文中程序以Tensorflow-2.6.0为例
部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。
截图和程序部分引用自北京大学机器学习公开课
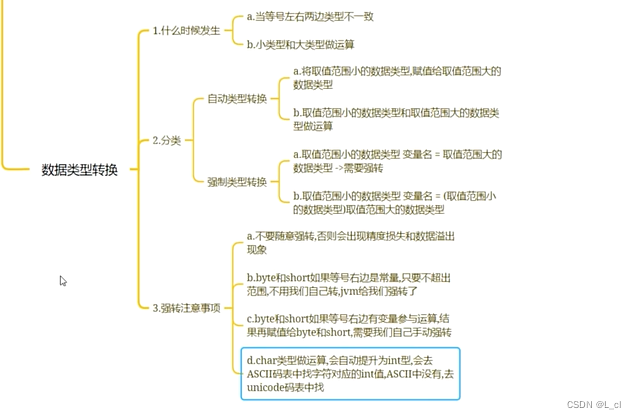
通过学习已经掌握了主要的基础函数之后具备了搭建一个网络并使其正常运行的能力,那下一步我们还需要进一步对网络中的重要节点进行优化并加深认知。
首先我们知道NN(自然神经)网络算法能够相比传统建模类算法发挥更好效果的原因是网络对复杂非线性函数的拟合效果更好,且使用简单。实际应用中通常利用多层神经网络级联来发挥效果。既然涉及到回归和分类问题,不难发现,拟合效果,系统线性还是非线性,拟合结果输入输出结构,如何自动更新参数等等概念,成为了深度学习研究的重中之重。 这篇笔记重点关注优化网络时除了参数优化器以外的其它概念。同时数学概念会相对增加一些。
神经网络复杂度
评价一个网络模型的好坏是多方面的,其中很重要的一点就是看网络的复杂程度。网络完整的计算一次需要的运算次数可以用浮点运算次数(FPLOPs)或者乘加运算次数来表示。通过计算次数可以表示网络的时间复杂度,计算量需要越大的网络,时间复杂度自然越高。
除了时间复杂度,还可以从网络的规模,也就是所有层中总的参数量和输出特征图的数量来表示,网络规模的大小表示了网络的空间复杂度。在ML神经元模型中,单一 一个神经元就含有n+1个参数,其中n个数是上个层的输入,1个偏置系数。而在一个层中可以包含多个神经元。
这里涉及两个概念
- 网络参数量:指网络模型中所有层中总的可变参数(权重参数)数量;
- 特征图:网络在运行过程中,每个层的输出矩阵被称之为这个层的特征图,矩阵的维度大小称为特征图大小。
学习率调整策略
在权重参数反向传播跟新的过程中,学习率是一个直接影响权重跟新变化大小的参数。在权重更新时,最基础的方法是原权重参数减去学习率乘以损失函数梯度 W t + 1 = W t − l r × ∂ l o s s ∂ W t W_{t+1} = W_{t} - lr \times \frac{\partial loss}{\partial W_{t}} Wt+1=Wt−lr×∂Wt∂loss 但是这样的参数更新是线性函数,有时候需要学习的数据呈现复杂的非线性特征,并且网络规模也各不相同,最主要的还是线性函数导致自始至终网络的学习能力(就是参数的跟新效率)是不变的。所以我们希望在损失计算较大时用一个较大学习率更新参数,随着损失的降低能不断地调小学习率,更加精细的调整网络权重。
所以引入指数衰减学习率 D l r = l r × φ N θ Dlr = lr\times \varphi ^{\frac{N}{\theta } } Dlr=lr×φθN 其中Dlr 是当前需要更新计算中使用的学习率,lr是初始学习率,fai是定义的衰减率,N是从开始到当前总的训练次数,sita表示每多少轮衰减一次学习率。根据指数函数性质可以知道要使学习率是下降趋势fai需要取值0到1之间。
import tensorflow as tf
from matplotlib import pyplot as pltw = tf.Variable(tf.constant(5, dtype=tf.float32))epoch = 40
LR_BASE = 0.4 # 最初学习率
LR_DECAY = 0.9 # 学习率衰减率
LR_STEP = 2 # 定义每经过两次BATCH_SIZE后,更新一次学习率
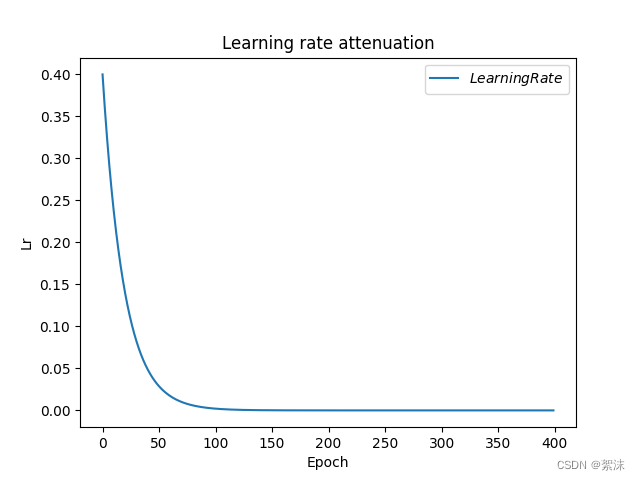
