文章目录
- 介绍
- 前言
- 高保真的文件
- 什么是PDF?
- PDF的一些优点
- 版本摘要
- 谁在使用PDF?
- 有用的免费软件
- 谁应该阅读
- 构建一个简单PDF文件
- 基本PDF语法
- File Structure
- Document Content
- Page Content
- 构建简单PDF
- 文件头
- 目录,交叉引用表和文件尾
- 主要对象
- 图形内容
- 把它放在一起
- 文件结构
- 文档布局
- 文件头
- Body
- 交叉引用表
- 文件尾
- 词汇约定
- 对象
- 整数和实数
- 字符串
- 十六进制字符串
- 名称
- 布尔值
- 数组
- 字典
- 间接对象
- 流和过滤器
- Incremental Update 增量更新
- Object and Cross-Reference Stream 对象和交叉引用流
- Linearized PDF 线性化 PDF
- 如何读取PDF文件
- 如何编写PDF文件
- 文档结构
- Trailer 字典
- 文档信息字典
- 文档目录
- 页面和页面树
- 文本字符串
- 日期
- 把它放在一起
- 参考
介绍
前言
可移植文档格式(PDF)是描述页面打印的世界领先语言,在印刷行业几乎无处不在。同时适用于电子文档交换和在线文档分页展示。
高保真的文件
今天我们认为高保真的PDF文件交换是理所当然的,因为知道这里发送的文件在哪里看起来都是相同的,并且它可以在屏幕上和纸上同等地显示。
但其他文件交换情况并非如此。例如word,当进行文字排版并设置相应字体后,在其他机器上若没有相应字体,则会面临显示不一致问题。
像PDF这样的页面描述语言是使用高度结构化的数据描述打印或屏幕页面的内容(文本和图形)的方式,通常是额外的描述文档各个方面的元数据(例如打印信息或文本注释或如何查看或打印)。这样,关于如何光栅化文档(由打印机或屏幕转换为像素)的决定可以留到生产过程结束。PDF文件可以包含文本和相关的字体定义,矢量和位图图形,导航(例如超链接和书签)以及交互式表单。
PDF用于内容的确切呈现是很重要的地方(例如,用于印刷广告或书籍)。当内容在最后时刻被布置或回流时通常是不合适的。
什么是PDF?
典型的PDF文件包含数千个对象,多种压缩机制,不同的字体格式,以及矢量和光栅图形的混合以及各种元数据和辅助内容。我们在这里简要介绍这些元素,以供下文使用。
-
文本和字体
PDF文件可以包含从所有常用格式(Type1,TrueType,OpenType,旧版位图字体等)字体中提取的文本。字体文件嵌入在文档中,因此字符形状始终可用,这意味着文件应在任何计算机上呈现相同的形状。支持各种字符编码,包括Unicode。
文本可以填充任何颜色,图案或透明度。一段文本可以用作剪辑其他内容的形状,允许复杂的图形效果,同时文本仍然可选择和可编辑。
通常,信息在PDF文档中以编码形式存在,且允许文本提取,尽管该过程并不总是直截了当。
-
矢量图像
PDF中的图形内容基于Adobe PostScript语言中首次使用的模型。它由直线和曲线构成的路径组成。可以填充每个路径,以绘制线,或两者。线条可以有不同的厚度,连接样式和破折号图案。
路径可以填充任何颜色,具有由其他对象定义的重复图案,或者具有两种颜色之间的平滑渐变。
可以使用各种普通或渐变透明度渲染路径,其中几种不同的混合模式定义了半透明对象如何相互作用。出于透明的目的,可以将对象组合在一起,因此可以一次将单个透明度应用于整个对象组。
路径可用于剪切其他对象,以便仅显示与剪切路径重叠的那些对象的部分,这些剪辑区域可以彼此嵌套。
PDF有一种机制,允许图形定义一次然后使用多次(在不同的时间背景下)。这可以用于跨越多个页面使用相同的图案。
-
光栅图像
PDF文档可以在每个组件中包括1到16位之间的位图图像,在几个颜色空间中(例如,三分量RGB或四分量CMYK)。可以使用各种无损或有损压缩机制来压缩图像。
图像可以以任何比例或旋转放置,用于创建填充图案,并且可以具有掩模,该掩模定义它们如何使用透明度与它们所放置的背景混合。
-
色彩空间
PDF可以使用与特定电子或打印设备(灰度,RGB,CMYK)相关的色彩空间以及与人类色彩感知相关的色彩空间。此外,还有印刷业的色彩空间,如专色。如果简单的PDF程序(如屏幕上的查看器)不支持更高级的颜色空间,则它们可以回退到基本的颜色空间。
-
元数据
PDF文档有一组标准元数据,如标题,作者,关键字等。这些是在图形内容之外定义的,对文档没有影响。还记录创建者(创建内容的程序)和制作者(编写PDF文件的程序)。每个文档还有一组唯一标识符,允许通过工作流跟踪它们。
从PDF 1.4开始,元数据可以使用Adobe的可扩展元数据平台(XMP)存储在嵌入PDF中的XML(可扩展标记语言)文档中。这定义了一种存储PDF中对象的元数据的方法,该方法可以用第三方扩展以保存与其特定工作流程或产品相关的信息。
-
导航
在屏幕上查看时,PDF文档有两种导航方法:
- 文档大纲(通常称为文档的书签)是文档中的目标结构列表。单击一个可将视图移动到该页面或位置。
- 文档或文档图形中的超链接允许用户单击以移动到文档中的其他位置或打开外部URL。
-
可选内容
PDF中的可选内容组允许将页面内容的一部分组合在一起并显示。基于某些其他因素(用户选择,文档是在屏幕上还是在打印时,缩放因子)或者不显示。可以定义组之间的关系,以便它们彼此依赖。一个用途是模拟图形包中的“图层”。例如,当使用PDF查看器读取其生成的文档时,将保留Adobe Illustrator图层。
-
多媒体
PDF文档可以包括各种多媒体元素。其中许多都破坏了PDF中固有的可移植性,并且在Adobe产品之外通常得不到很好的支持。来自PDF 1.2 可以嵌入声音和电影。来自PDF 1.4 可以定义幻灯片,以便在具有转换的页面之间自动移动效果。来自PDF 1.5 引入了包含任意媒体类型的更通用的系统。来自PDF 1.6 可以嵌入3D图稿。
-
互动表格
PDF中有两种不兼容的表单体系结构:AcroForms(一种开放标准)和Adobe XML Forms Architecture(XFA),它已被记录但需要Adobe的商业软件。
