2023 年是检索增强生成 (RAG) 的一年,人们探索了许多用例,并使用该技术开发了数百种产品。 从 Q/A 聊天机器人到基于上下文的代理,RAG 的使用一直是 LLM 申请快速增长的主要因素。 支持不断发展的社区以及 Langchain 和 LlamaIndex 等强大框架的可用性,使开发人员可以更轻松地构建复杂的应用程序。

在本文中,我想讨论一种先进的 RAG 技术,它有助于向客户提供了一些高质量的输出,并被证明是一种高效且有效的文本检索方法,即句子窗口检索 (sentence window retrieval - SWR)。

什么事 LIama-index
LlamaIndex 是一个数据框架,供 LLM 应用程序摄取、构建和访问私有或特定领域的数据。
LlamaIndex 是开源的,可用于构建各种应用程序。 在 GitHub 上查看该项目。
什么是句子窗口检索 ?
句子窗口检索背后的核心思想是根据查询有选择地从自定义知识库中获取上下文,然后利用该上下文的更广泛版本来生成更强大的文本。 此过程涉及嵌入一组有限的句子以供检索,这些句子周围的附加上下文(称为 “窗口上下文 - window context”)单独存储并链接到它们。 一旦识别出最相似的句子,就会在将这些句子发送到大型语言模型 (LLM) 进行生成之前重新整合上下文,从而丰富整体上下文理解。 通过将焦点缩小到特定的句子窗口,SWR 旨在提高信息提取的准确性和相关性,从而促进文本的全面合成。
这种方法的一个重要考虑因素是上下文窗口的大小,决定嵌入句子之前和之后有多少句子被合并到 LLM 中进行生成。 该方法相对于传统的检索增强生成(RAG)带来了一些改进:
- 提高精度:通过将搜索范围缩小到特定句子,可以提高信息检索的精度,过滤掉可能削弱结果相关性的不必要信息。
- 效率:SWR 通过最大限度地减少信息检索过程中处理的文本量、避免筛选冗长的文档并提高整体效率来加速流程。
- 灵活性:研究人员受益于该技术的灵活性,使他们能够调整关键字周围文本窗口的大小,从而完善他们的搜索策略。
虽然 SWR 通过关注特定句子来减少标记的使用,但需要权衡,因为关键的文本块可能会被遗漏并最终出现在周围的上下文中。 选择适当的上下文窗口超参数对于解决此问题至关重要。
让我们使用 Elasticsearch 和 LlamaIndex 设置我们自己的基于 SWR 的 RAG 管道。 我们将一步一步地实现每个组件并提供详细的解释。
向量数据库设置
在本文中,我选择 Elasticsearch 作为我们的 Vector 数据库,其背后的原因是:
- 开放几免费:那些计划构建包含向量搜索的可扩展人工智能应用程序的人可以考虑在其专用服务器上建立向量数据库
- 不仅仅是向量数据库:Elasticsearch 是一个构建在 Apache Lucene 之上的开源搜索和分析引擎。 它旨在处理大量数据并提供近乎实时的搜索功能。
在 Docker 上设置 Elasticsearch
使用以下 docker 命令启动单节点 Elasticsearch 实例。我们可以参考之前的文章 “Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发”。我选择不使用安全配置。直接使用 docker compose 来启动 Elasticsearch 及 Kibana:
.env
$ pwd
/Users/liuxg/data/docker8
$ ls -al
total 16
drwxr-xr-x 4 liuxg staff 128 Jan 16 13:00 .
drwxr-xr-x 193 liuxg staff 6176 Jan 12 08:31 ..
-rw-r--r-- 1 liuxg staff 21 Jan 16 13:00 .env
-rw-r--r-- 1 liuxg staff 733 Mar 14 2023 docker-compose.yml
$ cat .env
STACK_VERSION=8.11.3docker-compose.yml
version: "3.9"
services:elasticsearch:image: elasticsearch:${STACK_VERSION}container_name: elasticsearchenvironment:- discovery.type=single-node- ES_JAVA_OPTS=-Xms1g -Xmx1g- xpack.security.enabled=falsevolumes:- type: volumesource: es_datatarget: /usr/share/elasticsearch/dataports:- target: 9200published: 9200networks:- elastickibana:image: kibana:${STACK_VERSION}container_name: kibanaports:- target: 5601published: 5601depends_on:- elasticsearchnetworks:- elastic volumes:es_data:driver: localnetworks:elastic:name: elasticdriver: bridge我们使用如下的命令来启动:
docker-compose up
这样我们就完成了 Elasticsearch 及 Kibana 的安装了。我们的 Elasticsearch 及 Kibana 都没有安全的设置。这个在生产环境中不被推荐使用。
应用设计 - 组装管道
我们将使用 Jupyter notebook 来进行设计。我们在命令行中打入:
jupyter notebook安装依赖
我们使用如下的命令来安装 Python 的依赖包:
pip3 install llama-index openai elasticsearch transformers load_dotenv pypdf我们接下来在当前的工作目录中创建一个叫做 .env 的文件:
.env
OPENAI_API_KEY="YourOpenAIKey"请在 .env 中创建如上所示的变量。你需要把自己的 openai key 写入到上面的文件里。
初始化 LLM
import openai,os
from dotenv import load_dotenv
from llama_index.llms import OpenAIload_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')openai.api_key = openai_api_key
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)在本示例中,我们将使用在 pdf_files 目录下的 sample2.pdf 文件做为示例来进行展示。我们的文档共有 5 页。我们将使用 LlamaIndex 加载、分块和摄取我们的文件。你也可以使用自己的文件来进行练习。
加载数据中
我们使用 Llamaindex 的 SimpleDirectoryReader 来加载我们的 pdf 文件。 你可以使用此阅读器加载目录中的所有内容,但我们指定文件名更精确。
from llama_index import VectorStoreIndex, SimpleDirectoryReader, Documentreader = SimpleDirectoryReader(input_files=['./pdf_files/sample2.pdf'])
docs = reader.load_data()document = Document(text="\n\n".join([doc.text for doc in docs]))reader 将 pdf 中的所有页面加载到单独的文档中,并将它们添加到一个数组中,然后我们迭代所有文档并将它们连接到一个文档中。
将 Elasticsearch 初始化为向量存储
from llama_index.vector_stores import ElasticsearchStorevector_store = ElasticsearchStore(es_url="http://localhost:9200",index_name="books" # If this index doesn't exist, a new one is created
)现在我们已经有了数据和向量存储,让我们开始构建实际的句子窗口检索框架。我们将首先构建一个句子窗口索引,并使用它来创建一个句子窗口查询引擎。
以下是构建句子窗口索引所需的函数:
from llama_index import ServiceContext, VectorStoreIndex, StorageContext
from llama_index.node_parser import SentenceWindowNodeParser
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
from llama_index.indices.postprocessor import SentenceTransformerRerankdef build_sentence_window_index(document, llm, vector_store, embed_model="local:BAAI/bge-small-en-v1.5"
):node_parser = SentenceWindowNodeParser.from_defaults(window_size=3,window_metadata_key="window",original_text_metadata_key="original_text",)sentence_context = ServiceContext.from_defaults(llm=llm,embed_model=embed_model,node_parser=node_parser)storage_context = StorageContext.from_defaults(vector_store=vector_store)sentence_index = VectorStoreIndex.from_documents([document], service_context=sentence_context, storage_context=storage_context)return sentence_indexdef get_sentence_window_query_engine(sentence_index,similarity_top_k=6,rerank_top_n=2,
):postproc = MetadataReplacementPostProcessor(target_metadata_key="window")rerank = SentenceTransformerRerank(top_n=rerank_top_n, model="BAAI/bge-reranker-base")sentence_window_engine = sentence_index.as_query_engine(similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank])return sentence_window_engine让我们分解这些功能并看看每个组件的作用:
Sentence Window Index
def build_sentence_window_index(document, llm, vector_store, embed_model="local:BAAI/bge-small-en-v1.5"
):# create the sentence window node parser w/ default settingsnode_parser = SentenceWindowNodeParser.from_defaults(window_size=3,window_metadata_key="window",original_text_metadata_key="original_text",)sentence_context = ServiceContext.from_defaults(llm=llm,embed_model=embed_model,node_parser=node_parser)storage_context = StorageContext.from_defaults(vector_store=vector_store)sentence_index = VectorStoreIndex.from_documents([document], service_context=sentence_context, storage_context=storage_context)return sentence_indexbuild_sentence_window_index 函数用于从给定文档构建句子窗口的索引。 下面是它的作用的详细说明:
参数:该函数有四个参数:
- document:构建索引的文档。
- llm:要使用的语言模型。
- vector_store:要使用的向量存储。 在本例中,它是 ElasticsearchStore 的一个实例,它使用 Elasticsearch 作为存储后端。
- embed_model:要使用的嵌入模型。 默认值为 “local:BAAI/bge-small-en-v1.5”。
Node Parser:它使用默认设置创建一个 SentenceWindowNodeParser 对象。 该对象用于将文档解析为句子窗口,即句子序列。
Service Context:它使用提供的语言模型、嵌入模型和节点解析器创建 ServiceContext 对象。 该对象用于管理构建索引所需的服务。
Storage Context:它使用提供的向量存储创建一个 StorageContext 对象。 该对象用于管理索引的存储。
Index Creation:它使用服务上下文和存储上下文从文档创建 VectorStoreIndex。
Return Value: 返回创建的 VectorStoreIndex。
Query Engine
def get_sentence_window_query_engine(sentence_index,similarity_top_k=6,rerank_top_n=2,
):# define postprocessorspostproc = MetadataReplacementPostProcessor(target_metadata_key="window")rerank = SentenceTransformerRerank(top_n=rerank_top_n, model="BAAI/bge-reranker-base")sentence_window_engine = sentence_index.as_query_engine(similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank])return sentence_window_engineget_sentence_window_query_engine 函数用于根据给定的句子窗口索引创建查询引擎。 下面是它的作用的详细说明:
参数:该函数采用三个参数:
- Sentence_index:用于创建查询引擎的句子窗口索引。
- similarity_top_k:要返回的最相似结果的数量。 默认值为 6。
- rerank_top_n:要重新排名的顶部结果的数量。 默认值为 2。
Postprocessors:它定义了两个后处理器:
- MetadataReplacementPostProcessor:此后处理器将每个节点的文本替换为 “window” 元数据键的值。
- SentenceTransformerRerank:此后处理器使用句子转换器模型对顶部 rerank_top_n 结果进行重新排名。
查询引擎创建:它使用指定数量的要返回的最相似结果和定义的后处理器从句子窗口索引创建查询引擎。
返回值:返回创建的查询引擎。
重新排名是一个用于细化初始搜索结果的过程。
该函数使用 SentenceTransformerRerank 后处理器进行重新排名。 该后处理器使用句子转换器模型对顶部 rerank_top_n 结果进行重新排名。 rerank_top_n 参数指定应重新排名的顶部结果的数量。
重新排名过程涉及使用句子转换器模型来计算排名靠前的 rerank_top_n 结果的新相似度分数,然后根据新分数对这些结果进行排序。 这可以通过考虑初始排名可能无法捕获的更复杂的语义相似性来帮助提高结果的相关性。
把它放在一起
sentence_index = build_sentence_window_index(document,llm,embed_model="local:BAAI/bge-small-en-v1.5",vector_store=vector_store
)query_engine = get_sentence_window_query_engine(sentence_index=sentence_index)
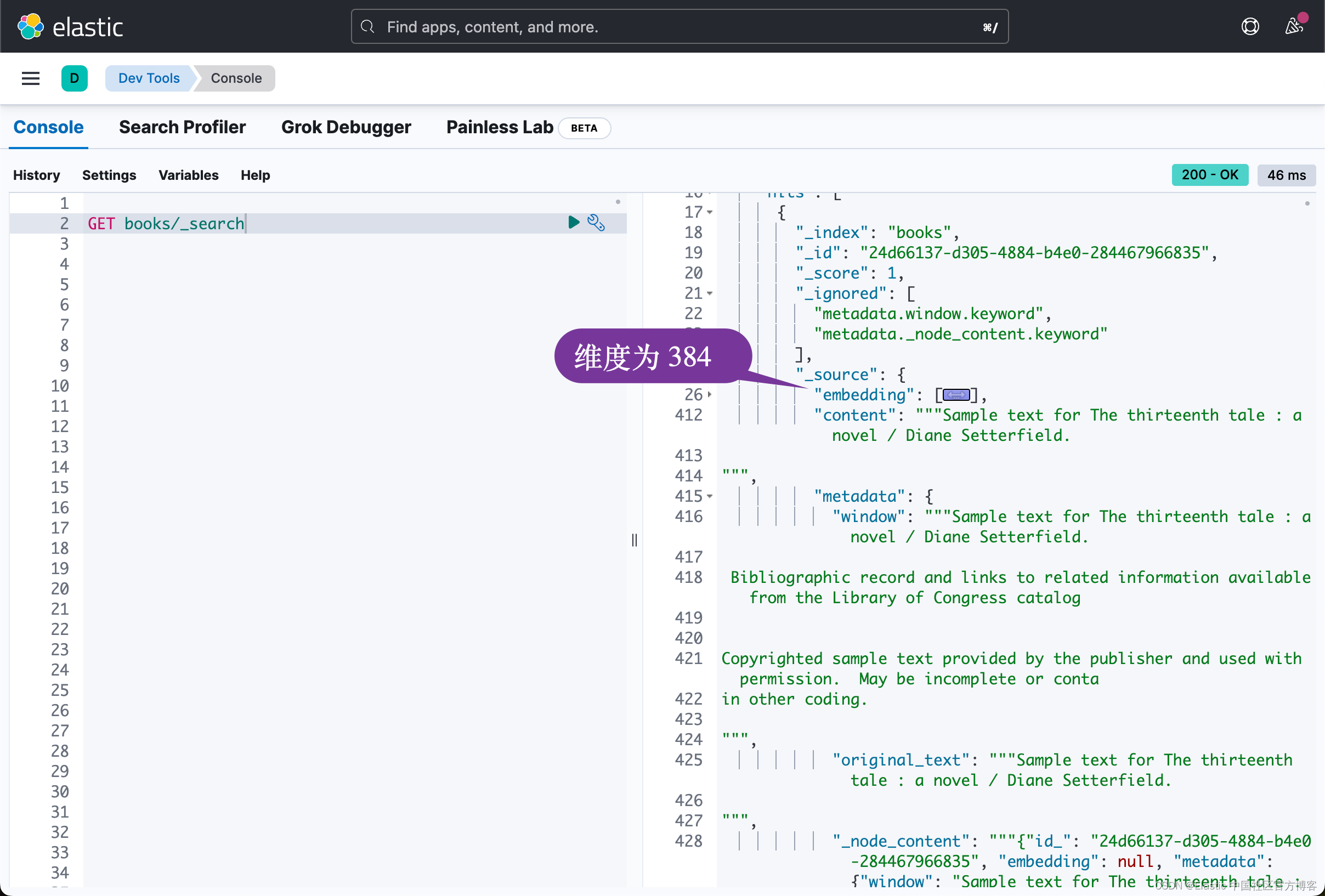
我们可以到 Kibana 里进行查看:

上面的向量的维度是384。我们可以在地址已进行查看。
我们已经有了引擎,让我们尝试从知识库中向它询问一个非常具体的问题:
resp = query_engine.query("what is the article about"
)
print(resp)






说的很详细了!
我鼓励您利用你的知识库进行尝试,并将性能与现有的 RAG 实施进行比较。你可以在地址 https://github.com/liu-xiao-guo/semantic_search_es 下载源码。相关文件:
- https://github.com/liu-xiao-guo/semantic_search_es/tree/main/pdf_files
- https://github.com/liu-xiao-guo/semantic_search_es/blob/main/Elasticsearch%20and%20LlamaIndex%20-%20Sentence%20Window%20Retrieval.ipynb
更多阅读:https://docs.llamaindex.ai/en/stable/examples/vector_stores/Elasticsearch_demo.html#basic-example


![[zabbix] zabbix监控其他](https://img-blog.csdnimg.cn/direct/5e2ec9e265984b4cb0c8c7bfc67b8cb1.png)
![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://img-blog.csdnimg.cn/direct/a736d872c6fc410b9c31bb70c1d3f03b.png)




![[C++] opencv - Mat::convertTo函数介绍和使用场景](https://img-blog.csdnimg.cn/direct/97826b57fdb64c88b05901c08abc548d.png)