文章目录
- 前言
- 数据结构
- 添加与删除操作
- JDK中BitSet源码解析
- 重要成员属性
- 初始化
- 添加数据
- 清除数据
- 获取数据
- size和length方法
- 集合操作:与、或、异或
- 优缺点
前言
为什么称为bitmap?
bitmap不仅仅存储介质以及数据结构不同于hashmap,存储的key和value也不同。
bitmap的key是元素的index,value只有0或者1(具体结构见下文)。
数据结构
Bit-map的基本思想就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此可以很大程度上节省存储空间。
举例:

key-value: bitmap[1] = 1、bitmap[2]=0
添加与删除操作
添加:使用1和key所在位的value进行 |(或)
删除:使用1和key所在位的value进行 &(与)
JDK中BitSet源码解析
位于java.util包中
重要成员属性
/** BitSets are packed into arrays of "words." Currently a word is* a long, which consists of 64 bits, requiring 6 address bits.* The choice of word size is determined purely by performance concerns.* 采用long作为载体,long有8个byte,所以有一个long有64个bit,64这个数字需要6个bit承载*/
private final static int ADDRESS_BITS_PER_WORD = 6;
// 每一个words里面的元素占有64位
private final static int BITS_PER_WORD = 1 << ADDRESS_BITS_PER_WORD;
private final static int BIT_INDEX_MASK = BITS_PER_WORD - 1;
/* Used to shift left or right for a partial word mask */
private static final long WORD_MASK = 0xffffffffffffffffL;
/*** @serialField bits long[]** The bits in this BitSet. The ith bit is stored in bits[i/64] at* bit position i % 64 (where bit position 0 refers to the least* significant bit and 63 refers to the most significant bit).*/
private static final ObjectStreamField[] serialPersistentFields = {new ObjectStreamField("bits", long[].class),
};
/*** The internal field corresponding to the serialField "bits".* bitset的数据载体*/
private long[] words;
/*** The number of words in the logical size of this BitSet.* 表示数组中最多使用的元素个数,也就是最后一个不为 0 的元素的索引加 1;比如[0,4,0,0],数组长度为 4,但是最后一个不为 0 的元素是 1,所以 wordsInUse = 2*/
private transient int wordsInUse = 0;
初始化
创建一个 BitSet 对象时,默认 words 的长度为 1,并且 words[0] = 0。当然也可以用户给定一个具体的容量大小,如下代码:
/**
* BitSet.class
* 创建一个能存储给定数据索引的 BitSet
*/
public BitSet(int nbits) {// 参数合法性判断if (nbits < 0)throw new NegativeArraySizeException("nbits < 0: " + nbits);// 调用 initWords 方法初始化initWords(nbits);sizeIsSticky = true;
}private void initWords(int nbits) {words = new long[wordIndex(nbits-1) + 1];
}
// 得到 bitIndex 对应的 words 下标
private static int wordIndex(int bitIndex) {return bitIndex >> ADDRESS_BITS_PER_WORD;
}
添加数据
public void set(int bitIndex) {// 参数合法性检验if (bitIndex < 0)throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);// 得到对应的数组下标int wordIndex = wordIndex(bitIndex);// 是否要扩容expandTo(wordIndex);// 修改数据words[wordIndex] |= (1L << bitIndex); // 参数检查checkInvariants();
}
private void expandTo(int wordIndex) {int wordsRequired = wordIndex+1;if (wordsInUse < wordsRequired) {// 扩容ensureCapacity(wordsRequired);wordsInUse = wordsRequired;}
}
private void ensureCapacity(int wordsRequired) {if (words.length < wordsRequired) {// Allocate larger of doubled size or required size// 基本上是扩容两倍int request = Math.max(2 * words.length, wordsRequired);words = Arrays.copyOf(words, request);sizeIsSticky = false;}}
注意这里的set(bitIndex)是让二进制的位置为1,并不是让words数组的某一index为1.