ls_list = []for epoch in range(epoch): # for epoch 定义顶层循环,表示对数据集循环epoch次,此例数据集数据仅有1个w,初始化时候constant赋值为5,循环100次迭代。lr = LR_BASE * LR_DECAY ** (epoch / LR_STEP) # 学习率指数衰减,每两轮衰减一次学习率ls_list.append(lr)with tf.GradientTape() as tape: # with结构到grads框起了梯度的计算过程。loss = tf.square(w + 1)grads = tape.gradient(loss, w) # .gradient函数告知谁对谁求导,这里是loss函数对w求导w.assign_sub(lr * grads) # .assign_sub 对变量做自减,更新参数 即:w -= lr*grads 即 w = w - lr*gradsprint("After %s epoch,w is %f,loss is %f,lr is %f" % (epoch, w.numpy(), loss, lr))plt.title('Learning rate attenuation') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Lr') # y轴变量名称
plt.plot(ls_list, label="$Learning Rate$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend()
plt.show()
可以看到最终结果,随着迭代次数的增加,学习率逐渐逐渐降低,成非线性下降,且下降程度根据学习率衰减率的减小而加快。
除了指数衰减以外,还可以根据迭代次数,设置分段函数的学习率。一般来说使用分段函数,各个段的长度取多少,每段内学习率设置为多少取决于设计者对网络调试的经验,往往难度较高。
# 其它上下文同上一段代码相同
epochs = epoch
for epoch in range(epoch): # for epoch 定义顶层循环,表示对数据集循环epoch次,此例数据集数据仅有1个w,初始化时候constant赋值为5,循环100次迭代。# lr = LR_BASE * LR_DECAY ** (epoch / LR_STEP) # 学习率指数衰减,每两轮衰减一次学习率if epoch < epochs*0.5: # 分段处理lr = 0.4elif epoch < epochs*0.7:lr = 0.2elif epoch < epochs*0.9:lr = 0.1elif epoch < epochs:lr = 0.05
举例设置了分四段的学习率函数

激活函数
在前面的博文中针对神经元只使用了输入权重参数和偏置系数。回顾一下基础的ML神经元模型结构:

其实神经元的输出位置还有一个非线性函数。假如我们不使用这个函数,那么无论网络复合多少层,依然总体上是一个线性函数的组合,所以引入这个函数对于复杂非线性数据的学习显得尤为重要。简而言之,为了提高模型对非线性数据的表达能力,需要添加输出位置的非线性函数。这个函数称之为激活函数。
根据激活函数的用途以及位置特点,一个优秀的激活应该满足:
- 非线性:使用非线性激活函数,并通过多层网络组合,几乎可以拟合所有函数类型。也正是由于非线性激活函数的存在才使得多层网络的深度叠加有了意义。
- 连续单调可导:因为绝大多数参数更新是利用梯度下降法,反向传播过程中从输出层到输入层逐层链式求导,满足连续可导是梯度下降法的要求。同时函数应该单调,最好能是凸函数,这样能使求导后结果正有负,可以更加快速的完成参数更新。
- 近似恒等:指函数输出应该近似等于输入,这样可以避免数据的丢失,并且保证在求和结果很小时依然能有稳定输出值。
在使用激活函数应该注意,对于使用梯度下降法更新参数的网络,适合使用输出是有界的激活函数。当激活函数输出无届时,应该尽量使用小的学习率,避免输出数据爆炸增涨。
