论文地址:https://arxiv.org/pdf/2312.17617.pdf
代码仓库:https://github.com/quqxui/Awesome-LLM4IE-Papers
信息抽取(IE)旨在从纯自然语言文本中提取结构化知识(如实体、关系和事件)。最近,生成式大型语言模型(LLMs)在文本理解和生成方面展示出了非凡的能力,可以在各个领域和任务中进行泛化。因此,许多研究提出了利用 LLMs 的能力,并基于生成范式为 IE 任务提供可行解决方案。
为了对LLMs在IE任务中的最新进展进行全面系统的回顾和探索,来自中国科学技术大学、香港城市大学和腾讯的研究人员共同撰写了本综述。本综述调查了这一领域中最近的进展,首先通过将这些工作按照不同的IE子任务和学习范式进行分类,提供了广泛的概述,同时对最先进的方法进行了实验分析,并发现了LLMs在IE任务中的新趋势。然后,探讨了一些技术上的insight和值得在未来的研究中进一步探索的方向。此外,作者们还维护了一个公仓库,并持续更新相关资源。
信息抽取是自然语言处理中的一个关键领域,它将纯文本转化为结构化知识。IE是许多下游任务的基础要求,例如知识图谱构建、知识推理和问答。典型的IE任务包括命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)。与此同时,大型语言模型(LLMs)的出现(例如GPT-4、Llama)极大地推动了自然语言处理的发展,它们在文本理解、生成和泛化方面具有强大的能力。因此,近年来对生成式 IE 方法的兴趣大幅增加,这些方法采用 LLMs 生成结构化信息,而不是从纯文本中提取结构化信息。与辨别式方法相比,这些方法在实际场景中可能更加实用,因为它们可以高效处理包含数百万实体的 schema,而不会出现明显的性能下降。
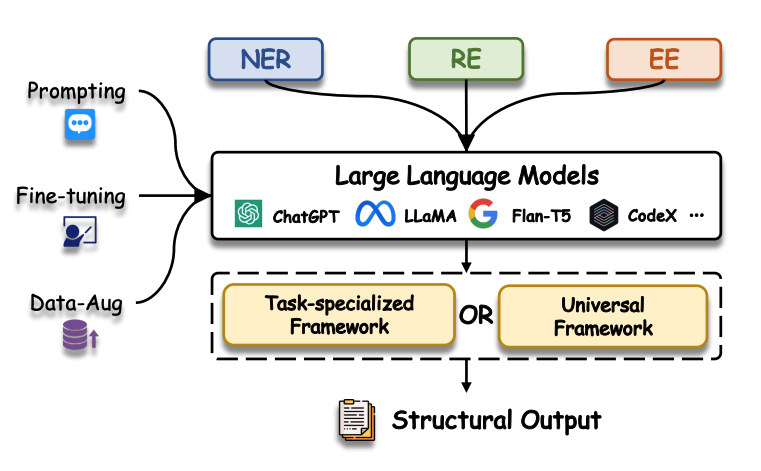
图表 1 LLMs已经广泛应用于生成式信息抽取(IE)的研究中。这些研究涵盖了各种学习范式、多样化的LLM架构以及专门为单个子任务设计的框架,和能够同时处理多个子任务的通用框架。
