- 👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:源码溯源,一探究竟
- 📝联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
文章目录
- 项目性能优化
- 性能问题分析
- 01-性能优化的终极目标是什么?
- 02-什么样的体验叫快呢?
- 03-怎么让系统快起来呢?
- 04-应用性能调优是个大工程
- 05-影响性能的关键要素
- 产品设计:产品逻辑、功能交互、动态效果、页面元素
- 基础网络:网络 = 连接介质 + 计算终端
- 代码质量&架构
- 移动端环境
- 硬件及云服务
- 压力测试
- 主机环境
- 什么是压力测试?
- 案例:SpringBoot项目不做任何配置,TPS上限是多少?
- 手把手带你创建压测案例
- 1)新建测试计划
- 2)配置线程组:
- 3)配置HTTP接口:
- 4)配置断言:
- 5)配置结果监听:
- 压测结果
- 1)聚合报告:
- 2)察看结果树:
- 3)汇总图与图形结果
- 4)汇总报告【类似于聚合报告】
- 线程组配置详解
- 01-线程数:用来发送http请求的线程的数量
- 02-循环次数:循环执行多少次操作
- 03-Ramp-Up:建立全部线程耗时
- JMeter常用插件
- 01-配置插件
- 响应时间:jp@gc - Response Times
- 活动线程数:jp@gc - Active Threads
- 每秒事务数:jp@gc - Transactions per Second
- 02-性能关键指标分析
- 服务器硬件资源监控【精简版】
- 01-配置服务端代理
- 02-监控CPU:
- 03-监控网络:
- 04-监控内存:
- 05-监控系统整体负载情况:
- 06-性能关键指标分析
- 2)系统负载: load average
- 单核CPU三种Load情况
- 双核CPU
- 压测监控平台
- 梯度压测:分析接口性能瓶颈
- 压测配置:
- 机器环境
- 配置监听器:
- 性能瓶颈剖析
- 1)梯度压测,测出瓶颈
- 2)问题1:网络到达瓶颈
- 3)问题2:接口的响应时间是否正常?是不是所有的接口响应都这么快?
- 4)问题3:TPS在上升到一定的值之后,异常率较高
- 分布式压测
- Windows Server部署JMeter Master
- Linux部署JMeter Salve
- 分布式环境配置
项目性能优化
性能问题分析
01-性能优化的终极目标是什么?
用户体验 = 产品设计(非技术) + 系统性能 ≈ 系统性能 = 快?
应用性能是产品用户体验的基石,性能优化的终极目标是优化用户体验。当我们谈及性能,最直观能想到的一个词是“快”,哪到底怎么才是快呢?如何又为慢!
02-什么样的体验叫快呢?
- 3S定理:Strangeloop在对众多的网站做性能分析之后得出了一个著名的3s定律“页面加载速度超过3s,57%的访客会离开”。
- SEO排名:速度在Google、百度等搜索引擎的PR评分中也占有一定的比例,会影响到网站的SEO排名。
03-怎么让系统快起来呢?
性能优化
04-应用性能调优是个大工程
- 后端:RT、TPS、并发数 。TPS和RT的影响因素:数据库读写、RPC、网络IO、逻辑计算复杂度、JVM
- Web端:首屏时间、白屏时间、可交互时间、完全加载时间…
- 移动端:端到端响应时间、Crash率、内存使用率、FPS…
首屏时间是指从用户打开网页开始到浏览器第一屏渲染完成的时间,是最直接的用户感知体验指标,也是性能领域公认的最重要的核心指标。
首屏时间 = DNS时间 + 建立连接时间 + 后端响应时间 + 网络传输时间 + 首屏页面渲染时间
FPS是体现页面顺畅程度的一个重要指标。
端到端响应时间是衡量一个API性能的关键指标,比纯后端响应时间更全面,它会受到DNS、网络带宽、网络链路、HTTP Payload等多个因素的影响。
端到端响应时间 = DNS解析时间 + 网络传输时间 + 后端响应时间。
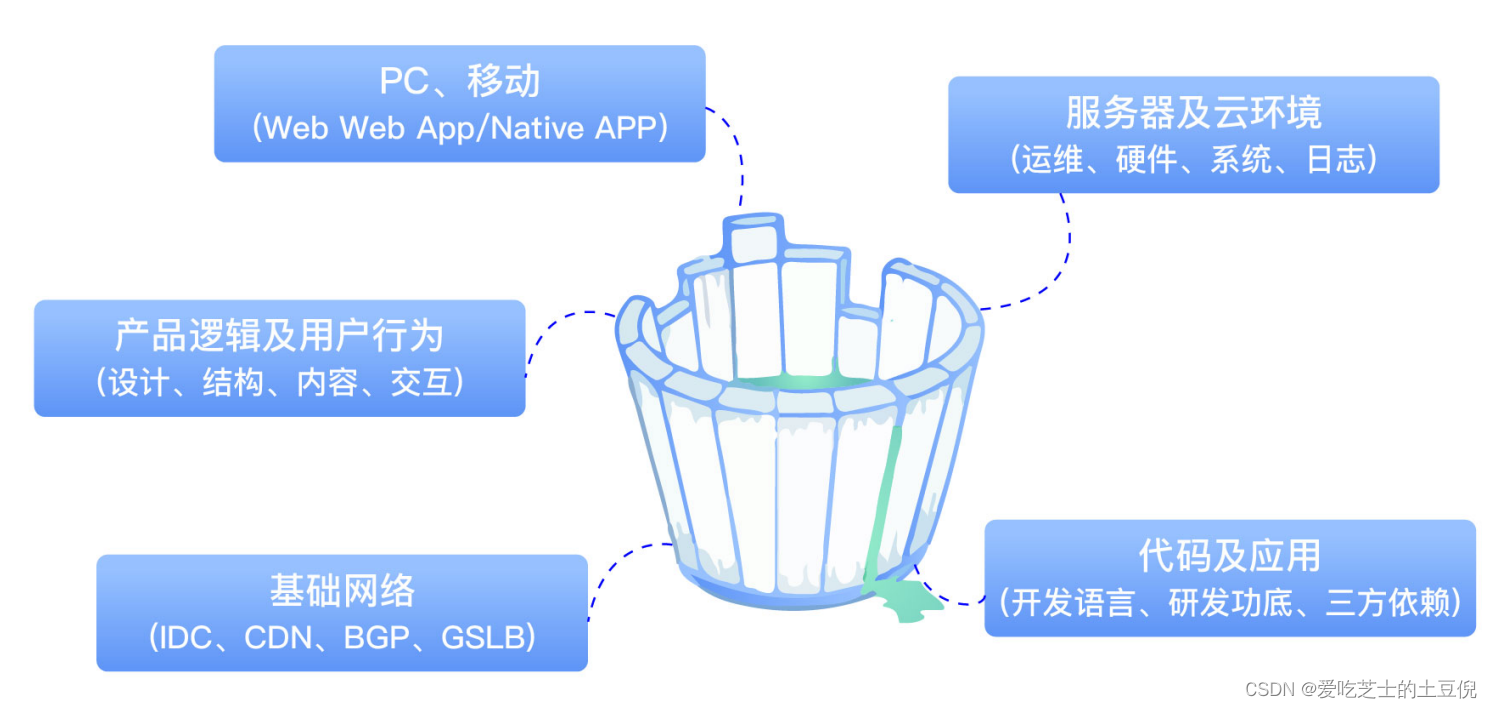
05-影响性能的关键要素
产品设计:产品逻辑、功能交互、动态效果、页面元素
12306购票案例查询按钮的设计
基础网络:网络 = 连接介质 + 计算终端
- 连接介质:电缆、双绞线、光纤、微波、载波或通信卫星。
- 计算终端:PC、手机、可穿戴设备、家具家电…
- 基础网络设施,互联网,局域网(LAN)、城域网(MAN)、广域网(WAN)
代码质量&架构
- 架构不合理
- 研发功底和经验不足
- 没有性能意识:只实现了业务功能不注意代码性能,新功能上线后整体性能下降,或当业务上量后系统出现连锁反应,导致性能问题叠加,直接影响用户体验。
移动端环境
硬件及云服务
- 架构不合理:业务发展超越架构支撑能力而导致系统负荷过载,进而导致出现系统奔溃、响应超时等现象。另外不合理的架构如:单点、无cache、应用混部署、没有考虑分布式、集群化等也都会影响性能。
- 研发功底和经验不足:开发的App、Server效率和性能较低、不稳定也是常见的事情。
- 没有性能意识:只实现了业务功能不注意代码性能,新功能上线后整体性能下降,或当业务上量后系统出现连锁反应,导致性能问题叠加,直接影响用户体验。
- 多数的性能问题发生在数据库上。由慢SQL、过多查询等原因造成的数据库瓶颈,没有做读写分离、分库分表等。
压力测试
主机环境
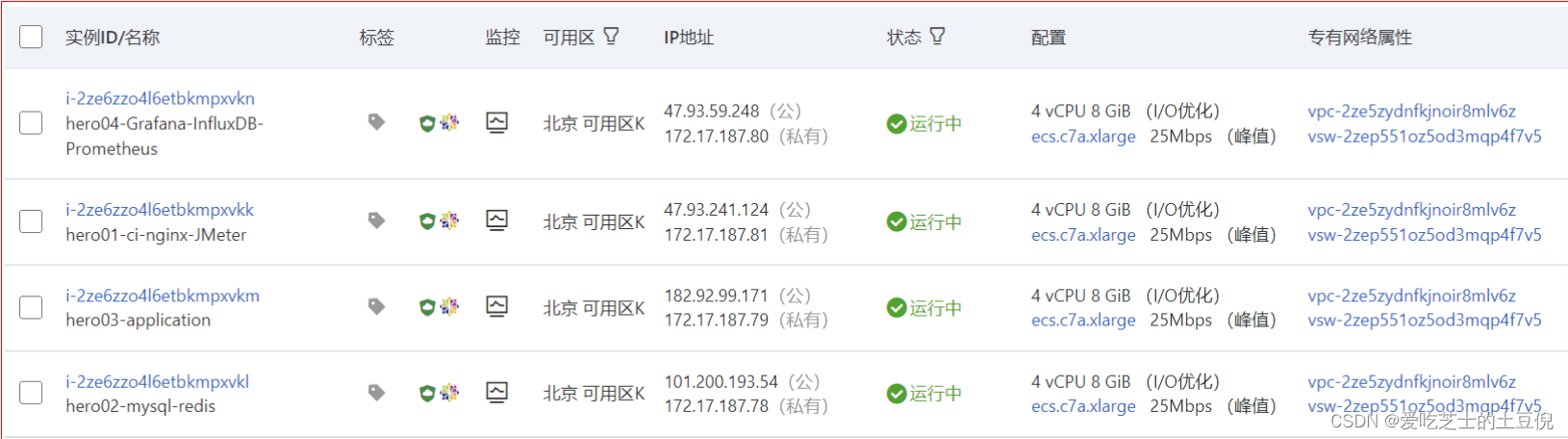
阿里云:5台4C8G机器,4台压力机2C4G
服务器环境:1台压力机,1台应用服务主机,1台数据库与缓存服务器,1CICD服务器
- hero01:CICD服务器4C8G:Nginx、JMeter、CICD
内网ip:172.17.187.81(I/O优化)25Mbps峰值
- hero02:数据库与缓存服务器4C8G:MySQL、Redis、MQ、ES
内网ip:172.17.187.78(I/O优化)25Mbps峰值
- hero03:应用服务器01-4C8G:Application
内网ip:172.17.187.79(I/O优化)25Mbps峰值
- hero04:监控服务器02-4C8G:Grafana、Prometheus、InfluxDB
内网ip:172.17.187.80(I/O优化)25Mbps峰值
网络中的Mbps和MBps,及两者的换算关系
Mbps = Megabit per second (Mbit/s or Mb/s)
MBps = Megabyte per second
1 Mbps = 0.125 MB/s
25Mbps = 3.125 MB/s
什么是压力测试?
什么是压测?
压力测试(英语:Stress testing)是针对特定系统或是组件,为要确认其稳定性而特意进行的严格测试。会让系统在超过正常使用条件下运作,然后再确认其结果。
压力测试是对系统不断施加压力,来预估系统服务能力的一种测试。
为什么对系统压测呢?有没有必要。压不压测要看场景!
一般而言,只有在系统基础功能测试验证完成、系统趋于稳定的情况下,才会进行压力测试。
目的是什么?
- 当负载逐渐增加时,观察系统各项性能指标的变化情况是否有异常
- 发现系统的性能短板,进行针对性的性能优化
- 判断系统在高并发情况下是否会报错,进程是否会挂掉
- 测试在系统某个方面达到瓶颈时,粗略估计系统性能上限
压测性能指标有哪些?

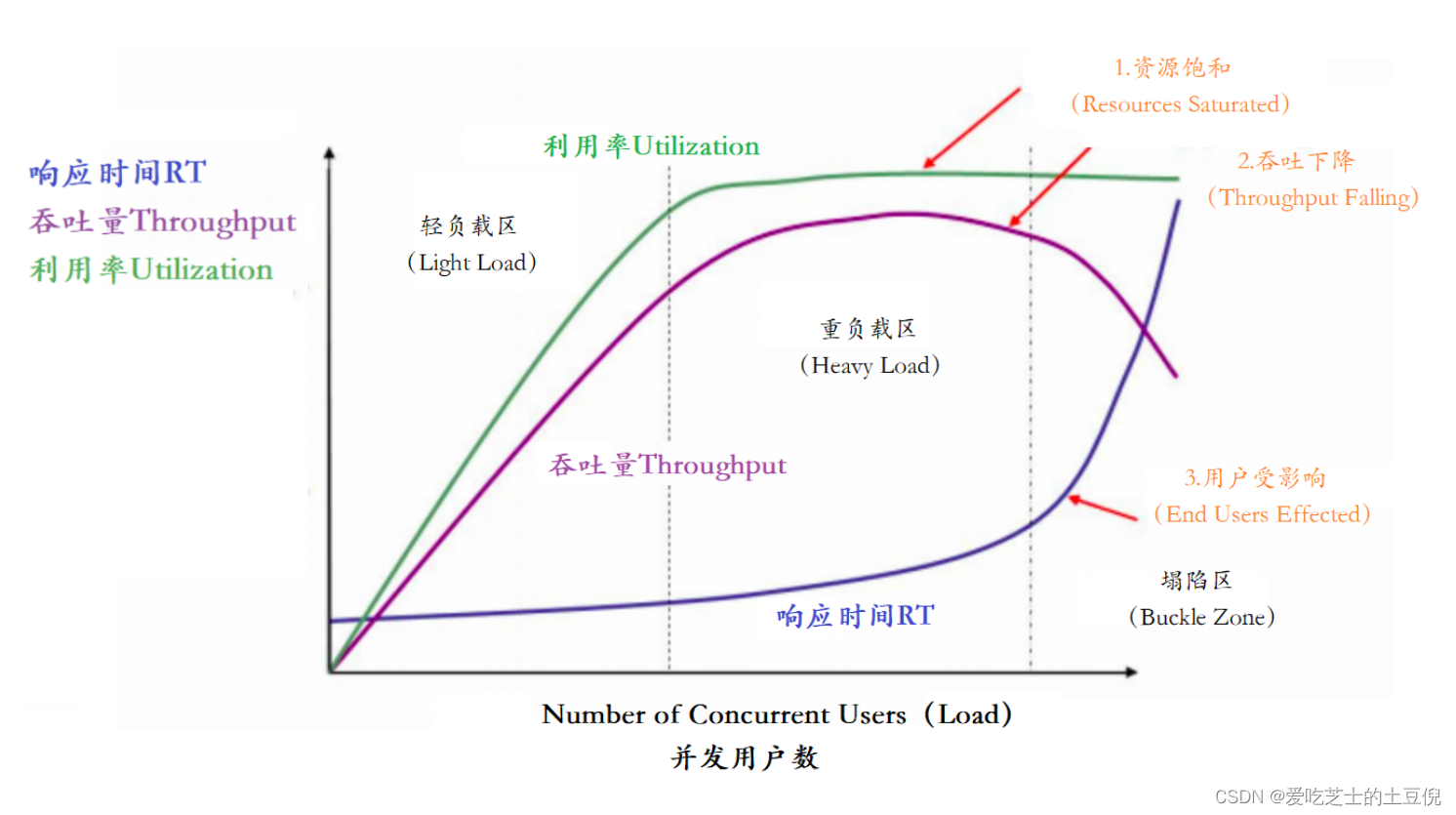
以上主要的四种性能指标【响应时间、并发用户数、吞吐量、资源使用率】它们之间存在一定的相关性,共同反映出性能的不同方面。
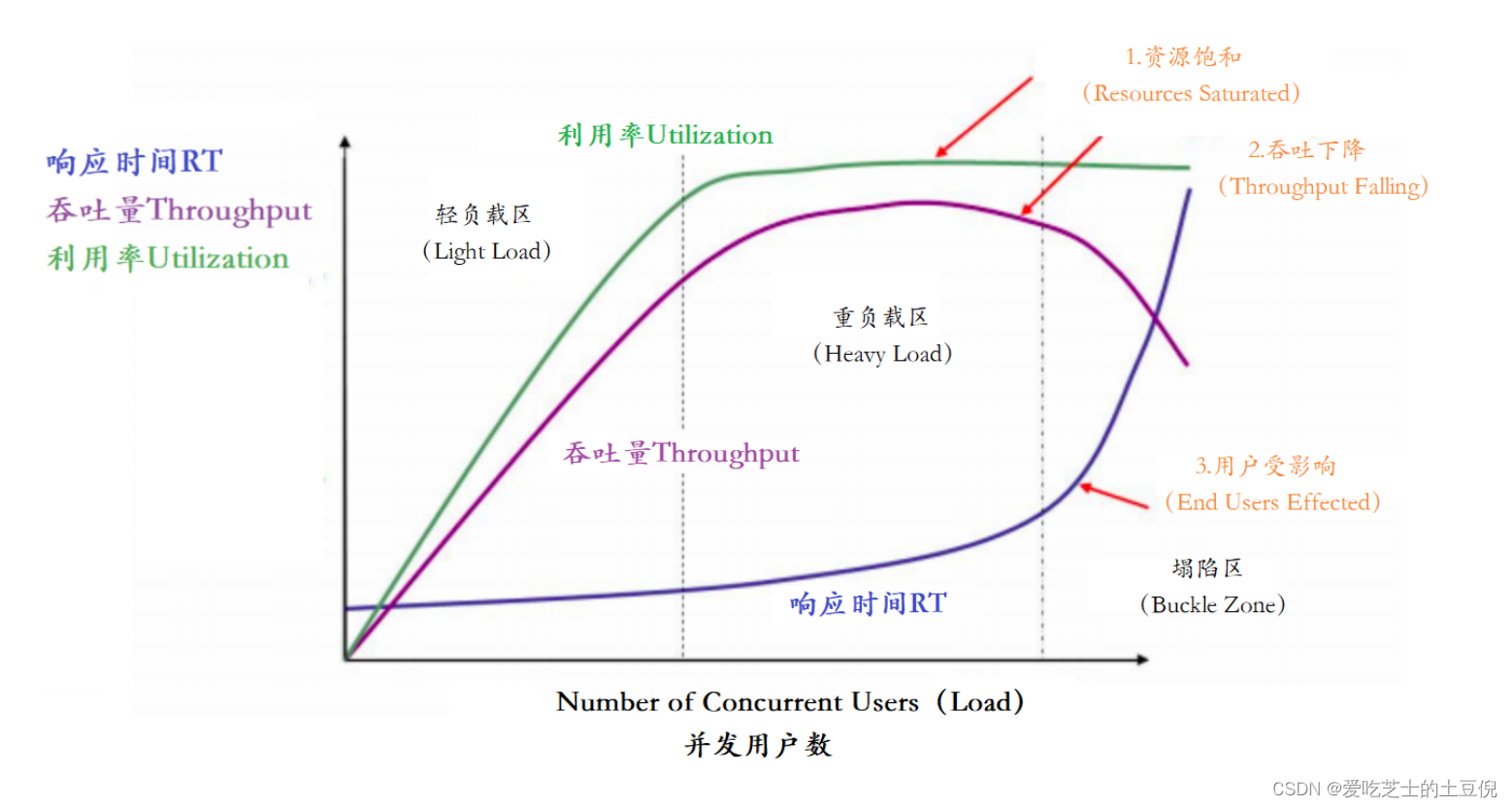
在这个图中,定义了三条曲线、三个区域、两个点以及三个状态描述。
三条曲线:
- 吞吐量的曲线(紫色)
- 利用率(绿色)
- 响应时间曲线(深蓝色)
三个区域:
- 轻负载区(Light Load)
- 重负载区(Heavy Load)
- 塌陷区(Buckle Zone)
两个点:
- 最优并发用户数(The Optimum Number of Concurrent Users)
- 最大并发用户数(The Maximum Number of Concurrent Users)
三个状态描述:
- 资源饱和(Resource Saturated)
- 吞吐下降(Throughput Falling)
- 用户受影响(End Users Effected)
常用压测工具:
- Apache JMeter : 可视化的测试工具
- Apache的ab压力测试
- nGrinter 韩国研发
- PAS 阿里测试工具
- MeterSphere :国内持续测试的开源平台
- 等等
JMeter压测环境架构图:
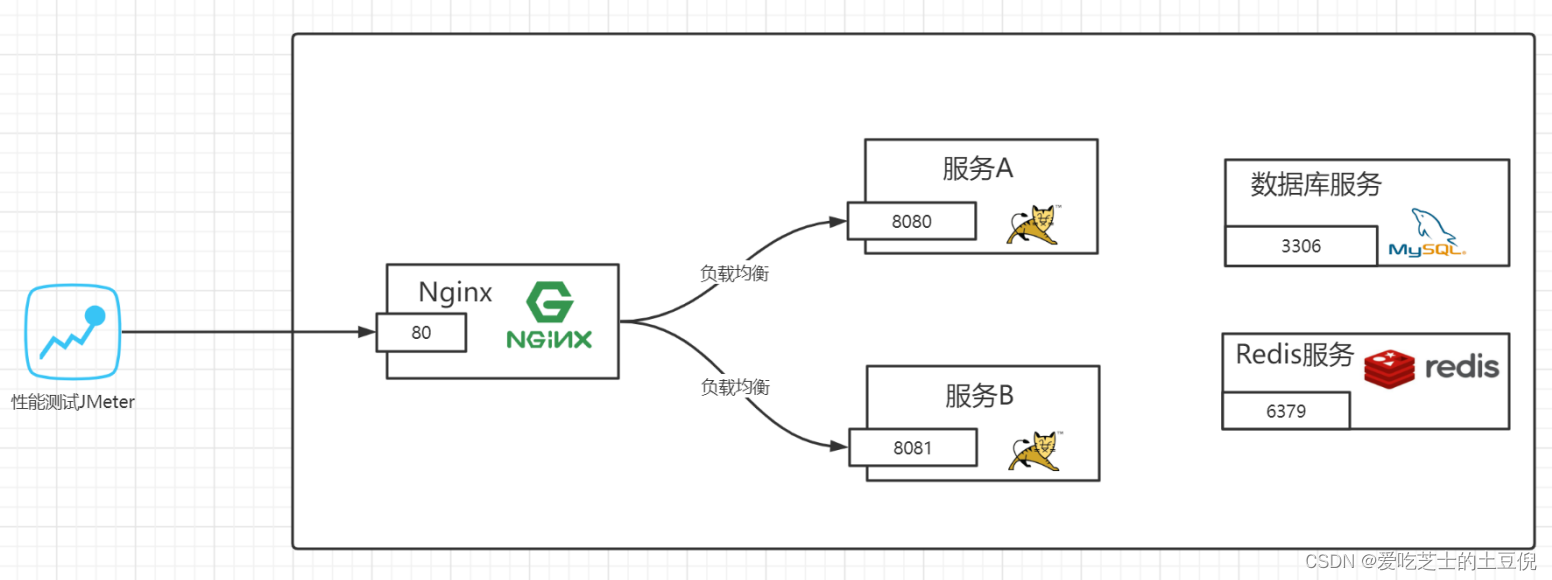
压测目标总的来说有4条:
- 负载上升各项指标是否正常
- 发现性能短板
- 高并发下系统是否稳定
- 预估系统最大负载能力
案例:SpringBoot项目不做任何配置,TPS上限是多少?