常用激活函数
在选择激活函数时有几个简单的规律:
- 首选ReLu函数
- 学习率设置一个较小的数,例如0.01
- 将输入的数据先进行标准归一化,也就是竟可能让数据的值域分布满足均值为0,标准差为1,或者处于[-1,1]之间
- 初始化网络参数时,各层的随机参数可以符合均值为0,方差为 σ = 2 当 前 层 输 入 特 征 个 数 \sigma = \sqrt{\frac{2}{当前层输入特征个数} } σ=当前层输入特征个数2 的标准正态分布
1、Sigmoid函数
f ( x ) = 1 1 + e − x f(x) = \frac{1}{1+e^{-x} } f(x)=1+e−x1 其导数为 f ( x ) ′ = ( 1 1 + e − x ) ′ = − ( − e − x ) ( 1 + e − x ) 2 = 1 1 + e − x × e − x 1 + e − x = f ( x ) × ( 1 − f ( x ) ) f{(x)}' = {( \frac{1}{1+e^{-x} }) } ' =\frac{-(-e^{-x}) }{(1+e^{-x})^{2}}= \frac{1}{1+e^{-x} }\times \frac{e^{-x} }{1+e^{-x} }=f(x)\times (1-f(x)) f(x)′=(1+e−x1)′=(1+e−x)2−(−e−x)=1+e−x1×1+e−xe−x=f(x)×(1−f(x)) (根据“小学一年级数学”,后文函数偏导数可自行计算)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt# 定义 Sigmoid 函数
def sigmoid(x):return 1 / (1 + tf.exp(-x))
# 定义 Sigmoid 函数的导数
def sigmoid_derivative(x):return sigmoid(x) * (1 - sigmoid(x)) # 推导得到的导数公式# 生成 x 值
x_values = np.linspace(-7, 7, 200)
# 计算 Sigmoid 函数在 x_values 上的值
y_sigmoid = sigmoid(x_values)
# 计算 Sigmoid 函数的导数在 x_values 上的值
y_derivative = sigmoid_derivative(x_values)# 绘制 Sigmoid 函数
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(x_values, y_sigmoid, label='Sigmoid Function')
plt.title('Sigmoid Function')
plt.xlabel('x')
plt.ylabel('sigmoid(x)')
plt.grid(True)
plt.legend()
# 绘制 Sigmoid 函数的导数
plt.subplot(1, 2, 2)
plt.plot(x_values, y_derivative, label='Sigmoid Derivative')
plt.title('Sigmoid Derivative')
plt.xlabel('x')
plt.ylabel('sigmoid\'(x)')
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()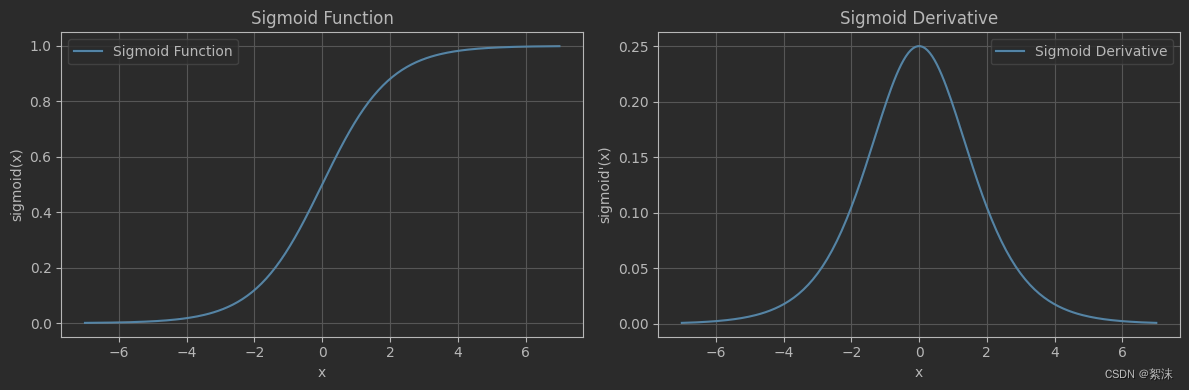
观察sigmoid激活函数的特点可以发现它具有以下特点:
- 容易梯度消失,导数值小于0.25,多次求导后可能导致输出接近0(解决:让激活函数导数值域更大)