一方面,LLMs 在各种IE任务的不同场景中吸引了研究人员的极大关注。除了在命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)等单个 IE 任务中表现出色外,LLMs 还具有在通用格式中有效建模各种IE任务的能力。这是通过捕捉任务间的相互依赖关系,并通过指导性提示实现的效果。另一方面,最近的研究表明,LLMs 不仅可以通过微调从IE训练数据中学习,还可以在少样本甚至零样本的情况下,仅依靠上下文示例或指令来提取信息。
然而,对于上述两类研究工作:1)涵盖多个任务的通用框架;2)缺乏训练数据的场景,现有的综述研究并没有充分探索它们。
在这项综述中,我们对大型语言模型(LLMs)用于生成式信息抽取(IE)的研究工作进行了全面的探索。为了实现这一目标,我们主要使用两个分类法对现有的代表性工作进行分类:
(1)IE 子任务的分类法,旨在对使用 LLMs 单独或统一提取的不同类型的信息进行分类;(2)学习范式的分类法,对如何利用LLMs进行生成式IE的各种新方法进行分类。此外,我们还展示了专注于特定领域的研究,以及评估/分析了 LLMs 在 IE 中性能的研究。此外,我们还比较了几种代表性方法在不同设置下的效果,以更深入地了解它们的潜力和局限性,并对利用 LLMs 进行生成式 IE 的挑战和未来方向进行深入分析。据我们所知,这是关于使用 LLMs 进行生成式 IE 的首篇综述。
预备知识
生成式信息抽取任务可以用如下公式概况:
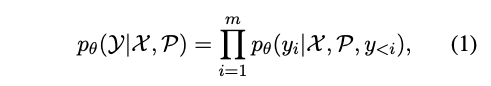
其中 X=[x1, x2, ..., xn] 是待提取的文本序列, Y=[y1, y2, ..., ym] 是目标序列,P 是提示词。
信息抽取主要包括如下三个任务及其子任务:
-
Named Entity Recognition(NER)包括两个任务:Entity Identification和Entity Typing。前者任务涉及识别实体的范围(例如,“Steve”),而后者任务则专注于为这些识别出的实体赋予类型(例如,“PERSON”)。
-
Relation Extraction(RE)在不同的研究中可能有不同的设置。我们根据其他研究使用三个术语进行分类:
(1) Relation Classification指的是对给定的两个实体之间的关系类型进行分类;