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。 它可以用于测试静态和动态资源,例如静态文件、Java 小服务程序、CGI 脚本、Java 对象、数据库、FTP 服务器, 等等。JMeter 可以用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能。另外,JMeter能够对应用程序做功能/回归测试,通过创建带有断言的脚本来验证你的程序返回了你期望的结果。为了最大限度的灵活性,JMeter允许使用正则表达式创建断言。
手把手带你创建压测案例
目标:完成压测案例,评测SpringBoot项目的吞吐量(TPS)上限。
步骤:
- 创建测试计划
- 配置线程组、http请求、断言、结果监听器
- 执行测试
- 查看测试结果,分析测试结果
实现:
1)新建测试计划
2)配置线程组:
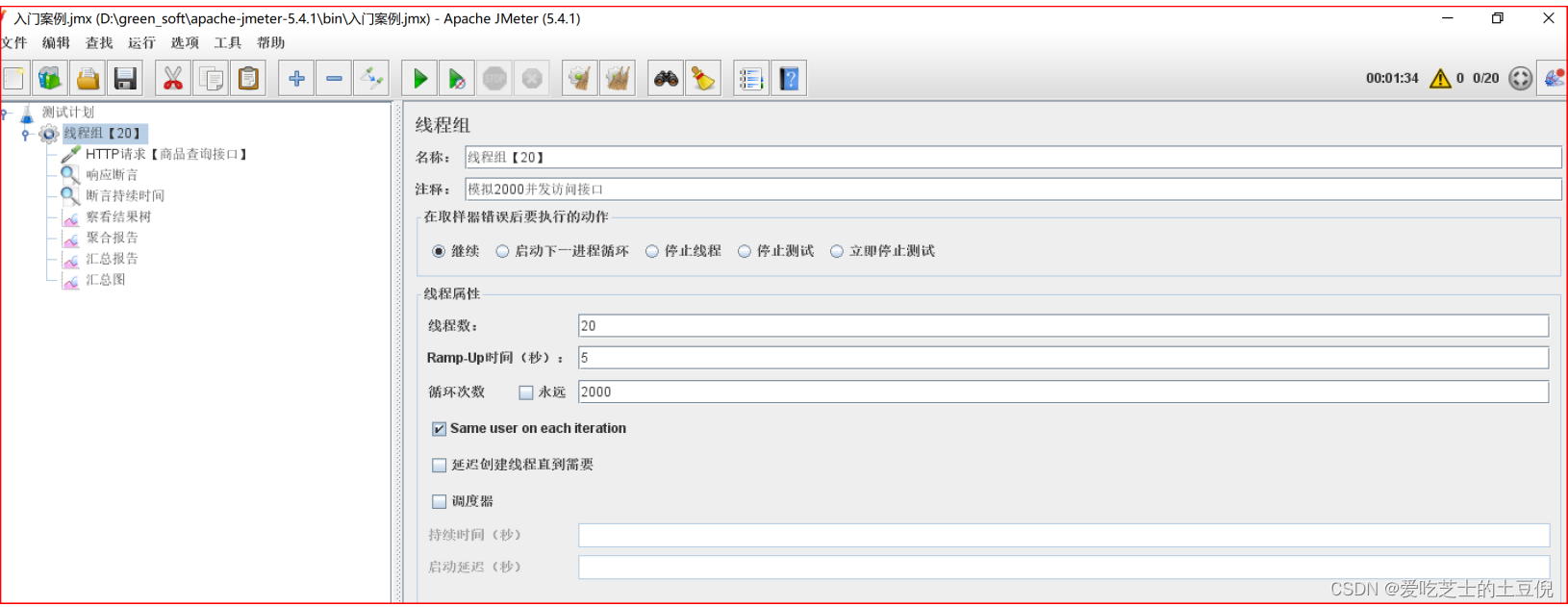
线程属性说明:
- 线程数:20, 线程数量,这里设置了20个线程
- ramp-up:表示在指定时间之内把这些线程全部启动起来。 如果n=1,那就表示要在1s以内把50个线程全部启动起来。
- 循环次数:2000,表示把 20 线程 循环2000次,也就是说让线程循环调用接口2000次
3)配置HTTP接口:
http://123.56.249.139:9001/spu/goods/10000005620800
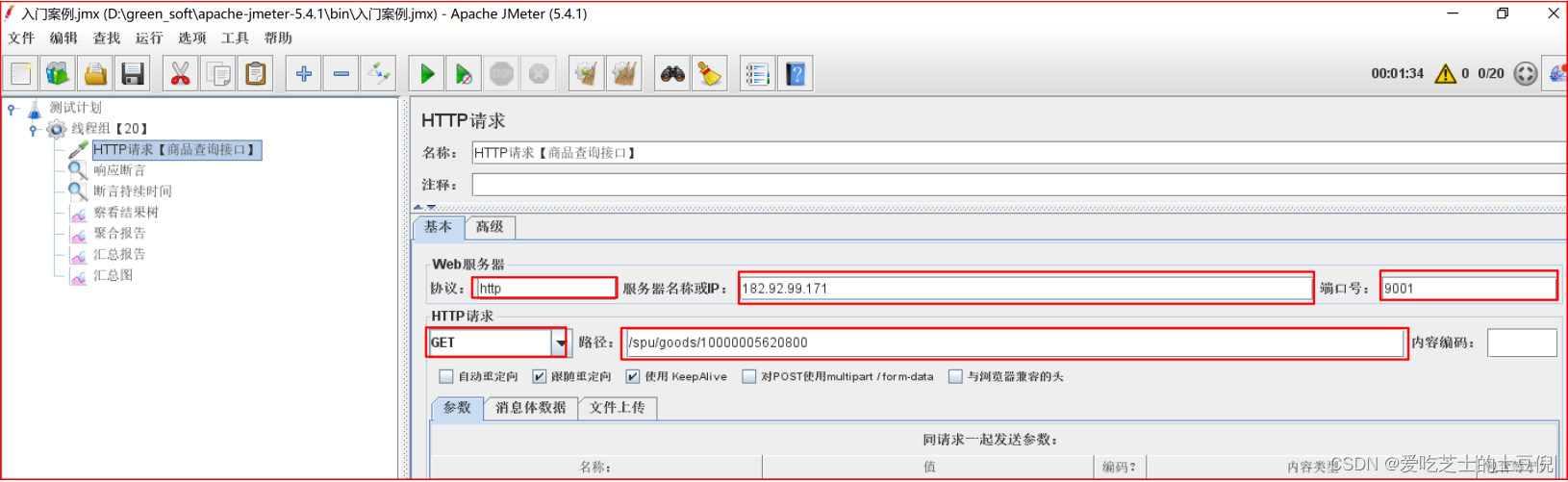
选择keepalive方式,表示使用了长连接。使用长连接可以防止频繁的建立连接,关闭连接消耗性能。一般浏览器都支持keepalive,如果这里不勾选,这样我们的压测的部分性能消耗会发生在建立,关闭连接上,导致我们的压测数据不准确。
4)配置断言:
JMeter断言常用有两种,一种是响应断言,一种是响应时间断言,如果响应内容不满足断言的配置,则认为这次的请求是失败的。
- 响应断言:判断响应内容是否包含指定的字符信息,用于判断api接口返回内容是否正确。
- 响应时间断言:判断响应时间,是否超过预期的时间,用于判断api接口返回时间是否超过预期。
(1)断言添加方式:右击测试计划的http请求,选择添加–>断言–>加响应断言和断言持续时间。
(2)配置响应断言:我们接口正常返回code值为20001,如果接口返回code值不是20001表示接口异常,为了测试,这里修改为接口返回code值不为20001则表示访问失败。
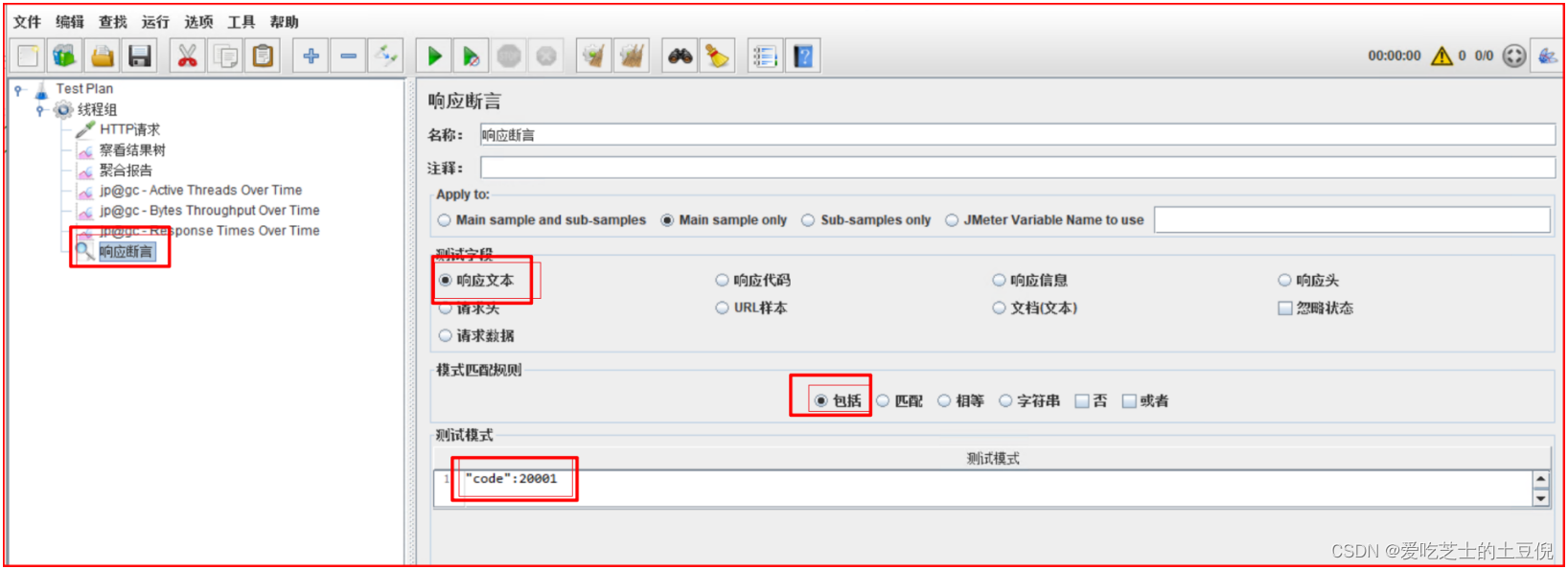
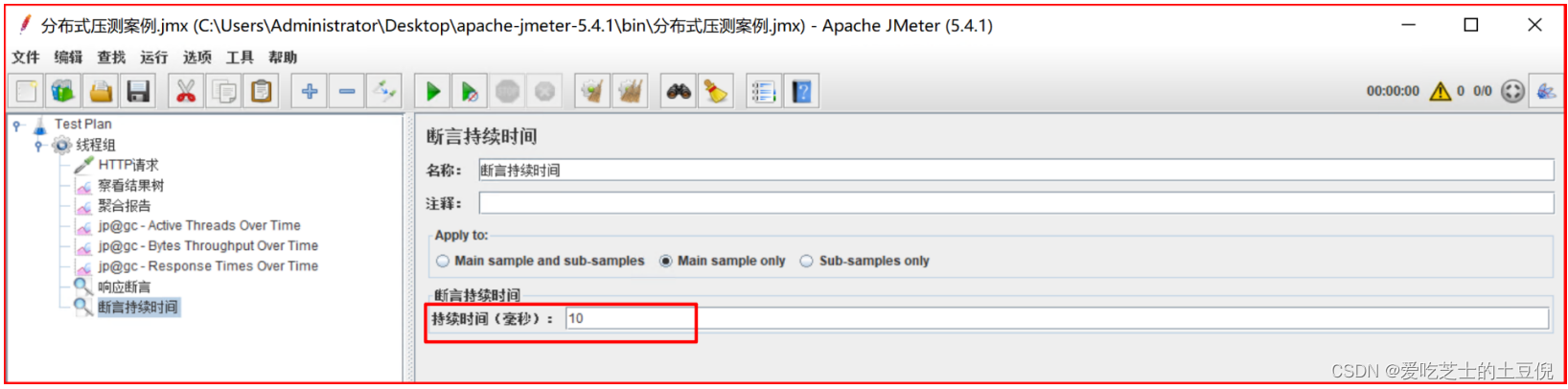
(3)配置断言响应时间:设置请求接口时间超过10毫秒,则认为请求失败。
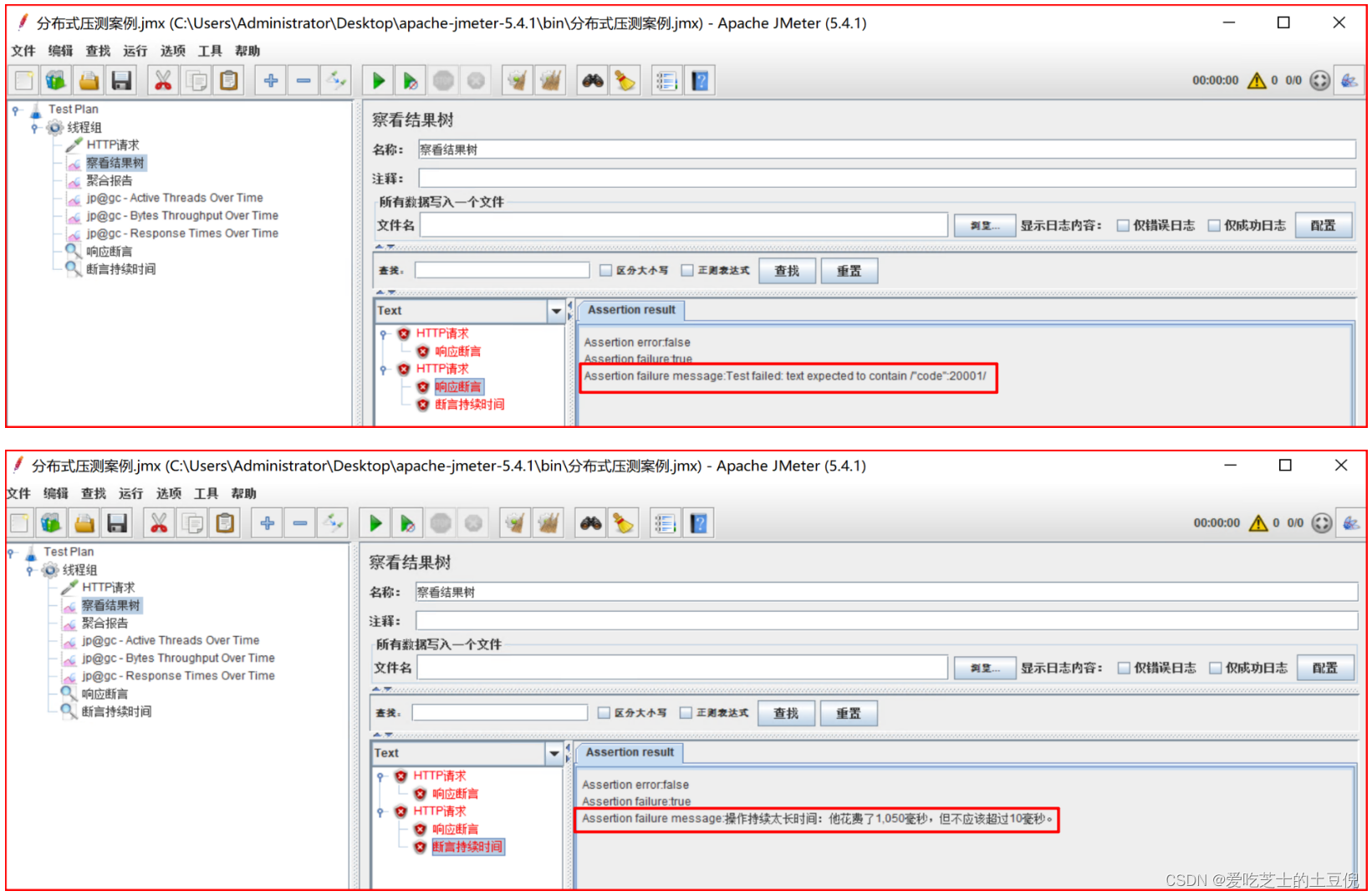
(4)验证断言配置:发起http请求,由于返回内容code值不为20001,以及访问时间超过10毫秒,所以认为访问失败。
5)配置结果监听:
配置监听器:监听压测结果【聚合报告和汇总结果很类似,看一个就行】
- 聚合报告:查询结果信息聚合汇总,例如样本、平均值、通吐量、最大值、最小值…
- 察看结果树:记录每一次压测请求
- 图像结果:分析了所有请求的平均值、中值、偏离值和通吐量之间的关系。
- 汇总结果:汇总压测结果
- 汇总图:将压测结果以图像形式展示
