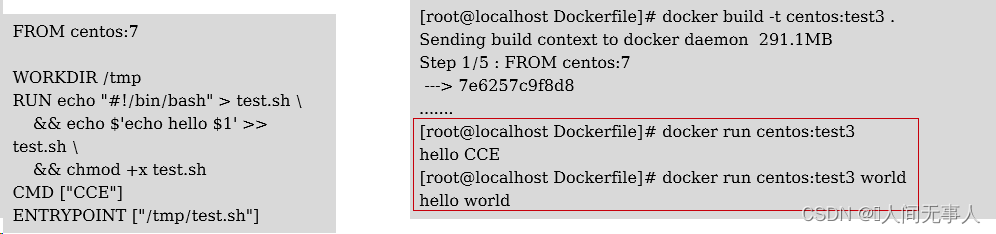
一.什么是ProtoBuf
1.序列化和反序列化概念
序列化:把对象转变为字节序列的过程,称为系列化。
反序列化:把字节序列的内容恢复为对象的过程,称为反序列化。
2.什么情况下需要序列化和反序列化
存储数据:将内存中的对象状态保存在文件中或存储在数据库中时。
网络传输:网络传输数据时,无法直接传输对象,需要在传输前序列化,传输完成后反 序列化成对象,就像学习Socket编程中发送与接收时。
3.如何实现序列化
xml,json,protoBuf这三种工具都可以实现序列化和反序列化
4.ProtoBuf是什么
ProtoBuf是让数据结构序列化的方法,具有以下特点:
- 语言无关、平台无关:即 ProtoBuf 支持 Java、C++、Python 等多种语言,支持多个平台。
- 高效:即比 XML 更小、更快、更为简单。
- 扩展性、兼容性好:你可以更新数据结构,而不影响和破坏原有的旧程序。
二.ProtoBuf简单语法知识
1.文件规范
创建一个ProtoBuf文件,后缀一定以.proto结尾,文件命名全小写字母,多个字母之间以_为分隔符,添加注释的方法和C/C++的一毛一样。
2.ProtoBuf语法分类
ProtoBuf有对个版本,在这里我们使用最新的版本,protobuf3的语法,简称proto3,它是最新的ProtoBuf语法版本。proto3 简化了 ProtoBuf 语言,既易于使用,又可以在更广泛的编程语言中使用。它允许你使用 Java,C++,Python等多种语言生成 protocol buffer 代码。
3.ProtoBuf3语法
syntax
我们在创建一个文件时,一定要在文件开头致命你所使用的语法,如果没有指定,默认使用Protobuf2的语法来使用,
比如:
syntax = "proto3";
syntax为指定语法,一定要有,就像函数中一定要指明函数返回类型一样。
package(声明符)
package 是一个可选的声明符,能表示 .proto 文件的命名空间,在项目中要有唯一性。它的作用是为了避免我们定义的消息出现冲突,就像c++中的namespace一样,指定一个域,防止冲突。
比如:
package person;
message(定义消息)
消息(message):要定义的结构化对象,可以给这个结构化对象中定义对用的属性内容,就像C//C++中的结构体一样,只能够定义对象。
这里强调下为什么要定义对象:
网络传输中,需要传输双方定制协议,定制协议就是定制结构体或者结构化数据,比如:Tcp,Udp。而且将数据存储在数据库时,需将数据统一为对象组织起来,在进行存储。
所以ProtoBuf就是以message的方式支持我们定义协议字段的。比如:
syntax="proto3";
package=package;
message people
{
;
}
定义字段消息
在 message 中我们可以定义其属性字段,字段定义格式为:字段类型 字段名 = 字段唯一编号,比如:
syntax="proto3";
package=package;
message people
{
int32 age=1;
}
int32为字段类型 age为字段名 1为字段唯一编号
下面是protobuf创建类型及所对应的C/C++类型:
注:[1] 变长编码是指:经过protobuf 编码后,原本4字节或8字节的数可能会被变为其他字节数。
比如:
syntax="proto3" package sss message person {string name=1;int32 age=2;string sex=3; }注意:字段唯一编号范围:
2^0~2^29-1,其中,19000~19999不可用,在 Protobuf 协议的实现中,对这些数进行了预留。如果非要在.proto文件中使用这些预留标识号,例如将 name 字段的编号设置为19000,编译时就会报警。值得一提的是,范围为 1 ~ 15 的字段编号需要一个字节进行编码, 16 ~ 2047 内的数字需要两个字节进行编码。编码后的字节不仅只包含了编号,还包含了字段类型。所以 1 ~ 15 要用来标记出现非常频繁的字段,要为将来有可能添加的、频繁出现的字段预留一些出来。

通过上面的学习,我们来实现一个简单的test.proto文件,
syntax="proto3";
package sss;
message person
{string name=1;int32 age=2;string sex=3;
}编辑protobuf命令如下:proto --cpp_out. [文件名]
我们使用的是C++语言,所以编译之后生成两个文件:test.pb.h和test.pb.cc。
对于编译生成的 C++ 代码,包含了以下内容 :
- 对于每个 message ,都会生成一个对应的消息类。
- 在消息类中,编译器为每个字段提供了获取和设置方法,以及一下其他能够操作字段的方法。
- 编辑器会针对于每个 .proto 文件生成.h 和 .cc 文件,分别用来存放类的声明与类的实现。
代码过长,就不展示了,感兴趣的自己做下!!!