表单允许用户填写文本字段,并使用复选框和单选按钮。数据完成后,可以将其保存到文档中(如果允许)或提交到URL进行进一步处理。嵌入式JavaScript通常与表单结合使用,以处理字段值或类似任务的验证。
-
逻辑结构和回流
逻辑结构工具允许将有关结构内容(章节,页面,图形,表格和脚注)的信息与图形内容一起包含在内。特定元素可由第三方定制。
标记的PDF是具有基于一组Adobe定义的元素的逻辑结构的PDF。读取器遵循这些约定,以便以不同的页面大小或文本大小显示相同的文本,例如在电子书阅读器中。
-
安全
可以使用RC4或AES加密方法对PDF文档进行加密以确保安全性。有两个密码,分别为所有者密码和用户密码。所有者密码为所有更改解锁文件,用户密码只允许在文件最初加密时由所有者选择的一系列操作(例如,允许或禁止打印或文本提取)。用户密码通常是空白的,因此文件似乎正常打开,但功能受到限制。
从PDF 1.3开始,数字签名可用于验证用户的身份或文档的内容。
-
压缩
PDF中的图像和其他数据流可以使用第三方定义的各种无损和有损方法进行压缩。通过仅压缩这些流(而不是整个文件),PDF对象的结构始终可用,无需解压缩整个文件,只有在需要时才能处理压缩的部分。有几组压缩方法:
- 双级(例如,黑色和白色)图像的无损压缩。PDF支持双层图像的标准传真编码方法,以及PDF 1.4的JBIG2标准,它为同一类图像提供更好的压缩。
- 有损图像滤镜,如JPEG和PDF 1.5,JPEG2000。
- 适用于图像数据和一般数据压缩的无损压缩机制,例如Flate(Zip算法),Lempel-Ziv-Welch(LZW)和行程编码。
PDF的一些优点
-
随机访问和线性化
PDF文档中的任何对象(页面,图形等)都可以在恒定时间内随意访问。这意味着阅读第150页并不比第1页更难。线性化是在文件中排列对象的过程,使得给定页面所需的所有对象都位于相邻位置。这解释了为什么你在Web浏览器窗口中或在Acrobat Reader中可以快速跳转查看PDF中的任何页面。这是因为查看器不需要加载整个文件,它只(web文档则从服务器)获取显示所需的特定页面内容。
-
流创建和增量更新
流创建是PDF格式中固有的能力,允许从头到尾按顺序创建文件,即使最终文件大于可用内存。
增量更新意味着,在编辑文件时,可以将更改写入文件末尾而无需修改任何现有部件。这样可以非常快速地保存更改的版本,并且可以用于提供撤消机制,回退到上一版本)。
-
嵌入字体
PDF中使用的字体与文档一起嵌入。这意味着无论在给定计算机上安装哪种字体,都始终正确呈现。创建PDF文档的程序将从字体中删除不必要的数据(例如度量和未使用的字符),因此文件不会变得过大。PDF支持所有常见的字体格式,例如TrueType和Type 1。
-
可搜索的文本
大多数PDF文件都维护信息,以将构成文本的字符形状映射到Unicode字符代码。这意味着你可以复制和粘贴文档中的文本,或轻松搜索文本。PDF的最新发展允许文档中文本的逻辑顺序与页面上文本的布局分开存储,从而保留更多结构化信息。
-
ISO标准化
PDF于2008年由国际标准化组织(ISO)作为开放标准发布.ISO-32000-1:2008文档与Adobe先前发布的PDF文件格式文档大致相同。
这种独立性为PDF标准提供了合法性和监督,这会鼓励其进一步采用。但是,由于没有真正的工具来检测文件是否符合标准(Adobe Reader会很乐意加载格式错误的文件,因为很多工具都会创建它们),真正的严谨性还需要一段时间。
-
专业的PDF格式
PDF格式有几种专门的变体 - 标准化和开发中。这些是PDF格式的子集。每个文件都是有效的PDF文档,但对所使用的设施或内容本身有限制。其中两个,PDF/A和PDF/X,现在是ISO标准。
-
PDF/A
PDF/A标准(ISO 19005-1:2005)为在图书馆,国家档案馆和政府机构中长期存档的文件定义了一套规则。它还需要“符合标准的阅读器”以某种方式,使用嵌入字体,使用颜色管理等。
-
PDF/X
PDF/X标准是印刷行业图形交换的ISO标准系列,其中最新的是PDF/X-5(ISO 15930-8:2010)。
-
版本摘要
PDF完全向后兼容(你可以将PDF版本1.0文档加载到为PDF 1.7设计的程序中)。并且大部分向前兼容(为PDF 1.0编写的程序通常可以加载PDF 1.7文件)。确保前向兼容性是因为读者忽略了他们不理解的内容 - 只有在引入新的压缩方法或对象存储机制时才会被忽略。自2003年的PDF 1.5以来,这种变化很小。如下表格总结了PDF版本及其功能。
| PDF 版本 | Acrobat Reader 版本 | 推出 | 新功能摘要 |
|---|---|---|---|
| 1.0 | 1.0 | 1993 | 首发 |
| 1.1 | 2.0 | 1996 | 设备无关的颜色空间,加密(40位),文章线程,命名目标和超链接 |
| 1.2 | 3.0 | 1996 | AcroForms(交互式表单),电影和声音,更多压缩方法,Unicode支持。 |
| 1.3 | 4.0 | 2000 | 更多色彩空间,嵌入(附加)文件,数字签名,注释,蒙版图像,渐变填充,逻辑文档结构,印前支持 |
| 1.4 | 5.0 | 2001 | 透明度,128位加密,更好的表单支持,XML元数据流,标记PDF,JBIG2压缩 |
| 1.5 | 6.0 | 2003 | 对象流和交叉引用流,用于更紧凑的文件,JPEG 2000支持,XFA表单,公钥加密,自定义加密方法,可选内容组 |
| 1.6 | 7.0 | 2004 | OpenType字体,3D内容,AES加密,新颜色空间 |
| 1.7 (later ISO 32000-1:2008) | 8.0 | 2006 | XFA 2.4,新类型的字符串,公钥体系结构的扩展 |
| 1.7 Extension Level 3 | 9.0 | 2008 | 256位AES加密 |
| 1.7 Extension Level 5 | 9.1 | 2009 | XFA 3.0. |
| 1.7 Extension Level 8 | X | 2011 | 未知 |
谁在使用PDF?