压测结果
1)聚合报告:

样本(sample): 发送请求的总样本数量
响应时间【单位ms】:
- 平均值(average):平均的响应时间
- 中位数(median): 中位数的响应时间,50%请求的响应时间
- 90%百分位(90% Line): 90%的请求的响应时间,意思就是说90%的请求是<=1765ms返回,另外10%的请求是大于等于1765ms返回的。
- 95%百分位(95% Line): 95%的请求的响应时间,95%的请求都落在1920ms之内返回的
- 99%百分位(99% Line): 99%的请求的响应时间
- 最小值(min):请求返回的最小时间,其中一个用时最短的请求
- 最大值(max):请求返回的最大时间,其中一个用时最长的请求
异常(error): 出现错误的百分比,错误率=错误的请求的数量/请求的总数
吞吐量(throughout): 吞吐能力,在这里相当于TPS
Received KB/sec----每秒从服务器端接收到的响应数据量
Sent KB/sec----每秒从客户端发送的请求的数量
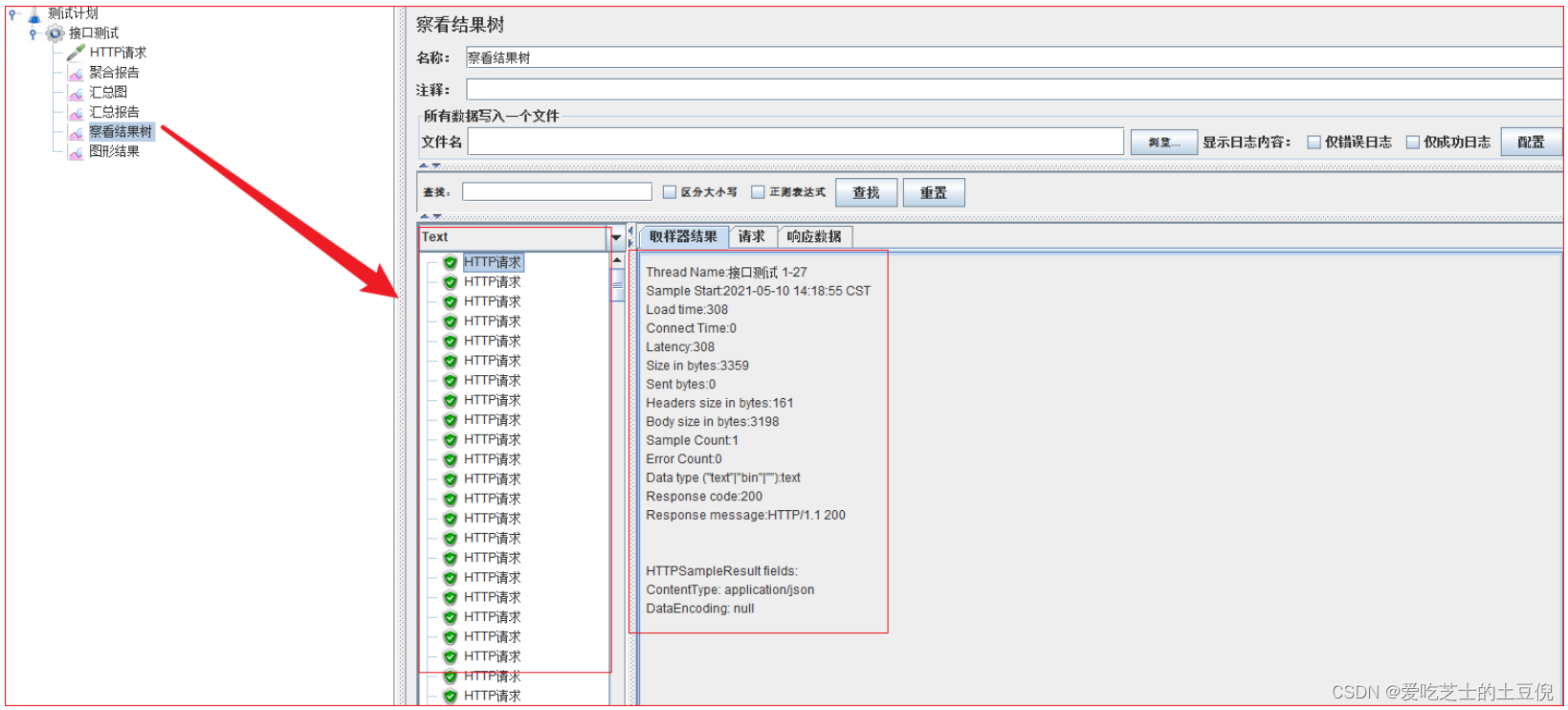
2)察看结果树:
记录了样本中的每一次请求
3)汇总图与图形结果
图形结果:分析了所有请求的平均值、终止、偏离值和通吐量之间的关系
横坐标:为请求数量,单位个数
纵坐标:响应时间,单位ms
4)汇总报告【类似于聚合报告】

样本(sample): 发送请求的总样本数量
响应时间【单位ms】:
- 平均值(average):平均的响应时间
- 最小值(min):请求返回的最小时间,其中一个用时最少的请求
- 最大值(max):请求返回的最大时间,其中一个用时最大的请求
- 标准偏差:度量响应时间分布的分散程度的标准,衡量响应时间值偏离平均响应时间的程度。标准偏差越小,偏离越少,反之亦然。
异常(error): 出现错误的百分比,错误率=错误的请求的数量/请求的总数
吞吐量TPS(throughout): 吞吐能力,这个才是我们需要的并发数
每秒接收 KB/sec----每秒从服务器端接收到的数据量
每秒发送KB/sec----每秒从客户端发送的请求的数量
平均字节数
线程组配置详解
01-线程数:用来发送http请求的线程的数量
线程组常用来模拟一组用户访问系统资源(API接口)。假如客户机没有足够的能力来模拟较重的负载,可以使用JMeter的分布式测试功能,通过一个JMeter的Master来远程控制多个JMeter的Salve完成测试。
02-循环次数:循环执行多少次操作
循环次数表示了循环执行多少次操作!循环次数直接决定整个测试单个线程的执行时间,和整体测试执行时间。
单线程执行时间 = 单请求平均响应时间 * 循环次数
整个测试耗时 = 单线程执行时间 + (Ramp-Up - Ramp-Up / 线程数)
03-Ramp-Up:建立全部线程耗时
Ramp-Up Period (in-seconds) 需要花费多久的时间启动全部的线程,默认值是0代表同时并发。用于告知JMeter 要在多长时间内建立全部的线程。
JMeter常用插件
已有内容的分析维度不够:需要加入新的插件
- TPS、QPS
- RT【平均响应时间】
- 压力机活动线程数
- 服务器资源信息
- …
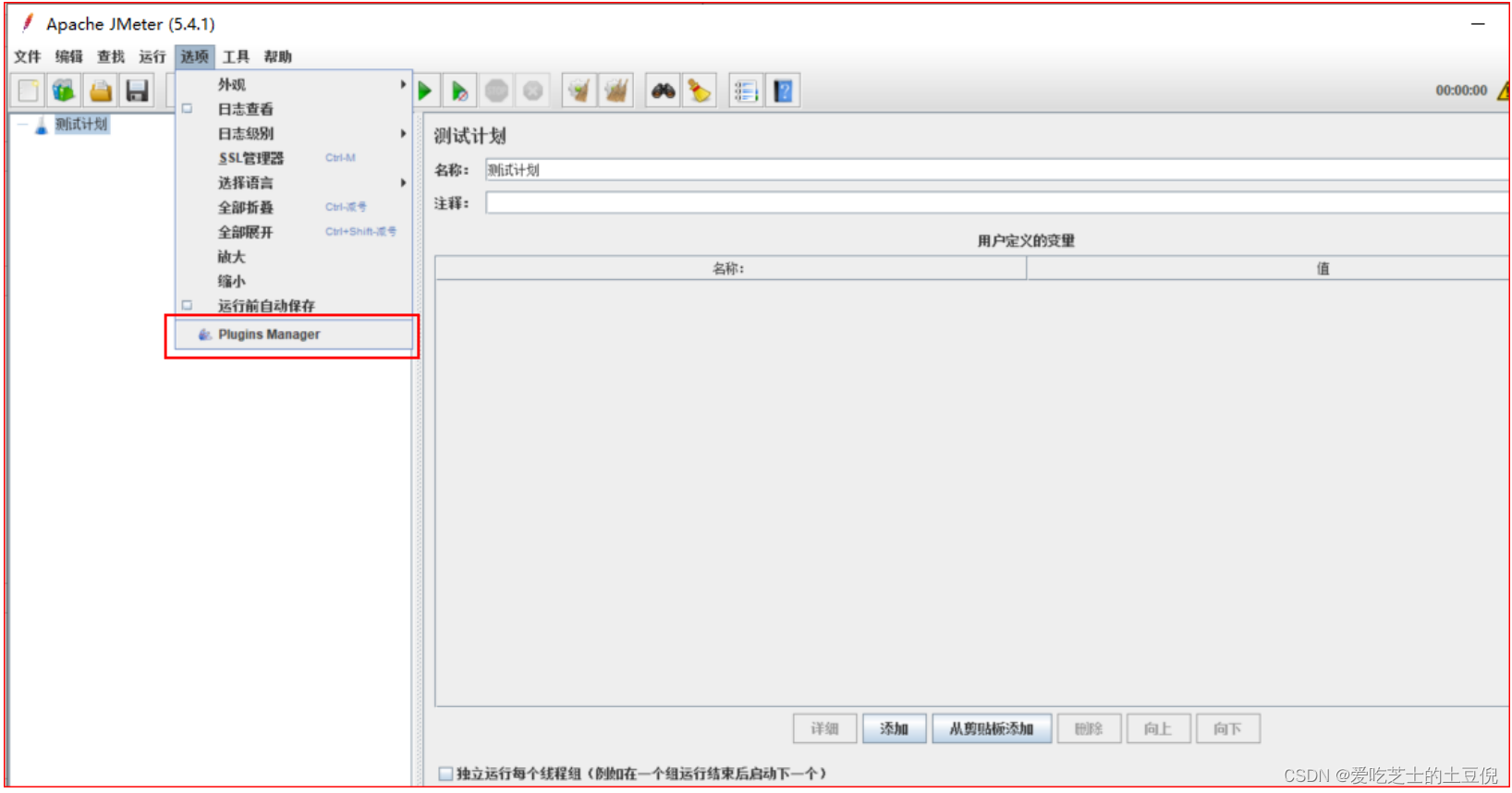
开启插件下载:
下载地址:http://jmeter-plugins.org/downloads/all/,官网上下载plugins-manager.jar直接在线下载,然后执行在线下载即可。
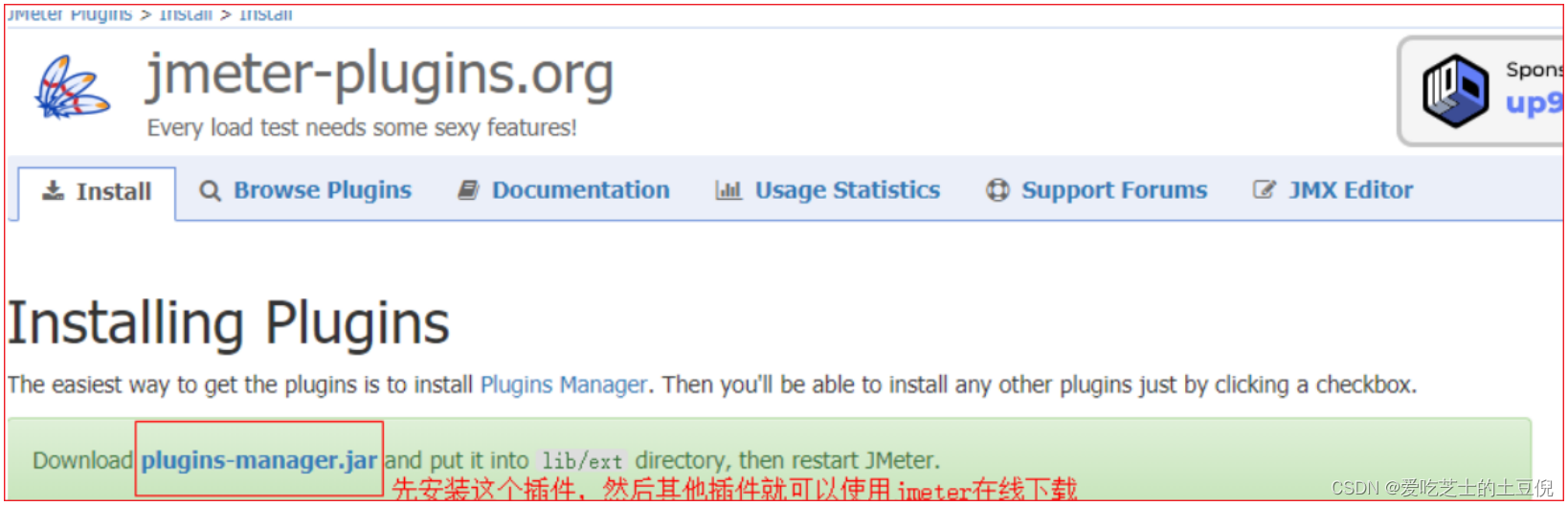
在线下载方法如下图所示:
常见的插件如下:
1、PerfMon:(Performance + Monitor)监控服务器硬件,如CPU,内存,硬盘读写速度等Allows collecting target server resource metrics
2、Basic Graphs:主要显示平均响应时间,活动线程数,成功/失败交易数等Average Response Time 平均响应时间Active Threads 活动线程数Successful/Failed Transactions 成功/失败 事务数
3、Additional Graphs:主要显示吞吐量,连接时间,每秒的点击数等Response CodesBytes ThroughputConnect TimesLatencyHits/s
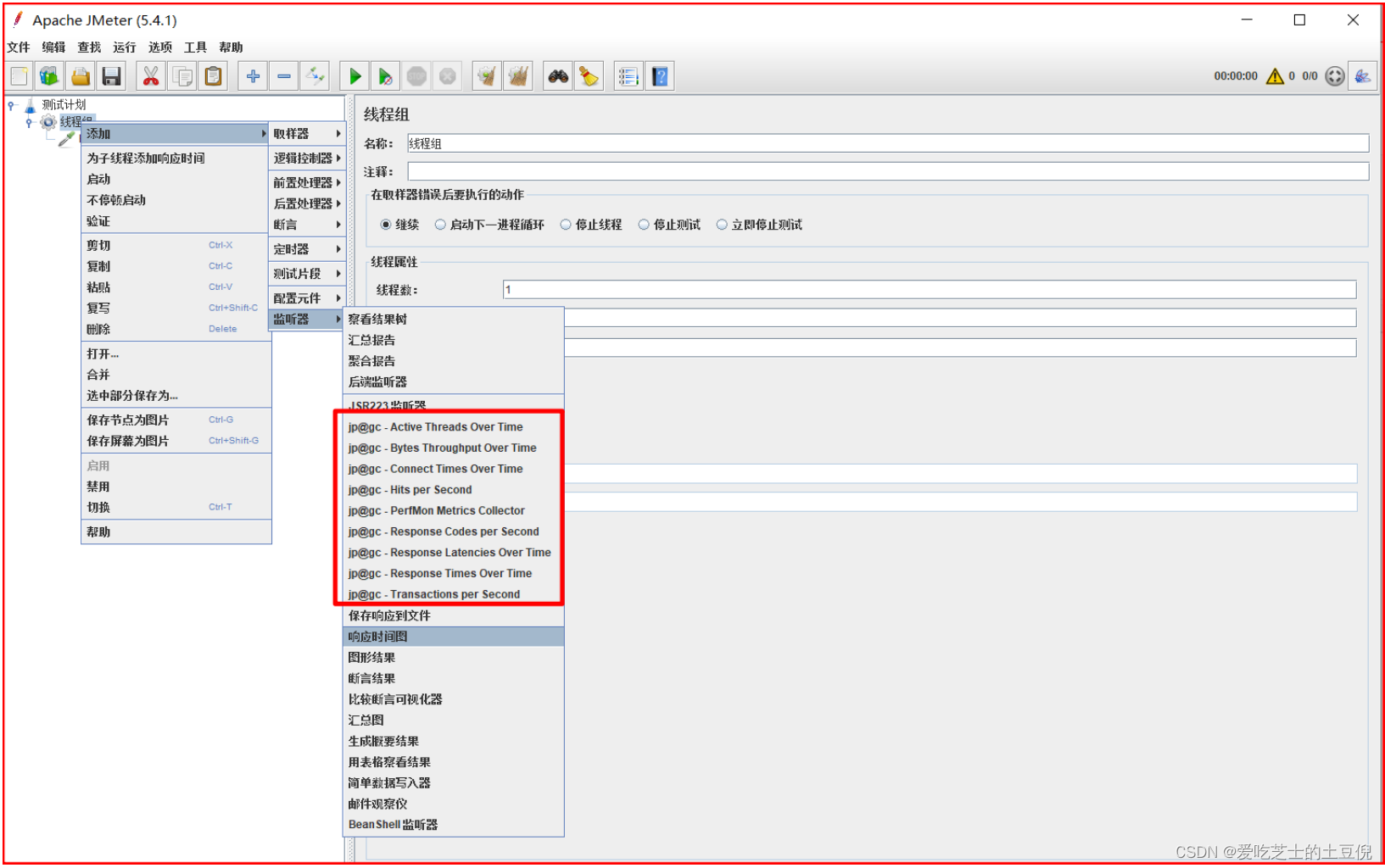
01-配置插件
如果可以配置如下三个监听器,就表示插件已经安装成功!执行压力测试,就可以看见压测的每秒事务数、响应时间,活动线程数等压测结果
- 响应时间:jp@gc - Response Times Over Time
- 活动线程数:jp@gc - Active Threads Over Time
- 每秒事务数:jp@gc - Transactions per Second
响应时间:jp@gc - Response Times
活动线程数:jp@gc - Active Threads
每秒事务数:jp@gc - Transactions per Second
02-性能关键指标分析

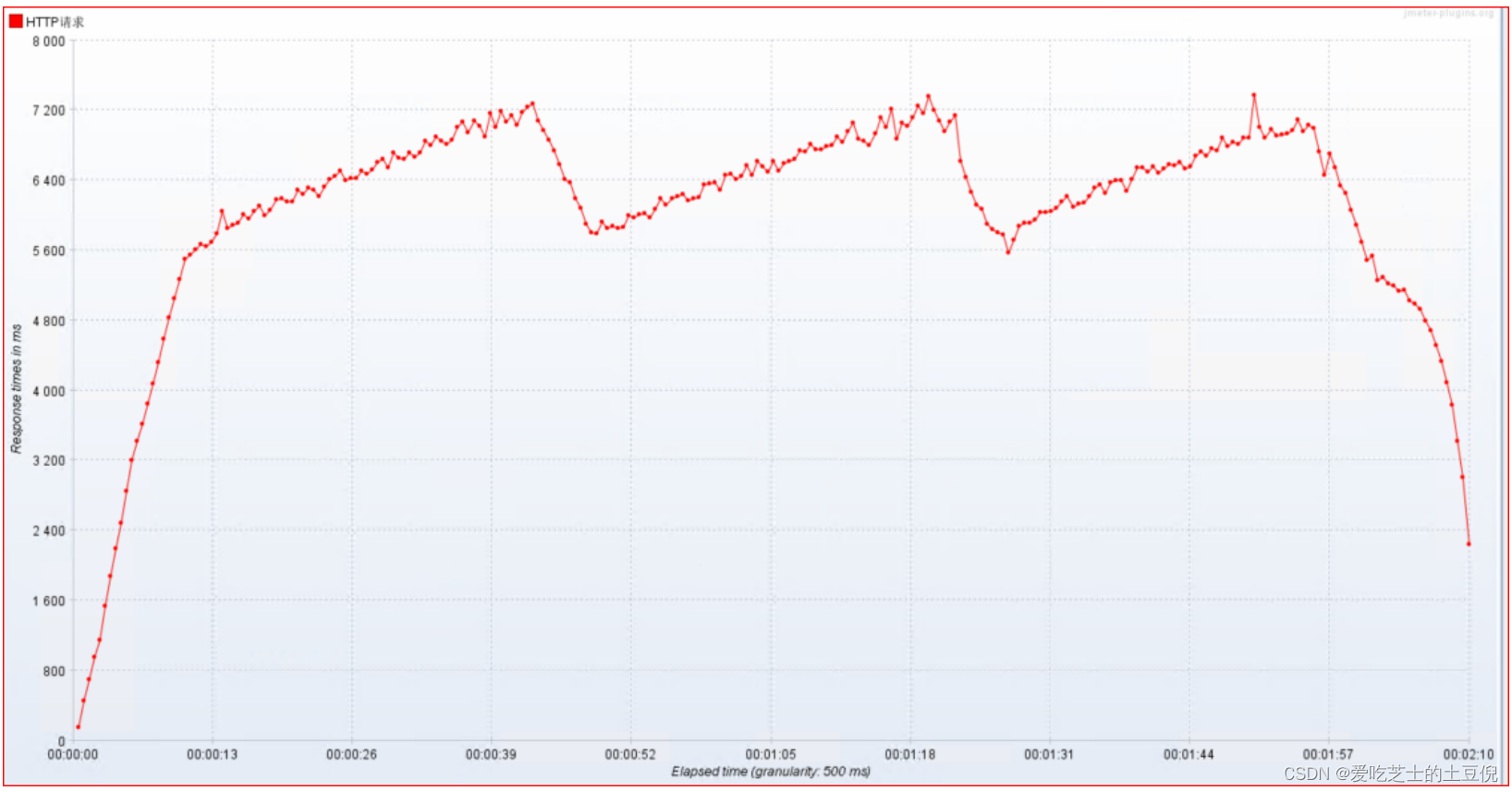
1)RT:响应时间
- 平均值: 请求响应的平均时间是6092ms
- 中位数: 50%请求响应时间都在6392ms之内
- P90: 90%的请求都在7290ms之内响应结束
- P95: 95%的请求都在7762ms之内响应结束
- P99:99%的请求都在8891ms之内响应结束
- 最小值: 请求响应最小时间3ms
- 最大值: 请求响应的最大时间是13656ms
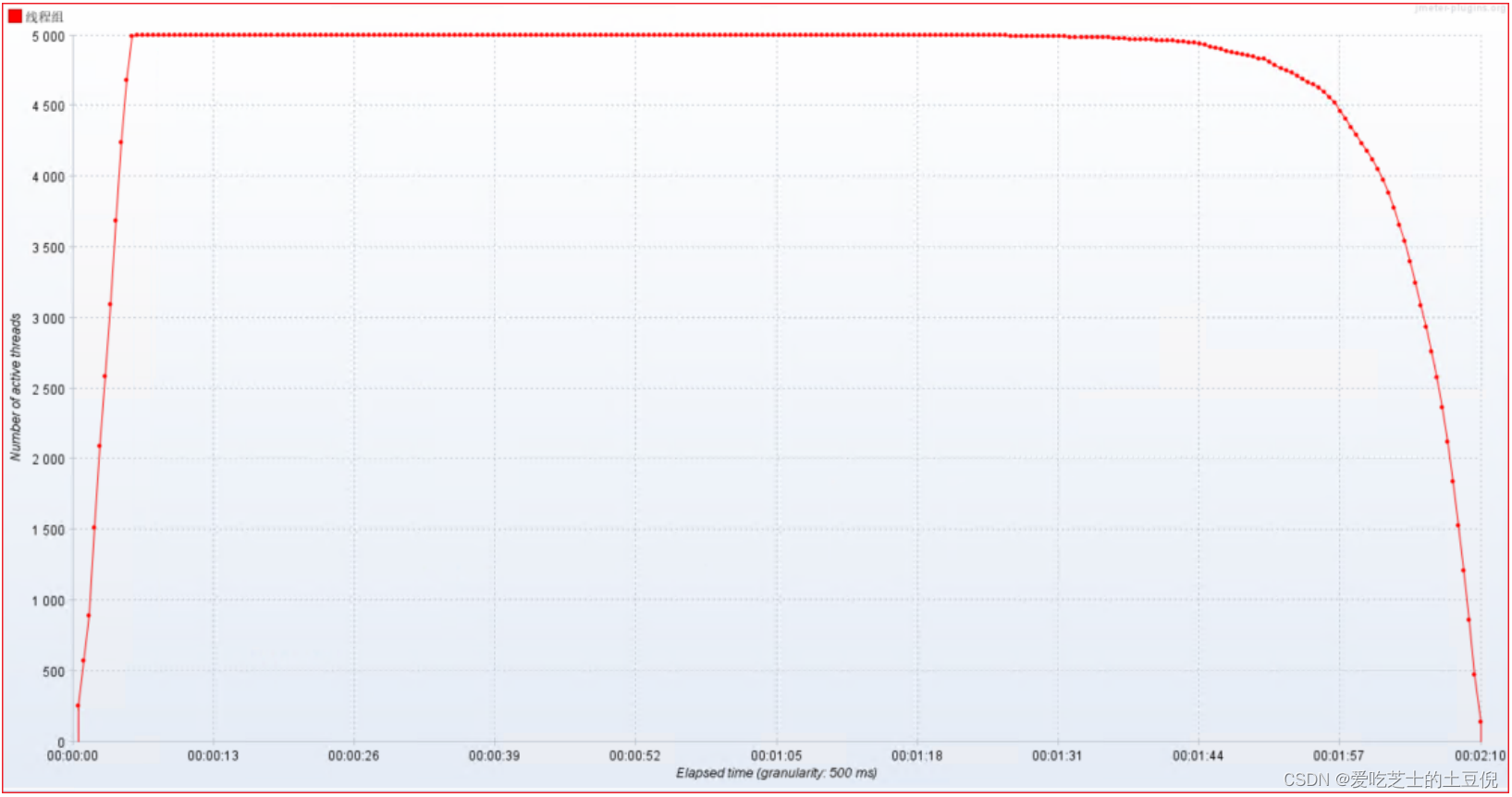
2)压力机活动线程数
压力机活动线程数表明压测过程中施加的压力的情况
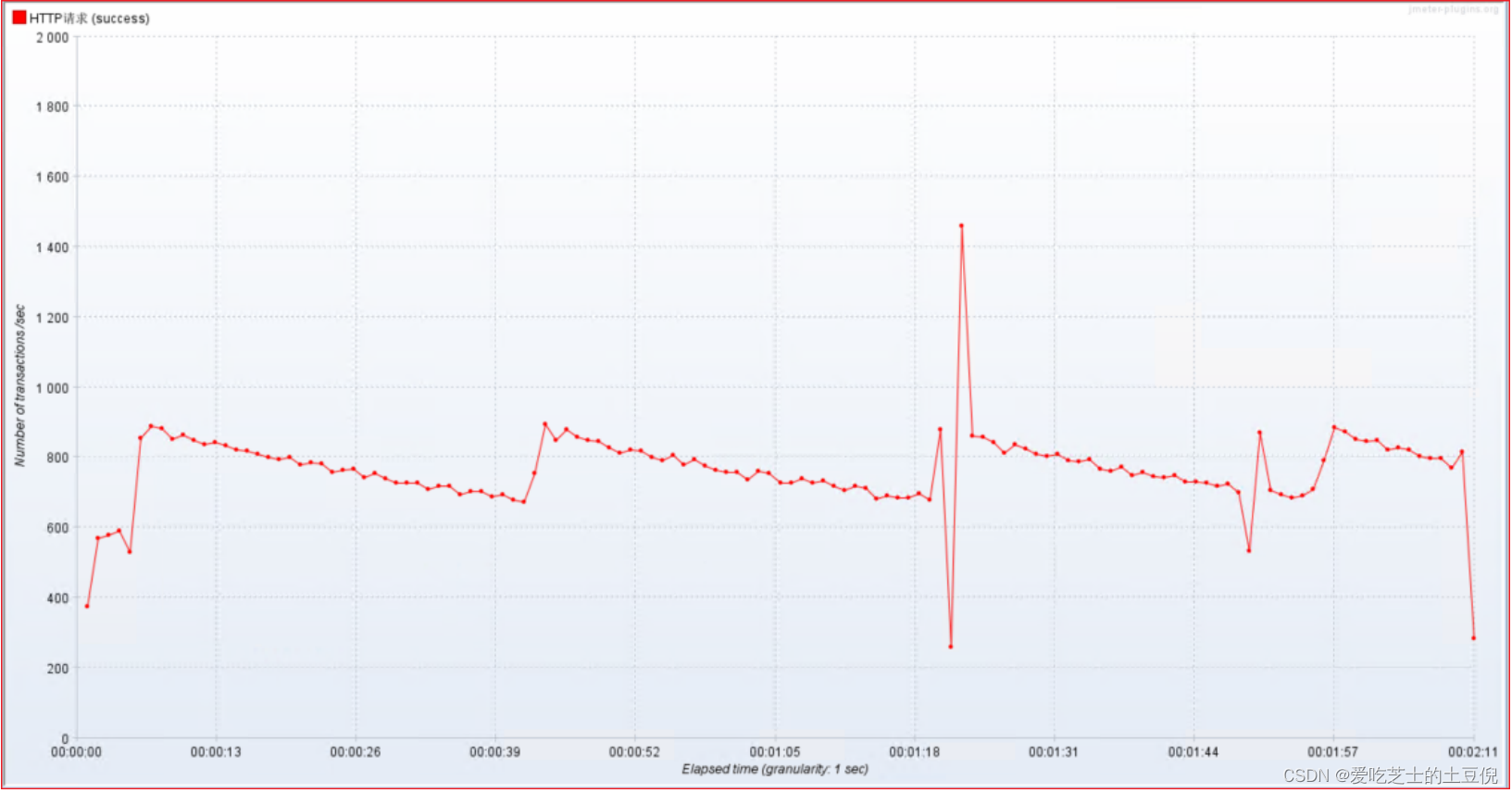
3)TPS: 每秒的事务数
数字愈大,代表性能越好;
4)QPS: 每秒的查询数量
数字愈大,代表性能越好;(1tps >= QPS)
5)吞吐量: 每秒的请求数量
数字愈大,代表性能越好;
服务器硬件资源监控【精简版】
压测的时候,我们需要实时了解服务器【CPU、内存、网络、服务器Load】的状态如何,哪如何监控服务器的资源占用情况呢?方法有很多种:
- 使用操作系统命令:top、vmstat、iostat、iotop、dstat、sar…
- 使用FinalShell
- 使用JMeter压测工具PerfMon
- 使用Grafana+Prometheus+node_exporter
监控原理:
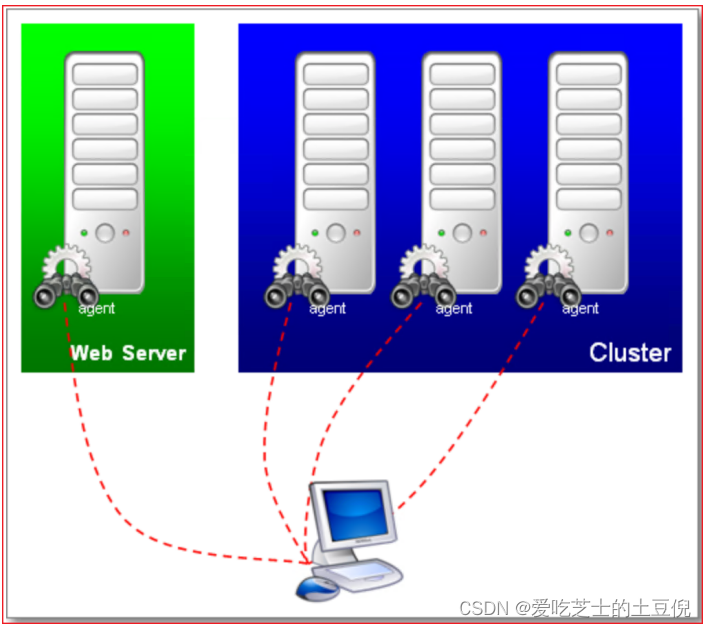
