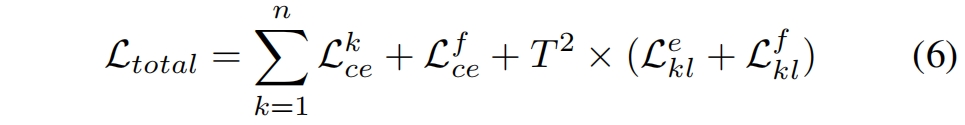【现代密码学】笔记3.1-3.3 --规约证明、伪随机性《introduction to modern cryphtography》
- 写在最前面
- 私钥加密与伪随机性 第一部分
- 密码学的计算方法论
- 计算安全加密的定义:对称加密算法
- 伪随机性
- 伪随机生成器(PRG)
- 规约法
- 规约证明
- 构造安全的加密方案
写在最前面
主要在 哈工大密码学课程 张宇老师课件 的基础上学习记录笔记。
内容补充:骆婷老师的PPT
《introduction to modern cryphtography》–Jonathan Katz, Yehuda Lindell(现代密码学——原理与协议)中相关章节
密码学复习笔记 这个博主好有意思
B站视频 密码学原理《Introduction to modern Cryptography》
初步笔记,如有错误请指正
快速补充一些密码相关的背景知识

私钥加密与伪随机性 第一部分
在本节课程中,我们学习计算安全下的私钥加密和伪随机性的第一部分。我们会学习一个完整的现代密码学研究过程,从定义到假设,再到一个密码学方案,最后使用规约法来证明其安全性。
目录:密码学的计算方法论,计算安全加密的定义,伪随机性,规约法,构造安全的加密方案
密码学的计算方法论
-
计算安全思想
- 完美保密局限性在于密钥需要很长,而且如果密钥不够长,则不能达到完美保密。Kerchhoffs提出另一个原则:一个加密方案如果不是数学上,那必须是实践上不可破解的。 不同于在完美保密部的信息论上的安全,计算安全放松了安全条件来追求实践中的安全,使得密钥相对于明文可以很短。
- 计算安全:
- 敌手在可行的时间内运行,破解密码的时间是有限的
- 敌手以非常小的概率成功,能成功但可能性很小
-
放松条件的必要性
为什么相对于完美保密,要放松对安全的需求。考虑之前的不可区分实验,
- 为了对抗蛮力攻击,需要限定敌手的能力;因为只要给了充足的时间来遍历 ∣ K ∣ |\mathcal{K}| ∣K∣,蛮力攻击一定会成功;
- 为了对抗随机猜测,需要允许小到可忽略的(negligible)成功概率;因为瞎猜也有 1 / ∣ K ∣ 1/|\mathcal{K}| 1/∣K∣概率成功;
-
具体法与渐进法
- 具体法:限定时间和成功的概率为具体值;一个加密方案是 ( t , ε ) (t,\varepsilon) (t,ε)-安全的,如果对任意敌手以时间 t t t 运行,成功破解方案的概率最多是 ε \varepsilon ε。
- 具体法的问题是缺乏规律性,无法描述密钥长度、时间和成功概率之间的关系。
- 渐进法:计算复杂性理论使用是与输入规模 n n n有关的函数来表示时间或空间复杂性。例如,快速排序算法的时间复杂性是 O ( n ⋅ log n ) O(n\cdot \log n) O(n⋅logn),其中 n n n是问题的规模,这里是排序元素的个数。
- 具体法和渐进法的区别之一是,一个是点,一个是线。
-
P=NP?