PDF广泛用于各行各业,我们在这里描述一些。
-
印刷业
PDF支持商业打印所需的色彩空间,页面尺寸信息 (如介质,裁剪,艺术和出血盒),陷印支持和分辨率独立性。与其他技术一起,PDF是出版印刷工作流程的关键部分。PDF元数据的可扩展性允许各种方案用于 将额外数据与文档包括一起,并且在整个发布过程中将其与文档保持在一起。
-
电子书和出版
PDF是主流电子书格式之一。为了支持在各种屏幕上显示,PDF文档可以用回流信息标记,允许在每个设备上以不同的宽度显示文本行。这与PDF的其他用途不一致,其中固定文本布局是印刷业必需的。
-
PDF表格
当现有的纸质系统转换为电子系统或必须与它们一起存在时,PDF表格特别有用。PDF格式(在线填写然后打印出来)看起来与在纸上手动填写的格式相同,并且可以以相同的方式由现有的人或计算机系统处理。
从PDF查看器中自动提交表单,使用JavaScript添加(例如确保数字以税表形式添加),以及使用数字签名签署填写表格都是使用PDF格式的电子表格。
-
文档存档
通过PDF/A,PDF是长期归档的理想格式,结合了扫描和电子内容的精确表示,以及Unicode语言支持,以及各种数据的压缩机制,包括用于单色图像的重要CCITT传真和JBIG2方法。作为ISO标准(以及几乎无处不在的标准) 保证这些文档可以在将来很长时间内阅读。
PDF可用于光学字符识别(OCR),允许从原始文本创建可搜索的文本,精确的视觉表示与识别的文本一起保留。
-
作为文件格式
乍一看,PDF不适合用作可编辑的矢量图形格式。例如,页面圆圈不会像原始矢量圆圈一样保持可编辑状态,因为它将被转换为多条曲线(PDF中没有圆形元素)。
但是,如果适当地使用它的可扩展性来存储辅助数据,那么它就是一个很好的解决方案。例如,Adobe Illustrator 现在使用扩展形式的PDF作为其文件格式。该文件可以在任何PDF查看器中查看,但Illustrator 可以在将数据加载回程序时使用扩展数据。
有用的免费软件
在本书中,我们使用各种软件来帮助我们举例。幸运的是,你需要的一切都是免费提供的。你需要一个PDF查看器:
- Acrobat Reader是Adobe自己的PDF查看器。它支持PDF的所有版本和功能,并在大多数平台上附带浏览器插件。它适用于Microsoft Windows,Mac OS X,Linux,Solaris和Android。
有个关键的命令行工具:
- pdftk是一个多平台命令行工具,用于以各种方式处理PDF文件。它可以以预构建的形式下载,适用于Microsoft Windows,Mac OS X和Linux,也可以源代码形式下载。
谁应该阅读
本文适合:
-
希望了解其提供的设施背后原因的Adobe Acrobat用户,而不仅仅是如何使用它们。例如:加密选项,修剪和裁剪框以及页面标签。
-
希望使用命令行软件批量处理PDF文档的高级用户,通过合并,拆分和优化它们。
-
程序员编写代码来读取,编辑或创建PDF文件。
-
想要了解如何使用PDF的元数据和工作流功能来构建连贯系统的搜索,电子出版和打印行业专业人士。
构建一个简单PDF文件
我们将在文本编辑器中手动构建PDF内容。然后我们将使用
免费的pdftk程序将其转换为有效的PDF文件,并在PDF查看器中查看输出。
基本PDF语法
PDF文件至少包含三种不同的部分:
- file structure 文件结构,包括header(文件头),trailer(文件尾)和交叉引用表,帮助程序找到并读取文件的内容。
- document content 文档内容,包含多个具有引用关系的对象,形成有向图。这些对象描述了文档的结构(页面,元数据,字体和资源)。
- page content 页面内容,描述了使用一系列操作符将文本和图形放在一个页面上。
File Structure
文件结构包括:
- 用于将文件区分为PDF文档的header(文件头)。
- 一个交叉引用表,列出了文档中每个对象的字节偏移量 - 这个
允许任意访问对象,而不是必须按顺序读取。 - trailer(文件尾),包括交叉引用表的字节偏移,后跟文件结束标记。
Document Content
文档内容包括由以下元素构建的对象:
- 名称,如写为
/Type - 整数,如
50 - 带圆括号的字符串,如
(The Quick Brown Fox) - 引用其他对象,如
2 0 R,对对象2的引用。 - 对象的数组(有序集合),如
[50 30 /Fred],是一个包含三个项目的数组,按顺序:50,30和/Fred。 - 字典(从名称到对象的无序映射),如
<</Three 3 /Five 5>>,映射/Three到3和/Five到5。 - stream(流),它由字典和一些二进制数据组成。这些用于存储PDF图形运算符的流,以及其他二进制数据,如图像和字体。
例如,这是一个页面对象,它是一个包含许多项目的字典,每个与名称相关联:
<< /Type /Page/MediaBox [0 0 612 792]/Resources 3 0 R/Parent 1 0 R/Contents [4 0 R]
>>
这个词典包含五个条目:
-
/Type /Page字典键
/Type与名称/Page相关联。 -
/MediaBox [0 0 612 792]字典键
/MediaBox与四个整数[0 0 612 792]的数组相关联。 -
/Resources 3 0 R字典键
/Resources与对象编号3相关联。 -
/Parent 1 0 R字典键
/Parent与对象编号1相关联。 -
/Contents [4 0 R]字典键
/Contents与间接引用[4 0 R]的单元素数组相关联。
Page Content
页面内容是运算符列表,每个运算符前面都有零个或多个操作数。
如下是一系列操作符,用于在36号字体选择/F0字体并放置当前位置的文字:
/F0 36.0 Tf
(Hello, World) Tj
这里,Tf 和 Tj 是运算符,而 /F0, 36.0 和 (Hello, World) 是操作数。
你可以看到一些语法元素(例如,名称和字符串)是共享的跨页面内
容。
构建简单PDF
我们将要构建的示例只是最简单有意义的PDF文件。我们会:
- 使用简短的header。
- 跳过了页面内容流的长度,因此我们不必手动计数字节数。
- 省略几乎所有的交叉引用表
- 使用0表示交叉引用表的字节偏移量,以避免必须计数它手动。
然而,它还需要另外较多的元素。除上所述,最小的PDF文档还必须包含许多基本部分:
- trailer字典,提供了如何阅读文件中其余的对象内容
- 文档目录,它是对象图的根。
- 页面树,它枚举文档中的页面。
- 至少有一页。且每个页面必须具有:
- resources(资源),包括例如字体。
- 其它页面内容,其中包含绘制文本和图形的说明在页面上。
这种安排如下图所示。
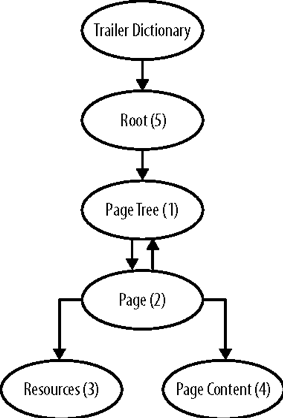
在编写我们的示例文件时,我们将对许多文件结构使用不完整的值,
依靠pdftk来填写细节。例如,我们手动编写交叉引用表是不切实际的。
注:文本编辑器选择的行结尾并不重要(<LF>[在 Unix 和 Mac OS X 中]和<CR><LF>[在 Windows 中]都很好)。
文件头
文件头通常由两行组成。第一行将文件标识为PDF和给出它的版本号:
%PDF-1.0 % PDF 版本号为 1.0 的文件头
第二行很难输入文本编辑器,因为它包含不可打印的字符。我们将有pdftk为我们处理。
目录,交叉引用表和文件尾
pdf文件读取是从下往上进行读取。
最后一行,文件结束标记 %%EOF。
向上两行,给出交叉引用表开始的字节偏移量(我们写0,pdftk将进行替换处理)。
再向上是trailer部分,给出了交叉引用表的行数,以及文档目录的引用对象。
交叉引用表在示例中是xref开头至trailer中间部分,它给出了文件中的每个对象的字节偏移量。我们将用pdftk为我们填写此内容。
由trailer获得的文档目录引用对象为5 0 R,则向上找到5 0 obj对象。该对象包含的是文档目录的根对象图。
5 0 obj
<< /Type /Catalog % 这是一个文档目录/Pages 1 0 R % 页面列表
>>
endobj
xref % 我们跳过了交叉引用表后续每个对象的字节偏移量
0 6
trailer
<< /Size 6 % 交叉引用表中的行数(对象数加1)/Root 5 0 R % 文档目录
>>
startxref
0 % xref开始的字节偏移量,我们将其设置为0
%%EOF % 文件结束标记
主要对象
到文件的主体(对象),/Kids对应的是Page列表,它是链接到文档中页面对象的字典。
1 0 obj % 对象1
<< /Type /Pages % 这是一个页面列表/Count 1 % 只有一页/Kids [2 0 R] % 页面对象编号列表,这里是对象2
>>
endobj % 对象1结束
接下来是页面,它是一个字典,包含纸张大小,父页面对象引用,以及图形内容和引用资源。
2 0 obj
<< /Type /Page % 这是一个页面/MediaBox [0 0 612 792] % 纸张尺寸为美国信肖像(612点x792点)/Resources 3 0 R % 对象3的资源引用/Parent 1 0 R % 父页面对象引用/Contents [4 0 R] % 图形内容在对象4中
>>
endobj
现在,资源(resource)在这里,只有一个条目,字体字典,在我们的
示例包含单个字体,我们将使用该字体在页面上写入一些文本。
3 0 obj
<< /Font % 字体字典<< /F0 % 只有一种字体,称为/F0<< /Type /Font % 这三行引用了内置字体Times Italic/BaseFont /Times-Italic/Subtype /Type1 >>>>