01-配置服务端代理
注意:服务器硬件资源的监控,必须在服务端安装serverAgent代理服务,JMeter才能实现监控服务端的cpu、内存、io的使用情况。
ServerAgent下载地址:https://github.com/undera/perfmon-agent/blob/master/README.md
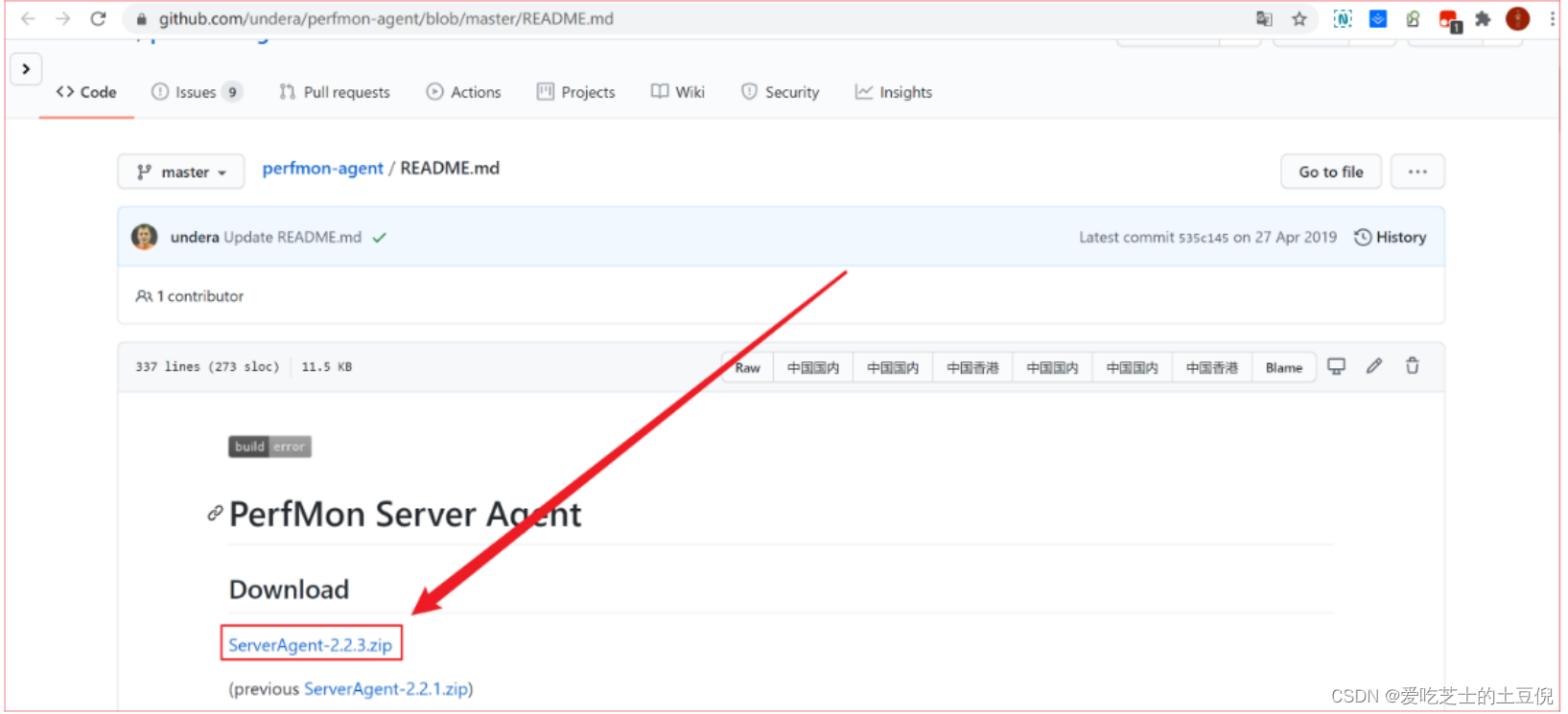
## 默认启动运行 startAgent.sh 脚本即可## 服务启动默认4444端口,根本连接不上,因此自己创建一个部署脚本文件对此进行部署,且把端口修
改为7879nohup java -jar ./CMDRunner.jar --tool PerfMonAgent --udp-port 7879 --tcpport 7879 > log.log 2>&1 &## 赋予可执行权限
chmod 755 startAgent.sh
启用7879端口后,服务器的cpu,io,内存使用情况就顺利的监控到了。
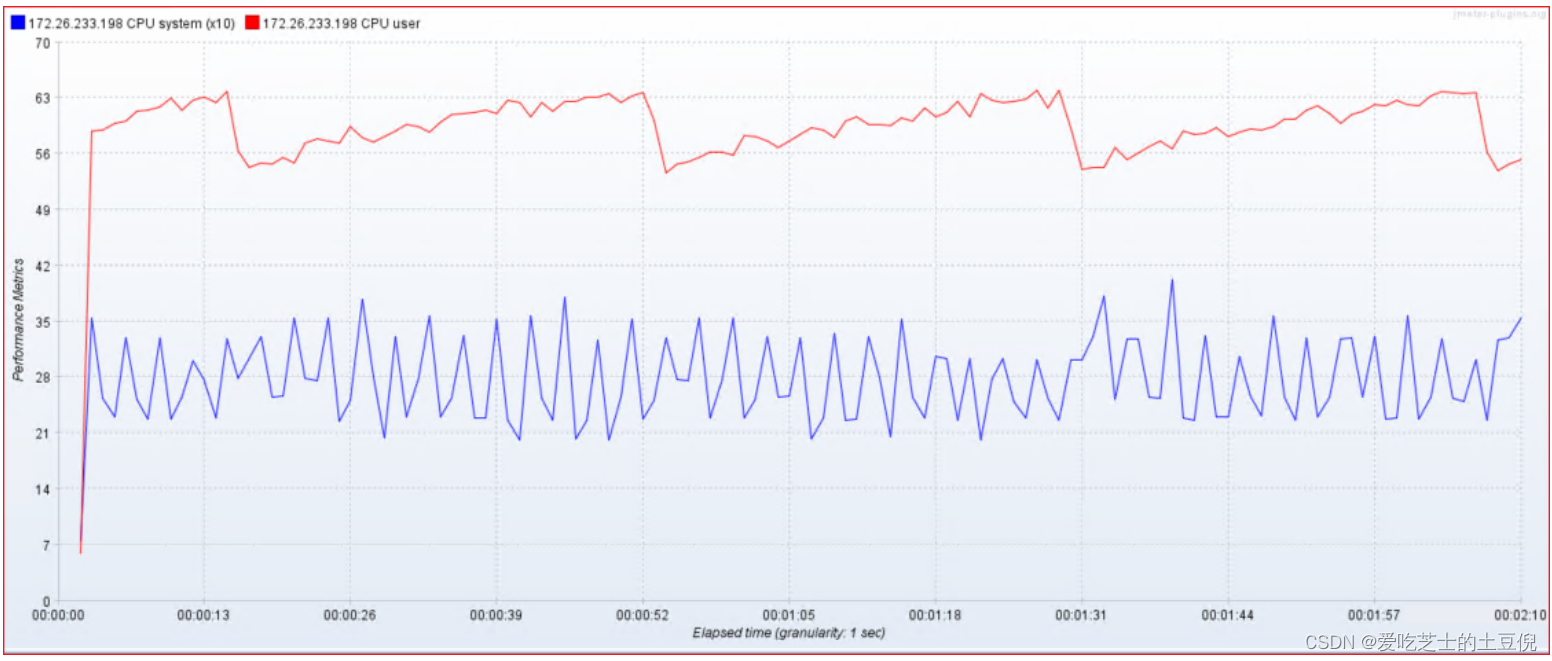
02-监控CPU:
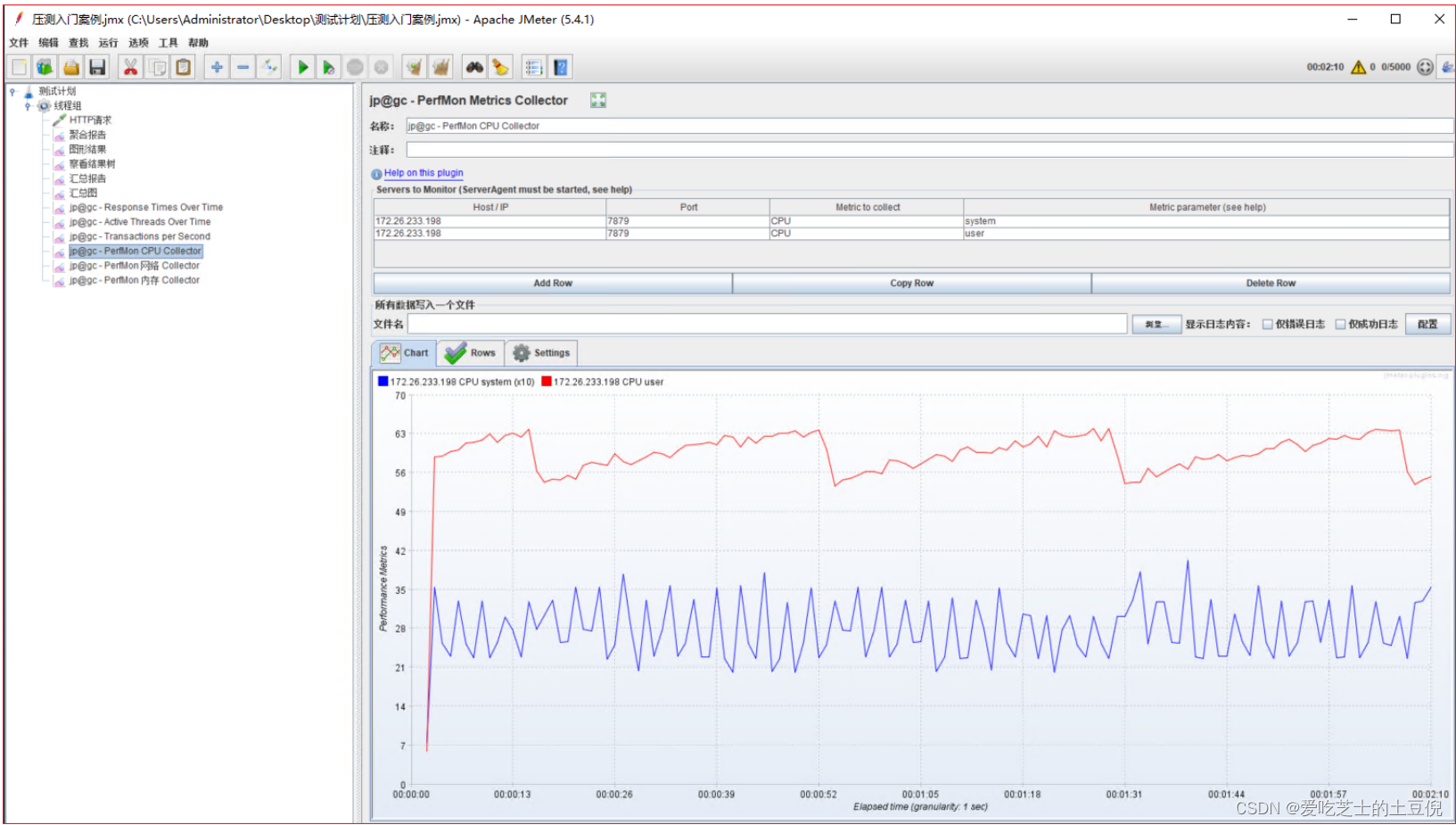
- Elapse time:消耗时间
- Performance Metrics:性能指标
- idle:CPU空闲
- iowait:IO等待
- system:系统占用
- CPU user:CPU用户占用
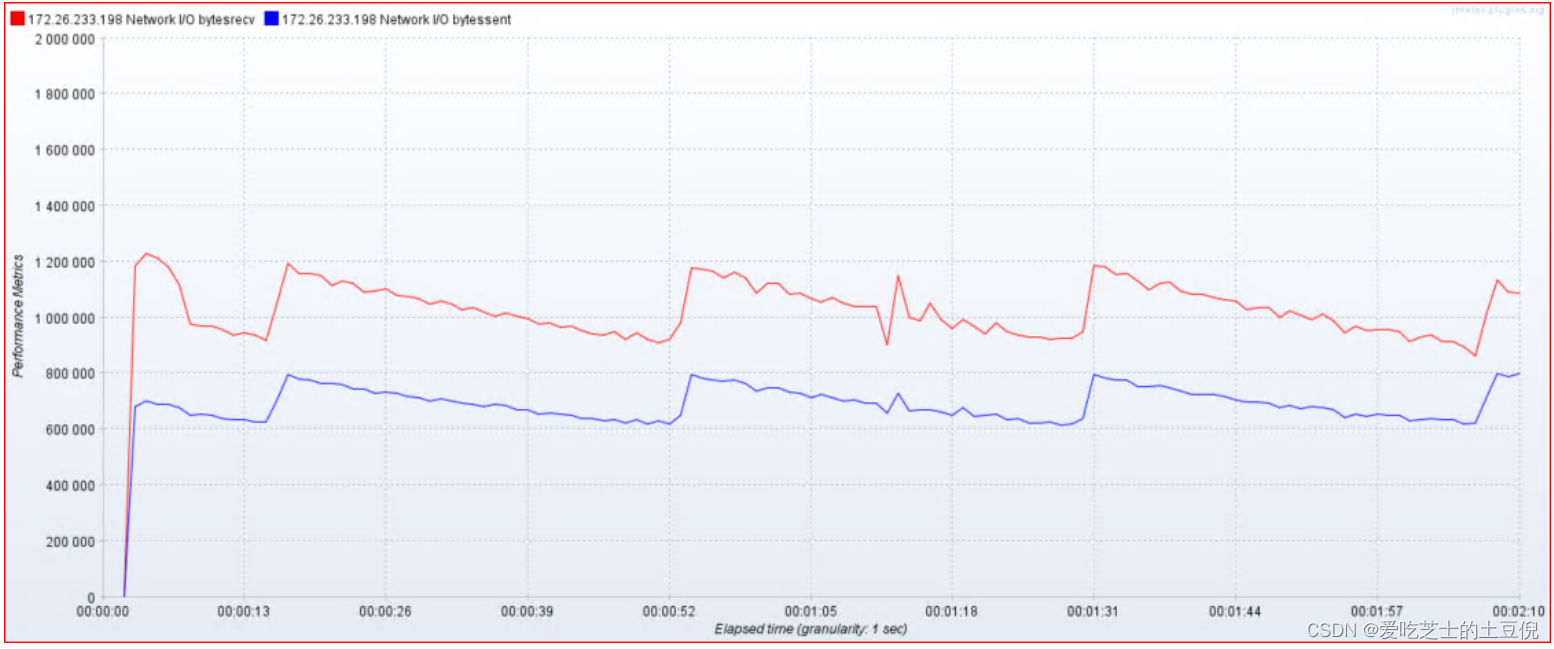
03-监控网络:
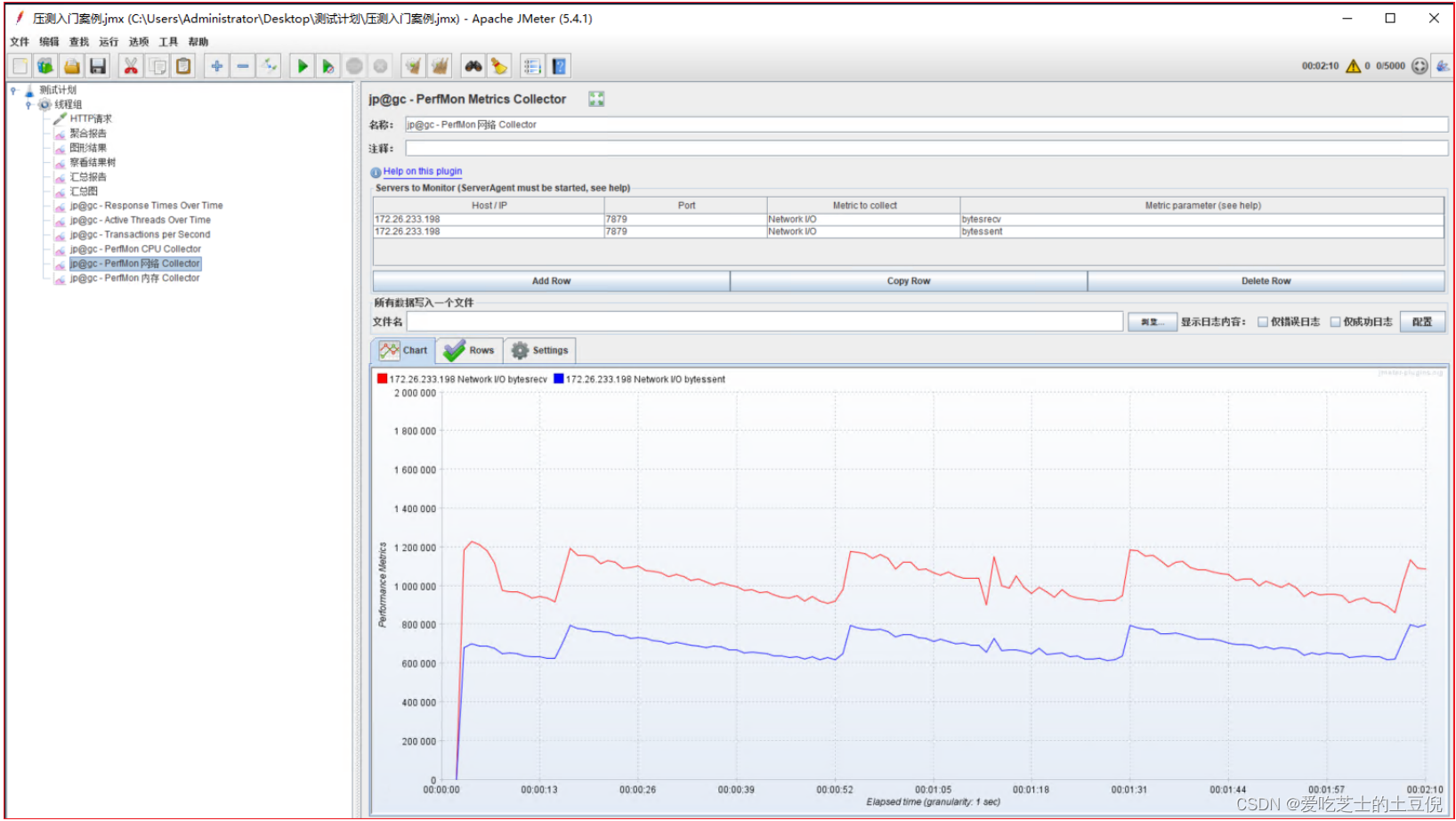
- 接收字节:byteSrecv【单位:比特、KB、MB】
- 发送字节:byteSent【单位:比特、KB、MB】
- 发送(transport):tx
- 接收(receive):rx
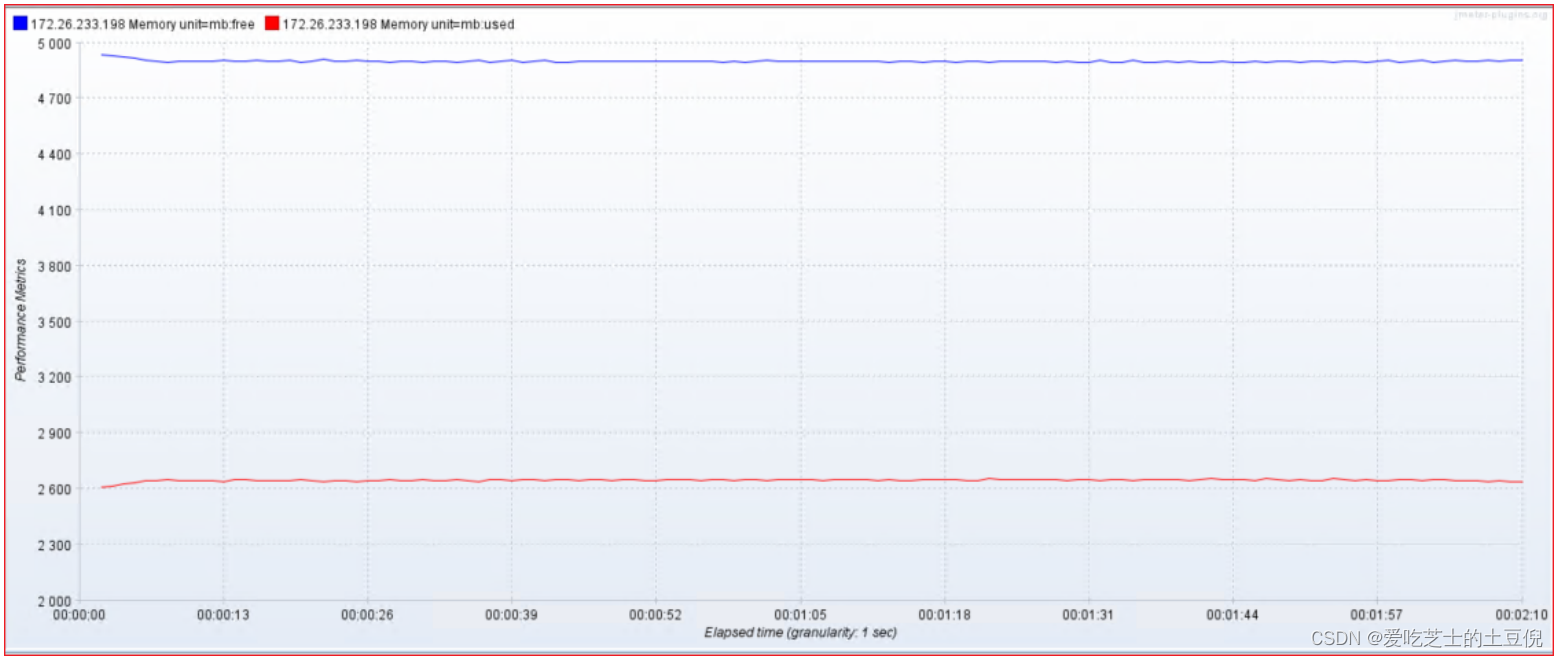
04-监控内存:
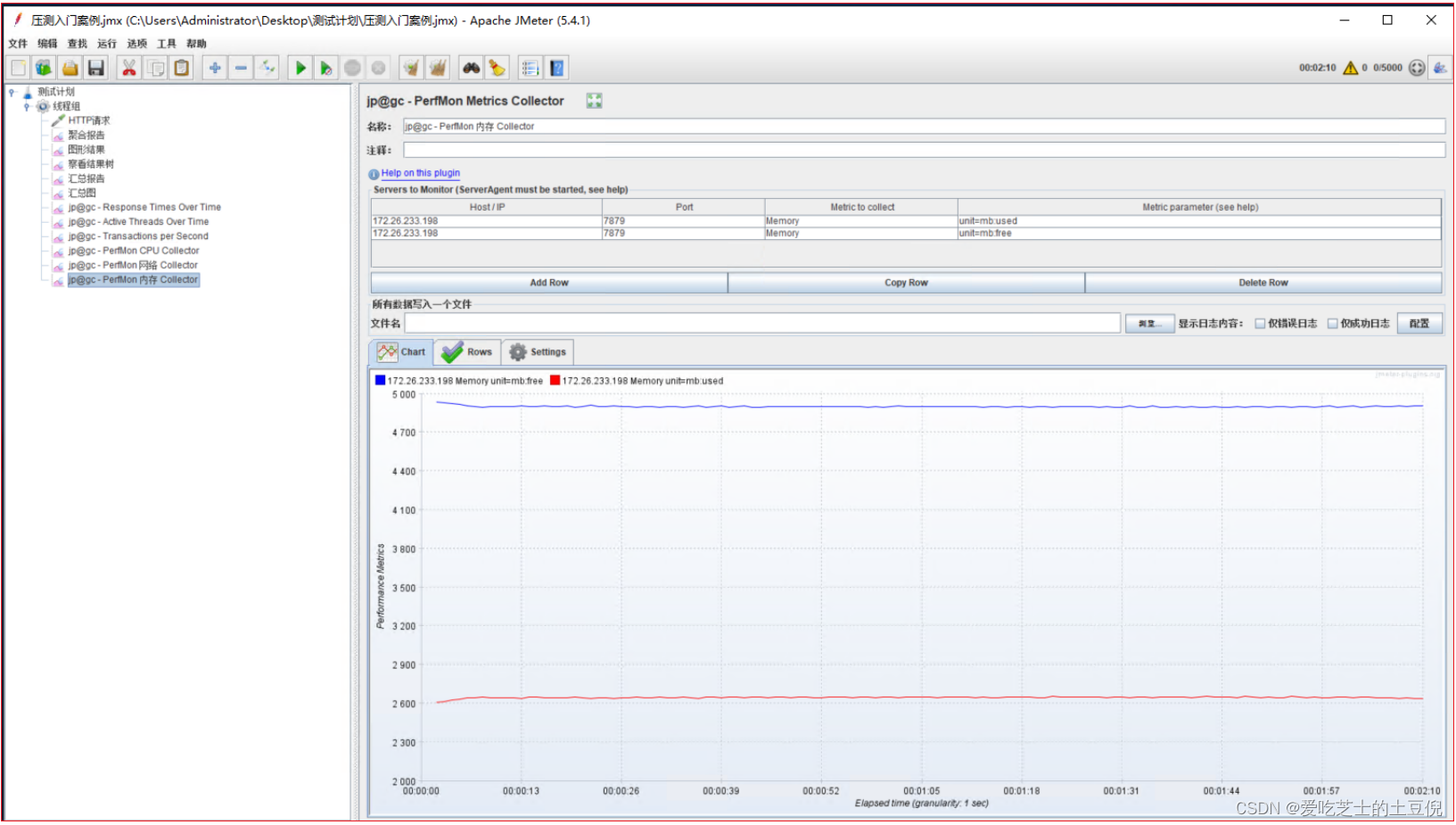
- usedPerc:每分钟使用内存【单位:字节、KB、MB】
- freePerc:每分钟未使用内存【单位:字节、KB、MB】
好处:可以将所有信息汇总到JMeter工具中来,查看非常方便。
弊端:数据记录时间有限,记录数据的量也有限
05-监控系统整体负载情况:
服务器上执行以下命令:
#查询服务器资源使用情况
top
top -H
如下图所示,可以看到系统负载 load average 情况,1分钟平均负载,5分钟平均负载,15分钟平均负载分别是 0.08, 0.03, 0.05 ;
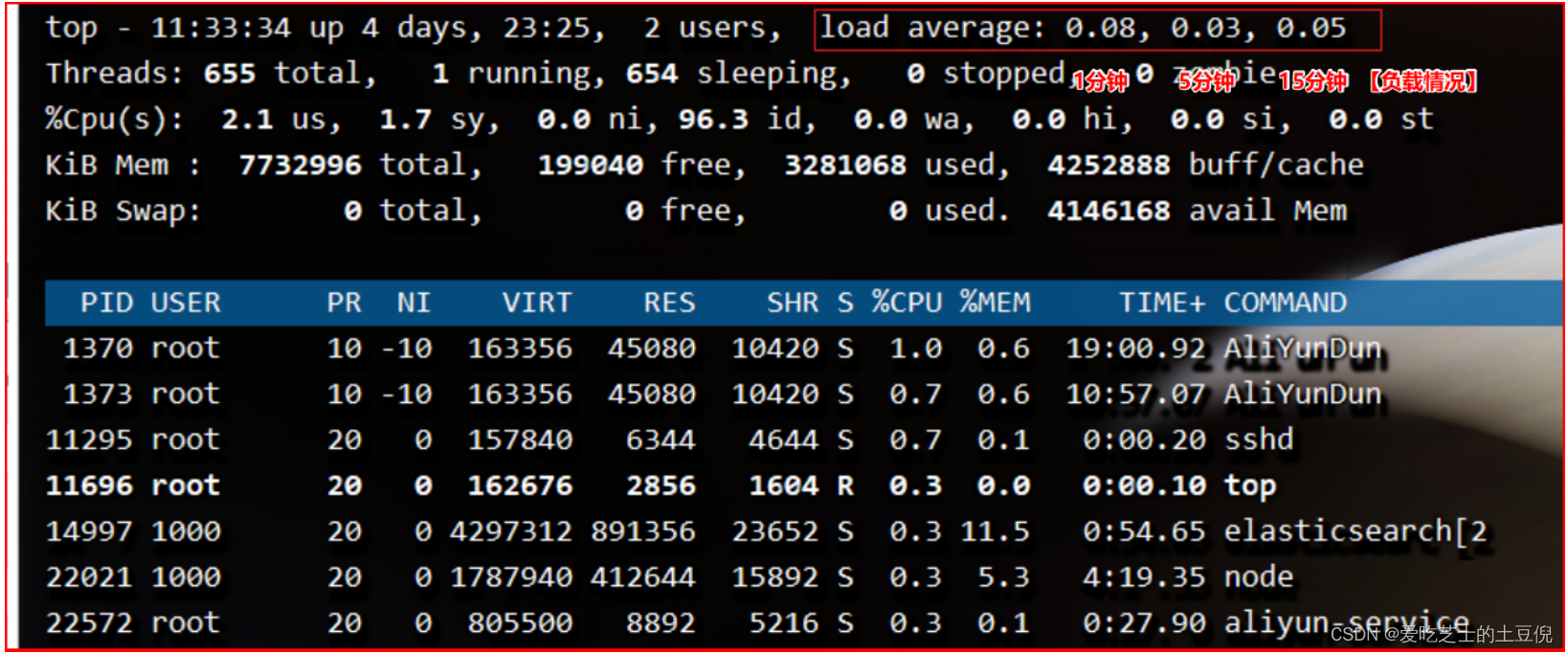
统计信息区前五行是系统整体的统计信息:

好处:不依赖环境,操作系统自带的命令,随时可以查看。
弊端:无法记录历史数据,不能看到变化的趋势
怎么理解系统资源的指标呢,怎么理解系统负载呢?
06-性能关键指标分析
1)服务器:CPU、内存、网络IO
CPU
内存
网络IO
2)系统负载: load average
- 什么是Load Average?
- 系统负载System Load是系统CPU繁忙程度的度量,即有多少进程在等待被CPU调度(进程等待队列的长度)。
- 平均负载(Load Average)是一段时间内系统的平均负载,这个一段时间一般取1分钟、5分钟、15分钟。