- 非0均值,函数均值非0收敛速度会比0均值函数更慢(解决:使用分段函数或奇函数)
- 幂运算会导致计算量大,使训练时间长(解决:钞能力,购买更厉害的显卡和CPU进行训练,👀👻)
2、Tanh函数
f ( x ) = 1 − e − 2 x 1 + e − 2 x f(x)=\frac{1-e^{-2x}}{1+e^{-2x}} f(x)=1+e−2x1−e−2x
# 上下文程序可以根据sigmoid函数部分代码简单修改函数名和画图部分标签名实现
# 定义 tanh 函数
def tanh(x):return tf.math.tanh(x)# 定义 tanh 函数的导数
def tanh_derivative(x):return 1 - tf.math.square(tf.math.tanh(x))
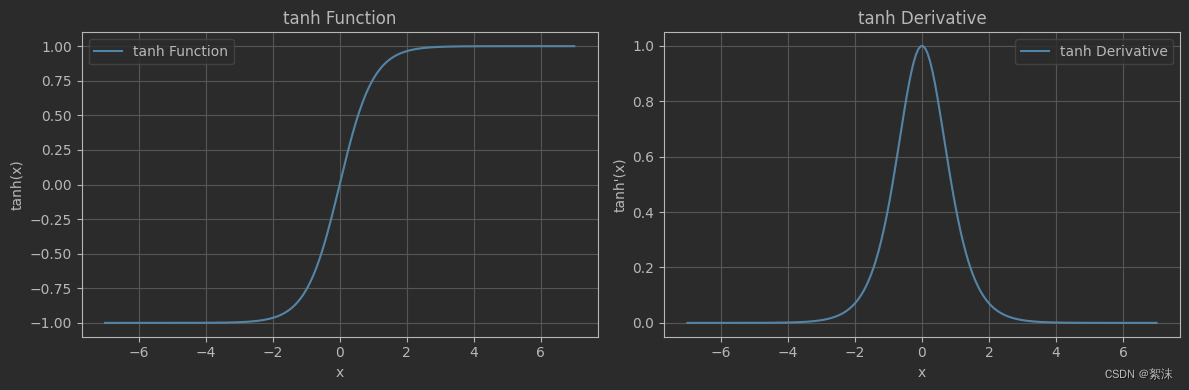
观察函数图像可以知道tanh 函数的输出是0均值(奇函数),但是只有当x属于[-2, 2]的区间内函数导数输出才有一个相对合适的值,其它大部分范围输出接近0,这样同样会造成梯度消失。并且同样使用了幂运算。
3、ReLu函数
f ( x ) = m a x ( x , 0 ) = { 0 x < 0 x x > = 0 f(x)=max(x, 0)= \left\{\begin{matrix} 0 \qquad x<0 \\ x \qquad x>=0 \end{matrix}\right. f(x)=max(x,0)={0x<0xx>=0
# 上下文程序可以根据sigmoid函数部分代码简单修改函数名和画图部分标签名实现
# 定义 ReLU 函数
def relu(x):return tf.nn.relu(x)
# 定义 ReLU 函数的导数
def relu_derivative(x):return tf.where(x > 0, 1.0, 0.0)x_values = np.linspace(-3, 3, 200) # 生成 x 值
y_relu = relu(x_values) # 计算 ReLU 函数的值
y_derivative = relu_derivative(x_values) # 计算导数
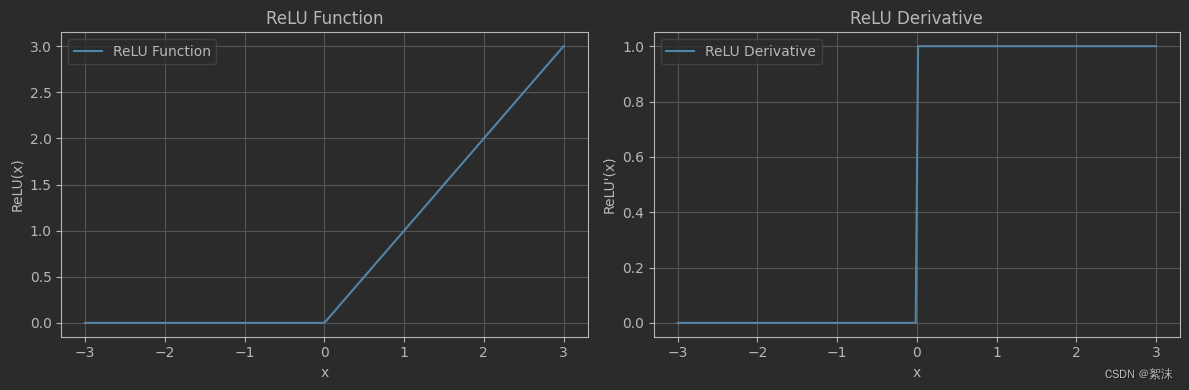
Relu函数则直接使用无界分段函数,首先解决了梯度消失的问题,但是只当输出值大于0时有效。
其次只用判断输出是否大于0,速度快,但是这样会导致训练过程中某些神经元的输出一直是0,这样该神经元参数不更新,失去学习效果,成为神经元死亡(dead relu)。为了解决这个问题往往初始化网络时会使用较多的正值参数,尽可能保证输出值是正数,同时调小学习率。
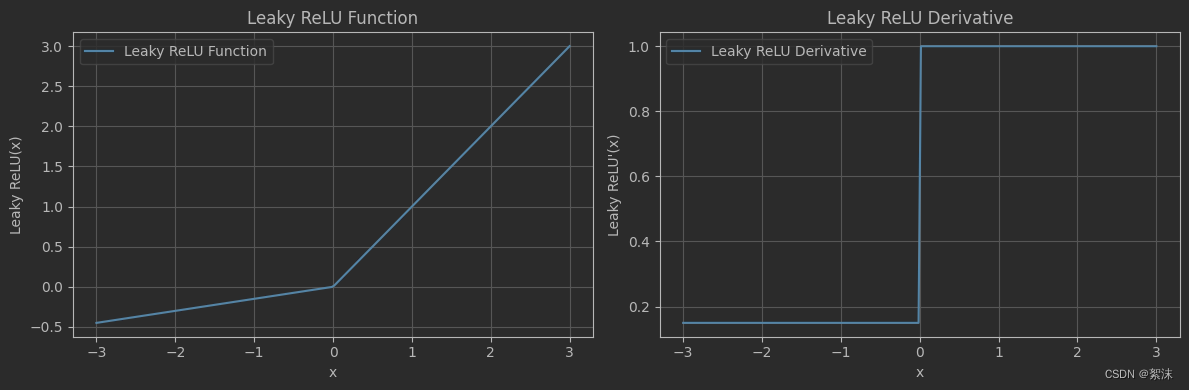
4、LeakyRelu函数
f ( x ) = m a x ( a x , x ) = { a x x < 0 x x > = 0 f(x) = max(ax,x)= \left\{\begin{matrix} ax \qquad x<0 \\ x \qquad x>=0 \end{matrix}\right. f(x)=max(ax,x)={axx<0xx>=0
函数在小于0时使用了一个带参数的一元函数。当a取值合适时,理论上LeakyRelu激活函数将具有Relu的所有优点同时避免其缺点,但是目前还没有严格的被证明LeakyRelu总是优于Relu。自己使用时可以多进行实验找到最合适的激活函数。
# 上下文程序可以根据sigmoid函数部分代码简单修改函数名和画图部分标签名实现
# 定义 Leaky ReLU 函数 其中alpha为小于0时的斜率系数,通常应用时这个值取0.02等较小的数
def leaky_relu(x, alpha=0.15):return tf.nn.leaky_relu(x, alpha)# 定义 Leaky ReLU 函数的导数