>>
endobj
图形内容
页面内容流包含用于放置文本和图形的一系列运算符。在页面上。它通过页面字典中的 /Contents 条目链接。
流对象由字典后跟原始数据流组成,包含一个一系列PDF操作数和运算符。通常,这将被压缩以减少文件大小,但我们手动输入,所以我们不压缩它。我们还必须以字节为单位指定流的长度(pdftk将为我们添加所需的/Length 条目到流字典)。
4 0 obj % 页面内容流
<< >> % 内容流长度
stream % 流的开始
1. 0. 0. 1. 50. 700. cm % 位置在(50,700)
BT % 开始文本块/F0 36. Tf % 在36pt选择/F0字体(Hello, World) Tj % 放置文本字符串
ET % 结束文本块
endstream % 流结束
endobj
页面上的图形运算符流的结果如图2-2所示。

现在我们准备将这些部分放在一起了
把它放在一起
无效的hello-broken.pdf PDF文件适合手动创建
%PDF-1.0 % 文件header
1 0 obj % 主要对象
<< /Type /Pages/Count 1/Kids [2 0 R]
>>
endobj
2 0 obj
<< /Type /Page/MediaBox [0 0 612 792]/Resources 3 0 R/Parent 1 0 R/Contents [4 0 R]
>>
endobj
3 0 obj
<< /Font<< /F0<< /Type /Font/BaseFont /Times-Italic/Subtype /Type1 >>>>
>>
endobj
4 0 obj % 图形内容
<< >>
stream
1. 0. 0. 1. 50. 700. cm
BT/F0 36. Tf(Hello, World) Tj
ET
endstream
endobj
5 0 obj % 目录,交叉引用表和trailer
<< /Type /Catalog/Pages 1 0 R
>>
endobj
xref
0 6
trailer
<< /Size 6/Root 5 0 R
>>
startxref
0
%%EOF
就目前而言,hello-broken.pdf不是有效的PDF文件。
注:Reader 2023.006.20380 Chinese Windows(64Bit) 已经可以直接打开
hello-broken.pdf文件。打开后关闭时,会提示是否需要保存。查看保存的 PDF 发现使用 PDF 1.6 规范并且已经线性化。
我们可以使用免费的pdftk工具来修复hello-broken.pdf文件,将输出写入hello.pdf:
pdftk hello-broken.pdf output hello.pdf
pdftk读取文件及其对象,并为缺失部分计算正确的数据,生成有效文件。注意一些语法的间距和格式已经改变(每个PDF制做人对此有不同的选择)。
完成的PDF文件hello.pdf。你可以使用文本编辑器查看现有的PDF文件。但是,有些数据(例如构成页面内容的图形运算符)很可能被压缩,因此不可读。
%PDF-1.0
%忏嫌 % ❶
1 0 obj
<<
/Kids [2 0 R]
/Count 1
/Type /Pages
>>
endobj
2 0 obj
<<
/Parent 1 0 R
/Resources 3 0 R
/MediaBox [0 0 612 792]
/Contents [4 0 R]
/Type /Page
>>
endobj
3 0 obj
<<
/Font
<<
/F0
<<
/BaseFont /Times-Italic
/Subtype /Type1
/Type /Font
>>
>>
>>
endobj
4 0 obj
<<
/Length 66 % ❷
>>
stream
1. 0. 0. 1. 50. 700. cm
BT/F0 36. Tf(Hello, World) Tj
ETendstream
endobj
5 0 obj
<<
/Pages 1 0 R
/Type /Catalog
>>
endobj xref
0 6 % ❸
0000000000 65535 f
0000000015 00000 n
0000000074 00000 n
0000000192 00000 n
0000000291 00000 n
0000000409 00000 n
trailer<<
/Root 5 0 R
/Size 6
>>
startxref
450 % ❹
%%EOF
- 一些不可打印的字符已添加到PDF标题中 —— 这可确保文件被识别为二进制(而不是文本),例如,通过FTP等文件传输程序。
- 已填写流的字节长度。
- 交叉引用表已填入了每个对象的字节偏移量。
- 已填写交叉引用表开头的字节偏移量。
文件结构
在该段落,我们将详细描述PDF文件的四个主要部分的布局和内容,以及构成每个部分的对象的语法。我们将概述PDF文件读入高级数据结构的过程,以及反向将该结构写入PDF文件的操作。
文档布局
一个简单有效的PDF文件按顺序包含四个部分:
- header,提供PDF版本号。
- body 包含页面,图形内容和大部分辅助信息的主体,全部编码为一系列对象。
- 交叉引用表,列出文件中每个对象的位置便于随机访问。
- trailer包括trailer字典,它有助于找到文件的每个部分,并列出可以在不处理整个文件的情况下读取各种元数据。
我们从上文经pdftk处理后的pdf作为示例进行讲解。四个部分中的每一部分的第一行都有注释。
%PDF-1.0 % Header从这里开始
%忏嫌
1 0 obj % Body从这里开始
<<
/Kids [2 0 R]
/Count 1
/Type /Pages
>>
endobj
2 0 obj
<<
/Parent 1 0 R
/Resources 3 0 R
/MediaBox [0 0 612 792]
/Contents [4 0 R]
/Type /Page
>>
endobj
3 0 obj
<<
/Font
<<
/F0
<<
/BaseFont /Times-Italic
/Subtype /Type1
/Type /Font
>>
>>
>>
endobj
4 0 obj
<<
/Length 66
>>
stream
1. 0. 0. 1. 50. 700. cm
BT/F0 36. Tf(Hello, World) Tj
ETendstream
endobj
5 0 obj
<<
/Pages 1 0 R
/Type /Catalog
>>
endobj
xref % 交叉引用表从这里开始
0 6
0000000000 65535 f
0000000015 00000 n
0000000074 00000 n
0000000182 00000 n
0000000281 00000 n
0000000400 00000 n
trailer % 预览块从这里开始<<
/Root 5 0 R
/Size 6
>>
startxref
450
%%EOF
PDF文件中的对象集合形成图形。这个图的意思与饼图或直方图无关,而是指通过链接连接在一起的节点集合。
在我们的例子中,节点是PDF对象,链接是间接引用。读一个PDF文档是在文件中创建PDF对象的图形的过程。这个图是直接链接只走一条路。
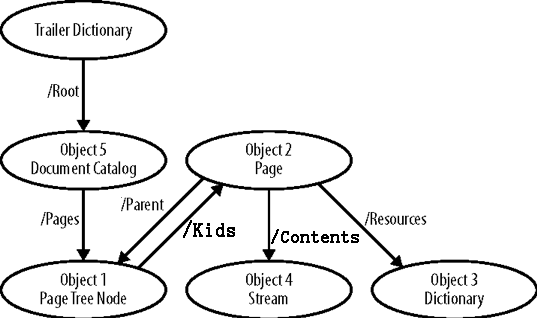
我们现在依次仔细研究这四个部分中的每一个,使用上图作为参考。
文件头
PDF文件的第一行给出文档的版本号。在我们的示例中,是:
%PDF-1.0
这将文件PDF版本定义为1.0。PDF是向后兼容的,它在很大程度上也是向前兼容的,因此PDF 1.5的程序可以读取PDF 1.3文档。所有大多数PDF程序都会尝试读取任何PDF文件,无论假设的版本号是什么。
由于PDF文件几乎总是包含二进制数据,因此如果更改行结尾(例如,如果文件通过FTP以文本模式传输),它们可能会损坏。为了允许传统文件传输程序确定文件是二进制文件,通常在标头中包含一些字符代码高于127的字节。
例如:
%忏嫌
百分号标识一行注释,其他几个字节是超过127的任意字符代码。因此,我们示例中的整个header是:
%PDF-1.0
%忏嫌
Body
文件正文由一系列对象组成,每个对象前会有单独的一行,该行包括一个对象编号,一个世代号以及关键字obj。紧跟在对象之后的是endobj关键字,它同样独占一行。
例如:
1 0 obj
<<
/Kids [2 0 R]
/Count 1
/Type /Pages
>>
endobj
这里,对象编号是1,并且世代号是0(几乎总是为0)。对象1的内容位于1 0 obj和endobj两行之间。在这种情况下,它是字典<</Kids [2 0 R] /Count 1 /Type /Pages >>
交叉引用表
交叉引用表列出了文件正文中每个对象的字节偏移量。这允许随机访问对象,因此不必按顺序读取它们。这意味着,即使在大型文件上,像计算PDF文档中的页数这样的简单操作也可以很快。
PDF文件中的每个对象都有一个对象编号和一个世代编号。当重用交叉引用表条目时使用世代号 —— 我们在这里不考虑它们(它们将始终为零)。
在我们的文件中,我们可以认为交叉引用表由一个表示条目数的标题行组成,然后是一个特殊条目,然后是文件体中每个对象的一行。
0 6 % 表中的六个条目,从0开始
0000000000 65535 f % 特别条目
0000000015 00000 n % 对象1的字节偏移量为15
0000000074 00000 n % 对象2的字节偏移量为74
0000000182 00000 n % 等等...