- 多核CPU和单核CPU的系统负载数据指标的理解还不一样。
在类Unix系统中,系统负载是衡量计算机系统执行的计算工作量的指标。
举个栗子:while(true) 这样程序不耗时,cpu会飙高,但是load average不会走高。说明程序在计算,但是并没有执行耗时工作,所以Load Average并不高。我们在核查服务器负载因需要重点关注loadaverage。
- Load的数值是什么含义?
不同的CPU性质不同:单核,双核,四核 -->>
单核CPU三种Load情况
举例说明:把CPU比喻成一条(单核)马路,进程任务比喻成马路上跑着的汽车,Load则表示马路的繁忙程度。
情况1-Load小于1:不堵车,汽车在马路上跑得游刃有余:

情况2-Load等于1:马路已无额外的资源跑更多的汽车了:

情况3-Load大于1:汽车都堵着等待进入马路:

双核CPU
如果有两个CPU,则表示有两条马路,此时即使Load大于1也不代表有汽车在等待:
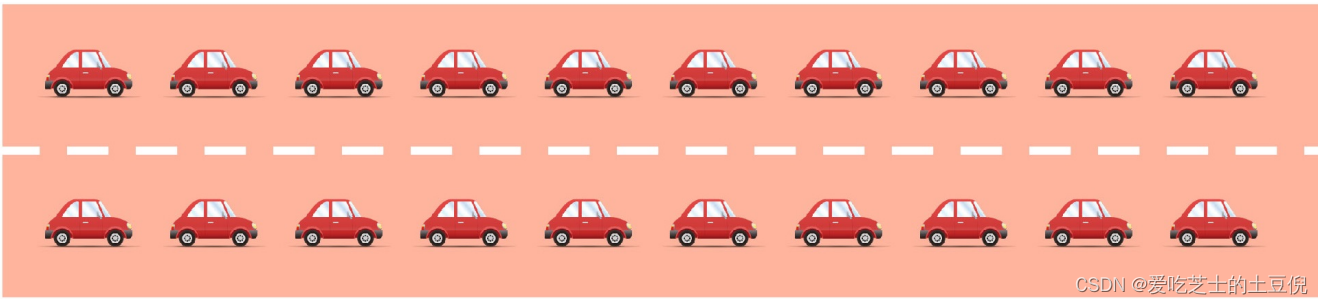
[Load==2,双核,没有等待]
- 什么样的Load值得警惕?
如下分析针对单核CPU
- 【0.0 - 0.7]】 :系统很闲,马路上没什么车,要考虑多部署一些服务
- 【0.7 - 1.0 】:系统状态不错,马路可以轻松应对
- 【等于1.0】 :系统马上要处理不多来了,赶紧找一下原因
- 【大于5.0】 :马路已经非常繁忙了,进入马路的每辆汽车都要无法很快的运行
- 不同Load值说明什么问题?
如下分析针对单核CPU的三种情况:
情况1:1分钟负载 > 5,5分钟负载 < 1,15分钟负载 < 1
举例: 5.18 , 0.05 , 0.03
短期内繁忙,中长期空闲,初步判断是一个“抖动”或者是“拥塞前兆”
情况2:1分钟负载 > 5,5分钟负载 > 1,15分钟负载 < 1
举例: 5.18 , 1.05 , 0.03
短期内繁忙,中期内紧张,很可能是一个“拥塞的开始”
情况3:1分钟负载 > 5,5分钟负载 > 5,15分钟负载 > 5
举例: 5.18 , 5.05 , 5.03
短中长期都繁忙,系统“正在拥塞”
压测监控平台
梯度压测:分析接口性能瓶颈
压测接口:响应时间20ms,响应数据包3.8kb,请求数据包0.421kb
http://123.56.249.139:9001/spu/goods/10000005620800
是与RT和服务端线程数有关的
压测配置:
情况01-模拟低延时场景,用户访问接口并发逐渐增加的过程。
预计接口的响应时间为20ms
线程梯度:5、10、15、20、25、30、35、40个线程
循环请求次数5000次
时间设置:Ramp-up period(inseconds)的值设为对应线程数
测试总时长:约等于20ms x 5000次 x 8 = 800s = 13分
配置断言:超过3s,响应状态码不为20000,则为无效请求
机器环境
应用服务器配置:4C8G
外网-网络带宽25Mbps (峰值)
内网-网络带宽基础1.5/最高10Gbit/s
集群规模:单节点
服务版本:v1.0
数据库服务器配置:4C8G
Mbps : Megabit per second (Mbit/s or Mb/s)
MB/s : Megabyte per second
1 byte = 8 bits
1 bit = (1/8) bytes