(2) Relation Triplet 指的是识别关系类型以及相应的头实体和尾实体范围;
(3) Relation Strict指的是给出正确的关系类型、范围以及头实体和尾实体的类型。
-
Event Extraction(EE)可以分为两个子任务:
(1) Event Detection(在某些研究中也称为事件触发词提取)旨在识别和分类最能清晰表示事件发生的触发词和类型。
(2) Event Arguments Extraction旨在从句子中识别和分类作为事件中特定角色的论元。
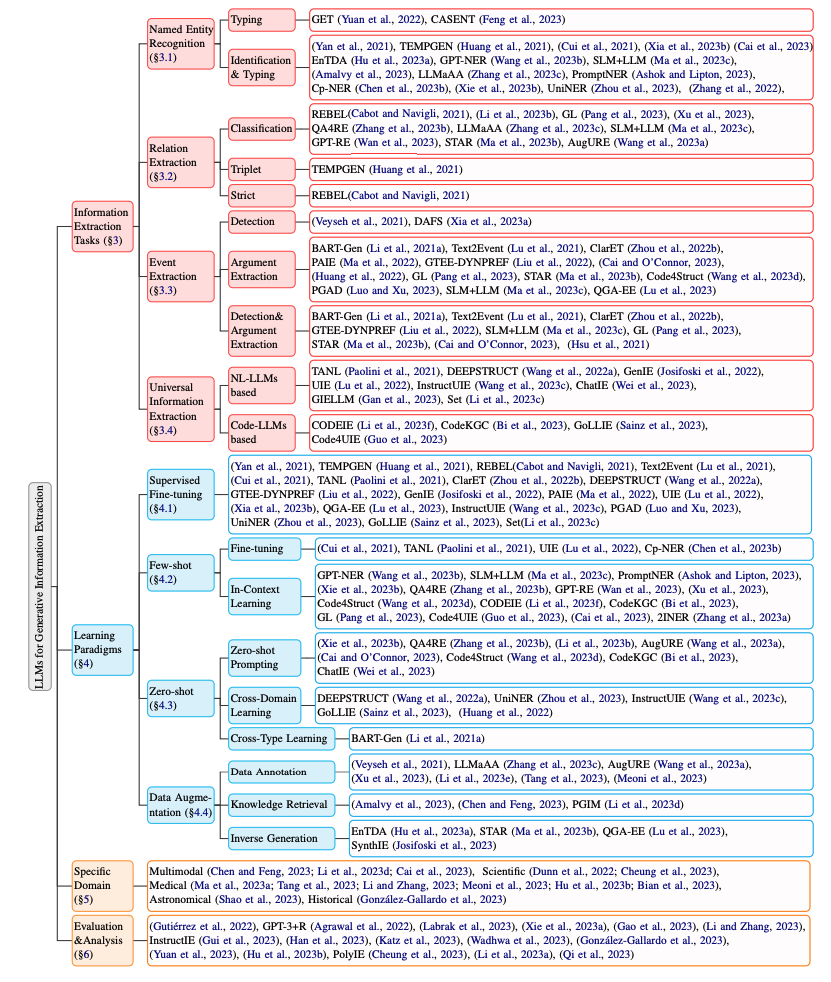
信息抽取任务
论文中首先对信息抽取(IE)的各个子任务涉及的相关技术进行全面介绍。还进行实验分析,评估各种方法在代表性数据集上的性能。
命名实体识别
命名实体识别 (NER) 是信息抽取的一个重要组成部分,可以看作是关系抽取 (RE) 和事件抽取 (EE) 的前身或子任务。这也是自然语言处理领域中的一项基本任务,因此吸引了研究人员的极大关注,以探索 llm 时代的新可能性。
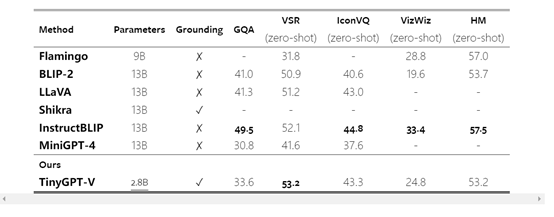
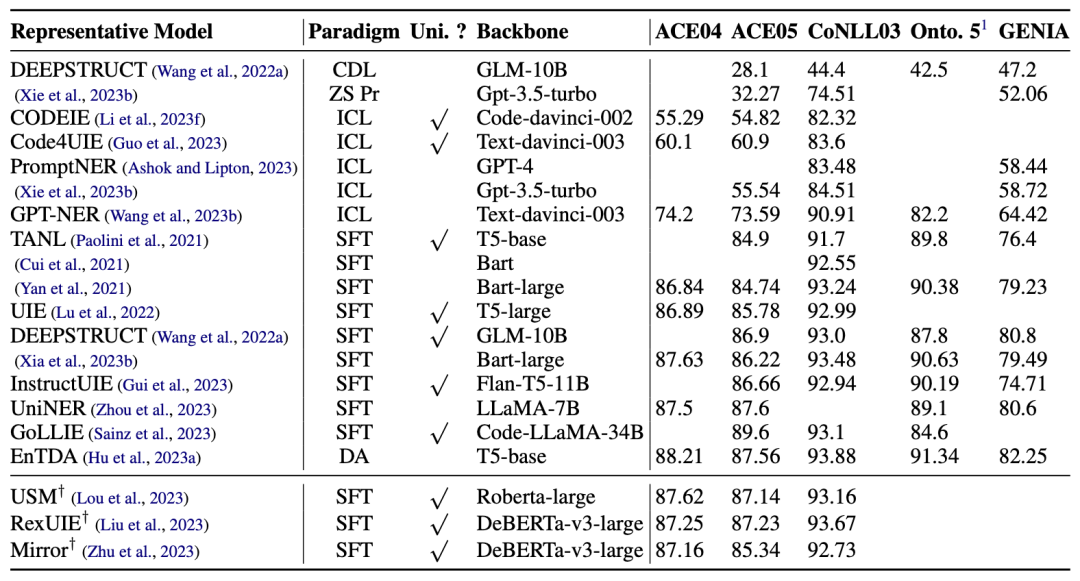
表格 1 中展示了在 5 个主要数据集上的 NER 实验结果对比,我们可以从结果中观察到以下几点:
1) 少样本和零样本范式下的模型与 SFT 和 DA 范式下的模型仍然存在巨大的性能差距。
2) 尽管 backbone 之间的差异不大,但 ICL 范式下的不同方法之间有着明显性能差距。例如,GPT-NER在每个数据集上与其他方法的 F1 值至少有 6% 的差距,最高可达 19%。
3) 与 ICL 范式相比,在 SFT 范式下的不同模型性能只有微小的差异,即使它们的骨干参数可能相差数百倍。
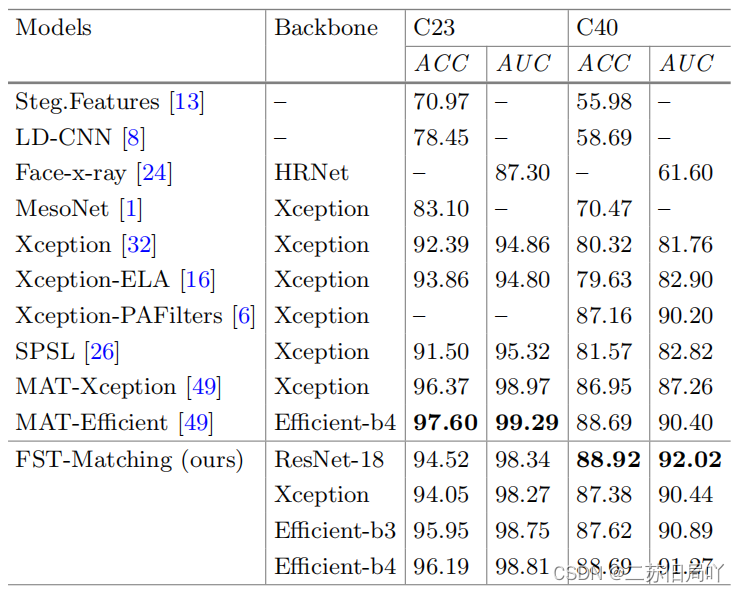
表格 1:命名实体识别(NER)的Micro-F1比较结果。† 表明是判别式模型。我们展示了一些通用IE模型和判别式模型,以供比较。学习范式包括跨域学习(CDL)、零样本提示(ZS Pr)、上下文学习(ICL)、监督微调(SFT)、数据增强(DA)。Uni. ?表示模型是否为通用IE框架。所有后续表的设置都与此格式一致。