0000000281 00000 n
0000000400 00000 n % 对象5的字节偏移量为400
请注意,字节偏移量以前导零(不足位数补0)存储,以确保每个条目都相同长度。因此,我们也可以通过随机访问来读取交叉引用表。
文件尾
Trailer的第一行只是Trailer关键字。之后是Trailer字典,至少包含 /Size 条目(给出交叉引用表中的条目数)和 /Root 条目(给出文档根目录对象编号,它是正文中对象图的根元素)。
接下来一行只包含startxref关键字,再一行包含一个数字(文件中交叉引用表开头的字节偏移量),然后是行%%EOF,它表示PDF文件的结尾。
trailer
<< % 字典
/Root 5 0 R
/Size 6
>>
startxref % 交叉引用表开始关键字
450 % 交叉引用表的字节偏移量
%%EOF % 文件结束标记
从文件末尾向上读取Trailer:找到文件结束标记,提取交叉引用表的字节偏移量,然后解析Trailer字典。Trailer关键字标记Trailer解析行为的结束。
词汇约定
PDF文件是8位字节的序列,这些字符可以分组为标记(例如关键字和数字)和文件解析。
有三种标记字符:常规字符,空白字符和分隔符。
如上hello.pdf源码中,最顶行插入如下包含空白字符的字符串,可正常打开。
Example 3-1. A small PDF file
分隔符是() <> [] {} / %,用于定义数组,字典等。所有其他字符都是常规字符,没有特殊含义。
文件解析字符含义如下表格所列:
| 字符代码 | 含义 |
|---|---|
| 0 | Null |
| 9 | Tab |
| 10 | Line feed |
| 12 | Form feed |
| 13 | Carriage return |
| 32 | Space |
PDF文件可以使用<CR>,<LF>或<CR><LF>序列来结束一行。但请注意,更改行结尾(例如,在文本编辑器中)可能会破坏文件,因为它将改变在压缩二进制数据部分中发生的任何行结束序列。
对象
PDF文件由对象图组成,将对象链接在一起的方法:间接引用,它形成从一个对象到另一个对象的链接。
PDF支持五个基本对象:
- 整数和实数,例如42和3.1415。
- 字符串,括在括号中,并有各种编码。例如
(The Quick Brown Fox)。 - 名称,用于词典中的键,以及其他用途。它们带有/,例如/Blue。
- 布尔值,由关键字true和false表示。
- null对象,由关键字null表示。
和三个复合对象:
-
数组,包含其他对象的有序集合,如
[1 0 0 0]。 -
字典,由无序的对集合组成,将名称映射到对象。
例如,
<</Contents 4 0 R /Resources 5 0 R >>,其将/Contents映射到间接引用4 0 R,/Resources映射到间接引用5 0 R。 -
间接对象,PDF文件中的任何对象都可标记为间接对象。这为对象提供了一个唯一的对象标识符, 其他对象可通过它来引用该对象(例如,作为数组的一个元素或字典条目的值)。
整数和实数
整数写为一个或多个十进制数字0~9,可选地以加号或减号开头:
0 +1 -1 63
实数被写为一个或多个十进制数字,可选地前面带有加号或减号,并且可选地有一个小数点,可以是内部,或以下:
0.0 0. .0 -0.004 65.4
通常,规范允许给定对象是整数或实数。其他时候它必须是整数。此外,整数和实数的范围和准确性由PDF实现定义,而不是标准。在某些实现中,如果整数超出可用范围,则将其转换为实数。
字符串
字符串由一系列字节组成,写在括号之间:(Hello, World)
反斜杠\字符和括号字符()必须通过在它们前面加上反斜杠进行转义。例如,写作:(Some \\ escaped \(characters)表示字符串"Some \ escaped (characters"。外部存在已经平衡的括号对在字符串内不需要转义。例如(Red(Rouge))表示字符串“Red(Rouge)”。
反斜杠也可用于引入其他字符代码以实现可读性(参见表3-2)。
| 字符序列 | 含义 |
|---|---|
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \b | 退格 |
| \f | 换页符 |
| \ddd | 三个八进制数字的字符代码 |
十六进制字符串
字符串也可以写为<和>之间的十六进制数字序列,每对代表一个字节:
<4F6Eff00> Bytes 0x4F, 0x6E, 0xFF, and 0x00
当存在奇数个数字时,假设最后一个为十六进制字符串通常用于使用户二进制数据可读。
它在功能上与以通常方式描述字符串相同。
名称
名称在整个PDF中使用,作为字典的键来定义各种值对象。一个名称引入正斜杠。例如:
/French
/字符是名称的一部分 —— 事实上,/它本身就是一个有效的名称。名称可能不包含空格或分隔符,但名称需要与之对应一些具有这些字符的外部名称(例如空格),我们可以使用哈希符号后跟两个十进制数字:
/Websafe#20Dark#20Green
这表示名称/Websafe Dark Green,因为在ASCII中,
十六进制20是空格的代码。名称区分大小写(/French和/french不同)。
布尔值
PDF允许布尔值为true和false。它们经常在字典条目中用作标志。
数组
数组表示PDF对象的有序集合,包括其他数组。对象不一定都是同一类型。例如,数组:
[0 0 400 500]
按顺序包含四个数字:0,0,400,500。数组:
[/Green /Blue [/Red /Yellow]]
包含三个项目:名称/Green,名称/Blue和两个名称的数组[/Red /Yellow]。
字典
字典表示键值对的无序集合。字典将键映射到值 —— 提供键,值是在字典中查找的结果。键是名称,值可以是任何PDF对象。字典写在<<和>>之间。例如:
<</One 1 /Two 2 /Three 3>>
将名称/One映射到整数1,将名称/Two映射到整数2,将名称/Three映射到整数3.字典当然可以包含其他字典。嵌套字典构成了大多数PDF文件中的大部分非图形结构化数据。
间接对象
为了将PDF内容拆分为单独的对象(因此只有在需要时才能读取数据),
我们将它们与间接引用连接在一起。对对象6的间接引用写为:
6 0 R
这里,6是对象编号,0是世代号(这里我们不考虑),R是间接参考关键字。
例如,这是使用间接引用的典型字典:
<< /Resources 3 0 R/Contents [4 0 R]
>>
在此示例中,对象3和4在字典的值中被引用。
流和过滤器
流用于存储二进制数据。它们由字典和一大块二进制数据组成。字典根据流所放置的特定用途列出数据的长度,以及可选的其他参数。
从语法上讲,流由字典组成,后跟stream关键字,换行符(<LF>或<CR> <LF>),零个或多个字节的数据,另一个换行符,最后是endstream关键字。从我们的示例文件中:
4 0 obj % 对象4
<<
/Length 66 % 数据长度
>>
stream % 流关键字
1. 0. 0. 1. 50. 700. cm % 66字节的数据,这里是图形流
BT/F0 36. Tf(Hello, World) Tj
ET
endstream % 结束流关键字
endobj % 对象的结束
这里,字典只包含/Length条目,它以字节为单位给出流的长度。
所有流必须是间接对象。流几乎总是使用各种机制进行压缩,如下表所示。
| 方法名称 | 描述 |
|---|---|
| /ASCIIHexDecode | 为压缩数据中的每对十六进制数字生成一个字节的未压缩数据。>表示数据结束。空格被忽略。这个过滤器和/ASCII85Decode旨在将数据减少到7位——/ASCII85Decode更复杂,但更紧凑 |
