任何字符,让这些字符可以顺利地在Flume终端中显示出来。
1、创建netcat的agent配置
[root@bigdata conf]# cd /usr/local/flume/conf
[root@bigdata conf]# vi netcat.conf
在文件中加入以下内容:
#/usr/local/flume/conf/netcat.conf# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 #同上,记住该端口名# Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2、启动flume agent
[root@bigdata conf]# /usr/local/flume/bin/flume-ng agent --conf /usr/local/flume/conf --conf-file /usr/local/flume/conf/netcat.conf --name a1 -Dflume.root.logger=INFO,console
这个终端不要关闭。
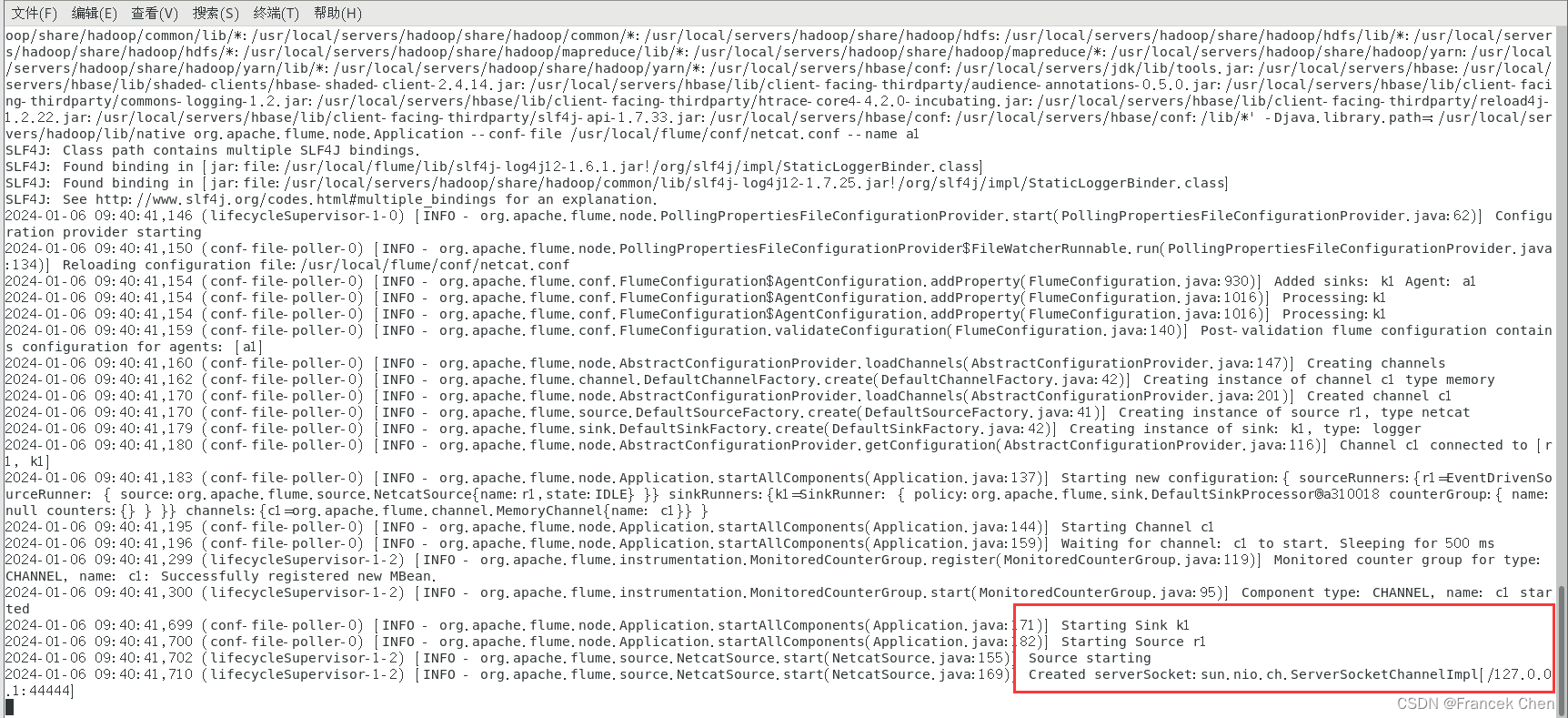
3、新建一个终端输入
[root@bigdata flume]# telnet localhost 44444在这个终端输入字符串就可以显示在前面那个终端里了,但是中文是不支持的,显示长度也有限。

五、Flume作为Spark Streaming数据源
(一)Spark准备工作
1、下载spark-streaming-flume_2.11-2.3.4.jar
首先,到官网下载spark-streaming-flume_2.11-2.3.4.jar:
https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-flume
上面的网址要是打不开,可以用下面的这个网址:
https://repo1.maven.org/maven2/org/apache/spark/spark-streaming-flume_2.11

2、把这个jar文件放到“/usr/local/spark/jars/flume”目录下
[root@bigdata flume]# cd /usr/local/spark/jars
[root@bigdata jars]# mkdir flume
[root@bigdata jars]# cd flume
[root@bigdata flume]# cp /usr/local/uploads/spark-streaming-flume_2.11-2.3.4.jar .