- 如何定义“可行的时间”和“非常小的概率”?答案来自计算复杂性理论,理论上认为一个搜索问题(例如,获得密钥)是相对简单的,如果解决该问题算法的时间复杂性为问题规模参数 n n n的多项式;而需要非多项式(包括指数)时间复杂性来解决的问题是难以被实际解决的。
- 在计算复杂性理论中,问题可分为两类:
- 一类可解的问题,称为P(polynomial time)问题,是指能够在问题规模的多项式时间内由确定性图灵机解决的问题;
- 另一类包含P问题的更大范围的NP(nondeterministic polynomial time)问题,不能确定是否在多项式时间内可以解决,但能够在多项式时间内验证一个答案是否正确的问题;尽管理论上用非确定性图灵机可在多项式时间解决,但非确定性图灵机还无法实现;
- 在NP问题中,包含一类相似的难题,尚未找到多项式时间算法,但这些问题中的一个若被解决了,则其它也能被解决,称为NP完全问题(NP-Complete);与NP完全问题一样难或更难的问题,称为NP难问题(NP-Hard);
- 科学家们相信NP问题集合不同于P问题集合,在NP问题中有一些难题无法在多项式时间内解决,即P ≠ \neq =NP;
- 在一部穿越电视剧《天才基本法》中,一个情节是:P=NP被证明真成立。
- 加密与计算复杂性:1955年,约翰·纳什在其给NSA的信中说,他猜测破解一个复杂的代码需要密钥长度指数的时间。如果如此,则意味着P ≠ \neq =NP,因为解决问题所需时间不是多项式的,而验证答案是多项式的。
- 因此,将多项式时间认为是“可行的时间”,而非多项式的指数时间被认为是“不可行的”;
- 非常小的概率定义为,比任何多项式分之一都小。
-
有效的计算
- 一个算法是多项式时间的(polynomial time),如果存在一个多项式使得对于任意输入,算法都在该多项式步骤内结束。
- 一个算法可以在多项式时间内以任何多项式时间算法作为子例程来运行;
- 概率(probabilistic)算法有“掷硬币”的能力。其中,随机数生成器应该是为密码学用途来设计的,而不是C语言里的
random()。相反地,没有随机性的算法就是确定性的; - 开放问题:概率性的敌手比确定性的敌手更强大吗? P = B P P \mathcal{P} = \mathcal{BPP} P=BPP (限定错误的概率多项式)?
-
可忽略的成功概率
- 一个函数 f f f是可忽略的,若对于任意多项式 p ( ⋅ ) p(\cdot) p(⋅),存在一个 N N N使得对于所有整数 n > N n>N n>N, f ( n ) < 1 p ( n ) f(n) < \frac{1}{p(n)} f(n)<p(n)1。
-
渐进方法(Asymptotic)
- 根据上面的基础,采用渐进方法来定义安全,所谓“渐进”是指不研究一个参数固定的问题的复杂性,而是研究时间复杂性随着问题参数 n n n的变化而变化的规律;
- 问题X(破解加密方案)是难的,若X不能由任何多项式时间算法以时间 t t t解决,除非以可忽略的概率 ε \varepsilon ε;
- t t t和 ε \varepsilon ε都描述为安全参数 n n n(通常是密钥长度)的函数;
- 注意:安全是对足够大的 n n n值来说的;
- 例如,例子中随着 n n n的增加,破解的复杂性随密钥空间指数增加,加密方案更难破解。
计算安全加密的定义:对称加密算法
-
定义私钥加密方案
- 回顾私钥加密相关定义

-
窃听不可区分实验
- 在窃听不可区分实验中,敌手和挑战者之间进行一个思维实验。敌手根据安全参数产生两个相同长度的不同消息,并发送给挑战者;挑战者根据安全参数生成密钥,并对随机选择的一个消息进行加密,将挑战密文发送给敌手。敌手输出一个比特,来表示对被加密消息的猜测,若猜对,则实验成功。
- 一个敌手 A \mathcal{A} A与一个挑战者 C \mathcal{C} C进行3轮交互:
- A \mathcal{A} A选择两个长度相同、内容不同明文 m 0 , m 1 m_0, m_1 m0,m1,并发送给 C \mathcal{C} C;
- C \mathcal{C} C根据密钥生成算法生成一个新密钥 k k k,随机生成一个比特 b b b并挑选一个明文 m b m_b mb,加密 E n c k ( m b ) \mathsf{Enc}_k(m_b) Enck(mb)后得到挑战密文 c c c,并发送给 A \mathcal{A} A;
- A \mathcal{A} A输出对所加密明文的猜测 b ′ b' b′,若 b = b ′ b=b' b=b′,则 A \mathcal{A} A成功;否则,失败;
- 这与之前在完美保密中的不可区分实验类似的,区别在于本实验不是无条件的,而是输入“安全参数”,该参数将作用于安全定义。窃听不可区分实验既用在了信息论安全定义,也用在了计算安全定义,这就在两者之间建立了联系。

-
私钥加密安全定义
- 一个加密方案在出现窃听者时是不可区分加密,若对于任意概率多项式时间的敌手,存在一个可忽略函数,使得不可区分实验成功概率与1/2相比(两者间的差异)是可忽略的。
- 其中,多项式时间和可忽略都是对于“安全参数”的函数。
-
理解不可区分性的定义
- 一次一密方案在出现窃听者时是否是不可区分的?