def leaky_relu_derivative(x, alpha=0.15):return tf.where(x > 0, 1.0, alpha)x_values = np.linspace(-3, 3, 200)
y_leaky_relu = leaky_relu(x_values)
y_derivative = leaky_relu_derivative(x_values)
损失函数(Loss)
损失函数计算的是计算得到的输出值和已知标签(正确答案)之间的差距
结合之前的介绍,我们知道反向传播的过程中需要使损失函数最小化,不同的损失函数会对网络的跟新和输出趋势产生影响。可以理解为损失函数的值直接影响着反向传播参数的更新(所以反向传播就类似于控制系统中的反馈控制,损失函数就类似反馈回路的传递函数)。所以损失函数的设计十分重要。
常用的损失函数
1、MSE均方误差
M S E ( Y , Y ^ ) = ∑ i = 1 n ( Y i − Y i ^ ) 2 n MSE(Y,\hat{Y} ) = \frac{\sum_{i=1}^{n}(Y_i - \hat{Y_i})^{2} }{n} MSE(Y,Y^)=n∑i=1n(Yi−Yi^)2
均方误差就是所有实际值和计算输出值差的平方的平均值。均方误差应用最多的领域就是计算回归问题。使用均方误差可以很快的找到数据中的规律性,实现网络的回归拟合。
import numpy as np
import tensorflow as tf
np.random.seed(42) # 设置随机数种子
true_values = np.random.randint(0, 10, 100) # 生成两组随机数
predicted_values = true_values + np.random.normal(0, 2, 100)# 转换为 TensorFlow 的张量
true_values_tensor = tf.constant(true_values, dtype=tf.float32)
predicted_values_tensor = tf.constant(predicted_values, dtype=tf.float32)# 计算均方误差 (MSE)
# 使用 tf.reduce_mean(平均数) 和 tf.square(平方)计算MSE
mse = tf.reduce_mean(tf.square(true_values_tensor - predicted_values_tensor)) # 输出 MSE 的值
print("Mean Squared Error (MSE):", mse.numpy())
2、CE交叉熵损失
H ( Y , Y ^ ) = − ∑ Y i ^ × l n Y i H(Y,\hat{Y} ) = -\sum \hat{Y_i}\times lnY_i H(Y,Y^)=−∑Yi^×lnYi 上式中Y表示真实值的概率,Y一巴表示网络计算的输出值的概率。
交叉熵表征两个概率分布之间的距离,交叉熵越小说明二者分布越接近。交叉熵的计算考虑了真实数据的概率分布,相比MSE交叉熵有一定的加权效果。除了回归问题,交叉熵则广泛应用在分类和迁移学习上。要注意的一点是,在网络的输出中往往最终输出的结果不符合概率分布,所以需要配合softmax函数一起使用。其原理可以看深度学习笔记(四)——softmax,一般流程值网络计算得到输出张量,经过softmax后转化为概率分布矩阵,随后计算CE。
import numpy as np
import tensorflow as tf