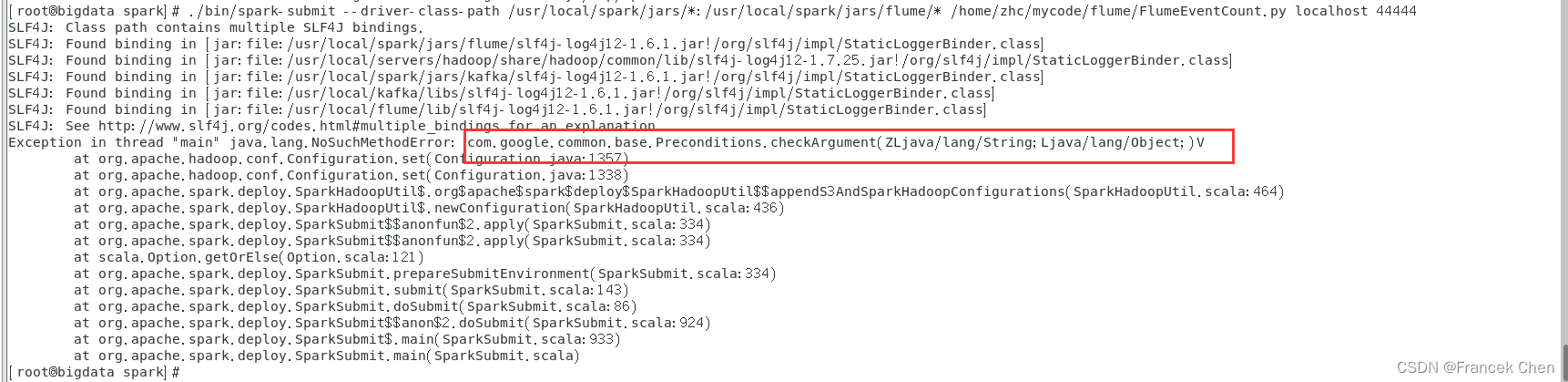
注意:此处不要将“/usr/local/flume/lib”目录下的所有jar包都拷贝到“/usr/local/spark/jars/flume” 目录下,不然会使Spark和Hadoop版本与Guava库的版本不兼容,从而导致后面运行程序时会报错!
错误如下图所示:
3、修改spark-env.sh文件
修改spark目录下conf/spark-env.sh文件中的SPARK_DIST_CLASSPATH变量。把flume的相关jar包添加到此文件中。
[root@bigdata flume]# cd /usr/local/spark/conf
[root@bigdata conf]# vi spark-env.sh
将如下内容加到文件中:
:/usr/local/spark/jars/flume/*:/usr/local/flume/lib/*
这样,Spark环境就准备好了。
(二)使用Flume作为Spark Streaming数据源
Flume是非常流行的日志采集系统,可以作为Spark Streaming的高级数据源。请把Flume Source设置为netcat类型,从终端上不断给Flume Source发送各种消息,Flume把消息汇集到Sink,这里把Sink类型设置为avro,由Sink把消息推送给Spark Streaming,由自己编写的Spark Streaming应用程序对消息进行处理。
1、创建flume-to-spark.conf
[root@bigdata conf]# cd /usr/local/flume/conf
[root@bigdata conf]# vi flume-to-spark.conf
输入以下内容:
#/usr/local/flume/conf/flume-to-spark.conf
#flume-to-spark.conf: A single-node Flume configuration# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1# Describe/configure the sourcea1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 33333# Describe the sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = localhosta1.sinks.k1.port =44444# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000000a1.channels.c1.transactionCapacity = 1000000# Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1
#说明:
1、Flume suorce类为netcat,绑定到localhost的33333端口,消息可以通过telnet localhost 33333 发送到flume suorce
2、Flume Sink类为avro,绑定44444端口,flume sink通过localhost 44444端口把消息发送出来。而spark streaming程序一直监听44444端口。
#注意!!先不要启动Flume agent,因为44444端口还没打开,sink的消息无处可去,44444端口由spark streaming程序打开。
2、编写Spark程序使用Flume数据源
(1)创建python文件
[root@bigdata flume]# cd /home/zhc/mycode/flume
[root@bigdata flume]# vi FlumeEventCount.py
在FlumeEventCount.py中输入以下代码:
#/home/zhc/mycode/flume/FlumeEventCount.pyfrom __future__ import print_functionimport sysfrom pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.flume import FlumeUtils
import pyspark
if __name__ == "__main__":if len(sys.argv) != 3:print("Usage: flume_wordcount.py <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="FlumeEventCount")ssc = StreamingContext(sc, 2)hostname= sys.argv[1]port = int(sys.argv[2])stream = FlumeUtils.createStream(ssc, hostname, port,pyspark.StorageLevel.MEMORY_AND_DISK_SER_2)stream.count().map(lambda cnt : "Recieve " + str(cnt) +" Flume events!!!!").pprint()ssc.start()ssc.awaitTermination()
~ 注意:可能需要安装pyspark,命令为:
[root@bigdata flume]# pip3 install pyspark

(2)测试实际效果
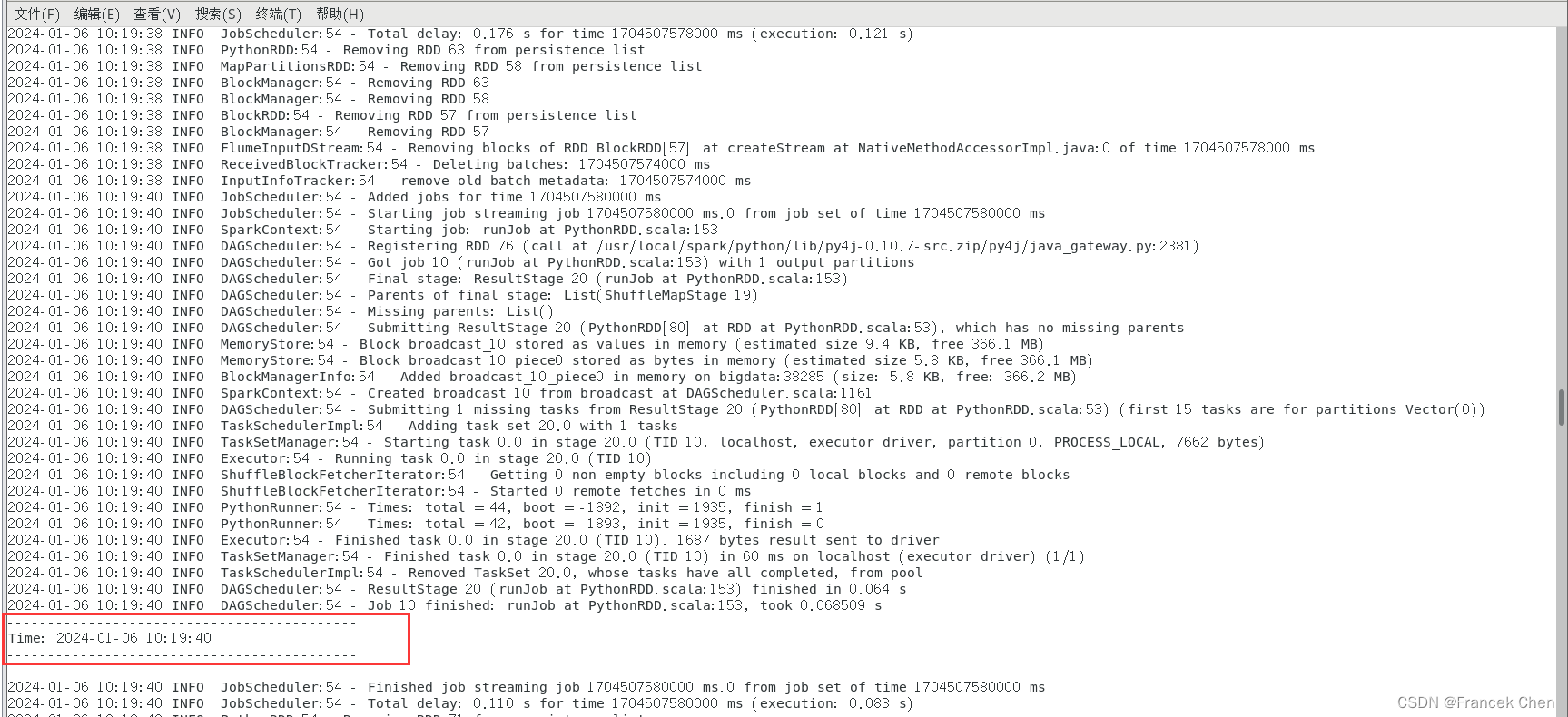
首先,启动Spark streaming程序:
[root@bigdata flume]# cd /usr/local/spark
[root@bigdata spark]# ./bin/spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/flume/* /home/zhc/mycode/flume/FlumeEventCount.py localhost 44444
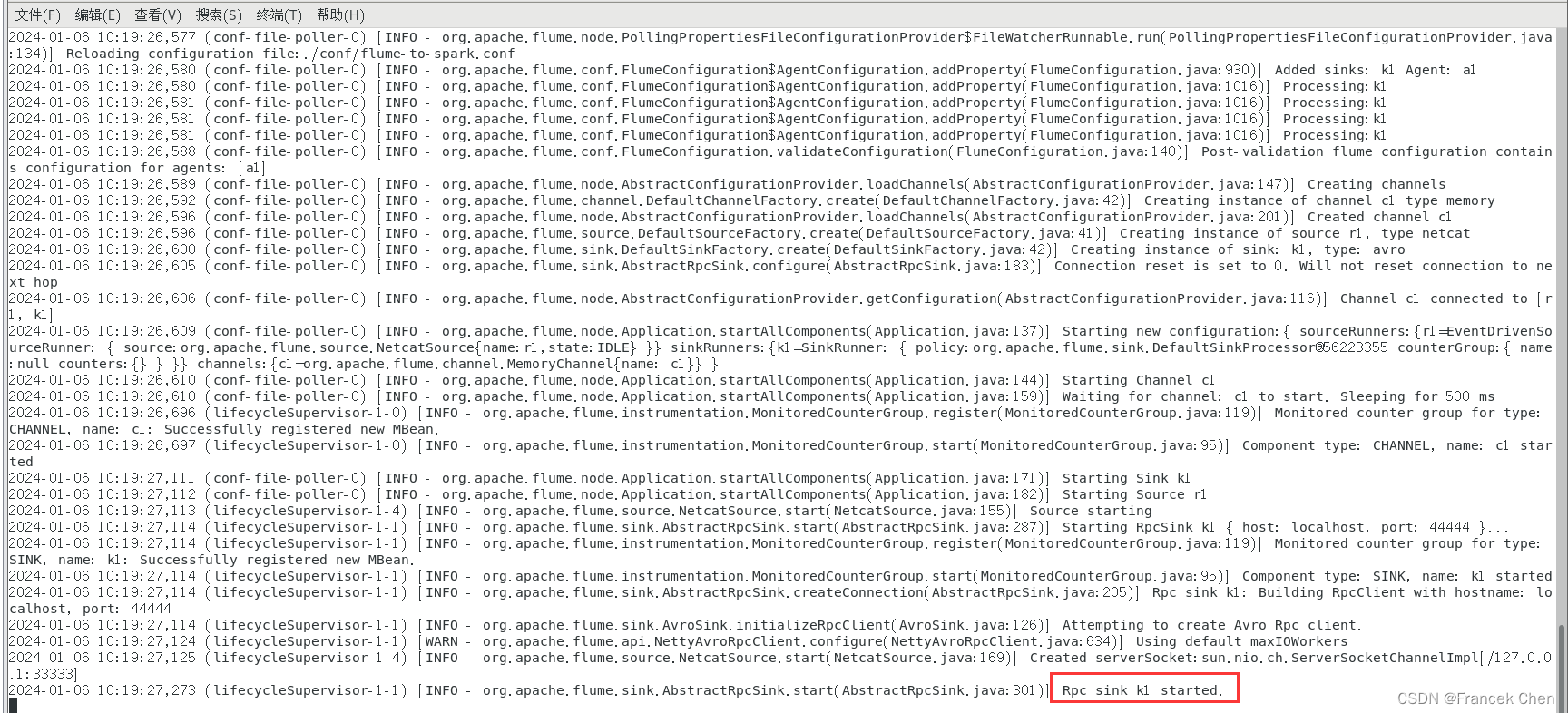
然后,启动一个新的终端,启动Flume Agent:
[root@bigdata zhc]# cd /usr/local/flume
[root@bigdata flume]# bin/flume-ng agent --conf ./conf --conf-file ./conf/flume-to-spark.conf --name a1 -Dflume.root.logger=INFO,console
最后,再启动一个新的终端连接33333端口:
现在你可以在最后这个终端里输入一些字符了。在你输入字符后可以看到第一个终端会显示如下的信息:
-------------------------------------------
Time: 1488029430000 ms
-------------------------------------------
Received 1 flume events!!!