- 若一个敌手一直在实验中失败,该方案是安全的吗?
- 在两个连续窃听不可区分实验中,使用同一个密钥的概率有多大?
- 若从密文中猜测到消息中最低比特的概率是3/4,该方案是安全的吗?
- 若从密文中猜测到消息中最低3个比特的概率是3/8,该方案是安全的吗?
- 相关性: X X X和 Z Z Z的分布不可区分, Y Y Y和 Z Z Z的分布不可区分,那么 X X X和 Y Y Y的分布是不可区分的吗?
-
语义安全(semantic security)
- 之前在导论部分有一个问题:如何定义不泄漏“meaningful”的信息。下面引入语义安全的概念来解决这个问题。
- 直觉:没有关于明文的任何有意义的信息泄漏
- 关于明文的信息用明文的函数来表示, h ( m ) h(m) h(m)表示敌手预先了解的关于明文的外部信息, f ( m ) f(m) f(m)表示敌手希望获取的关于明文的有意义的信息
- 定义:加密方案是窃听者出现时语义安全的,如果对于任意敌手,任意明文分布,任意函数 f f f和 h h h,一个敌手根据密文和 h ( m ) h(m) h(m)获得 f ( m ) f(m) f(m),另一个敌手只根据 h ( m ) h(m) h(m)获得 f ( m ) f(m) f(m),这两个敌手成功的概率之间的差异是可以忽略的
- 定理:一个私钥加密方案是窃听者不可区分的,当且仅当该方案是语义安全的。
- 证明略。直觉上,从右到左:若敌手能够在不可区分实验中成功(不是不可区分的),则意味着根据密文获得了关于区分明文的某些信息(不是语义安全);反之,若敌手能够获得关于明文的某些信息(不是语义安全),那么可以利用这些信息来区分明文(不是不可区分的)。
伪随机性
-
伪随机性概念(Pseudorandomness)
- 回顾之前完美保密的局限性,密钥长度需要和明文一样长才安全;计算安全中放松了安全的定义,那密钥能不能短一些,或者说能不能放松对随机性的要求,产生足够长但不完全随机的密钥?下面我们来学习伪随机性概念。
- 真随机性不能由一个可描述的机制产生。这里的“可描述的机制”显然是不包括“掷骰子”,而是指确定性的机制;
- 伪随机对于不知道其机制的观察者来说,看起来是真的随机;
- 一个固定的字符串谈不上是否随机/伪随机,随机/伪随机指的是产生字符串的过程;
- 问题:能否绝对地证明随机性?不能,因为我们可能是不知道其机制的观察者。
-
区分器(Distinguisher):统计测试
- 一类判断是否随机的务实的方法是,从一个随机生成器中得到多个随机序列并进行一套统计测试。
- 例如,序列中0和1的数量之差不应该太大,最大连续0的长度不应该太长等等。
- 伪随机性意味着下一比特不可预测(next-bit unpredictable),通过所有下一比特测试等且仅当通过所有统计测试。(这是姚期智的贡献)
- 问题是难以确定多少测试才足够?
-
定义伪随机性的直觉
- 直觉:从一个短的真随机种子生成一个长的随机串,这个伪随机串与真随机串是不可区分的。
- 这是不是和图灵测试类似?