关系抽取
关系抽取(RE)在信息抽取中也起着重要作用,正如上文中提到的,在不同的研究中,RE通常有不同的设置。
如表格 2 和表格 3 所示,我们统计发现,由于学习了多种任务之间的依赖关系,通用信息抽取模型通常偏向于解决更难的Relation Strict子任务,而特定任务的方法大多解决较为简单的RE子任务(如Relation Classification)。此外,与 NER 相比,可以发现不同方法在 RE 中的性能差异更为明显,这表明 LLM 在 RE 任务中的潜力仍有很大的挖掘空间。
表格 2:Relation Strict Extraction中的Micro-F1比较结果。† 表明是判别式模型。
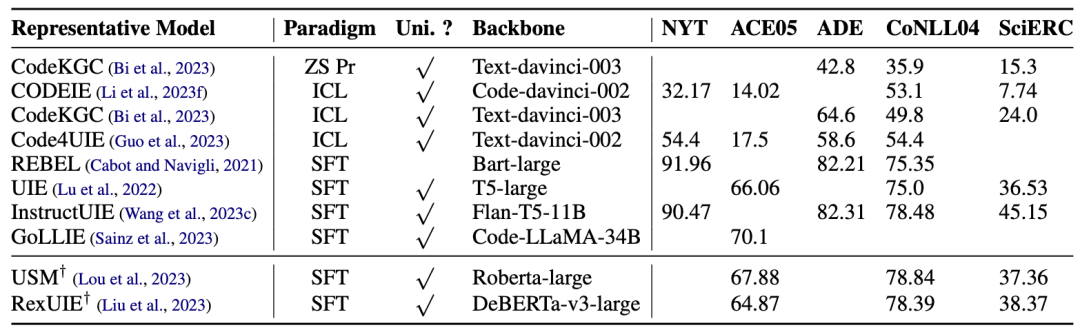
表格 3:Relation Classification中的Micro-F1比较结果。
事件抽取
事件可以定义为在特定环境中发生的具体事件或事故。最近,许多研究旨在通过使用 LLMs 提取事件触发器和论据来理解事件并捕捉它们之间的相关性,这对各种推理任务至关重要。
在表格 4 中,我们收集了最近一些工作在最常用的EE数据集(ACE05)上的实验结果。可以看出,目前绝大多数方法都是基于 SFT 范式的,而使用 LLMs 进行零样本或少样本学习的方法较少。值得注意的是,表格中的生成式方法表现远远优于判别式方法,尤其是在 Arg-C 这一指标上,这表明生成式 LLMs 在 EE 中具有巨大的潜力。
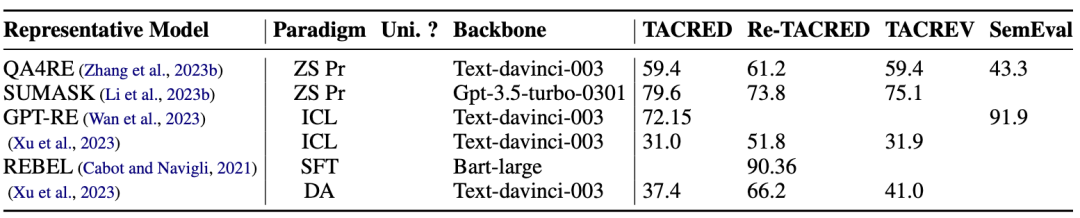
表格 4:事件抽取在ACE05数据集上的实验结果对比。评测任务包括:触发词识别(Trg-I)、触发词分类(Trg-C)、论元识别(Arg-I)和论元分类(Arg-C)。† 表明是判别式模型。
通用信息抽取框架
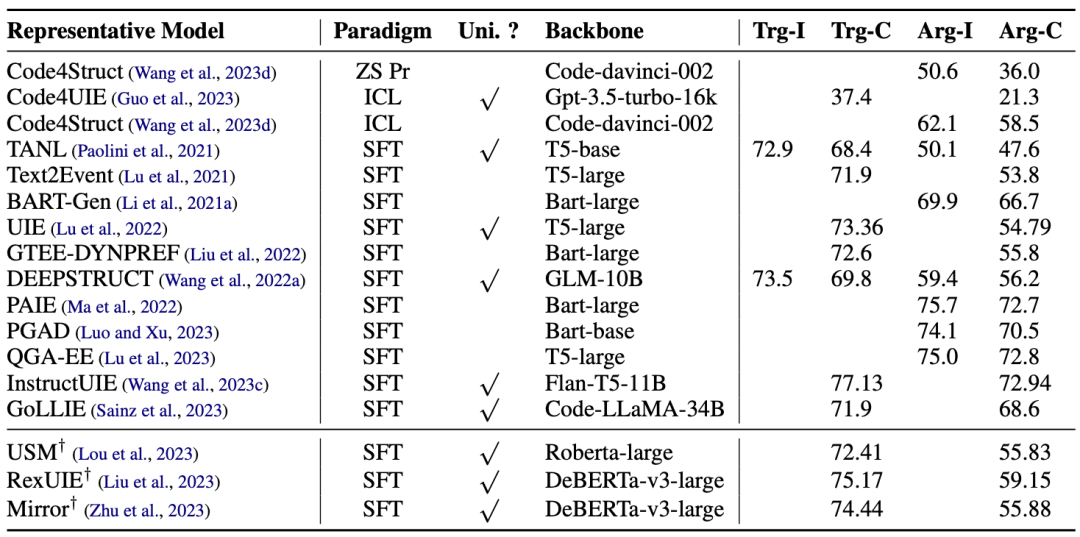
不同的信息抽取(IE)任务高度多样化,具有不同的优化目标和任务特定的模式,因此需要独立的模型来处理大量 IE 任务、设置和场景的复杂性。许多研究仅关注 IE 的一个子任务。然而,最近 LLMs 的进展促进了一些研究工作提出统一的生成式框架。该框架旨在对所有IE任务进行建模,捕捉 IE 的共同能力并学习跨多个任务的依赖关系。我们将通用框架分为两种格式:自然语言(基于NL-LLMs)和代码语言(基于Code-LLMs),以讨论它们如何使用统一的范式对这多个不同的任务进行统一建模,如图所示。