编译命令行格式
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.proto
protoc:是protobuf提供的命令行编辑工具。
--proto_path: 指定被编辑的所在目录,可多次指定,可简写为-I。如不指定,则在当前目录下进行搜索。
--cpp_out=: 指定编译后的文件为c++文件。
DST_DIR; 文件路径
path/to/file.proto:要编译的文件。
上述的例子中,每个字段都有设置和获取的方法,getter 的名称与小写字段完全相同,setter 方法以 set_ 开头,每个字段都有一个clear_的方法,可以将字段设置为empty状态。比如:
#include <iostream>#include "test.ph.h"
using namespace sss;
using namespace std;
int main()
{person p1;p1.set_name("张三");p1.set_age(11);p1.set_sex("nan");return 0;
}在消息类的父类MessageLift中,提供了读写消息实例的方法,包括序列化方法和反序列化方法。
class MessageLite {
public:
//序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写入文件
//流
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进行反序列化
//动作
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);
};注意:
序列化的方法为二进制方法,非文本格式;以上三种序列化的方法没有本质区别,只是序列化之后输出的格式不同,可以提供不同场景使用,序列化的 API 函数均为const成员函数,因为序列化不会改变类对象的内容, 而是将序列化的结果保存到函数入参指定的地址中。
更多详细API函数参考:message.h | Protocol Buffers Documentation (protobuf.dev)
序列化和反序列化的使用:看结果
#include "contact.pb.h"
using namespace std;
int main()
{string people_str;contact::PersonInit p1;p1.set_age(100);p1.set_name("张三");p1.set_sex("boy");if (!p1.SerializeToString(&people_str)) {cout << "序列化联系人失败." << endl;}// 打印序列化结果cout << "序列化后的 people_str: " << people_str << endl;if(!p1.SerializePartialToString(&people_str)){cout<<"反序列化失败:"<<endl;}cout<<"反序列化成功:"<<endl<<people_str<<endl;return 0;
}
这就是简单的Protobuf的应用。
接下来是ProtoBuf的语法详解。
三.ProtoBuf语法详解
在这部分,我们使用一个简单的项目推进的方式来讲解语法内容,通过一个通讯录的实现,完成我们从最基础的内容到网络版本的知识。
1.字段规则
singular :消息中可以包含该字段零次或一次(不超过一次)。 proto3 语法中,字段默认使用该规则,可以不用设置。
repeated :消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理解为定义了一个数组。
比如:
syntax="proto3";
package contacts2;
message person
{string name=1;int32 age=2;repeated string phone_num=3;
}2.消息类型的定义与使用
在单个.proto文件中,可以定义多个message,也可以嵌套定义,每个message中的字段编号可以重复,并且,消息字段也可以作为字段类型来使用,比如:
syntax="proto3"; package contacts2;// message Phone{ // string phone_num=1; // } message person {string name=1;int32 age=2;//第一种,单独写法//repeated Phone=3;//第二种,嵌套写法message Phone{string phone_num=1;}repeated Phone=3; }也可以将其他.proto文件中定义的消息导入并使用,但一定要加import 比如:
syntax="proto3"; package contacts2; import "Photo.proto";//将其他文件中的消息字段导入message person {string name=1;int32 age=2;//第三种repeated Phone.Phone phone=3; }syntax="proto3"; package Phone;message Phone{string phone_num=1; }注:在 proto3 文件中可以导入 proto2 消息类型并使用它们,反之亦然
编译
我们可以将以上的内容稍加修改,变为我们的第一版通讯录:
syntax="proto3";
package contacts2;
//import "Photo.proto";//将其他文件中的消息字段导入message peopleInfo
{string name=1;int32 age=2;message Phone{string phone_num=1;}repeated Phone=3;
}message Contact{repeated PeopleInfo contact=1;
}然后编译,编译后生成的 contacts.pb.h contacts.pb.cc 会将老版本的代码覆盖掉,由于代码过长,就不展示啦!!!
上述的代码中:
- 每个字段都有一个 clear_ 方法,可以将字段重新设置回 empty 状态。
- 每个字段都有设置和获取的方法, 获取方法的方法名称与小写字段名称完全相同。但如果是消息类型的字段,其设置方法为 mutable_ 方法,返回值为消息类型的指针,这类方法会为我们开辟好空间,可以直接对这块空间的内容进行修改。
- 对于使用 repeated 修饰的字段,也就是数组类型,pb 为我们提供了 add_ 方法来新增一个值,并且提供了 _size 方法来判断数组存放元素的个数。
我们可以对编译好的代码试用一下:
#include <iostream>
#include <fstream>
#include "contact.pb.h"
using namespace std;
using namespace contacts;
void AddPeopleInfo(PeopleInfo *people_info_ptr)
{cout << "-------------新增联系人-------------" << endl;cout << "请输入联系人姓名: ";string name;getline(cin, name);people_info_ptr->set_name(name);//输入用set_函数cout << "请输入联系人年龄: ";int age;cin >> age;people_info_ptr->set_age(age);cin.ignore(256, '\n');for (int i = 1;; i++){cout << "请输入联系人电话" << i << "(只输入回车完成电话新增): ";string number;getline(cin, number);if (number.empty()){break;}//number需要添加才可以用PeopleInfo_Phone *phone = people_info_ptr->add_phone();phone->set_number(number);}cout << "-----------添加联系人成功-----------" << endl;
}int main()
{Contacts contacts;// 先读取已存在的 contactsfstream input("text.bin",ios::in | ios::binary);if (!input){cout << ": File not found. Creating a new file." << endl;}else if (!contacts.ParseFromIstream(&input))//序列化{cerr << "Failed to parse contacts." << endl;input.close();return -1;}// 新增一个联系人AddPeopleInfo(contacts.add_contacts());//向磁盘文件写入新的 contactsfstream output("test.bin",ios::out | ios::trunc | ios::binary);if (!contacts.SerializeToOstream(&output)){cerr << "Failed to write contacts." << endl;input.close();output.close();return -1;}input.close();//output.close();return 0;
}3:enum类型的使用
语法支持我们定义枚举类型来使用,我们可以定义一个enum类型的使用,
syntax="proto3";
package Phone;
message{enum PhoneType{MP=0;//移动电话TEL=1;//固定电话}
}要注意枚举类型的定义有以下几种规则:
1. 0 值常量必须存在,且要作为第一个元素。这是为了与 proto2 的语义兼容:第一个元素作为默认值,且值为 0。
2. 枚举类型可以在消息外定义,也可以在消息体内定义(嵌套)。
3. 枚举的常量值在 32 位整数的范围内。但因负值无效因而不建议使用(与编码规则有关)。定义时注意:
将两个 ‘具有相同枚举值名称’ 的枚举类型放在单个 .proto 文件下测试时,编译后会报错:某某某常量已经被定义!所以这里要注意:
• 同级(同层)的枚举类型,各个枚举类型中的常量不能重名。
• 单个 .proto 文件下,最外层枚举类型和嵌套枚举类型,不算同级。
• 多个 .proto 文件下,若一个文件引入了其他文件,且每个文件都未声明 package,每个 proto 文件中的枚举类型都在最外层,算同级。
• 多个 .proto 文件下,若一个文件引入了其他文件,且每个文件都声明了 package,不算同级。
下面我们来使用一下:
message Address
{string home_address=1;string unit_address=2;
}message PeopleInfo
{string name=1;int32 age=2;message Phone{string number=1;enum PhoneType {MP = 0; // 移动电话TEL = 1; // 固定电话}PhoneType type=2;}//多组电话repeated Phone phone=3;
}编译生成后的文件:对于在.proto文件中定义的枚举类型,编译生成的代码中会含有与之对应的枚举类型、校验枚举值是否有效的方法 _IsValid、以及获取枚举值名称的方法 _Name。对于使用了枚举类型的字段,包含设置和获取字段的方法,已经清空字段的方法clear_;
4.any类型
字段还可以声明为 Any 类型,可以理解为泛型类型。使用时可以在 Any 中存储任意消息类型。Any 类型的字段也用 repeated 来修饰,Any 类型是 google 已经帮我们定义好的类型,在安装 ProtoBuf 时,其中的 include 目录下查找所有google 已经定义好的 .proto 文件,在此目录下查找:/usr/local/protobuf/include/google/protobuf/
我们可以来使用一下:
message Address
{string home_address=1;string unit_address=2;
}message PeopleInfo
{string name=1;int32 age=2;message Phone{string number=1;enum PhoneType {MP = 0; // 移动电话TEL = 1; // 固定电话}PhoneType type=2;}//多组电话repeated Phone phone=3;google.protobuf.Any data = 4;oneof other_contact {// repeated string qq = 5; // 不能使用 repeatedstring qq = 5;string wechat = 6;}//备注信息map<string,string> remake=7;
}
上述的代码中,对于 Any 类型字段:
设置和获取:获取方法的方法名称与小写字段名称完全相同。设置方法可以使用 mutable_ 方
法,返回值为Any类型的指针,这类方法会为我们开辟好空间,可以直接对这块空间的内容进行
修改;之前说过,我们可以在 Any 字段中存储任意消息类型,这就要涉及到任意消息类型 和 Any 类型的互转。这部分代码就在 Google为我们写好的头文件 any.pb.h 中。使用方法:
- 使用 PackFrom() 方法可以将任意消息类型转为 Any 类型。
- 使用 UnpackTo() 方法可以将 Any 类型转回之前设置的任意消息类型。
- 使用 Is() 方法可以用来判断存放的消息类型是否为 typename T。
方法使用:
Address address;
cout << "请输入联系人家庭地址: ";
string home_address;
getline(cin, home_address);
address.set_home_address(home_address);
cout << "请输入联系人单位地址: ";
string unit_address;
getline(cin, unit_address);
address.set_unit_address(unit_address);
google::protobuf::Any * data = people_info_ptr->mutable_data();
data->PackFrom(address);if (people.has_data() && people.data().Is<Address>())
{Address address;people.data().UnpackTo(&address);if (!address.home_address().empty()) {cout << "家庭地址:" << address.home_address() << endl;}if (!address.unit_address().empty()) {cout << "单位地址:" << address.unit_address() << endl;}
}5.oneof 类型
如果消息中有很多可选字段, 并且将来同时只有一个字段会被设置, 那么就可以使用 oneof 加强这个行为,也能有节约内存的效果。
oneof other_contact {// repeated string qq = 5; // 不能使用 repeatedstring qq = 5;string wechat = 6;}注意:
- 可选字段中的字段编号,不能与非可选字段的编号冲突。
- 不能在 oneof 中使用 repeated 字段。
- 将来在设置 oneof 字段中值时,如果将 oneof 中的字段设置多个,那么只会保留最后一次设置的成员,之前设置的 oneof 成员会自动清除。
- 上述的代码中,对于 oneof 字段:会将 oneof 中的多个字段定义为一个枚举类型。设置和获取:对 oneof 内的字段进行常规的设置和获取即可,但要注意只能设置一个。如果设置多个,那么只会保留最后一次设置的成员。清空oneof字段:clear_ 方法,获取当前设置了哪个字段:_case 方法。
std::cout << "请选择要添加的其他联系方式(1、qq 2、wechat):";int other_contact;std::cin>>other_contact;std::cin.ignore(256, '\n');if(other_contact==1){std::cout<<"输入QQ: ";std::string qq;getline(std::cin, qq);people->set_qq(qq);}else if(other_contact==2){std::cout<<"输入wechat: ";std::string wechat;getline(std::cin, wechat);people->set_wechat(wechat);}else std::cout<<"输入错误!"<<std::endl;switch (people.other_contact_case()){case PeopleInfo::OtherContactCase::kQq:cout << "qq号: " << people.qq() << endl;break;case PeopleInfo::OtherContactCase::kWeixin:cout << "微信号: " << people.weixin() << endl;break;case PeopleInfo::OtherContactCase::OTHER_CONTACT_NOT_SET:break;}6.map类型
语法支持创建一个关联映射字段,也就是可以使用 map 类型去声明字段类型,格式为:
map<key_type, value_type> map_field = N;
要注意的是:
• key_type 是除了 float 和 bytes 类型以外的任意标量类型。 value_type 可以是任意类型。
• map 字段不可以用 repeated 修饰。
• map 中存入的元素是无序的。
使用:
map<string, string> remark = 7; // 备注
清空map: clear_ 方法
• 设置和获取:获取方法的方法名称与小写字段名称完全相同。设置方法为 mutable_ 方法,返回
值为Map类型的指针,这类方法会为我们开辟好空间,可以直接对这块空间的内容进行修改。
7.默认值
反序列化消息时,如果被反序列化的二进制序列中不包含某个字段,反序列化对象中相应字段时,就会设置为该字段的默认值。不同的类型对应的默认值不同:
- 对于字符串,默认值为空字符串。
- 对于字节,默认值为空字节。
- 对于布尔值,默认值为 false。
- 对于数值类型,默认值为 0。
- 对于枚举,默认值是第一个定义的枚举值, 必须为 0。
- 对于消息字段,未设置该字段。它的取值是依赖于语言。
- 对于设置了 repeated 的字段的默认值是空的( 通常是相应语言的一个空列表 )。
- 对于消息字段、oneof字段和any字段,C++ 和 Java 语言中都有 has_ 方法来检测当前字段是否被设置。
8.更新消息
更新规则·
- 禁止修改任何已有字段的字段编号。
- 若是移除老字段,要保证不再使用移除字段的字段编号。正确的做法是保留字段编号(reserved),以确保该编号将不能被重复使用。不建议直接删除或注释掉字段。
- int32, uint32, int64, uint64 和 bool 是完全兼容的。可以从这些类型中的一个改为另一个,而不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,会采用与 C++ 一致的处理方案(例如,若将 64 位整数当做 32 位进行读取,它将被截断为 32 位)。
- sint32 和 sint64 相互兼容但不与其他的整型兼容。
- string 和 bytes 在合法 UTF-8 字节前提下也是兼容的。
- bytes 包含消息编码版本的情况下,嵌套消息与 bytes 也是兼容的。
- fixed32 与 sfixed32 兼容, fixed64 与 sfixed64兼容。
- enum 与 int32,uint32, int64 和 uint64 兼容(注意若值不匹配会被截断)。但要注意当反序列化消息时会根据语言采用不同的处理方案:例如,未识别的 proto3 枚举类型会被保存在消息中,但是当消息反序列化时如何表示是依赖于编程语言的。整型字段总是会保持其的值。
- oneof:
将一个单独的值更改为 新 oneof 类型成员之一是安全和二进制兼容的。若确定没有代码一次性设置多个值那么将多个字段移入一个新 oneof 类型也是可行的。将任何字段移入已存在的 oneof 类型是不安全的。保留字段:reserved
如果通过 删除 或 注释掉 字段来更新消息类型,未来的用户在添加新字段时,有可能会使用以前已经存在,但已经被删除或注释掉的字段编号。将来使用该 .proto 的旧版本时的程序会引发很多问题:数据损坏、隐私错误等等。
确保不会发生这种情况的一种方法是:使用 reserved 将指定字段的编号或名称设置为保留项 当我们再使用这些编号或名称时,protocol buffer 的编译器将会警告这些编号或名称不可用。未知字段
未知字段:解析结构良好的 protocol buffer 已序列化数据中的未识别字段的表示方式。例如,当旧程序解析带有新字段的数据时,这些新字段就会成为旧程序的未知字段。
本来,proto3 在解析消息时总是会丢弃未知字段,但在 3.5 版本中重新引入了对未知字段的保留机制。所以在 3.5 或更高版本中,未知字段在反序列化时会被保留,同时也会包含在序列化的结果中。
9.UnknownFieldSet 类介绍
- UnknownFieldSet 包含在分析消息时遇到但未由其类型定义的所有字段。
- 若要将 UnknownFieldSet 附加到任何消息,请调用 Reflection::GetUnknownFields()。
- 类定义在 unknown_field_set.h 中。
10.UnknownField 类介绍
- 表示未知字段集中的一个字段。
- 类定义在 unknown_field_set.h 中。
使用:
const Reflection *reflection = PeopleInfo::GetReflection();const UnknownFieldSet &unknowSet = reflection->GetUnknownFields(people);for (int j = 0; j < unknowSet.field_count(); j++){const UnknownField &unknow_field = unknowSet.field(j);cout << "未知字段" << j + 1 << ":"<< " 字段编号: " << unknow_field.number()<< " 类型: " << unknow_field.type();switch (unknow_field.type()){case UnknownField::Type::TYPE_VARINT:cout << " 值: " << unknow_field.varint() << endl;break;case UnknownField::Type::TYPE_LENGTH_DELIMITED:cout << " 值: " << unknow_field.length_delimited() << endl;break;}}11.前后兼容性
前后兼容的作用,当我们维护一个很大的分布式系统时,由于无法同时升级说有模块,为了在保证升级过程中,整个系统能够尽可能不受影响,就需要尽量保证通讯协议的“向后兼容”或“向前兼容”。
12.选项 option
proto 文件中可以声明许多选项,使用 option 标注。选项能影响 proto 编译器的某些处理方式。
选项的完整列表在google/protobuf/descriptor.proto中定义。文件分为字段级,消息级,文件级,但并没有所有的选项能作用于所有类型,常见举例:
optimize_for:为文件选项,可以设置 protoc 编译器的优化级别,分别为 SPEED 、
CODE_SIZE 、LITE_RUNTIME 。受该选项影响,设置不同的优化级别,编译 .proto 文件后生成的代码内容不同。
- SPEED:protoc编译器将生成的代码是高度优化的,代码运行效率高,但生成的代码更占空间,SPEED为默认选项。
- CODE_SIZE : proto 编译器将生成最少的类,会占用更少的空间,是依赖基于反射的代码来实现序列化、反序列化和各种其他操作。但和SPEED 恰恰相反,它的代码运行效率较低。这种方式适合用在包含大量的.proto文件,但并不盲目追求速度的应用中。
- LITE_RUNTIME : 生成的代码执行效率高,同时生成代码编译后的所占用的空间也是非常少。这是以牺牲Protocol Buffer提供的反射功能为代价的,仅仅提供 encoding+序列化 功能,所以我们在链接 BP 库时仅需链接libprotobuf-lite,而非libprotobuf。这种模式通常用于资源有限的平台,例如移动手机平台中。
- allow_alias : 允许将相同的常量值分配给不同的枚举常量,用来定义别名。该选项为枚举选项。
本地版本代码实现:
四:网络版本通讯录的实现
Protobuf 还常用于通讯协议、服务端数据交换场景。那么在这个示例中,我们将实现一个网络版本通讯录,模拟实现客户端与服务端的交互,通过 Protobuf 来实现各端之间的协议序列化。
1.环境搭建
Httplib 库:cpp-httplib 是个开源的库,是一个c++封装的http库,使用这个库可以在linux、
windows平台下完成http客户端、http服务端的搭建。使用起来非常方便,只需要包含头文件
httplib.h 即可。编译程序时,需要带上 -lpthread 选项。
镜像仓库:weixin_30886717 / cpp-httplib · GitCodecentos 下编写的注意事项:
如果使用 centOS 环境,yum源带的 g++ 最新版本是4.8.5,发布于2015年,年代久远。编译该项目会出现异常。将 gcc/g++ 升级为更高版本可解决问题。
实现:
// 自定义异常类
class ContactException
{
private:std::string message;
public:ContactException(std::string str = "A problem") : message{str} {}std::string what() const { return message; }
};#include <iostream>
#include "contact.pb.h"
#include "ContactException.h"void menu()
{std::cout << "-----------------------------------------------------" << std::endl<< "--------------- 请选择对通讯录的操作 ----------------" << std::endl<< "------------------ 1、新增联系人 --------------------" << std::endl<< "------------------ 2、删除联系人 --------------------" << std::endl<< "------------------ 3、查看联系人列表 ----------------" << std::endl<< "------------------ 4、查看联系人详细信息 ------------" << std::endl<< "------------------ 0、退出 --------------------------" << std::endl<< "-----------------------------------------------------" << std::endl;
}int main()
{enum OPERATE{QUIT = 0,ADD,DEL,FIND_ALL,FIND_ONE};while (true){menu();std::cout << "---> 请选择:";int choose;std::cin >> choose;std::cin.ignore(256, '\n');try{switch (choose){case OPERATE::ADD:contactsServer.addContact();break;case OPERATE::DEL:contactsServer.delContact();break;case OPERATE::FIND_ALL:contactsServer.findContacts();break;case OPERATE::FIND_ONE:contactsServer.findContact();break;case 0:std::cout << "---> 程序已退出" << std::endl;return 0;default:std::cout << "---> 无此选项,请重新选择!" << std::endl;break;}}catch (const ContactException &e){std::cerr << "---> 操作通讯录时发现异常!!!" << std::endl<< "---> 异常信息:" << e.what() << std::endl;}catch (const std::exception &e){std::cerr << "---> 操作通讯录时发现异常!!!" << std::endl<< "---> 异常信息:" << e.what() << std::endl;}}
}
class ContactsServer
{
public:void addContact();void delContact();void findContacts();void findContact();
private:void buildAddContactRequest(add_contact_req::AddContactRequest* req);void printFindOneContactResponse(find_one_contact_resp::FindOneContactResponse&resp);void printFindAllContactsResponse(find_all_contacts_resp::FindAllContactsResponse&resp);
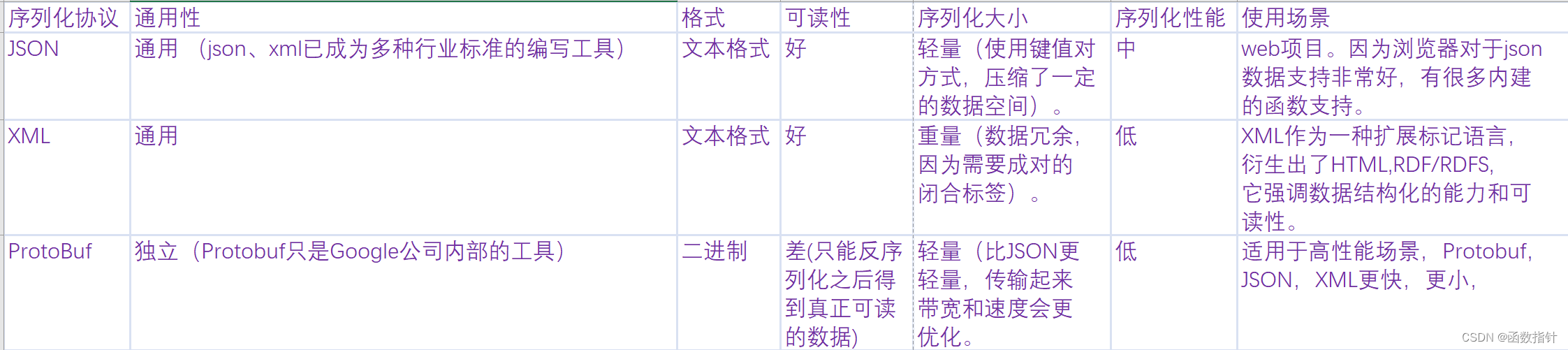
};五:总结:
![洛谷 P9868 [NOIP2023] 词典](https://img-blog.csdnimg.cn/direct/1f9548cb457a4fb599b1a6589e214ca8.png)