- 区分器输入一个比特串,输出1位比特。注意:该比特不一定表示输入的串是否是随机的。
伪随机生成器(PRG)
-
伪随机生成器 (Pseudorandom Generator) 定义
- 一个确定性的多项式时间算法 G : { 0 , 1 } n → { 0 , 1 } ℓ ( n ) G : \{0,1\}^n \to \{0,1\}^{\ell(n)} G:{0,1}n→{0,1}ℓ(n)是一个伪随机生成器(PRG),如果:
- 延展: ∀ n , ℓ ( n ) > n \forall n, \ell(n) > n ∀n,ℓ(n)>n。只有生成更长的串才有意义,否则可以直接从种子中复制一段输出;
- 伪随机:对于任意PPT区分器 D D D, ∣ Pr [ D ( r ) = 1 ] − Pr [ D ( G ( s ) ) = 1 ] ∣ ≤ n e g l ( n ) \left|\Pr[D(r)=1] - \Pr[D(G(s))=1]\right| \le \mathsf{negl}(n) ∣Pr[D(r)=1]−Pr[D(G(s))=1]∣≤negl(n)。其中, r r r是随机的,种子 s s s随机的, ℓ ( ⋅ ) \ell(\cdot) ℓ(⋅)是延展因子。这里的意思是输出不同结果的概率差可以忽略,如果有一个区分器始终输出1,则两个概率都是1,差为0;另外,输出1并不需要表示特定含义,改成输出0也可以。
- 存在性:若单向函数存在或 P ≠ N P \mathcal{P} \ne \mathcal{NP} P=NP,则PRG存在。后面我们会进一步学习。
- 一个确定性的多项式时间算法 G : { 0 , 1 } n → { 0 , 1 } ℓ ( n ) G : \{0,1\}^n \to \{0,1\}^{\ell(n)} G:{0,1}n→{0,1}ℓ(n)是一个伪随机生成器(PRG),如果:
-
真实案例
- C语言的
random() - Netscape早期版本的漏洞https://people.eecs.berkeley.edu/~daw/papers/ddj-netscape.html
- C语言的
- 从这两个例子可以看出来,输出都是可预测的。
-
关于PRG的一些问题
- 利用下一比特不可预测,还有PRG的不可区分实验定义可以解决这些问题。
-
充分种子空间
- 稀疏输出:当扩展因子为 2 n 2n 2n时,在长度为 2 n 2n 2n的串中只会产生 2 − n 2^{-n} 2−n。
- 蛮力攻击:给定无穷的时间,通过枚举所有种子来产生所有串,能以较高的概率区分出伪随机串。
- 充分种子空间:种子必须长来抵抗蛮力攻击。
-
不充分的随机性
- 2008年,为了避免一个编译警告,Debian的一个发布版本中误删了一行代码,引起OpenSSL中关于随机生成器的漏洞。
规约法
-
规约法(Reduction)
- 规约法是将一个问题A变换为另一个问题B。变换的意思可以理解为,A可以通过解决B来解决。
- 规约 A ≤ m B A \le_m B A≤mB: A A A可规约为B,如果B的解存在并且给定该解时A可解,其中 m m m表示映射规约;这里可以将规约理解为A对B的子函数调用,除了子函数B是一个黑盒,解决A的步骤都应该是明确的。
- 解决A不能比解决B更难,因为A可以通过解决B来得到解决。
- 例题,测量矩形面积可规约到测量矩形边长;计算一个数的平方可规约到两个数乘积,相反可以规约吗?