扩容的逻辑是:如果需要的长度大于数组的两倍,则扩容到需要的长度。否则,扩容位数组的两倍。
清除数据
public void clear(int bitIndex) {//...int wordIndex = wordIndex(bitIndex);// 如果 wordIndex >= wordsInUse,说明该索引要么不存在,要么一定是 0 ,直接返回即可if (wordIndex >= wordsInUse)return;words[wordIndex] &= ~(1L << bitIndex);recalculateWordsInUse();//...
}
// 修改完可能会引起 wordsInUse 的变化,所以还要调用 recalculateWordsInUse() 重新计算 wordsInUse:从后往前遍历直到遇到 words[i] != 0,修改 wordsInUse = i+1。
private void recalculateWordsInUse() {int i;for (i = wordsInUse-1; i >= 0; i--)if (words[i] != 0)break;wordsInUse = i+1; // The new logical size
}
获取数据
public boolean get(int bitIndex) {if (bitIndex < 0)throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);checkInvariants();int wordIndex = wordIndex(bitIndex);return (wordIndex < wordsInUse)&& ((words[wordIndex] & (1L << bitIndex)) != 0);
}
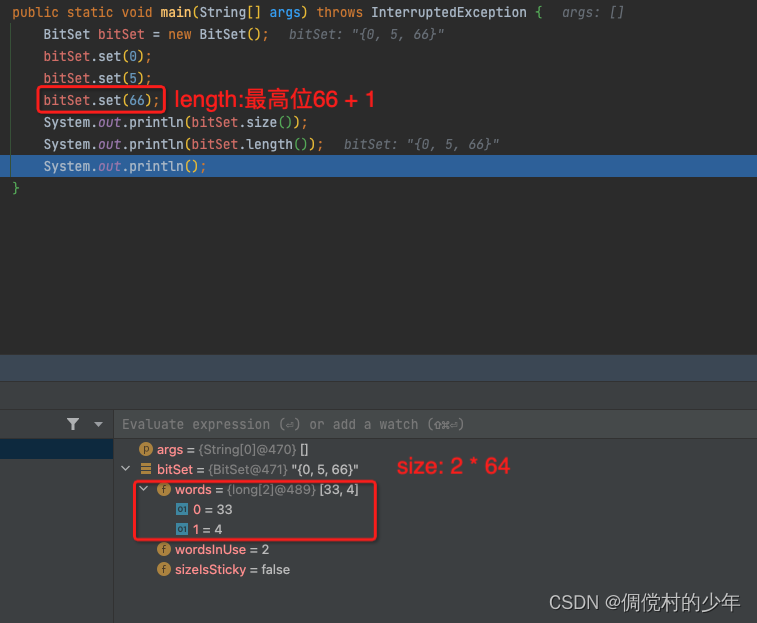
size和length方法
/*** Returns the number of bits of space actually in use by this* {@code BitSet} to represent bit values.* The maximum element in the set is the size - 1st element.** @return the number of bits currently in this bit set*/
public int size() {return words.length * BITS_PER_WORD;
}/*** Returns the "logical size" of this {@code BitSet}: the index of* the highest set bit in the {@code BitSet} plus one. Returns zero* if the {@code BitSet} contains no set bits.* 最高非0位+1** @return the logical size of this {@code BitSet}* @since 1.2*/
public int length() {if (wordsInUse == 0)return 0;return BITS_PER_WORD * (wordsInUse - 1) +(BITS_PER_WORD - Long.numberOfLeadingZeros(words[wordsInUse - 1]));
}
- size方法:words数组的长度 * 64(每个long的长度)
- lenght方法:最高位的1所在位置+ 1
示例:
集合操作:与、或、异或
集合操作还是很常用的,具体不作说明了,自行去看源码。
优缺点
优点:可以大幅减少数据存储空间,适合稠密的数据场景
缺点:当数据稀散的时候,会浪费空间(例如存储1,1000000)
本文就到这里,为了解决普通bitmap的缺点,下一篇将介绍它的变体RoaringBitMap。