字符串
Rust 中的字符串类型是String。虽然字符串只是比字符多了一个“串”字,但是在Rust中这两者的存储方式完全不一样,字符串不是字符的数组,String内部存储的是Unicode字符串的UTF8编码,而char直接存的是Unicode Scalar Value。
Rust字符串对Unicode字符集有着良好的支持,可以看一下示例:
let hello = String::from("こんにちは");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שָׁלוֹם");
let hello = String::from("नमस्ते");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("السلام عليكم");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
Rust 中的String不能通过下标去访问。
let testString = String::from("天下");
let s = testString[0]; // 你可能想把“天”字取出来,但实际上这样是错误的
String存储的Unicode序列的UTF8编码,而UTF8编码是变长编码。上边即使能访问成功,也只能取出一个字符的 UTF8 编码的第一个字节,很可能是没有意义的。因此 Rust 直接对String禁止了这个索引操作。
字符串字面量中的转义
与 C 语言一样,Rust 中转义符号也是反斜杠\,可用来转义各种字符。
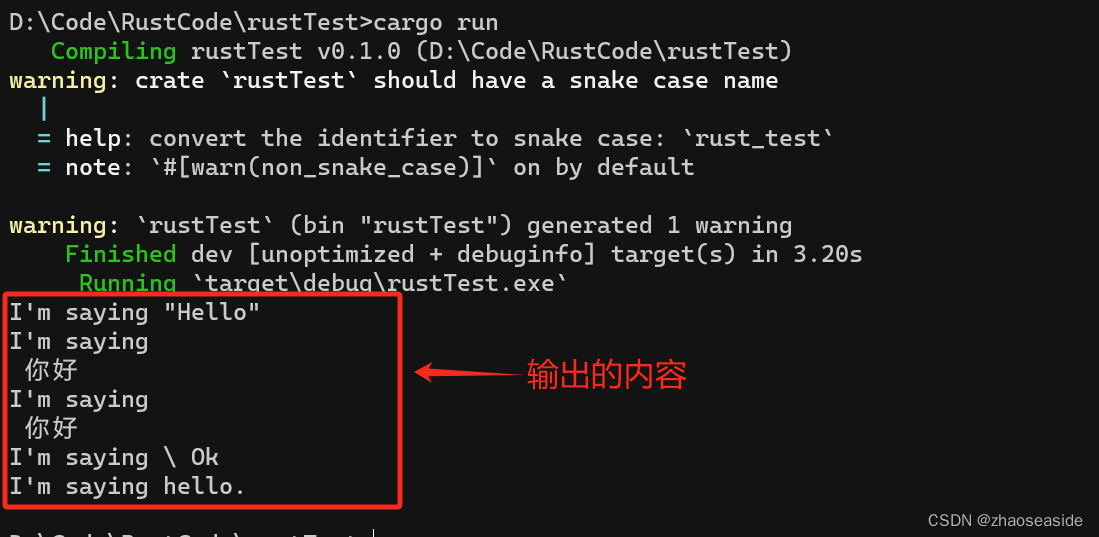
fn main() {// 将""号进行转义let byte_escape = "I'm saying \"Hello\"";println!("{}", byte_escape); //输出的内容为 I'm saying "Hello"// 分两行打印let byte_escape = "I'm saying \n 你好";println!("{}", byte_escape);//输出的内容是// I'm saying// 你好// Windows下的换行符let byte_escape = "I'm saying \r\n 你好";println!("{}", byte_escape);//输出的内容是// I'm saying// 你好// 打印出 \ 本身let byte_escape = "I'm saying \\ Ok";println!("{}", byte_escape);//输出的内容是 I'm saying \ Ok// 强行在字符串后面加个0,与C语言的字符串一致。let byte_escape = "I'm saying hello.\0";println!("{}", byte_escape);//输出的内容是 I'm saying hello.
}
Rust 还支持通过\x输入等值的 ASCII 字符,以及通过\u{}输入等值的 Unicode 字符。