规约证明
-
规约证明
- 我们现在站在敌手的角色来思考,希望解决“破解”加密方案这个问题,并且在此之前我们已经知道有个一“假设”问题是不可解决的;
- 为了证明一个加密方案 Π \Pi Π在假设 X X X下是安全的,就是证明“破解”问题不可解。
- 将解决“假设” X X X问题的算法 A ′ \mathcal{A}' A′规约到“破解” Π \Pi Π的算法 A \mathcal{A} A。如果加密方案可以被破解,则假设问题也可以解决。然而,由于假设问题是难以解决的,这导致矛盾,说明加密方案不可以被破解。
- 先令一个概率多项式时间的算法 A \mathcal{A} A能够以概率 ε ( n ) \varepsilon(n) ε(n)破解 Π \Pi Π ;
- 假设:一个问题 X X X是难以解决的,即不存在多项式时间算法来解决 X X X; A ′ \mathcal{A}' A′是一个解决 X X X的概率算法;
- 规约:解决假设问题 X X X可以通过破解加密方案 Π \Pi Π,即将 A ′ \mathcal{A}' A′规约到 A \mathcal{A} A, A ′ \mathcal{A}' A′通过以 A \mathcal{A} A作为子函数可以以概率 1 / p ( n ) 1/p(n) 1/p(n)有效地解决问题 X X X;
- 矛盾:若加密方案可以被有效破解,即 ε ( n ) \varepsilon(n) ε(n)是不可忽略的,则 A ′ \mathcal{A}' A′可以以不可忽略的概率 ε ( n ) / p ( n ) \varepsilon(n)/p(n) ε(n)/p(n)解决问题 X X X,这与假设矛盾,因而 ε ( n ) \varepsilon(n) ε(n)一定是可忽略的。
-
一个规约法证明PRG的例子
- 假设 F F F是PRG,证明 G G G也是PRG。
- 问题A:如何区分 F F F;问题B:如何区分 G G G;
- 从A规约到B:区分 F F F的算法输入按位取反后作为区分 G G G的算法输入,区分 G G G的算法输出作为区分 F F F的算法输出。
-
一个规约法证明PRG的例子(续)
- 由此,建立了不可区分定义中概率的联系。
构造安全的加密方案
-
一个安全的定长加密方案
- ∣ G ( k ) ∣ = ℓ ( ∣ k ∣ ) |G(k)| = \ell(|k|) ∣G(k)∣=ℓ(∣k∣), m ∈ { 0 , 1 } ℓ ( n ) m \in \{0,1\}^{\ell(n)} m∈{0,1}ℓ(n), 一个PRG以长度为 n n n的密钥作为种子,输出与明文相同长度的pad;
- G e n \mathsf{Gen} Gen: k ∈ { 0 , 1 } n k \in \{0,1\}^n k∈{0,1}n,密钥作为种子,长度小于明文长度;
- E n c \mathsf{Enc} Enc: c : = G ( k ) ⊕ m c := G(k)\oplus m c:=G(k)⊕m,加密方法和一次一密一样;
- D e c \mathsf{Dec} Dec: m : = G ( k ) ⊕ c m := G(k)\oplus c m:=G(k)⊕c,解密也是;
- 定理:该定长加密方案是窃听下不可区分的。
- 直觉上,这个方案和一次一密是类似的,除了密钥更短并且用伪随机生成器生成的比特串来与明文异或。因为伪随机对于任何敌手都可以认为是真随机,所以对于敌手而言,该方案与一次一密是一样的。由此,我们得到了一个安全的加密方案,同时避免了一次一密的最大局限性——密钥过长。
-
证明不可区分加密方案
- 思路:区分伪随机性为难题假设,破解加密方案为规约的子函数。针对伪随机生成器 G G G的区分器 D D D以 A \mathcal{A} A为子函数,使得当 A \mathcal{A} A破解了 Π \Pi Π则 D D D可以区分出 G G G,与 G G G的伪随机性矛盾。注意这里我们用了符号 Π ~ \tilde{\Pi} Π~来表示 Π \Pi Π的一个变体,来刻画加密方案中可能使用了真随机串来加密;
- 回顾针对伪随机生成器的区分器 D D D的问题是,输入一个串 w w w,输出一个比特;这里关键问题是输出的比特从何而来?
