文章目录
- 一、增加(插入)INSERT INTO...VALUES(...,...)
- VALUES的方式添加
- 情况一:为表的所有字段按默认顺序插入数据
- 情况二:为表的指定字段插入数据
- 情况三:同时插入多条记录
- 将查询结果插入到表中
- 二、修改(更新)UPDATE...SET...
- 使用 **WHERE** 子句指定需要更新的数据
- 三、删除 DELETE FROM ...
- 使用 WHERE 子句删除指定的记录
- 四、计算列
- 综合案例
一、增加(插入)INSERT INTO…VALUES(…,…)
VALUES的方式添加
情况一:为表的所有字段按默认顺序插入数据
- 一次只能向表中插入一条数据
格式:
INSERT INTO 表名
VALUES (value1,value2,....);
值列表中需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同
举例:
INSERT INTO departments
VALUES(5050,'鹅国',NULL,3200);

情况二:为表的指定字段插入数据
- 只向部分字段中插入值,而其他字段的值为表定义时的默认值
- 表名后面指定的列名,在values内要一一对应,否则报错
格式:
INSERT INTO 表名(column1 [, column2, …, columnn])
VALUES (value1 [,value2, …, valuen]);
举例:
INSERT INTO departments(department_id,department_name)
VALUES(404,666);
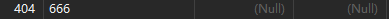
情况三:同时插入多条记录
格式:
所有字段
INSERT INTO table_name
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
部分字段
INSERT INTO table_name(column1 [, column2, …, columnn])
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
举例:
INSERT INTO departments
VALUES
(1017,'散人',NULL,3000),
(1010,'KB',NULL,2800);

总结:
VALUES也可以写成VALUE,但是VALUES是标准写法。字符和日期型数据应包含在单引号中。
将查询结果插入到表中
INSERT还可以将SELECT语句查询的结果插入到表中
格式:
INSERT INTO 目标表名
(tar_column1 [, tar_column2, …, tar_columnn])
SELECT
(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
- 在 INSERT 语句中加入子查询。
- 不必书写 VALUES 子句。
- 子查询中的值列表应与 INSERT 子句中的列名对应。
举例:
添加所有字段
INSERT INTO emp2
SELECT *
FROM employees
WHERE department_id = 90;

添加部分字段:
INSERT INTO emp1(employee_id,last_name,salary,email,hire_date,job_id)
SELECT employee_id,last_name,salary,email,hire_date,job_id
FROM employees
WHERE job_id LIKE '%IT%';
二、修改(更新)UPDATE…SET…
格式:
UPDATE table_name
SET column1=value1, column2=value2, … , column=valuen
[WHERE condition]
- 可以一次更新多条数据。
- 如果需要回滚数据,需要保证在DML前,进行设置:SET AUTOCOMMIT = FALSE;
使用 WHERE 子句指定需要更新的数据
UPDATE departments
SET department_name = '紫色'
WHERE department_id = 404;

如果省略 WHERE 子句,则表中的所有数据都将被更新
这种情况一边查找一边修改,不能这样写:这是错的改不了
UPDATE employees
SET department_id = 4040
WHERE department_id = 404;
三、删除 DELETE FROM …

DELETE FROM table_name [WHERE <condition>];
“[WHERE <condition>]”为可选参数,指定删除条件。
如果没有WHERE子句,DELETE语句将删除表中的所有记录。
举例:
使用 WHERE 子句删除指定的记录

如果省略
WHERE子句,则表中的全部数据将被删除
四、计算列
先定义 两个列 , 第三个列是前两个列的综合(相加的数or…)
CREATE TABLE tb1(
id INT,
a INT,
b INT,
c INT GENERATED ALWAYS AS (a + b) VIRTUAL
);
CREATE TABLE 和 ALTER TABLE 中都支持增加计算列
INSERT INTO tb1(a,b)
VALUES (100,200);

UPDATE tb1
SET a = 500;

综合案例
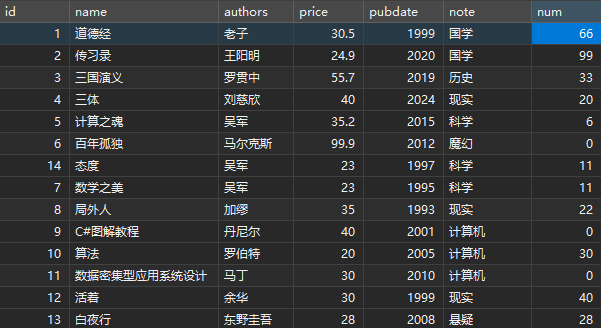
# 1、创建数据库test01_library
CREATE DATABASE IF NOT EXISTS test01_library;# 2、使用当前数据库
USE test01_library;# 3、当创建数据库时忘记添加字符集时 -> 修改数据库字符集
ALTER DATABASE test01_library CHARACTER SET 'utf8';# 4、创建表
CREATE TABLE IF NOT EXISTS books
(id INT,name VARCHAR(50),authors VARCHAR(100),price FLOAT,pubdate YEAR,note VARCHAR(100),num INT
);# 5、插入记录
# 1)不指定字段名称,插入第一条记录
INSERT INTO books
VALUES(1,'道德经','老子',25.5,'1999','国学',66);# 2)指定所有字段名称,插入第二记录
INSERT INTO books(id,name,authors,price,pubdate,note,num)
VALUES(2,'传习录','王阳明',19.9,'2020','国学',99);# 3)同时插入多条记录(剩下的所有记录)
INSERT INTO books
VALUES
(3,'三国演义','罗贯中',55.7,'2019','历史',33),
(4,'三体','刘慈欣',11.8,'2024','科幻',20),
(5,'计算之魂','吴军',35.2,'2015','科学',6);DESC books;# 题目:
# 6、将小说类型('国学')的书的价格都增加5。
UPDATE books
SET price = price + 5
WHERE note = '国学';# 7、将作者为刘慈欣的书的价格改为40,并将说明改为现实。
UPDATE books
SET price = 40,note = '现实'
WHERE authors = '刘慈欣';# 8、删除库存为0的记录。
INSERT INTO books
VALUES(6,'百年孤独','马尔克斯',99.9,'2012','魔幻',0);DELETE FROM books
WHERE num = 0;# 题目:
INSERT INTO books(id,NAME,AUTHORS,price,pubdate,note,num)
VALUES
(7,'数学之美','吴军',23,'1995','科学',11),
(8,'局外人','加缪',35,'1993','现实',22),
(9,'C#图解教程','丹尼尔',40,2001,'计算机',0),
(10,'算法','罗伯特',20,2005,'计算机',30),
(11,'数据密集型应用系统设计','马丁',30,2010,'计算机',0),
(12,'活着','余华',30,1999,'现实',40),
(13,'白夜行','东野圭吾',28,2008,'悬疑',28);# 7、统计书名中包含'三'的书
SELECT COUNT(*)
FROM books
WHERE NAME LIKE '%三%';# 8、统计书名中包含'三'的书的数量和库存总量
SELECT COUNT(*),SUM(num)
FROM books
WHERE NAME LIKE '%三%';# 9、找出“计算机”类型的书,按照价格降序排列
SELECT name,note,price
FROM books
WHERE note = '计算机'
ORDER BY price DESC;# 10、查询图书信息,按照库存量降序排列,如果库存量相同的按照note升序排列
SELECT *
FROM books
ORDER BY num DESC,note;# 11、按照note分类统计书的数量
SELECT COUNT(*),note
FROM books
GROUP BY note;# 12、按照note分类统计书的库存量,显示库存量超过30本的
SELECT SUM(num),note
FROM books
GROUP BY note
HAVING SUM(num) > 30;# 13、查询所有图书,每页显示5本,显示第二页
SELECT *
FROM books
LIMIT 0,5; -- 第一页SELECT *
FROM books
LIMIT 5,5; -- 第二页# 14、按照note分类统计书的库存量,显示库存量最多的
SELECT SUM(num),note
FROM books
GROUP BY note
ORDER BY SUM(num) DESC
LIMIT 0,1;# 15、查询书名达到6个字符的书,不包括里面的空格
SELECT name
FROM books
WHERE CHAR_LENGTH(REPLACE(name,' ','')) >= 6;# 16、查询书名和类型,其中note值为计算机显示科学,国学显示历史
SELECT name,CASE noteWHEN '计算机' THEN'科学6666'WHEN '国学' THEN'历史66666666'ELSEnote
END
FROM books; -- 相当于switch语句# 17、查询书名、库存,其中num值超过30本的,显示滞销,大于0并低于10的,显示畅销,为0的显示无货
SELECT name,CASE WHEN num > 30 THEN'滞销'WHEN num > 0 AND num < 10 THEN'畅销'WHEN num = 0 THEN'无货'ELSE'正常'
END AS '库存状态'
FROM books; -- 相当于 ifelse# 18、统计每一种note的库存量,并合计总量
SELECT SUM(num),IFNULL(note,'合计总量') AS note
FROM books
GROUP BY note WITH ROLLUP;# 19、统计每一种note的数量,并合计总量
SELECT COUNT(*),IFNULL(note,'合计总量') AS note
FROM books
GROUP BY note WITH ROLLUP;# 20、统计库存量前三名的图书
SELECT SUM(num),name
FROM books
GROUP BY name
ORDER BY SUM(num) DESC
LIMIT 0,3SELECT * FROM books ORDER BY num DESC LIMIT 0,3;# 21、找出最早出版的一本书
SELECT name,pubdate
FROM books
ORDER BY pubdate
LIMIT 0,1;# 22、找出计算机note中价格最高的一本书
SELECT name,price
FROM books
WHERE note = '计算机'
ORDER BY price DESC
LIMIT 0,1;# 23、找出书名中字数最多的一本书,不含空格
SELECT name
FROM books
ORDER BY CHARACTER_LENGTH(REPLACE(name,' ','')) DESC
LIMIT 0,1;