# 生成两组数据 y_ 已经符合概率分布要求,y 可以认为是网轮的输出矩阵
y_ = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 0, 0], [0, 1, 0]])
y = np.array([[12, 3, 2], [3, 10, 1], [1, 2, 5], [4, 6.5, 1.2], [3, 6, 1]])
y_pro = tf.nn.softmax(y) # 计算输出数据的概率分布
loss_ce1 = tf.losses.categorical_crossentropy(y_,y_pro) # 计算交叉熵
loss_ce2 = tf.nn.softmax_cross_entropy_with_logits(y_, y) # 复合了softmax和交叉熵计算的函数print('分步计算的结果:\n', loss_ce1)
print('结合计算的结果:\n', loss_ce2)
提示:如果你的环境是tensorflow2.6.0,且安装步骤是按照前面几篇笔记来的,那你可能会遇到这一行代码报错tf.losses.categorical_crossentropy,请终端在对应虚拟环境中执行pip install keras==2.6即可
3、自定义损失函数
根据具体任务和目的,可设计不同的损失函数。例如,我们可以看目标检测中的多种损失函数。目标检测的主要功能是定位和识别,损失函数的功能主要就是让定位更精确,识别准确率更高。目标检测任务的损失函数由分类损失(Classificition Loss)和回归损失(Bounding Box Regeression Loss)两部分构成。近几年来回归损失主要有Smooth L1 Loss(2015), IoU Loss(2016 ACM), GIoU Loss(2019 CVPR), DIoU Loss & CIoU Loss(2020AAAI)等,分类损失有交叉熵、softmax loss、logloss、focal loss等。主要是认识到:需要时,得针对特定的背景、具体的任务设计损失函数。
欠拟合和过拟合
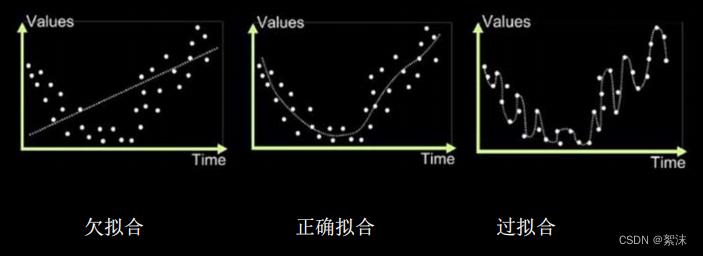
上面这幅图很好的表达了三种拟合情况的区别,欠拟合时网络判断能力不够,无法输出正确结果,过拟合时网络陷入局部最优,失去了泛化能力,容易把相同但只有细微差别的输入数据判断为两种情况。拟合的好坏决定了训练好的模型迁移到新的环境中对新数据输出的准确程度。良好的模型训练过程应该避免欠拟合与过拟合的出现。
解决欠拟合的方法:
- 扩大数据的特征数量(学习更多的细节)
- 增加网络的参数和网络的层数(提高学习和理解能力)
- 减少正则化参数(降低学习的复杂程度)
解决过拟合的方法:
- 清洗输入数据(让学习的数据特征更明显,噪声更少,押题战术)
- 增大训练数据集(学习更多的样本,题海战术)
- 使用正则化(提高复杂度和计算量,回归基础,认识特征)
- 增大正则化参数(上强度,深挖概念,排除错误选项)
正则化方法
正则化是用于缓解训练过程中出现过度拟合的一种有效手段。通过正则化可以在损失函数中引入模型的复杂度指标,也就是在原有损失函数计算的基础上,进一步的给权重参数加权。正则化的方式通常有两种:L1正则和L2正则,其中L1正则为: l o s s L 1 ( W ) = ∑ i ∣ W i ∣ loss_{L1}(W) = \sum_{i}^{}\left | W_i \right | lossL1(W)=i∑∣Wi∣ L2正则为: l o s s L 2 ( W ) = ∑ i ∣ W i 2 ∣ loss_{L2}(W) = \sum_{i}^{}\left | W_i^{2} \right | lossL2(W)=i∑∣∣Wi2∣∣ 正则化计算得到的损失函数为: l o s s = l o s s ( Y , Y ^ ) + R e g u l a r i z e r × l o s s ( W ) loss = loss(Y,\hat{Y} ) + Regularizer \times loss (W) loss=loss(Y,Y^)+Regularizer×loss(W) 其中等式右边第一项loss计算输出值和真实值的损失,第二项的Regularizer 为正则化的权重系数,第二个loss则计算需要正则的参数w。