| /ASCII85Decode | 这种7位编码格式使用可打印的字符从 ! 到 u 和 Z。(译者注:即通过五个ASCII字符来表示四个字节的二进制数据。)~>标识数据结束 |
| /LZWDecode | 实现Lempel-Ziv-Welch压缩,如TIFF图像格式所使用 |
| /FlateDecode | Flate压缩,由开源zlib库使用。在RFC 1950中定义。/LZWDecode和/FlateDecode都可以在流字典中具有预测变量,它们定义数据的后处理以反转在压缩时完成的预处理 |
| /RunLengthDecode | 一个简单的基于字节的游程压缩器 |
| /CCITTFaxDecode | 实现传真机使用的第3组和第4组编码。适用于单色(位深度为1)图像,不适用于一般数据 |
| /JBIG2Decode | 一种更现代,更好的压缩机制,适用于与/CCITTFaxDecode一起使用的各种数据,但也适用于灰度和彩色图像和一般数据。实现JBIG2压缩方法 |
| /DCTDecode | JPEG有损压缩。整个JPEG文件可以放在这里,包括JPEG文件头 |
| /JPXDecode | JPEG2000有损和无损压缩。仅限于JPX基准功能集,但有一些例外 |
以下是压缩流的示例:
796 0 obj
<</Length 275 /Filter /FlateDecode>> % 流
HTKO0÷ü % 这里还有 268 字节被隐藏,即总计 275 字节
endstream
endobj
通过为流的字典中的/Filter条目指定数组而不是名称,可以使用多个过滤器。
例如,使用JPEG方法压缩然后使用ASCII85编码的图像可能具有以下过滤条目:
/Filter [/ASCII85Decode /DCTDecode]
需要外部参数的过滤器(例如,在数据流本身之外定义压缩参数)也会将这些参数存储在流字典中。
Incremental Update 增量更新
增量更新允许通过将修改附加到文件末尾来更新文件,因此不需要再次写入整个文件(对于大文件,可能需要很长时间)。更新构成新的或更改的对象,以及对交叉引用表的更新。这意味着保存更改所花费的时间更少,但文件可能会变得臃肿(因为不再需要的对象无法删除)。
此更新过程可能会发生多次。副作用是以这种方式更新的文件能进行撤销一次或多次,从而能检索到文档的早期版本。
更改经过数字签名的文档时,必须以增量方式进行所有更新,否则,
数字签名将无效。收件人可以撤消增量更新以检索原始的,经过认证的文档。
当一个文件以递增方式更新时,会添加一个新的trailer,其中包含前一个trailer中的所有条目,以及一个/Prev条目,它给出了之前交叉引用表的字节偏移量。因此,已逐步更新的文件将具有多个trailer词典和文件结束标记。
通过这种方式,PDF应用程序可以以相反的顺序读取交叉引用部分,以构建文件中每个对象的最新版本的列表。
Object and Cross-Reference Stream 对象和交叉引用流
从PDF 1.5开始,引入了一种新机制,通过允许将多个对象放入单个
对象流中来进一步压缩PDF文件,整个流被压缩。同时,引入了一种用于引用这些流中的对象的新机制 —— 交叉引用流。
文件通常使用几组对象流,将特定时间所需的对象组合在一起,例如第一页上的所有对象,第二页上的所有对象,等等。这保留了文档的随机访问属性,如果将文件中的所有对象放入单个对象流中,该属性将丢失。对象流不能包含其他流。
使用这些机制压缩的文件很难手动读取,因此我们可以像往常一样使用pdftk中的解压缩操作,将它们重写为解压缩以供检查。
Linearized PDF 线性化 PDF
在网络环境中查看大型PDF文件时,尤其是当数据速率较低或网络延迟较高时,用户不希望等待整个文件下载以查看它。
在Web浏览器中查看文档时,这一点尤为重要。我们希望第一页快速显示,并且要更改为另一页(通过单击超链接或书签)尽可能快。
网络传输机制例如HTTP(超文本传输协议,用于在Web浏览器中获取网页)通常允许获取任意数据块。但是,因为延迟,我们希望获取一个包含页面所有数据的块,而不是数百个小块,每个对象一个。
PDF 1.2引入了这样一种机制,线性化PDF。这将添加有关如何对文件中的对象进行排序的规则。该系统是向后兼容的,因此线性化的PDF文件可以由不理解线性化PDF的阅读器读取。
线性化的PDF文件可以通过文件顶部直接在标题之后存在线性化字典来识别。例如:
%PDF-1.4
%âãÏÓ
4 0 obj
<< /E 200967/H [ 667 140 ]/L 201431/Linearized 1/N 1/O 7/T 201230
>>
endobj
如何读取PDF文件
要读取PDF文件,将其从一系列平坦的字节转换为内存中对象的图形,
通常可能会发生以下步骤:
- 从文件开头读取PDF header,确认这确实是PDF文档并检索其版本号。
- 现在通过从末尾向后搜索找到文件结束标记。现在可以读取trailer字典,以及startxref的字节偏移量检索交叉引用表。
- 现在可以读取交叉引用表,知道每个对象是在文件哪里了。
- 在此阶段,可以读取和解析所有对象,或者我们可以离开此过程直到实际需要每个对象,按需阅读。
- 我们现在可以使用数据,提取页面,解析图形内容,提取元数据等。
这不是详尽的描述,因为存在许多可能的复杂性(线性化,对象和交叉引用流,加密)。
以下伪代码中给出的递归数据结构可以包含PDF对象。
pdfobject ::= Null| Boolean of bool| Integer of int| Real of real| String of string| Name of string| Array of pdfobject array| Dictionary of (string, pdfobject) array Array of (string, pdfobject) pairs | Stream of (pdfobject, bytes) Stream dictionary and stream data| Indirect of int
例如,对象<< /Kids [2 0 R] /Count 1 /Type /Pages >>可能表示为:
Dictionary((Name (/Kids), Array (Indirect 2)),(Name (/Count), Integer (1)), (Name (/Type), Name (/Pages)))
如何编写PDF文件
将PDF文档写入文件中的一系列字节要比阅读它简单得多,我们不需要支持所有PDF格式,只需要支持我们打算使用的子集。写作PDF文件非常快,因为它只是将对象图展平为一系列字节。
- 输出header。
- 删除PDF中未引用的对象,这个避免编写不再需要的对象。
- 重新编号对象,使它们从1到n运行,其中n是对象的数量文件。
- 逐个输出对象,从对象编号1开始,在交叉引用表中记录每个对象偏移量,并编写交叉引用表。
- 编写trailer字典,交叉引用表偏移量和文件结束标记
文档结构
现在我们考虑下文档结构。trailer字典,文档目录和页面树。我们枚举每个对象中的必需条目。然后我们看看PDF文件中的两个常见结构:文本字符串和日期。
下图显示了典型文档的逻辑结构。

Trailer 字典
这个字典驻留在文件的trailer而不是文件的主体中,是程序想要读取PDF文档时要处理的第一件事。它包含允许读取交叉引用表的条目,从而可进行后续文件对象的读取。
| 键 | 值类型 | 值 |
|---|---|---|
| /Size* | 整数 | 文件交叉引用表中的条目总数(通常等于文件中的对象数加1) |
| /Root* | 间接引用字典 | 文件目录 |
| /Info | 间接引用字典 | 文档信息字典 |
| /ID | 两个字符串的数组 | 唯一标识工作流程中的文件。第一个字符串在首次创建文件时确定,第二个字符串在工作流系统修改文件时进行修改 |
这是一个示例trailer词典:
<</Size 421/Root 377 0 R/Info 375 0 R/ID [<75ff22189ceac848dfa2afec93deee03> <057928614d9711db835e000d937095a2>]
>>
一旦处理了trailer字典,我们就可以继续阅读文档信息字典和文档目录。
文档信息字典
文档信息字典包含文件的创建日期和修改日期,以及一些简单的元数据。文档信息字典条目在如下表格描述。
| 键 | 值类型 | 值 |
|---|---|---|
| /Title | 文本字符串 | 该文件的标题。请注意,这与第一页上显示的任何标题无关 |
| /Subject | 文本字符串 | 该文件的主题。同样,这只是元数据,没有关于内容的特定规则 |
| /Keywords | 文本字符串 | 与此文档相关的关键字。没有给出关于如何构建这些的建议 |
| /Author | 文本字符串 | 文件作者的姓名 |
| /CreationDate | 日期字符串 | 文档创建的日期 |
| /ModDate | 日期字符串 | 上次修改文档的日期 |
| /Creator | 文本字符串 | 最初创建此文档的程序的名称,如果它以另一种格式(例如,“Microsoft Word”)启动 |
| /Producer | 文本字符串 | 将此文件转换为PDF的程序的名称,如果它以另一种格式(例如,字处理器的格式)启动 |
这是一个示例Info词典:
<</ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00')/Title (catalogueproduit-UK.qxd)/Creator (QuarkXPress: pictwpstops filter 1.0) /Producer (Acrobat Distiller 6.0 for Macintosh) /Author (James Smith)/Subject (subject test)/Keywords (keywords test)
>>
文档目录
文档目录是主对象图的根对象,可以通过间接引用从中到达所有其他对象。在如下表格中,我们列出了必需(带*)的文档目录字典条目,以及许多可选的文档目录字典条目。
| 键 | 值类型 | 值 |
|---|---|---|
| /Type* | name | 必须是/Catalog |
| /Pages* | 间接引用字典 | 页面树的根节点 |
| /PageLabels | number tree | 一个数字树,给出了该文档的页面标签。这种机制允许文档中的页面具有比1,2,3更复杂的编号…例如,书籍的前言可以编号为i,ii,iii …,而主要内容 再次以1,2,3开始…这些页面标签显示在PDF查看器中 - 它们与打印输出无关 |
| /Names | dictionary | 名字词典。它包含各种名称树,它们将名称映射到实体,以防止必须使用对象编号直接引用它们 |
| /Dests | dictionary | 将名称映射到目标的字典。目的地是向用户发送的PDF文档中的超链接位置的描述 |
| /ViewerPreferences | dictionary | 一个查看器首选项字典,允许标志指定在屏幕上查看文档时的PDF查看器的行为,例如打开文档的页面,初始查看比例等 |
| /PageLayout | name | 指定PDF查看器要使用的页面布局。值为/SinglePage,/OneColumn,/TwoColumnLeft,/TwoColumnRight,/TwoPageLeft,/TwoPageRight。(默认值:/SinglePage)。详情见ISO 32000-1:2008的表28 |
| /PageMode | name | 指定PDF查看器要使用的页面模式。值为/UseNone,/UseOutlines,/UseThumbs,/FullScreen,/UseOC,/UseAttachments。(默认值:/UseNone)。详情见ISO 32000-1:2008的表28 |
| /Outlines | 间接引用字典 | 大纲字典是文档大纲的根,通常称为书签 |
| /Metadata | 间接引用流 | 文档的XMP元数据 |
页面和页面树
PDF文档中的页面字典汇集了使用指令来操作资源(字体,图像和其他外部数据)从而绘制图形和文本内容的说明。它还包括页面大小,以及定义裁剪等。
如下表格总结了页面字典中的条目。
| 键 | 值类型 | 值 |
|---|---|---|
| /Type* | name | 必须是/Page |
| /Parent* | 间接引用字典 | 页面树中此节点的父节点 |
| /Resources | dictionary | 页面的资源(字体,图像等)。如果完全省略此条目,则资源将从页面树中的父节点继承。如果确实没有资源,请包含此条目但使用空字典 |
| /Contents | 对这些引用的流或数组的间接引用 | 一个或多个部分中页面的图形内容。如果缺少此条目,则页面内容为空 |
| /Rotate | 整数 | 页面的查看旋转,以度为单位,从北向顺时针。值必须是90的倍数。默认值:0。这适用于查看和打印。如果缺少此条目,则其值将从页面树中的父节点继承 |
| /MediaBox* | rectangle | 页面的媒体框(媒体大小,即纸张)。对于大多数用途,页面大小。如果缺少此条目,则它将从页面树中的父节点继承 |
| /CropBox | rectangle | 页面的裁剪框。这定义了在显示或打印页面时默认可见的页面区域。如果不存在,则将其值定义为与媒体框相同 |
媒体框和其他框的矩形数据结构是四个数字的数组。这些定义了矩形的对角相对的角: 数组的前两个元素是一个角的x和y坐标,后两个元素是另一个角的x和y坐标。
通常,给出左下角和右上角,如下示例:
/MediaBox [0 0 500 800]
/CropBox [100 100 400 700]
定义一个500 x 800点的页面,裁剪框在页面的每一侧删除100个点。
页面使用页面树而不是简单的数组链接在一起。这种树结构使得在具有数百或数千页的文档中查找给定页面变得更快。
好的PDF应用程序构建了一个平衡树(一个节点数量最小的树)。这可确保快速定位特定页面。没有子节点的节点就是页面本身。
下表总结了中间或根页面树节点中的条目(即,不是页面本身)。
| 键 | 值类型 | 值 |
|---|---|---|
| /Type* | name | 必须是/Pages |
| /Kids* | 间接引用数组 | 此节点的直接子页面树节点 |
| /Count* | 整数 | 页节点(不是其他页面树节点)的数量,它们是此节点的最终子节点 |
| /Parent | 间接引用页面树节点 | 引用此节点的父节点(此节点是其子节点)。如果不是页面树的根节点,则必须存在 |
下图显示了七页的示例页面树结构。

PDF对象编写如下,
1 0 obj % Root node
<< /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >>
endobj
2 0 obj % Intermediate node
<< /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >> endobj
3 0 obj % Intermediate node
<< /Type /Pages /Kids [8 0 R 9 0 R 10 0 R] /Parent 1 0 R /Count 3 >> endobj
4 0 obj % Page 7
<< /Type /Page /Parent 1 0 R /MediaBox [0 0 500 500] /Resources << >> >> endobj
5 0 obj % Page 1
<< /Type /Page /Parent 2 0 R /MediaBox [0 0 500 500] /Resources << >> >> endobj