1 bit = 0.125 bytes
1 megabyte = 10002 bytes
1 megabit = 10002 bits
1 megabit = 0.125 megabytes
1 megabit/second = 0.125 megabytes/second
1 Mbps = 0.125 MB/s
配置监听器:
-
聚合报告:添加聚合报告
-
查看结果树:添加查看结果树
-
活动线程数:压力机中活动的线程数
-
TPS统计分析:每秒事务树
-
RT统计分析:响应时间
-
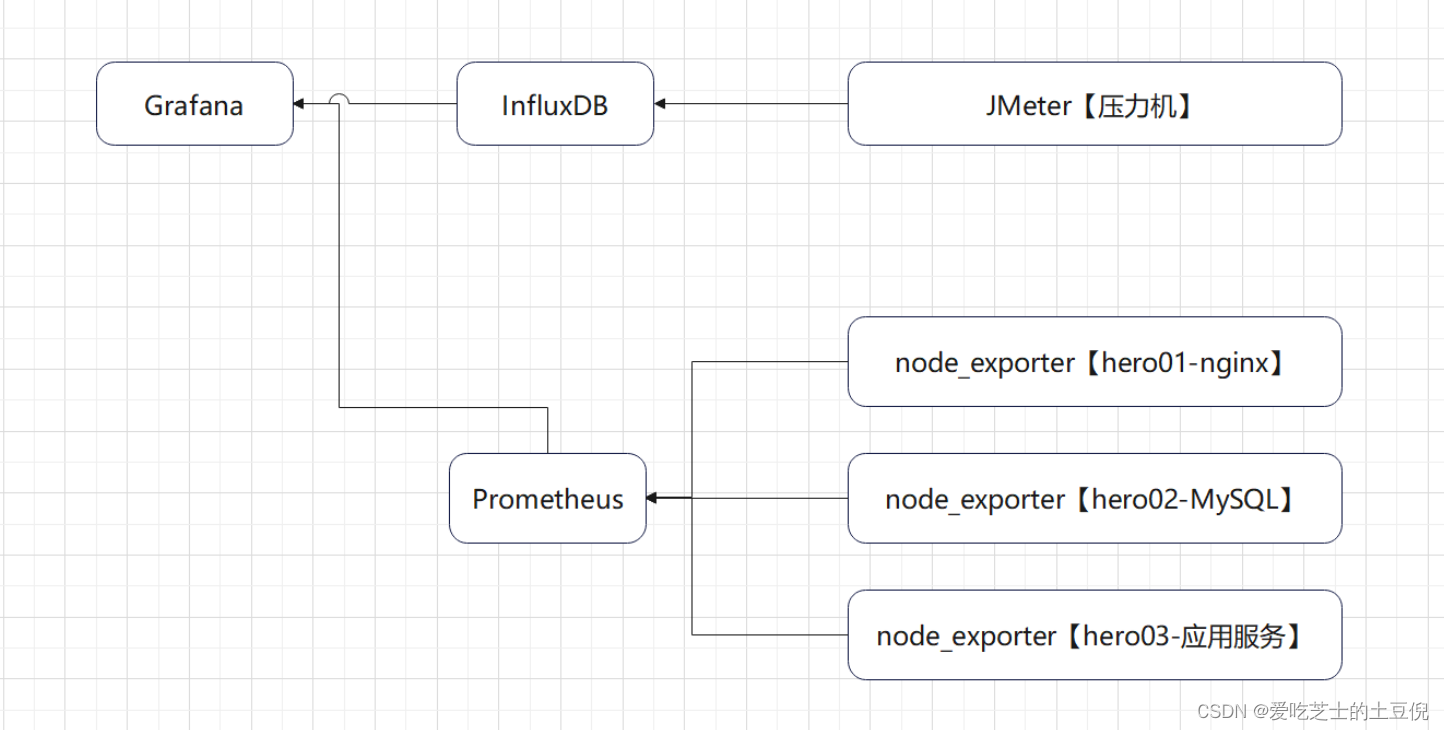
后置监听器,将压测信息汇总到InfluxDB,在Grafana中呈现
-
压测监控平台:
JMeter DashBoard
应用服务器:内存、网络、磁盘、系统负载情况
MySQL服务器:内存、网络、磁盘、系统负载情况
性能瓶颈剖析
1)梯度压测,测出瓶颈
进一步提升压力,发现性能瓶颈
- 使用线程:5,然后循环5000次,共2.5万个样本
- 使用线程:10,然后循环5000次,共5万个样本
- 使用线程:15,然后循环5000次,共7.5万个样本
- 使用线程:20,然后循环5000次,共10万个样本
- 使用线程:25,然后循环5000次,共12.5万个样本
- 使用线程:30,然后循环5000次,共15万个样本
- 使用线程:35,然后循环5000次,共17.5万个样本
- 使用线程:40,然后循环5000次,共20万个样本
聚合报告

Active Threads
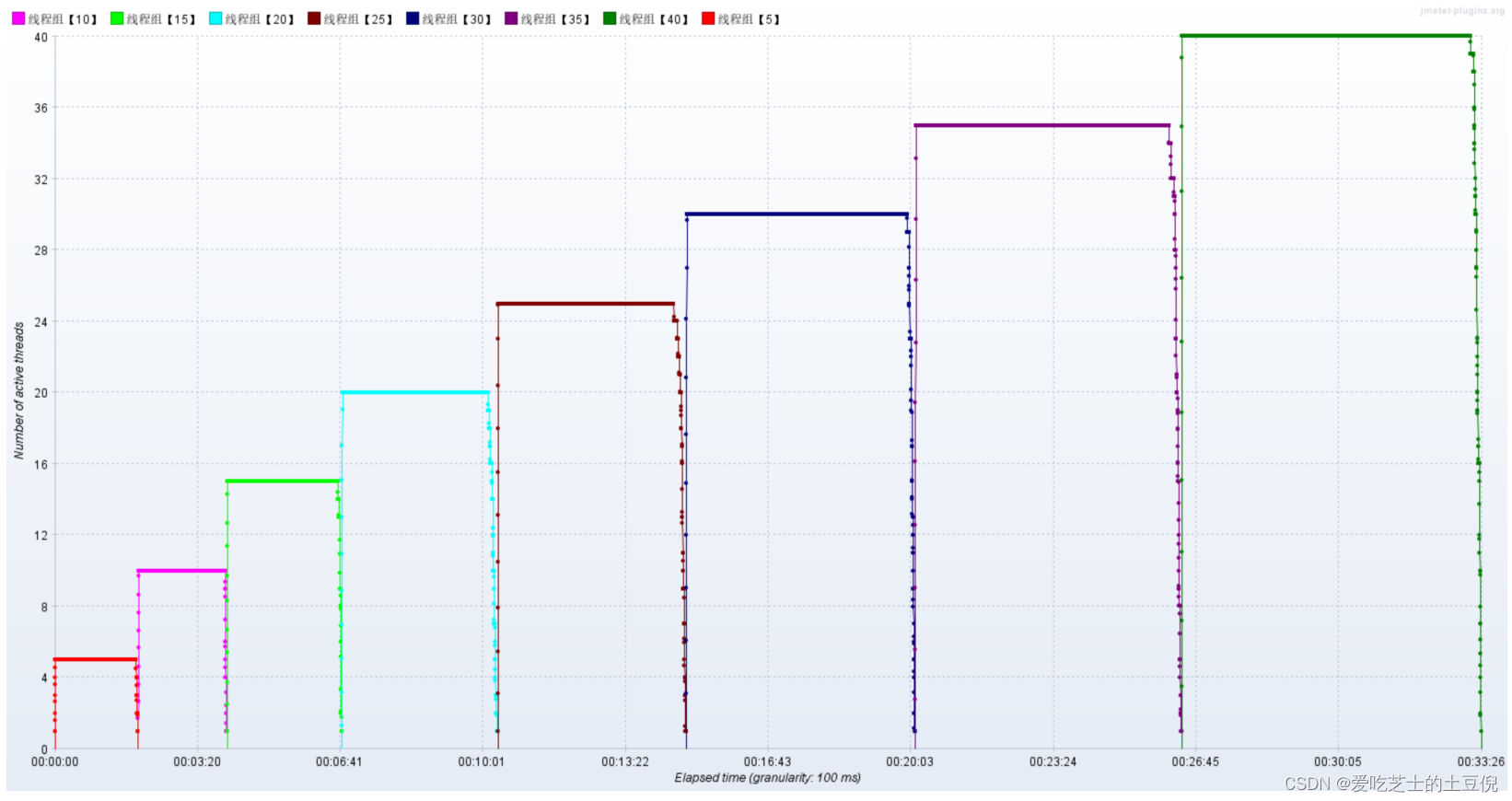
RT

TPS
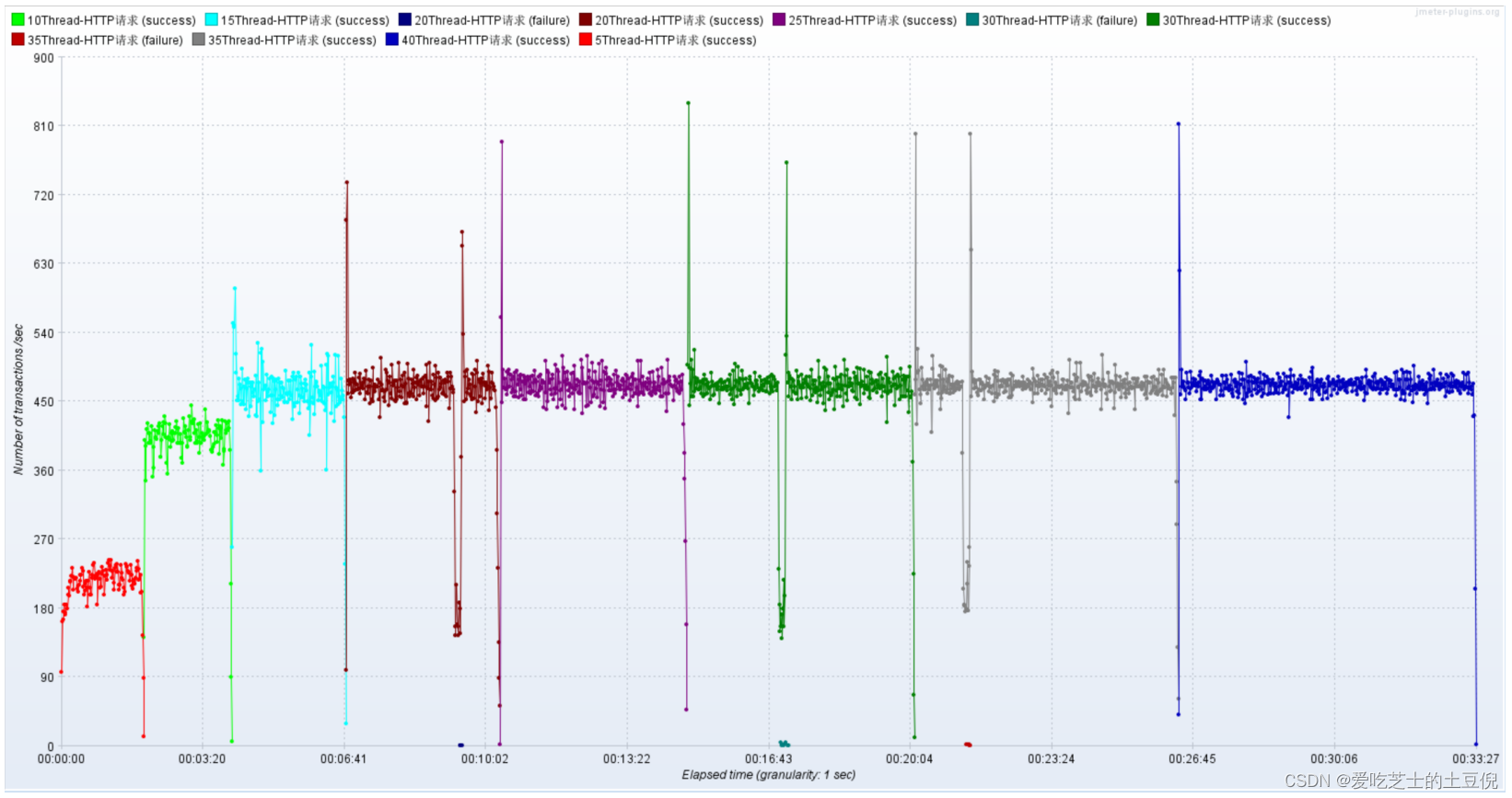
此时就是到了重负载区
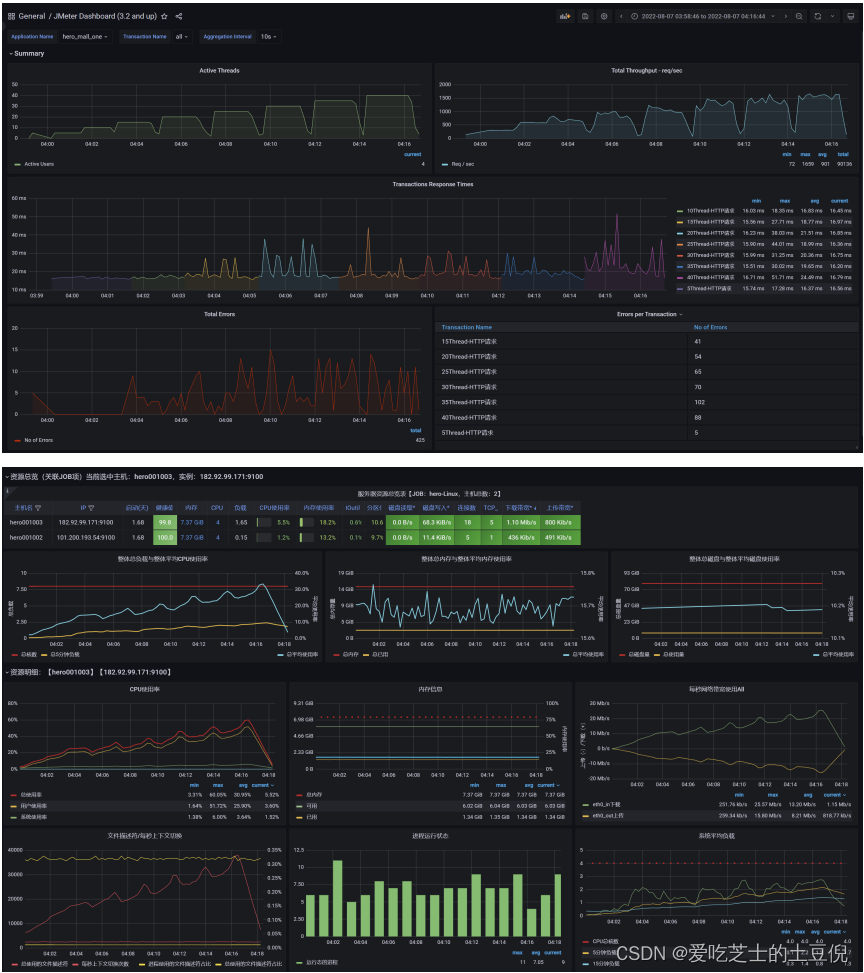
压测监控平台与JMeter压测结果一致
压了13分钟,产生了5G的数据,按照我们的阿里云服务器配置,相当于三四块钱没了
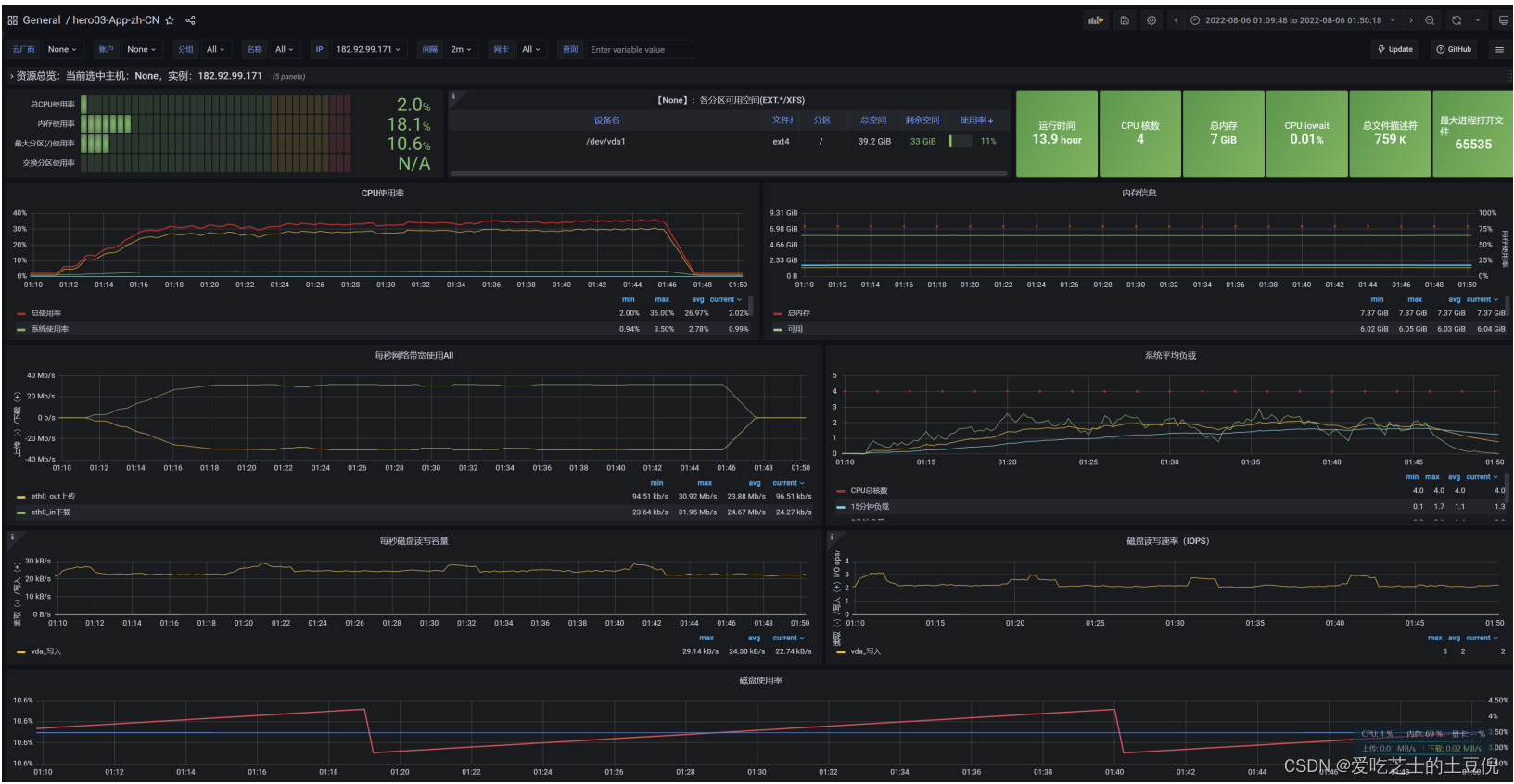
压测中服务器监控指标
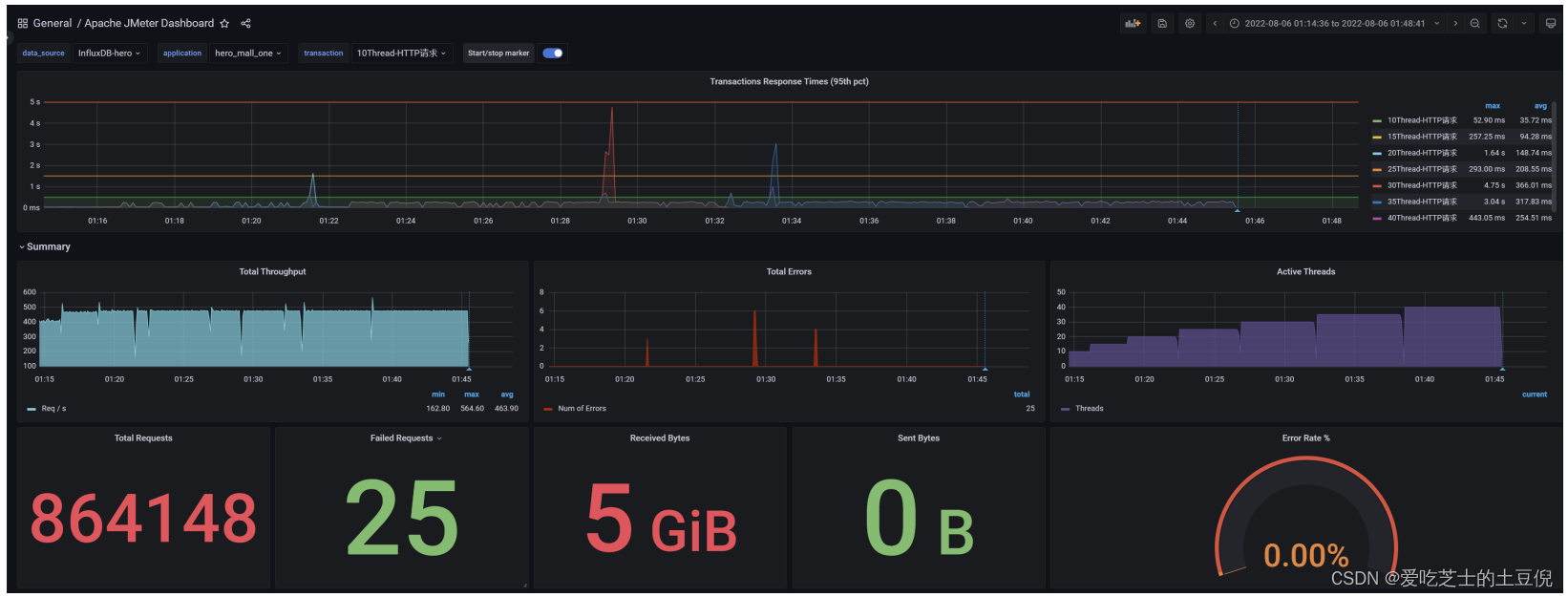
2)问题1:网络到达瓶颈
注意:系统网络带宽为25Mbps
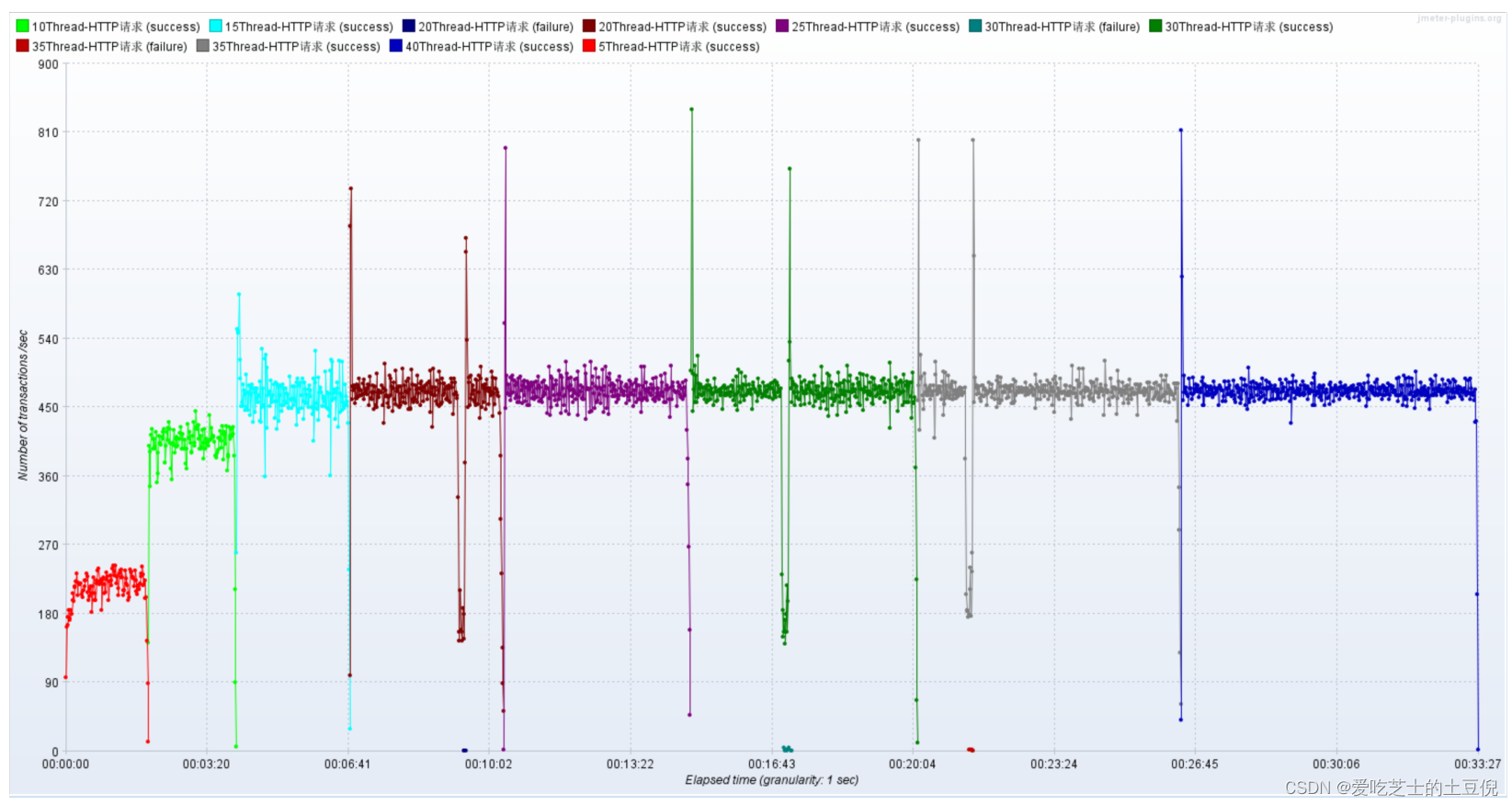
结论:随着压力的上升,TPS不再增加,接口响应时间逐渐在增加,偶尔出现异常,瓶颈凸显。系统的负载不高。CPU、内存正常,说明系统这部分资源利用率不高。带宽带宽显然已经触顶了。
优化方案:
方案01-降低接口响应数据包大小(把不应该推送给用户的优化掉)
返回数据量小的接口,响应数据包0.6kb,请求数据包0.421kb
htp://123.56.249.139:9001/spu/goods/10000023827800
方案02-提升带宽【或者在内网压测】
25Mbps --> 100Mbps(但是会变贵)
云服务器内网:这里在Linux中执行JMeter压测脚本
jmeter -n -t 02-jmeter-example.jmx -l 02-jmeter-example.jtl
所以就是,想要高并发,money得有才行。
方案03-CDN
买CDN,给用户离他最近的流量
优化之后:
方案01-降低接口响应数据包大小,压测结果

问题:可不可以基于RT与TPS算出服务端并发线程数?