使用正则化时,L1正则会将较多的参数变为0,所以该方法可以稀疏参数,减少非0的参数数量,降低模型的复杂度。
L2正则由于使用平方计算,会使参数接近0但不等于0,这个方法可以减小部分参数的权重(反应为参数变小),降低模型的复杂度。
抽象一点理解,加入了正则化,局部计算就难以过度拟合,可以让模型的拟合效果变的更加平滑。
正则化拟合示例
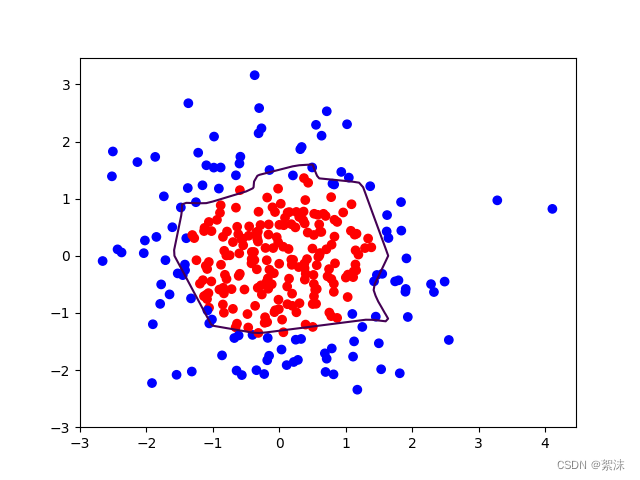
1、无正则
# @ 引用自:北京大学-《人工智能实践》-曹建
# 导入所需模块
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd# 读入数据/标签 生成x_train y_train
df = pd.read_csv('dot.csv')
x_data = np.array(df[['x1', 'x2']])
y_data = np.array(df['y_c'])x_train = np.vstack(x_data).reshape(-1, 2)
y_train = np.vstack(y_data).reshape(-1, 1)Y_c = [['red' if y else 'blue'] for y in y_train]# 转换x的数据类型,否则后面矩阵相乘时会因数据类型问题报错
x_train = tf.cast(x_train, tf.float32)
y_train = tf.cast(y_train, tf.float32)# from_tensor_slices函数切分传入的张量的第一个维度,生成相应的数据集,使输入特征和标签值一一对应
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)# 生成神经网络的参数,输入层为2个神经元,隐藏层为11个神经元,1层隐藏层,输出层为1个神经元
# 用tf.Variable()保证参数可训练
w1 = tf.Variable(tf.random.normal([2, 11]), dtype=tf.float32)
b1 = tf.Variable(tf.constant(0.01, shape=[11]))w2 = tf.Variable(tf.random.normal([11, 1]), dtype=tf.float32)
b2 = tf.Variable(tf.constant(0.01, shape=[1]))lr = 0.005 # 学习率
epoch = 800 # 循环轮数# 训练部分
for epoch in range(epoch):for step, (x_train, y_train) in enumerate(train_db):with tf.GradientTape() as tape: # 记录梯度信息h1 = tf.matmul(x_train, w1) + b1 # 记录神经网络乘加运算h1 = tf.nn.relu(h1)y = tf.matmul(h1, w2) + b2# 采用均方误差损失函数mse = mean(sum(y-out)^2)loss = tf.reduce_mean(tf.square(y_train - y))# 