6 0 obj % Page 2
<< /Type /Page /Parent 2 0 R /MediaBox [0 0 500 500] /Resources << >> >> endobj
7 0 obj % Page 3
<< /Type /Page /Parent 2 0 R /MediaBox [0 0 500 500] /Resources << >> >> endobj
8 0 obj % Page 4
<< /Type /Page /Parent 3 0 R /MediaBox [0 0 500 500] /Resources << >> >> endobj
9 0 obj % Page 5
<< /Type /Page /Parent 3 0 R /MediaBox [0 0 500 500] /Resources << >> >> endobj
10 0 obj % Page 6
<< /Type /Page /Parent 3 0 R /MediaBox [0 0 500 500] /Resources << >> >> endobj
在此树中,任何页面最多可以找到两个远离根节点的间接引用。
文本字符串
页面的实际文本内容之外的字符串(例如,书签名称,文档信息等)被称为文本字符串。它们使用PDFDocEn编码或(在最近的文档中)Unicode编码。PDFDocEncoding基于ISO Latin-1编码。它完全记录在ISO标准32000-1:2008的附录D中。
编码为Unicode的文本字符串通过查看前两个字节来区分:这些字符将是254后跟255.这是Unicode字节顺序标记U + FEFF,表示UTF16BE编码。这意味着PDFDocEncoding字符串不能以þ(254)后跟ÿ(255)开头,但这在任何合理的情况下都不太可能发生。
日期
文档信息字典中的创建和修改日期/CreationDate和/ModDate是PDF日期格式的示例,对字符串中的日期进行编码,包括有关时区的信息。
日期字符串的格式为: (D:YYYYMMDDHHmmSSOHH'mm')
其中括号表示通常的字符串。该日期的其他部分在如下表格中进行了总结。
| Portion | 含义 |
|---|---|
| YYYY | 年份,有四位数,例如2008年 |
| MM | 月份,从01到12的两位数 |
| DD | 天数,从01到31的两位数 |
| HH | 小时,从00到23的两位数 |
| mm | 分钟,从00到59两位数 |
| SS | 秒钟,从00到59两位数 |
| O | 本地时间与世界时的关系,+,- 或Z。 +表示本地时间晚于UT,- 更早,Z等于世界时 |
| HH’ | 世界时的偏差绝对值,以小时为单位,以00到23的两位数表示 |
| mm’ | 通用时间偏移的绝对值,以分钟为单位,从00到59两位数 |
一年之后的所有日期都是可选的。例如,(D:1999)完全有效。但是,很明显,如果省略一个部分,
则必须省略后面的所有内容,否则结果将是模糊的。DD和MM的默认值为01,对于所有其他部分,默认值为零。
例如:(D:20060926213913+02'00')
如果当前在中国,为东8区,则当前时间为2006年9月27日3:39:13。
把它放在一起
这是一个手动创建的文本,由pdftk处理成有效的PDF文件,它是一个三页文档,包含文档信息字典和页面树。
相应的对象图

%PDF-1.0 % 文件头
1 0 obj % Top-level of page tree: has two children—page one and an intermediate page tree node
<< /Kids [2 0 R 3 0 R] /Type /Pages /Count 3 >>
endobj
4 0 obj % Contents stream for page one
<< >>
stream
1. 0.000000 0.000000 1. 50. 770. cm BT /F0 36. Tf (Page One) Tj ET
endstream
endobj
2 0 obj % Page one
<</Rotate 0 /Parent 1 0 R /Resources<< /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >> /MediaBox [0.000000 0.000000 595.275590551 841.88976378]/Type /Page/Contents [4 0 R]
>>
endobj
5 0 obj % Document catalog
<< /PageLayout /TwoColumnLeft /Pages 1 0 R /Type /Catalog >> endobj
6 0 obj % Page three
<</Rotate 0 /Parent 3 0 R /Resources<< /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >> /MediaBox [0.000000 0.000000 595.275590551 841.88976378]/Type /Page/Contents [7 0 R]
>>
endobj
3 0 obj % Intermediate page tree node, linking to pages two and three
<< /Parent 1 0 R /Kids [8 0 R 6 0 R] /Count 2 /Type /Pages >>
endobj
8 0 obj % Page two
<</Rotate 270 /Parent 3 0 R /Resources<< /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >> /MediaBox [0.000000 0.000000 595.275590551 841.88976378]/Type /Page/Contents [9 0 R]
>>
endobj
9 0 obj % Content stream for page two
<< >>
stream
q 1. 0.000000 0.000000 1. 50. 770. cm BT /F0 36. Tf (Page Two) Tj ET Q
1. 0.000000 0.000000 1. 50. 750 cm BT /F0 16 Tf ((Rotated by 270 degrees)) Tj ET
endstream
endobj
7 0 obj % Content stream for page three
<< >>
stream
1. 0.000000 0.000000 1. 50. 770. cm BT /F0 36. Tf (Page Three) Tj ET
endstream
endobj
10 0 obj % Document information dictionary
<</Title (PDF Explained Example) /Author (John Whitington) /Producer (Manually Created) /ModDate (D:20110313002346Z) /CreationDate (D:2011)
>>
endobj
xref
0 11
trailer % Trailer dictionary
<</Info 10 0 R/Root 5 0 R/Size 11/ID [<75ff22189ceac848dfa2afec93deee03> <057928614d9711db835e000d937095a2>]
>>
startxref
0
%%EOF
显示的效果
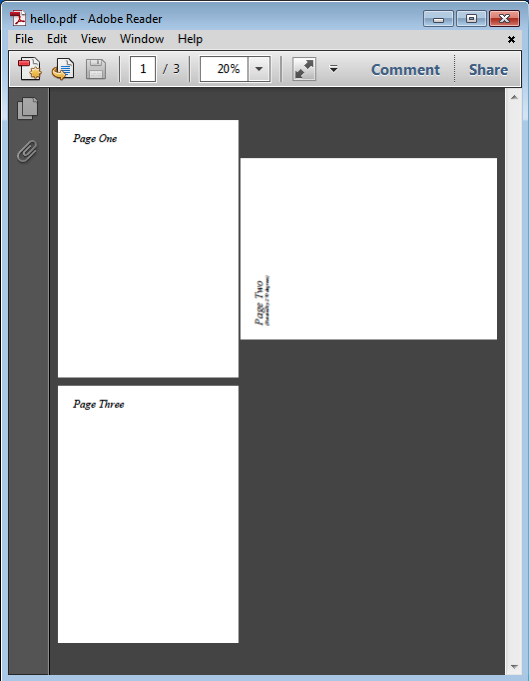
参考
- PDF 解析中文版
- pdf1.7 标准英文参考