基于自然语言的方法将所有 IE 任务统一到一个通用的自然语言模式中;基于代码的方法通过生成具有通用编程模式的代码输出来统一IE任务。一般来说,NL-LLMs based 的方法在广泛的文本上进行训练,能够理解和生成人类语言,这使得提示和指令更加简洁和易于设计。然而,由于IE任务具有与大模型训练数据不同的独特语法和结构,NL-LLMs 可能难以产生非自然文本的输出。而作为一种形式化语言,代码具有准确表示不同模式下的知识的内在能力,这使得它更适合于结构预测。但是,基于代码的方法通常需要大量的文本来定义一个 Python 类,这反过来限制了上下文的样本大小。
通过实验比较,我们可以观察到,在大多数数据集上,统一的IE模型在命名实体识别(NER)、关系抽取(RE)和实体抽取(EE)任务中优于单个特定任务的模型。
学习范式
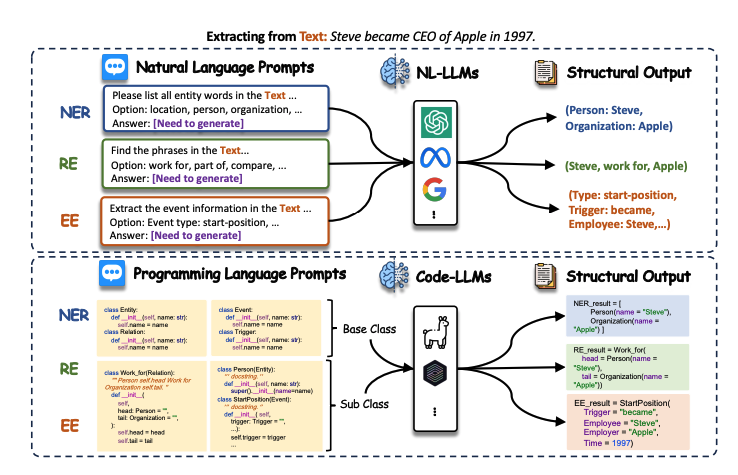
同时,论文根据学习范式对所有方法进行了分类,包括有监督微调(使用标记数据对LLM进行进一步的IE任务训练)、小样本学习(指通过训练或上下文学习从少量标记示例中进行泛化,包括小样本微调和上下文学习)、零样本学习(指在没有获得特定IE任务的训练数据的情况下生成答案,包括零样本提示词设计,跨领域学习,跨类型学习)、以及数据增强(指通过使用LLM对现有数据应用各种转换来增强信息,包括数据标注,知识检索,反向生成),以突出使用LLM进行IE的常用方法。
以数据增强方法为例,数据增强涉及生成有意义且多样化的数据,以有效地增强训练示例或信息,同时避免引入不真实、误导性和偏移的模式。最近LLM在数据生成任务中也展示出了卓越的性能,这引起了许多研究人员使用LLM来生成用于IE的合成数据。如图所示,它可以大致分为三种策略。
1)数据标注 这种策略直接使用LLM生成标注数据。
2)知识检索 这种策略从LLMs中检索相关知识用于辅助IE。
3)反向生成 这种策略使用LLMs根据结构数据生成自然文本或问题,与大模型的训练范式相一致。