计算loss对各个参数的梯度variables = [w1, b1, w2, b2]grads = tape.gradient(loss, variables)# 实现梯度更新# w1 = w1 - lr * w1_grad tape.gradient是自动求导结果与[w1, b1, w2, b2] 索引为0,1,2,3 w1.assign_sub(lr * grads[0])b1.assign_sub(lr * grads[1])w2.assign_sub(lr * grads[2])b2.assign_sub(lr * grads[3])# 每20个epoch,打印loss信息if epoch % 20 == 0:print('epoch:', epoch, 'loss:', float(loss))# 预测部分
print("*******predict*******")
# xx在-3到3之间以步长为0.01,yy在-3到3之间以步长0.01,生成间隔数值点
xx, yy = np.mgrid[-3:3:.1, -3:3:.1]
# 将xx , yy拉直,并合并配对为二维张量,生成二维坐标点
grid = np.c_[xx.ravel(), yy.ravel()]
grid = tf.cast(grid, tf.float32)
# 将网格坐标点喂入神经网络,进行预测,probs为输出
probs = []
for x_test in grid:# 使用训练好的参数进行预测h1 = tf.matmul([x_test], w1) + b1h1 = tf.nn.relu(h1)y = tf.matmul(h1, w2) + b2 # y为预测结果probs.append(y)# 取第0列给x1,取第1列给x2
x1 = x_data[:, 0]
x2 = x_data[:, 1]
# probs的shape调整成xx的样子
probs = np.array(probs).reshape(xx.shape)
plt.scatter(x1, x2, color=np.squeeze(Y_c)) # squeeze去掉纬度是1的纬度,相当于去掉[['red'],[''blue]],内层括号变为['red','blue']
# 把坐标xx yy和对应的值probs放入contour函数,给probs值为0.5的所有点上色 plt.show()后 显示的是红蓝点的分界线
plt.contour(xx, yy, probs, levels=[.5])
plt.show()
2、加入L2正则后:
# 接上一段程序,修改43行到46行为下面的 正则化计算# 采用均方误差损失函数mse = mean(sum(y-out)^2)loss_mse = tf.reduce_mean(tf.square(y_train - y))# 添加l2正则化loss_regularization = []# tf.nn.l2_loss(w)=sum(w ** 2) / 2loss_regularization.append(tf.nn.l2_loss(w1))loss_regularization.append(tf.nn.l2_loss(w2))# 求和# 例:x=tf.constant(([1,1,1],[1,1,1]))# tf.reduce_sum(x)# >>>6loss_regularization = tf.reduce_sum(loss_regularization)loss = loss_mse + 0.03 * loss_regularization # REGULARIZER = 0.03
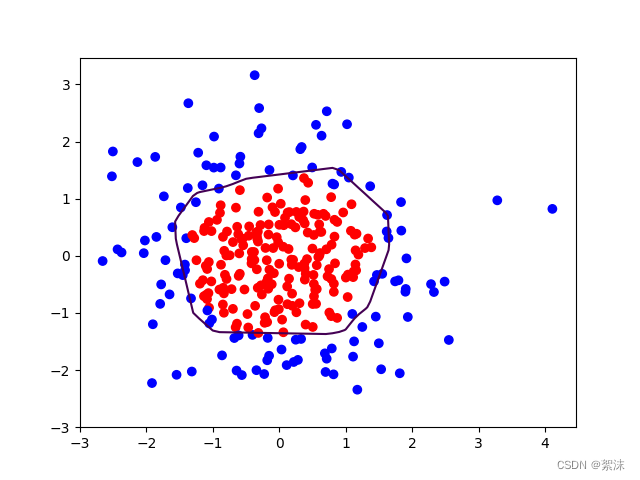
不难看出使用了正则化后参数的拟合变得更加平滑。