注意:大家记得学完通用测试记得再学鸿蒙专项测试
https://blog.csdn.net/weixin_51166786/article/details/145768653
注意:博主有个鸿蒙专栏,里面从上到下有关于鸿蒙next的教学文档,大家感兴趣可以学习下
如果大家觉得博主文章写的好的话,可以点下关注,博主会一直更新鸿蒙next相关知识
目录
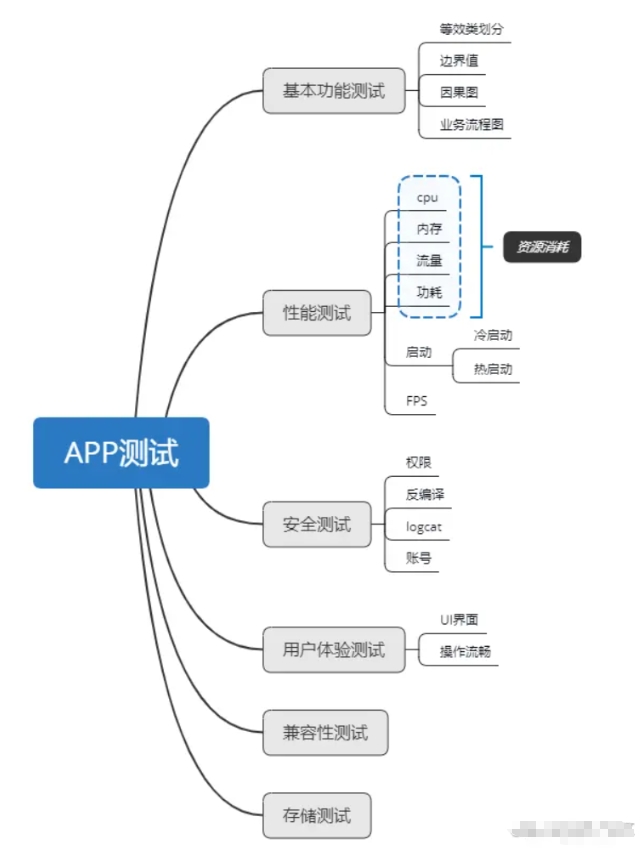
1. App测试基本流程图
2. 功能测试的基本方法
2.1 等价类划分:有效等价类和无效等价类
2.2 边界值:最大值和最小值
2.3 错误推测法
2.4 因果图:对于相互影响关联的功能测试
2.5 业务流程图
3. 性能测试
4. 中断测试
5. 兼容性测试
6. 存储测试
7. 安全测试
8. 用户体验测试
9. 稳定测试
10. 测试设计
10.1 基本介绍
10.2 要求
11. 测试用例
11.1 基本介绍
11.2 要求
12. 测试报告
12.1 基本介绍
12.2 要求
1. App测试基本流程图
2. 功能测试的基本方法
2.1 等价类划分:有效等价类和无效等价类
等价类划分是一种常用的黑盒测试技术,它将输入数据划分为几个合理的等价类,然后从每个等价类中选取少量具有代表性的数据作为测试用例。
假设有一个系统接收年龄作为输入,年龄的有效范围是18至60岁。
- 有效等价类:[18, 60]
- 无效等价类:小于18(如17);大于60(如61)
2.2 边界值:最大值和最小值
边界值分析是一种补充等价类划分的方法,它专注于测试输入变量的边界值,因为程序往往在边界值附近更容易出错。
延续上面的年龄输入例子,边界值可能包括17、18、19、59、60和61。
2.3 错误推测法
基于经验和直觉,预测可能出现错误的情况,然后针对这些情况进行测试。
假设一个登录页面,可以尝试输入过长的用户名或密码、特殊字符、空白输入等,看系统如何响应。
2.4 因果图:对于相互影响关联的功能测试
因果图方法首先使用因果图模型化输入与输出之间的关系,之后将因果图转换为决策表,最后从决策表中导出测试用例。这种方法特别适用于处理多个输入条件之间存在复杂逻辑关系的情况。
一个银行转账系统,其中转账成功与否取决于账户余额是否足够、账户状态是否正常等多个因素。可以通过因果图来分析这些因素之间的关系,从而设计出有效的测试用例。
2.5 业务流程图
业务流程图用于描述系统的业务流程,帮助测试人员理解整个业务场景,进而设计更贴近实际使用的测试用例。
电商平台的购物流程,从用户浏览商品、加入购物车、选择支付方式到最后完成支付,每一步都涉及到不同的功能点。通过绘制业务流程图,可以清晰地看到各个步骤之间的关系,有助于全面覆盖测试点。
3. 性能测试
1.关注应用使用时资源消耗(CPU、内存、流量、功耗)
2.应用启动时耗时(冷启、热启)
3.主要页面加载时间、响应时间
4.应用安装、卸载、更新
5.极限测试:在各种边界情况下验证app的响应能力(低电量、储存满、弱网等)
6.压力测试:在反复长期操作下或高负载情况下,应用资源的使用情况、请求响应时间等
4. 中断测试
干扰,比如正在使用应用播放音乐,突然来电话,短信等对应用的影响
5. 兼容性测试
1、应用在不同的网络环境(wifi,2g,3g,4g,5g等)的兼容性
2、应用在不同鸿蒙手机分辨率和系统基线不同的兼容性
3、应用在多设备兼容性(手机、平板、手表等)
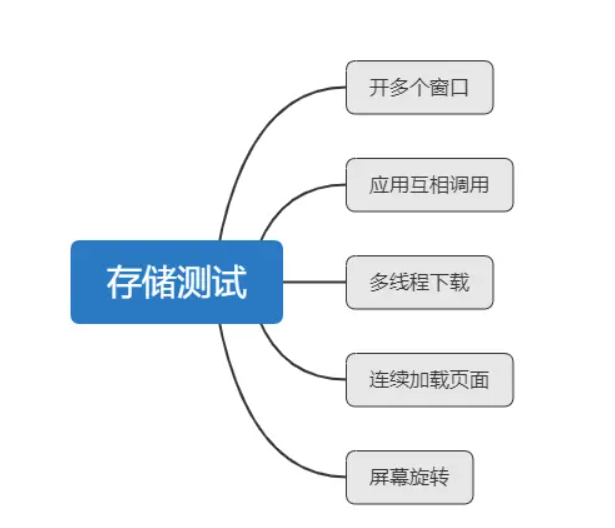
6. 存储测试
存储测试过程中,一般会受到设备本身性能的影响
7. 安全测试
1、APP权限
2、反编译
3、日志打印
4、账号安全
8. 用户体验测试
1、UI界面是否美观
2、操作是否流畅
3、功能是否达到用户使用要求
9. 稳定测试
通过模拟极端条件来测试应用的极限,例如非常高的数据流量或长时间连续运行,以检查应用是否会崩溃或出现错误
10. 测试设计
10.1 基本介绍
1、熟悉app的功能需求、用户故事和设计文档、用户群体、使用场景等