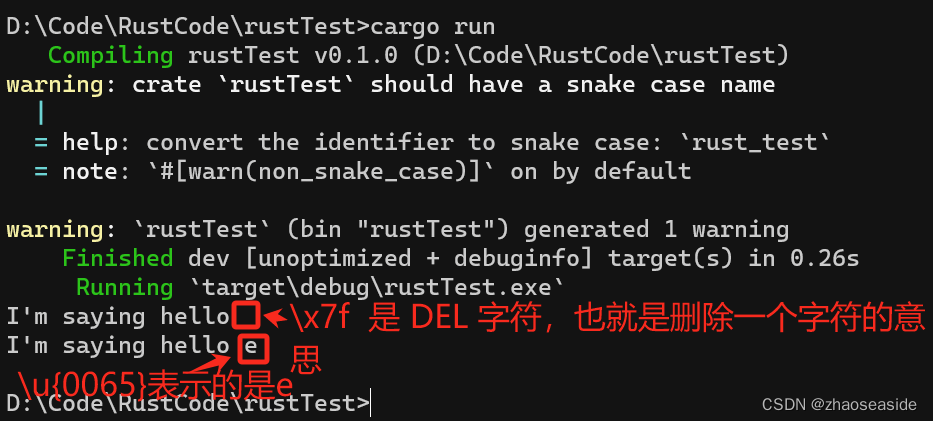
fn main() {// 使用 \x 输入等值的ASCII字符(最高7位)let byte_escape = "I'm saying hello \x7f";println!("{}", byte_escape);// 使用 \u{} 输入等值的Unicode字符(最高24位)let byte_escape = "I'm saying hello \u{0065}"; // 0065表示的是十六进制 65,也是十进制 101println!("{}", byte_escape);
}
禁止转义的字符串字面量
我们要是想输出原始字面量,也就是不进行转义,使用 r""或r#""#把字符串字面量套起来就行了。
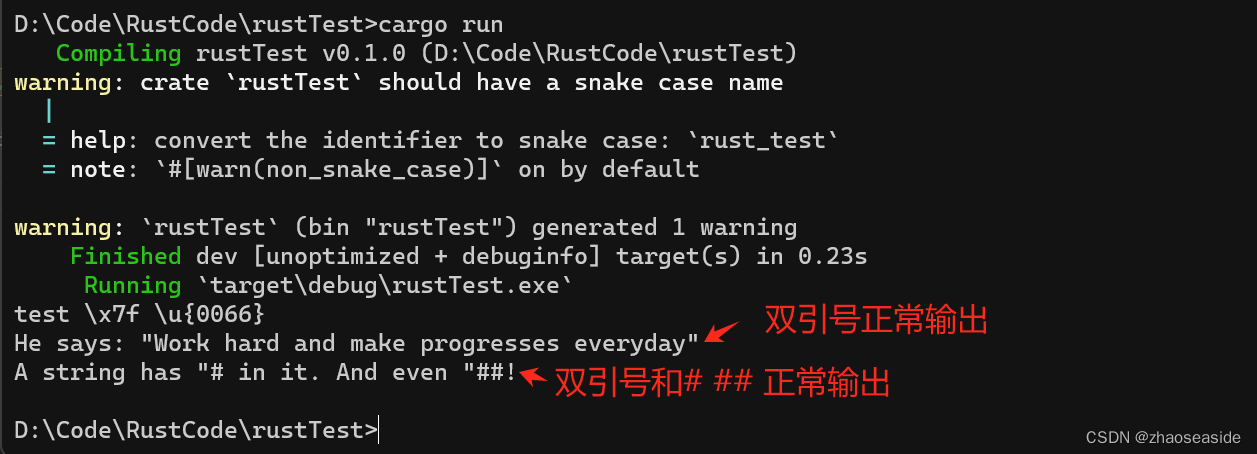
fn main() {// 字符串字面量前面加r,表示不转义let test_str = r"test \x7f \u{0066}";println!("{}", test_str);// 这个字面量必须使用r##这种形式,因为我们希望在字符串字面量里面保留""let test_string = r#"He says: "Work hard and make progresses everyday""#;println!("{}", test_string );// 如果遇到字面量里面有#号的情况,可以在r后面,加任意多的前后配对的#号,// 只要能帮助Rust编译器识别就行let test_string1 = r###"A string has "# in it. And even "##!"###;println!("{}", test_string1);
}
字节串
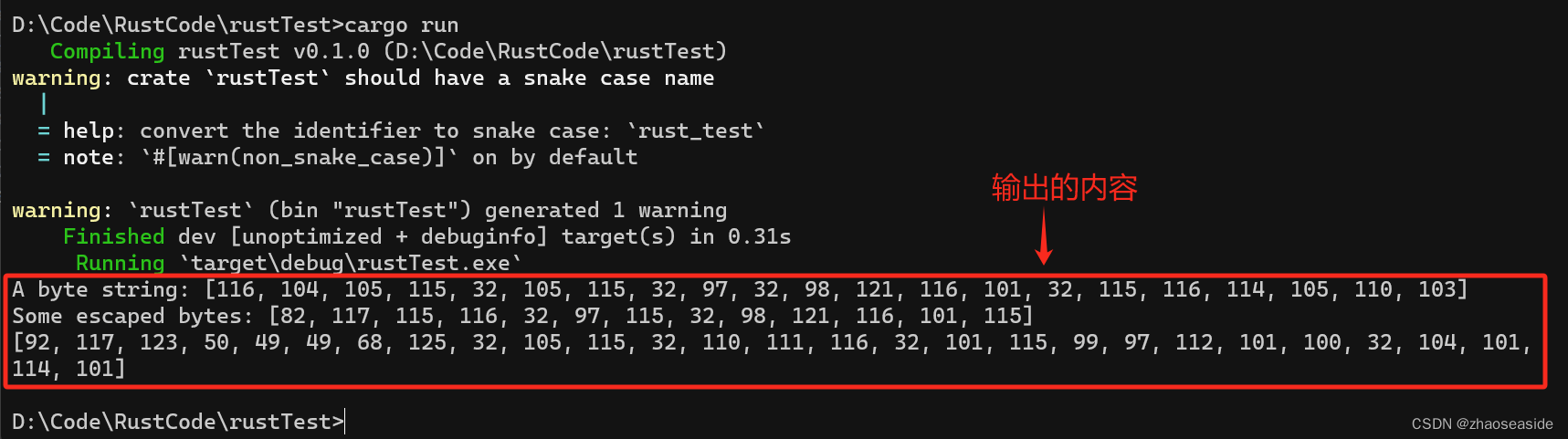
很多时候,我们只需要 ASCII 字符集,字符串字面量中用不到Unicode字符。对于这种问题,Rust 还有一种更紧凑的表示法:字节串。用b开头,双引号括起来,比如b"this is a byte string"。这时候字符串的类型已不是字符串,而是字节的数组 [u8; N],N为字节数。示例代码如下:
fn main() {// 字节串的类型是字节的数组,而不是字符串了let bytestring: &[u8; 21] = b"this is a byte string";println!("A byte string: {:?}", bytestring);// 可以看看下面这串打印出什么let escaped = b"\x52\x75\x73\x74 as bytes";println!("Some escaped bytes: {:?}", escaped);// 字节串与原始字面量结合使用let raw_bytestring = br"\u{211D} is not escaped here";println!("{:?}", raw_bytestring);
}