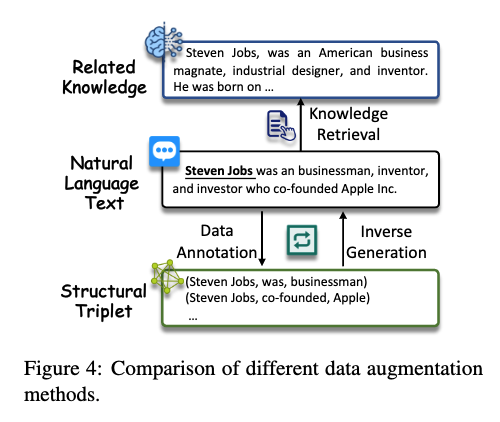
总的来说,这些策略各有优劣。虽然数据标注可以直接满足任务需求,但 LLMs 的结构化生成能力仍需改进。知识检索可以提供关于实体和关系的额外信息,但它存在幻觉问题并引入噪声。反向生成与 LLMs 的问答范式相符,然而,它需要结构化数据,并生成的文本和需要解决的领域之间也可能存在差距。
讨论和未来方向
该团队总结了一些仍待解决的挑战和值得讨论的研究方向:
-
通用信息抽取
以往的生成式 IE 方法和基准往往针对特定领域或任务进行定制,限制了它们的泛化能力。尽管最近提出了一些使用 LLM 的统一方法,但它们仍然存在一定的局限性(例如,长上下文输入限制,结构化输出的不对齐)。因此,进一步发展能够灵活适应不同领域和任务的通用 IE 框架是一个有前景的研究方向。
-
低资源信息抽取
基于 LLM 的生成式 IE 系统在资源有限的场景中仍然面临挑战。有必要进一步探索 LLM 的上下文学习,特别是在改进示例选择方面。未来的研究应考虑发展稳健的跨领域学习技术,例如领域自适应或多任务学习,以利用资源丰富的领域外的知识。此外,还应探索使用 LLM 的高效数据标注策略。
-
高效的提示词设计
设计有效的指令对 LLM 的性能有重要影响。指令设计的一个方面是构建输入和输出对,以更好地与 LLM 的预训练阶段(例如代码生成)对齐。另一个方面是优化指令,以便更好地理解和推理模型(例如思维链),通过鼓励 LLM 进行逻辑推理或可解释的生成。此外,研究人员可以探索交互式指令设计(例如多轮问答),在这种情况下,LLM 可以自动迭代地改进生成的抽取结果或提供反馈。
-
开放式场景信息抽取
在开放式信息抽取中,IE 模型面临更大的挑战,因为它们不提供任何候选标签集,完全依赖模型理解任务的能力。LLM 凭借其知识和理解能力,在某些开放式信息抽取任务中具有显著优势。然而,在更具挑战性的任务中仍然存在性能不佳的情况,需要研究人员进一步探索。



![[Kubernetes]9. K8s ingress讲解借助ingress配置http,https访问k8s集群应用](https://img-blog.csdnimg.cn/direct/103b811397b8408a8d0e0f42def2d89d.png)