2、编写测试方案(包含功能测试、性能测试、安全测试、兼容性测试、风险评估等)
3、编写测试计划(测试周期,完成时间等)
4、根据需求文档和软件设计文档编写详细的测试用例
10.2 要求
充分性:测试设计对应用功能、场景的覆盖率;
可读性:测试设计撰写的可读性和可理解性,要求清晰易理解,无歧义;
全面性:除功能外,性能、功耗、稳定性等方面的考虑,测试工具依赖和测试资源的诉求;
11. 测试用例
11.1 基本介绍
一个完整的测试用例通常包含以下几个部分:
- 测试用例ID:唯一标识符,用于追踪和管理测试用例。
- 测试标题:简短描述测试的目的或要验证的功能点。
- 前置条件:执行测试前必须满足的条件或环境设置。
- 输入数据:测试过程中需要提供的数据。
- 测试步骤:详细列出执行测试的具体步骤。
- 预期结果:期望的测试结果,包括系统的行为和输出。
- 实际结果:测试执行后的实际结果(这部分通常在测试执行后填写)。
- 测试结果:判断测试是否通过(Pass/Fail)。
- 备注:任何额外的信息,如依赖项、注意事项等。
示例:登录功能测试用例
测试用例ID: test001
测试标题: 验证正确的用户名和密码可以成功登录
前置条件:
1、用户已注册账号。
2、应用处于登录界面。
输入数据:
1、用户名: testuser
2、密码: 123456
测试步骤:
1、打开APP并进入登录界面。
2、在用户名字段中输入“testuser”。
3、在密码字段中输入“123456”。
4、点击“登录”按钮。
预期结果:
用户成功登录,跳转至主界面。显示欢迎信息:“您好,testuser”。
实际结果: (测试执行后填写)
测试结果: (测试执行后填写)
备注:
如果用户已经登录,则需要先注销。
检查是否有验证码要求,如果有,需要正确输入验证码。
11.2 要求
1、充分性:对测试功能点的用例覆盖率;
2、准确性:测试用例撰写要求可读性强,易解性,可重复;
3、规范性:测试用例的必填字段均被规范且完整的填写、用例级别定义是否合理;
4、测试方法的全面性:是否使用了边界值、等价类等常用方法;
12. 测试报告
12.1 基本介绍
一个完整的测试报告通常包含以下几个部分:
- 封面
- 项目名称
- 报告标题(例如:APP测试报告)
- 测试日期
- 编写人
- 审核人
- 版本号
- 目录
- 列出报告的主要章节和页码。
- 概述
- 项目背景:简要介绍项目的背景和目的。
- 测试目标:明确本次测试的主要目标和范围。
- 测试范围:列出本次测试覆盖的功能模块和未覆盖的部分。
- 测试环境
- 硬件环境:测试所用的设备型号、操作系统版本等。
- 软件环境:测试所用的应用版本、测试工具等。
- 网络环境:测试所用的网络类型(如Wi-Fi、4G等)。
- 测试用例概览
- 总测试用例数
- 成功通过的测试用例数
- 失败的测试用例数
- 未执行的测试用例数
- 测试结果
- 功能测试
- 各个功能模块的测试结果汇总。
- 发现的问题和缺陷列表,包括问题描述、严重程度、重现步骤等。
- 性能测试
- 性能测试的数据和图表,如响应时间、吞吐量等。
- 兼容性测试
- 不同设备和操作系统上的测试结果。
- 安全测试
- 安全漏洞和风险评估。
- 用户体验测试
- 用户体验方面的反馈和改进建议。
- 问题和缺陷
- 列出所有发现的问题和缺陷,按严重程度分类(如致命、严重、中等、轻微)。
- 每个问题应包括:
- 问题ID
- 问题描述
- 重现步骤
- 截图或视频(如有)
- 当前状态(如已解决、未解决)
- 总结和建议
- 测试总结:总体评价应用的质量和测试过程。
- 改进建议:针对发现的问题提出具体的改进建议。
- 附件
- 测试用例文档
- 测试日志
- 相关截图和视频
12.2 要求
1、测试结论&风险:准备给出应用的测试结论及详细的缺陷风险描述;
2、测试报告规范性:测试报告的可读性、可理解性;
3、测试报告准备性:测试报告内容描述、截图与应用情况一致,缺陷可复现。测试用例通过率真实可靠;



