- 将 D D D规约到 A \mathcal{A} A。回顾窃听者不可区分实验中, A \mathcal{A} A与一个挑战者进行3轮交互:
- A \mathcal{A} A选择两个不同明文 m 0 , m 1 m_0, m_1 m0,m1,并发送给挑战者;
- 挑战者生成密钥,并随机挑选一个明文 m b m_b mb加密后得到挑战密文 c c c,并发送给 A \mathcal{A} A;
- A \mathcal{A} A输出对所加密明文的猜测 b ′ b' b′,若 b = b ′ b=b' b=b′,则 A \mathcal{A} A成功;否则,失败;
- 区分器 D D D成为窃听不可区分实验中的挑战者,特别之处在于:在第2步,不需要生成密钥,而是直接以输入串 w w w作为pad来加密, c : = w ⊕ m b c := w \oplus m_b c:=w⊕mb;根据 w w w的两种可能,分两种情况:
- 当 w w w是由 G G G生成的,即伪随机串,则 c c c就是加密方案 Π \Pi Π中密文, A \mathcal{A} A面对的就是 Π \Pi Π;
- 当 w w w是真随机串,则 c c c不同于加密方案 Π \Pi Π中密文,而与一次一密中一样, A \mathcal{A} A面对的就是 Π ~ \tilde{\Pi} Π~一次一密;
- 回答前面关于 D D D输出什么的问题:破解加密方案的 A \mathcal{A} A成功时, D D D输出1;否则, D D D输出0。
-
证明不可区分加密方案(续)
- 规约完毕,证明 A \mathcal{A} A在实验中成功的概率是可忽略的
- 当 w w w为真随机串 r r r,就是一次一密, Pr [ D ( r ) = 1 ] = Pr [ P r i v K A , Π ~ e a v ( n ) = 1 ] = 1 2 \Pr[D(r)=1] = \Pr[\mathsf{PrivK}^{\mathsf{eav}}_{\mathcal{A},\tilde{\Pi}}(n)=1]=\frac{1}{2} Pr[D(r)=1]=Pr[PrivKA,Π~eav(n)=1]=21;
- 当 w w w为伪随机串 G ( k ) G(k) G(k), Pr [ D ( G ( k ) ) = 1 ] = Pr [ P r i v K A , Π e a v ( n ) = 1 ] = 1 2 + ε ( n ) \Pr[D(G(k))=1] = \Pr[\mathsf{PrivK}^{\mathsf{eav}}_{\mathcal{A},\Pi}(n)=1] = \frac{1}{2} + \varepsilon(n) Pr[D(G(k))=1]=Pr[PrivKA,Πeav(n)=1]=21+ε(n);
- 根据伪随机生成器定义,上下两个公式相减, ∣ Pr [ D ( r ) = 1 ] − Pr [ D ( G ( k ) ) = 1 ] ∣ = ε ( n ) ≤ n e g l ( n ) \left|\Pr[D(r)=1] - \Pr[D(G(k))=1]\right| = \varepsilon(n) \le \mathsf{negl}(n) ∣Pr[D(r)=1]−Pr[D(G(k))=1]∣=ε(n)≤negl(n);
- 所以 ε ( n ) \varepsilon(n) ε(n)是可忽略的,即 Π \Pi Π是窃听者不可区分的。
- 小结:通过规约将 A \mathcal{A} A的不可区分实验成功的概率与 D D D的区分器实验输出1的概率建立等式;分析输入真随机串时 D D D输出1的概率(即不可区分实验成功概率)是1/2;根据PRG的定义,输入伪随机串时 D D D输出1的概率(1/2+ ε ( n ) \varepsilon(n) ε(n))与输入真随机串时 D D D输出1的概率(1/2)的差异时可忽略的。
- 规约完毕,证明 A \mathcal{A} A在实验中成功的概率是可忽略的
-
处理变长消息
- 对于一个变长输出的伪随机生成器,前面的加密方案和安全性都成立;这是作业,其中一个关键是条件2,短串是长串的前缀。
-
计算安全与信息安全
- 敌手:PPT窃听者,无限算力窃听者;
- 定义:不可区分性 1 2 + n e g l \frac{1}{2} + \mathsf{negl} 21+negl,不可区分性 1 2 \frac{1}{2} 21;
- 假设:伪随机,随机;
- 密钥:短随机串,长随机串;
- 构造:异或pad,异或pad;
- 证明:规约法,概率论;