服务端线程数计算公式:TPS/ (1000ms/ RT均值)
- RT=21ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 17
- RT=500ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 400
- RT=1000ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 800
结论:
- 在低延时场景下,服务瓶颈主要在服务器带宽。
- TPS数量等于服务端线程数 乘以 (1000ms/ RT均值)
- RT=21ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 17
3)问题2:接口的响应时间是否正常?是不是所有的接口响应都这么快?
情况02-模拟高延时场景,用户访问接口并发逐渐增加的过程。接口的响应时间为500ms,
- 线程梯度:100、200、300、400、500、600、700、800个线程;
- 循环请求次数200次
- 时间设置:Ramp-up period(inseconds)的值设为对应线程数的1/10;
- 测试总时长:约等于500ms x 200次 x 8 = 800s = 13分
- 配置断言:超过3s,响应状态码不为20000,则为无效请求
//慢接口
@GetMapping("/goods/slow/{spuId}")
public Result findGoodsBySpuIdTwo(@PathVariable String spuId){Goods goods = spuService.findBySpuId(spuId);//模拟慢接口try {//休眠500msTimeUnit.MILLISECONDS.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}return new Result(true, StatusCode.OK, "查询成功", goods);
}
响应慢接口:500ms+,响应数据包3.8kb,请求数据包0.421kb
htp://123.56.249.139:9001/spu/goods/slow/10000005620800
测试结果:RT、TPS、网络IO、CPU、内存、磁盘IO

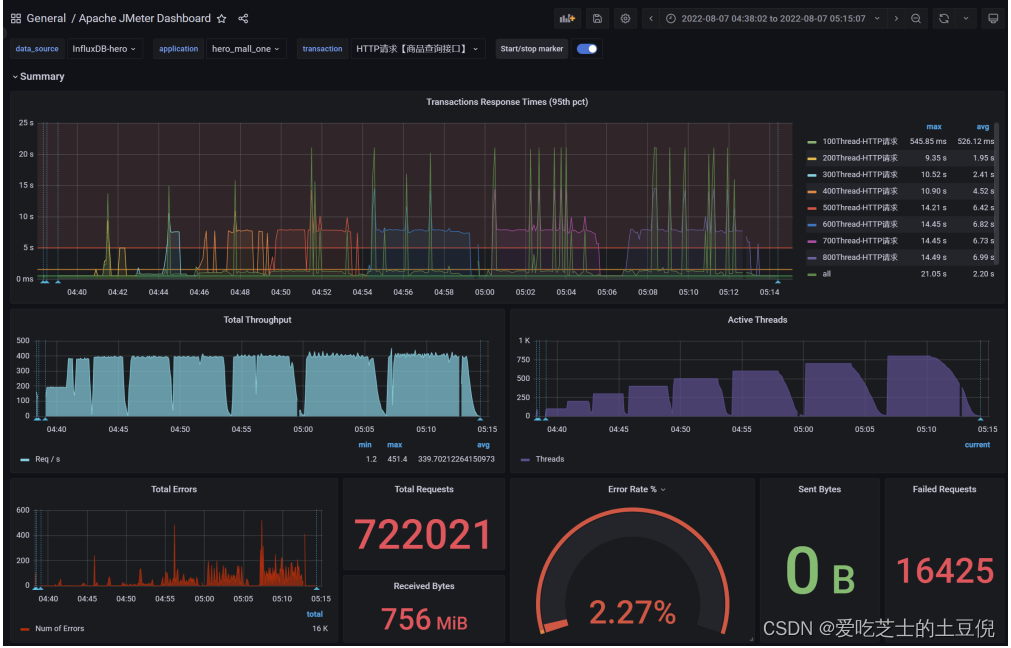
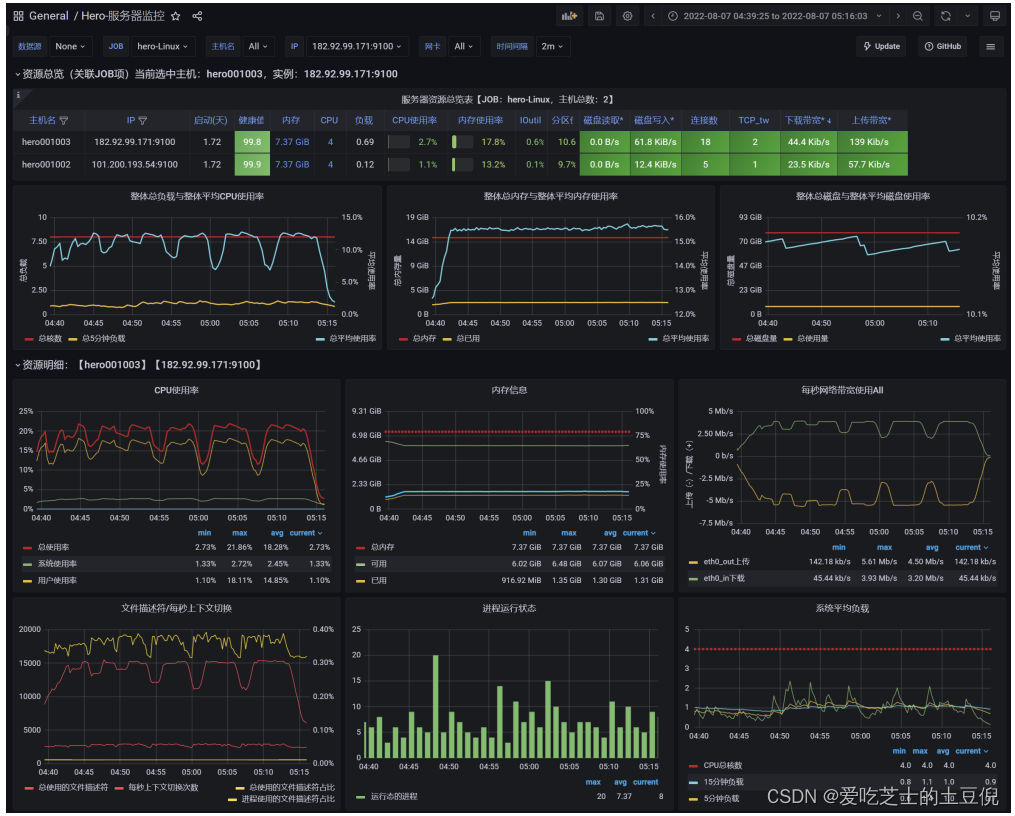
结论:
- 在高延时场景下,服务瓶颈主要在容器最大并发线程数。
- RT=500ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT) = 400
Tomcat的默认线程数是200
- 观察服务容器最大线程数,发现处理能力瓶颈卡在容器端
4)问题3:TPS在上升到一定的值之后,异常率较高
可以理解为与IO模型有关系,因为当前使用的是阻塞式IO模型。这个问题我们在服务容器优化部分解决。
因为是使用的是NIO,阻塞了之后我们前面配置的是超过3s就会报错,所以报异常了。
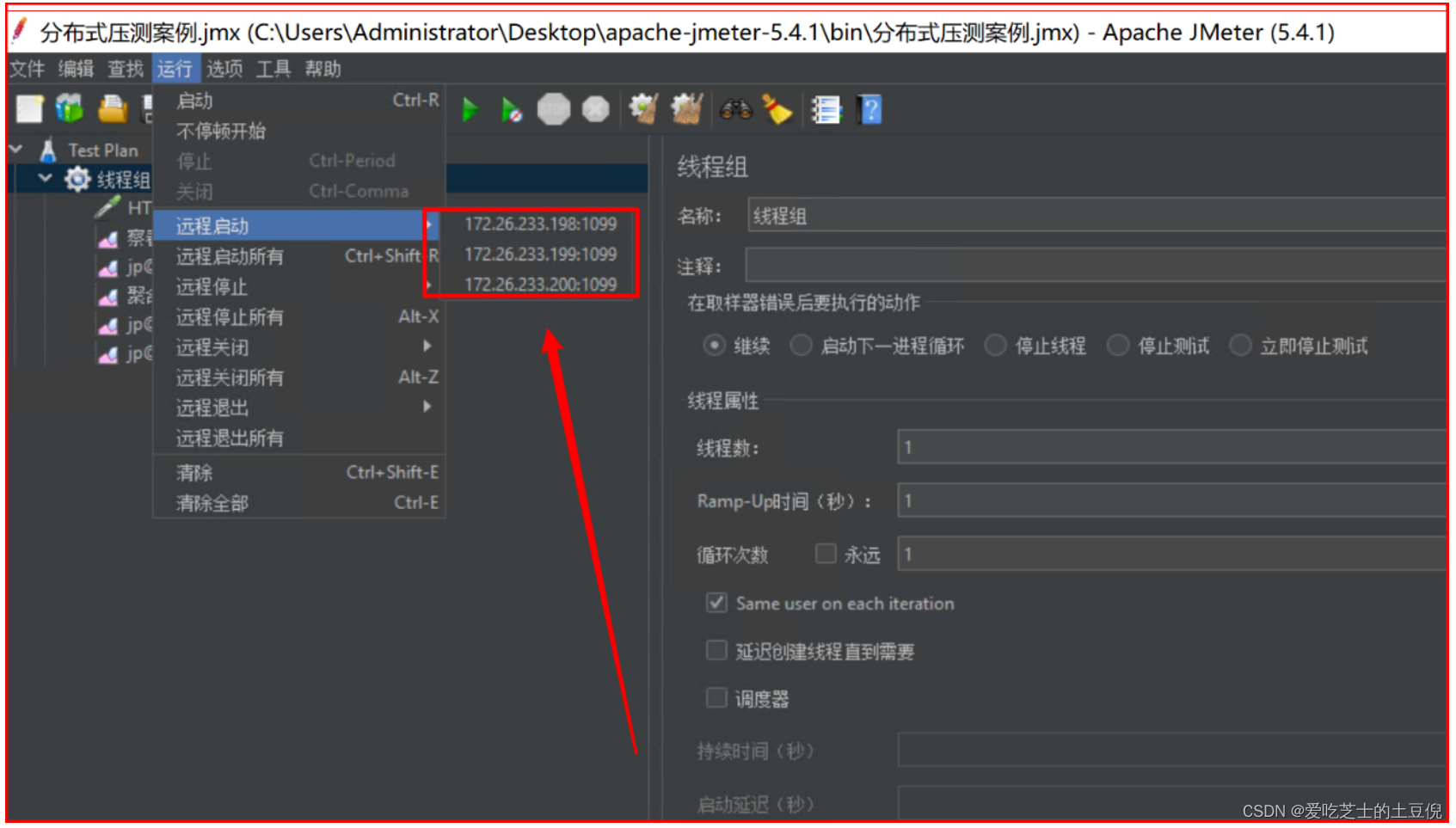
分布式压测
使用JMeter做大并发压力测试的场景下,单机受限与内存、CPU、网络IO,会出现服务器压力还没有上去,但是压测机压力太大已经死机!为了让JMeter拥有更强大的负载能力,JMeter提供分布式压测能力。
- 单机网络带宽有限
- 高延时场景下,单机可模拟最大线程数有限
如下是分布式压测架构:
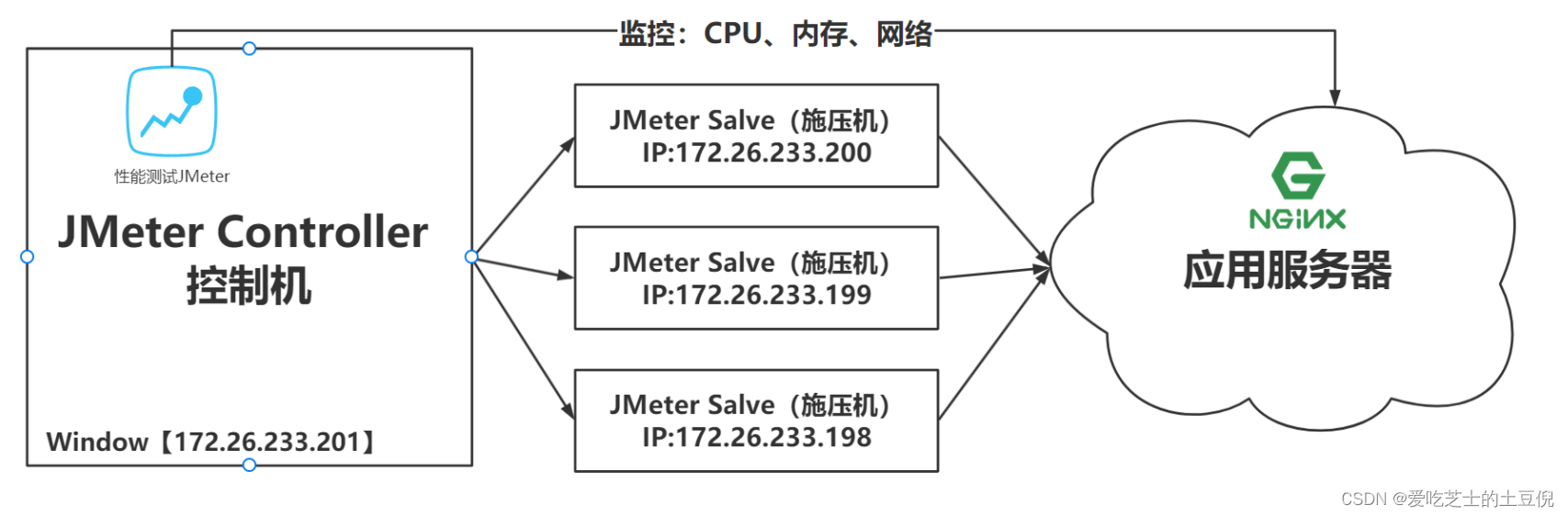
注意:在JMeter Master节点配置线程数10,循环100次【共1000次请求样本】。如果有3台Salve 节点。那么Master启动压测后,每台Salve都会对被测服务发起10x100次请求。因此,压测产生的总样本数量是:10 x 100 x 3 = 3000次。
搭建JMeter Master控制机和JMeter Salve施压机
- 第一步:三台JMeter Salve搭建在Linux【Centos7】环境下
- 第二步:JMeter Master搭建在Windows Server环境下【当然也可以搭建在Linux里面,这里用win是为了方便观看】
搭建注意事项:
- 需保证Salve和Server都在一个网络中。如果在多网卡环境内,则需要保证启动的网卡都在一个网段。
- 需保证Server和Salve之间的时间是同步的。
- 需在内网配置JMeter主从通信端口【1个固定,1个随机】,简单的配置方式就是关闭防火墙,但存在安全隐患。
Windows Server部署JMeter Master
与Window中安装JMeter一样,略
Linux部署JMeter Salve
(1)下载安装
wget https://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apachejmeter-5.4.1.tgztar -zxvf apache-jmeter-5.4.1.tgzmv apache-jmeter-5.4.1 ./apache-jmeter-5.4.1-salve
(2)配置修改rmi主机hostname
# 1.改ip
vim jmeter-server
# RMI_HOST_DEF=-Djava.rmi.server.hostname=本机ip
# 2.改端口
vim jmeter.properties
# RMI port to be used by the server (must start rmiregistry with same port)
server_port=1099
# To change the default port (1099) used to access the server:
server.rmi.port=1098(3)配置rmi_keystore.jks
(4)启动jmeter-server服务
nohup ./jmeter-server > ./jmeter.out 2>&1 &
分布式环境配置
(1)确保JMeter Master和Salve安装正确。
(2)Salve启动,并监听1099端口。
(3)在JMeter Master机器安装目录bin下,找到jmeter.properties文件,修改远程主机选项,添加3个Salve服务器的地址。
remote_hosts=172.17.187.82:1099,172.17.187.83:1099,172.17.187.84:1099
(4)启动jmeter,如果是多网卡模式需要指定IP地址启动
jmeter -Djava.rmi.server.hostname=172.26.233.201
(5)验证分布式环境是否搭建成功: