更新
补充了gpt-4版本的答案,只能说牛逼,我收回之前的替代不了高级科研工作者的结论,话不多说上答案:
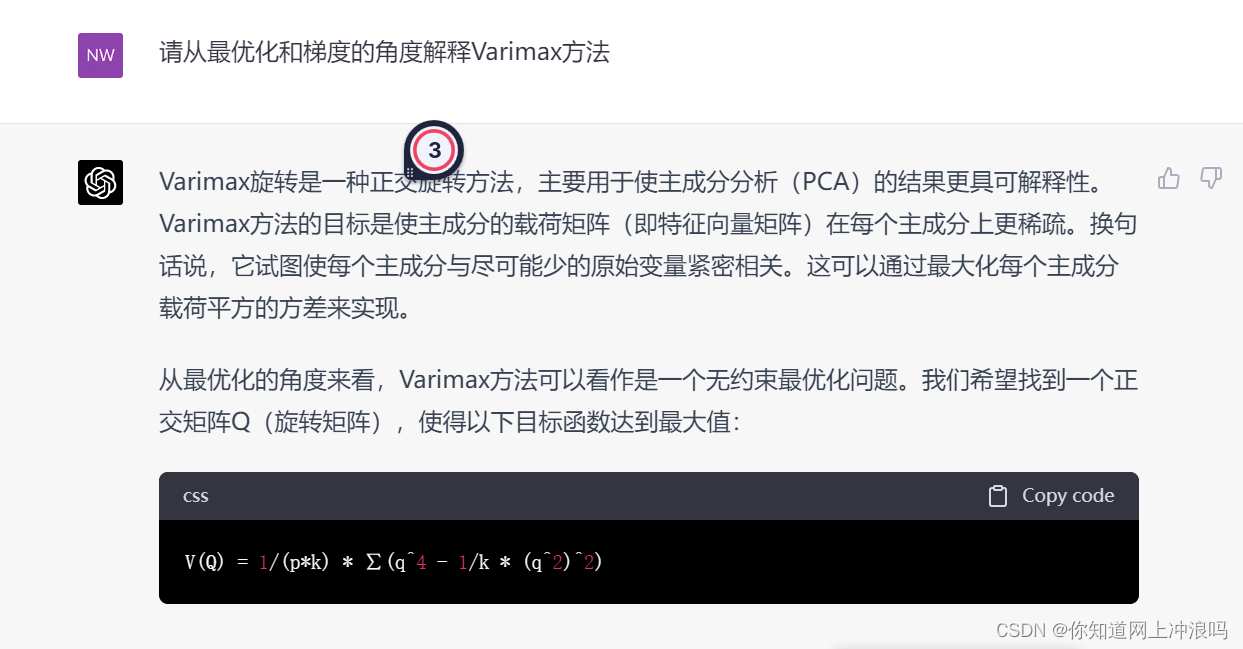

可以看到这里已经吊打got3.5了,它能把这个问题解释的很清楚了
那么关于GPF算法和varimax的关系呢
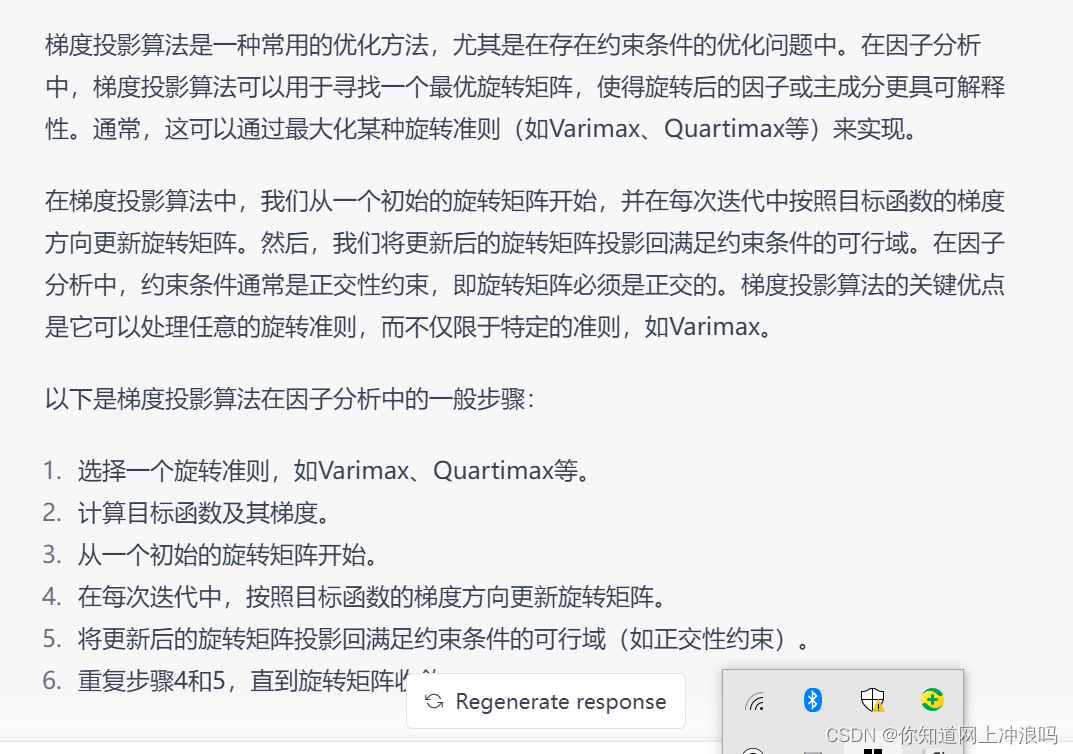
可以看到gpt3.5根本串不起来,但gpt4可以

它能改自己代码的错
并且它给出了基于scipy的一个算法,注意rpca的算法python实现大多来自github仓库这个我从来没见过:

import numpy as np
from scipy.optimize import minimizedef varimax_rotation(components, gamma=1.0, tol=1e-6):n, m = components.shapedef varimax_objective_function(orthogonal_matrix_flat):orthogonal_matrix = orthogonal_matrix_flat.reshape(m, m)rotated_components = components @ orthogonal_matrixvarimax_criterion = (rotated_components ** 2).sum(axis=0) - gamma / n * (rotated_components ** 4).sum(axis=0)return -varimax_criterion.sum()def orthogonality_constraint(orthogonal_matrix_flat):orthogonal_matrix = orthogonal_matrix_flat.reshape(m, m)return np.linalg.norm(orthogonal_matrix.T @ orthogonal_matrix - np.eye(m), ord='fro')initial_guess = np.eye(m).flatten()result = minimize(varimax_objective_function,initial_guess,constraints={'type': 'eq', 'fun': orthogonality_constraint},tol=tol)if not result.success:print("Warning: Varimax rotation did not converge within the specified tolerance")rotation_matrix = result.x.reshape(m, m)return components @ rotation_matrix有点牛皮啊
接下来我让他用公式解释代码原理:
设 U ∈ R p × k U \in \mathbb{R}^{p \times k} U∈Rp×k为旋转前的矩阵, Z = U T ∈ R p × k Z = U T \in \mathbb{R}^{p \times k} Z=UT∈Rp×k为旋转后的矩阵,其中 T ∈ R k × k T \in \mathbb{R}^{k \times k} T∈Rk×k为正交旋转矩阵。Varimax旋转的目标是最大化以下目标函数

注意这个就很吊了
我们对比一下GPA论文中的算法看看它是不是在胡编乱造:

这个用矩阵符号表示的

看它继续解释
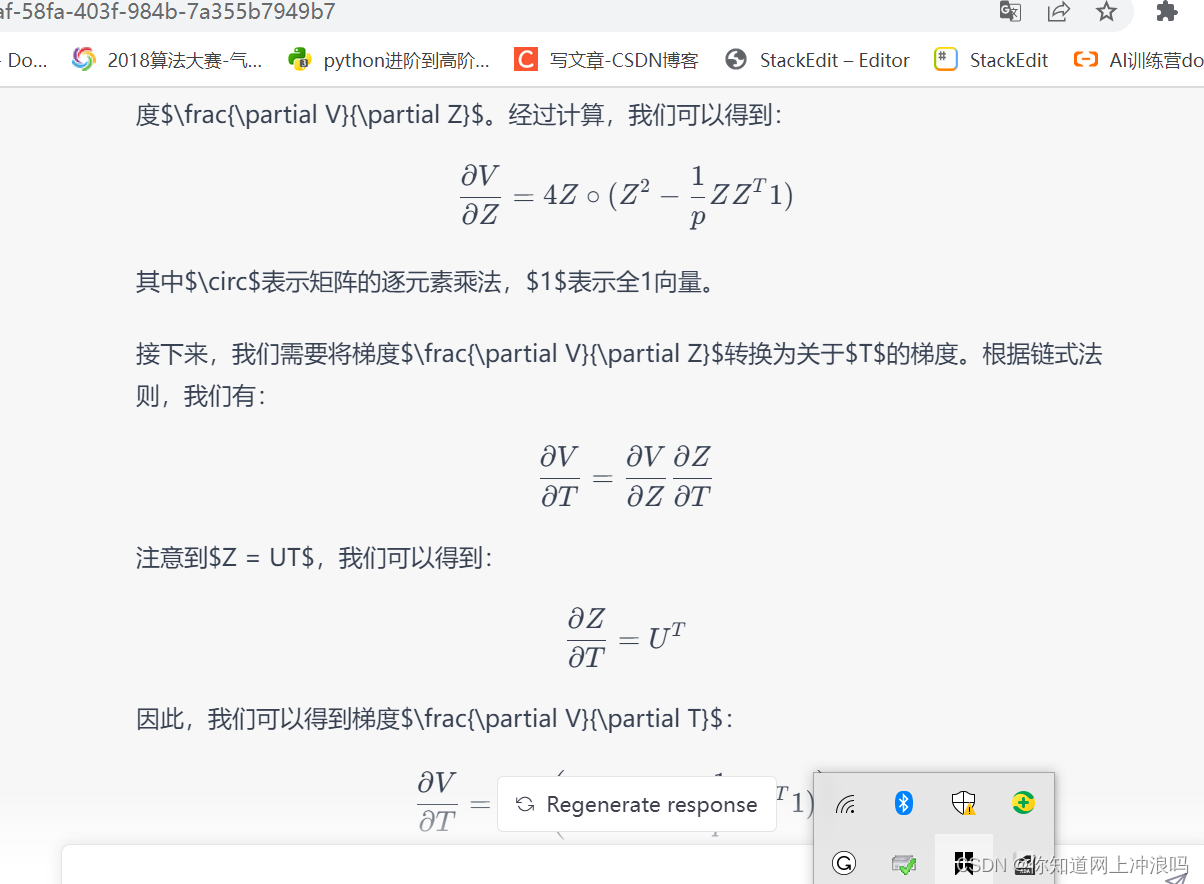
实际上就是计算了梯度 ∂ V ∂ T \frac{\partial V}{\partial T} ∂T∂V。在这个梯度的基础上,通过奇异值分解(SVD)计算新的旋转矩阵,进而优化目标函数
测试流程
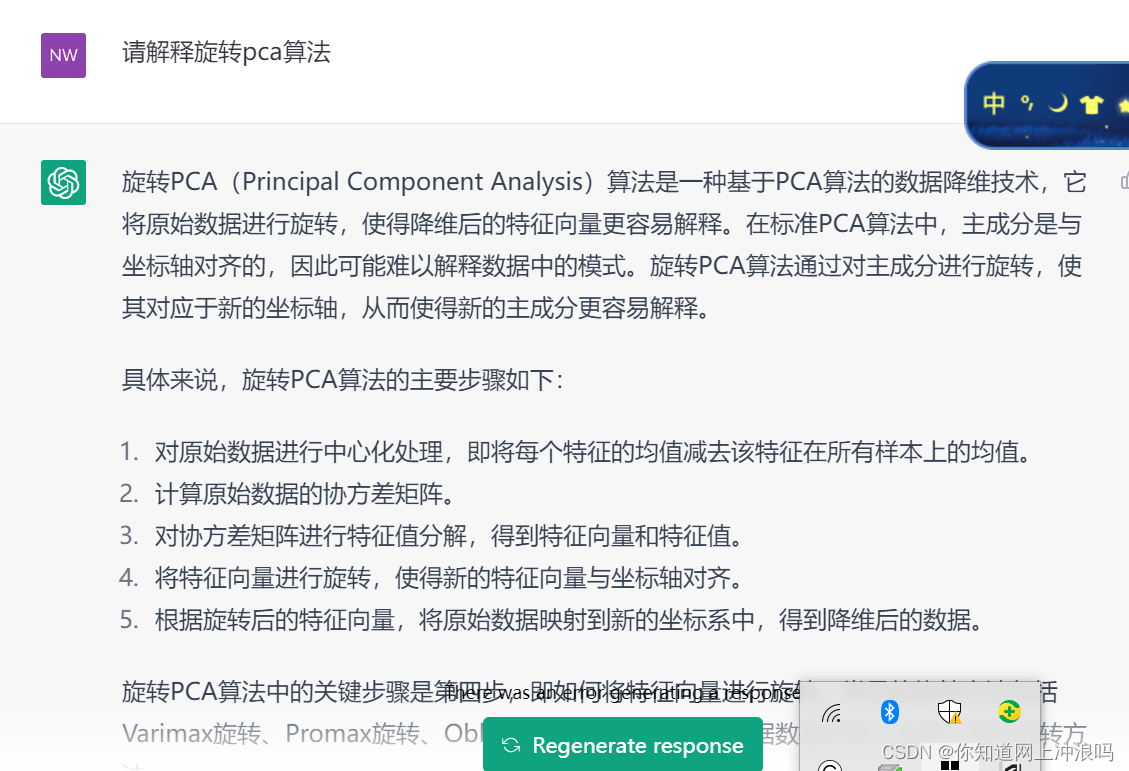
这里我们看看气象统计中的经典算法-REOF/RPCA算法,用chatgpt(3.5)当老师看看会怎么样
首先我们让他解释rpca算法流程,它讲的很清楚,实际上就是旋转基得到新基
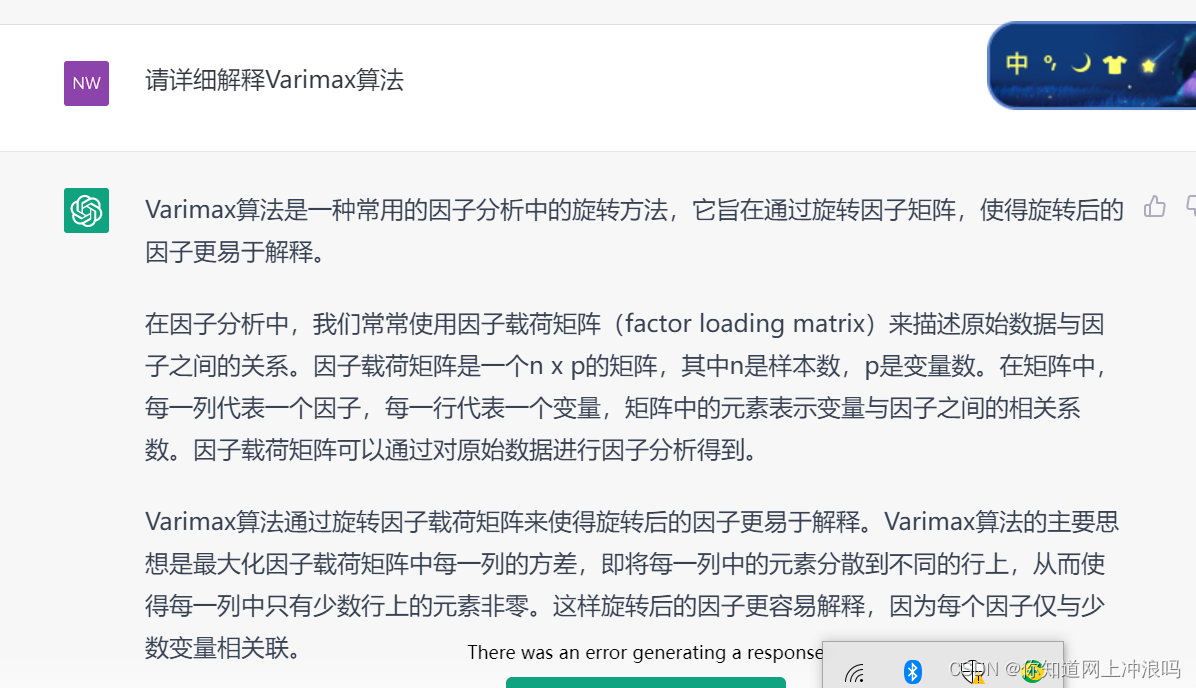
进一步解释varimax旋转即刚性旋转算法,讲的挺清楚哈

接下来我们让它用python实现代码:
到这里我都不怎么惊讶因为这个代码是wiki里直接抄过来的,相当于复制粘贴
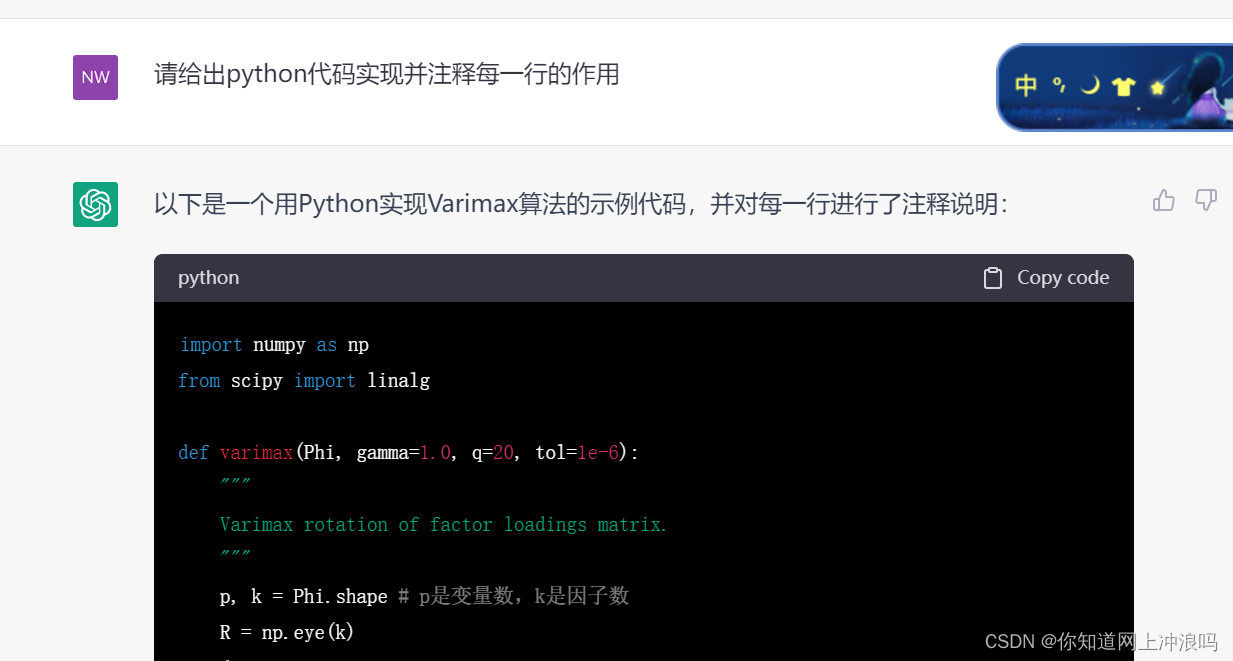
import numpy as np
from scipy import linalgdef varimax(Phi, gamma=1.0, q=20, tol=1e-6):"""Varimax rotation of factor loadings matrix."""p, k = Phi.shape # p是变量数,k是因子数R = np.eye(k)d = 0for i in range(q): # 迭代q次,直到收敛或达到最大迭代次数Phi1 = np.dot(Phi, R)tmp = np.diag(np.sum(Phi1 ** 2, axis=0)) / pU, S, V = linalg.svd(np.dot(Phi1, Phi1.T) - gamma * tmp)R = np.dot(U, V)d1 = np.sum(S)if d1 < d * (1 + tol):breakd = d1return np.dot(Phi, R)接下来它给了逐行说明,这里解释的很清楚了,鄙人曾经在气象家园的帖子里详解了reof算法,基本上跟它这个差不多,到这里虽然觉得有点厉害但仍在我理解范围内
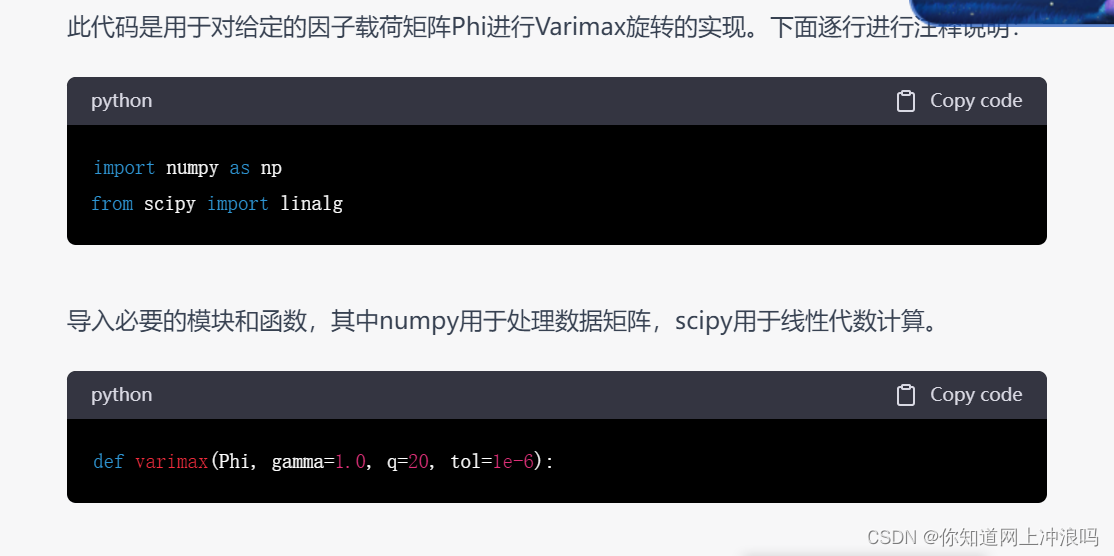
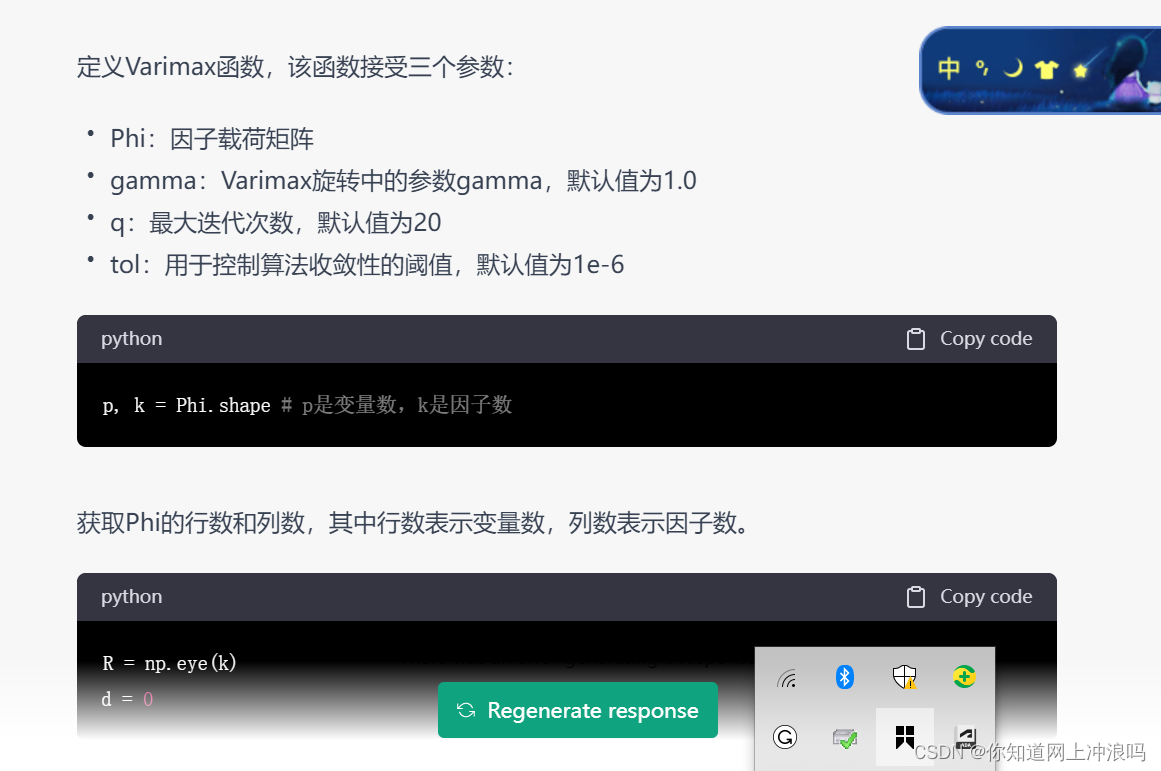
好家伙–注意到这里我就有些觉得恐怖了,它居然指出了算法中核心步骤:
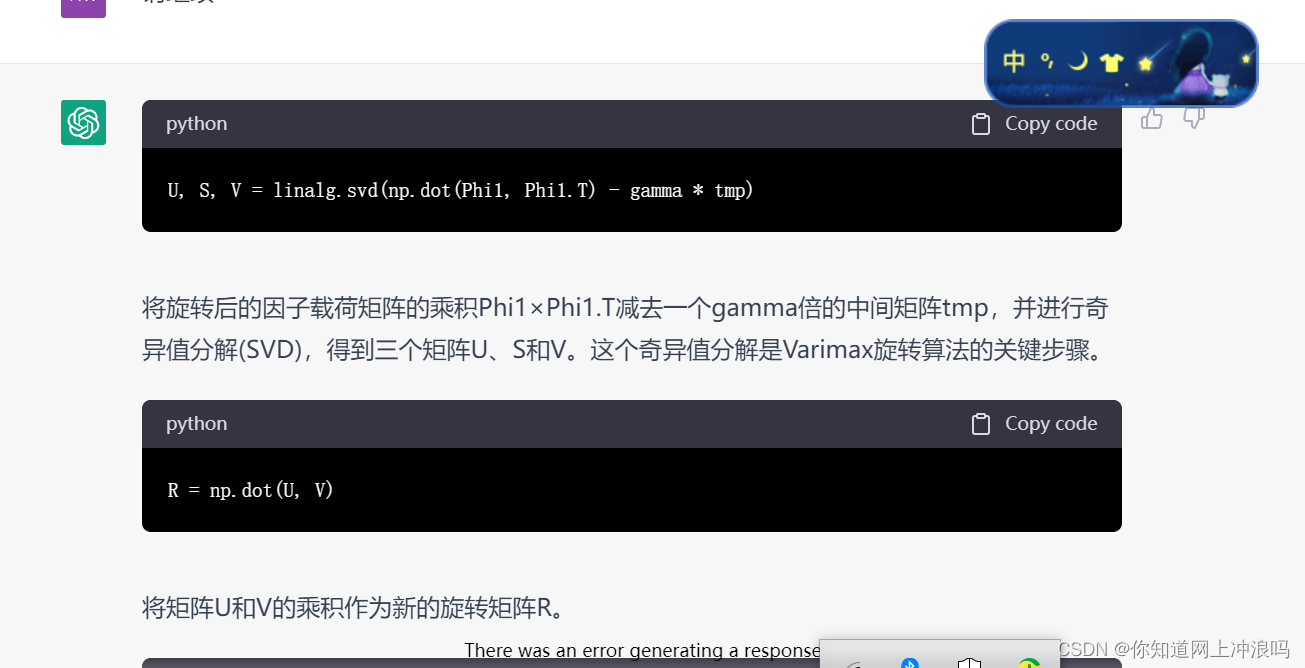
也就是为什么要奇异值分解这步,接下来我将进行诱导提问,看看他能不能讲清楚,如果能完全讲清楚,那么学校就可以完全删除统计学这门课了,因为到这里基本上是个数学不太差的工科大学牲应该都能理解
开始压力测试:

你搁着搁着呢?
继续诱导提问,很显然它的总结并没有涉及到问题的本质,所以我们明确的给它提出来,诱导它
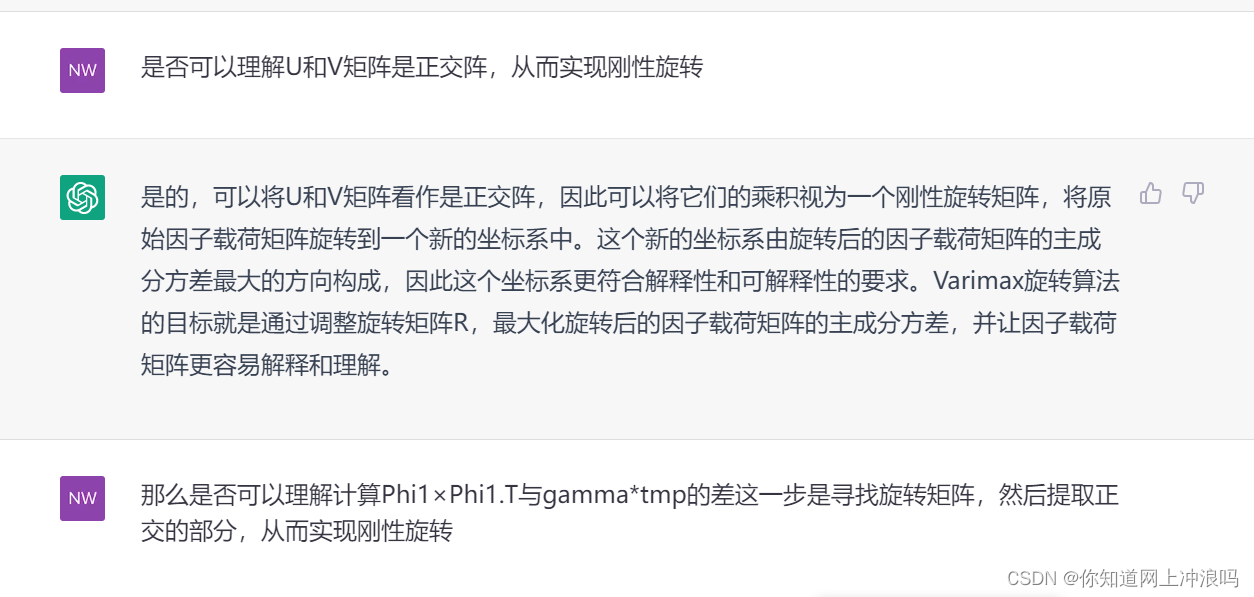

注意这是解释手段而非从设计算法的角度来解释,这里有天差地别,如果不诱导提问它是不会自己回答出来的,但到这里其实已经很离谱了,完全可以替代本科的课程了,因为它解释的很清楚了对于应用工科来说,这些完全够了
继续压力测试
我们剑指向核心

好家伙,干断线了,这个问题的输出极慢,我们继续搞它
实际上到这里它已经妈妈生的了

看看它到底能不能讲清楚
到这里它已经解释到了这是个最优化问题
但又妈妈生的了
那么换一种思路可以先让他了解一下啊GPA梯度投影算法

诱导它从最优化和梯度等关键词的角度来解释
它的回答:
在非负矩阵分解(NMF)问题中,我们希望将一个非负矩阵分解成两个非负矩阵的乘积,即 X = W H X=WH X=WH,其中 X X X是原始矩阵, W W W和 H H H是非负矩阵。我们通常使用最小化误差的方法来求解这个问题,即:
min W , H ∣ ∣ X − W H ∣ ∣ F 2 \min_{W,H}||X-WH||^2_F minW,H∣∣X−WH∣∣F2
其中, ∣ ∣ ⋅ ∣ ∣ F ||\cdot||_F ∣∣⋅∣∣F表示矩阵的Frobenius范数, W W W和 H H H都是非负矩阵。
从最优化问题的角度来看,上述问题等价于:
min W , H 1 2 ∣ ∣ X − W H ∣ ∣ F 2 \min_{W,H}\frac{1}{2}||X-WH||^2_F minW,H21∣∣X−WH∣∣F2
s . t . W , H ≥ 0 s.t.\ W,H\geq 0 s.t. W,H≥0
其中, s . t . s.t. s.t.表示满足约束条件, W , H ≥ 0 W,H\geq 0 W,H≥0表示 W W W和 H H H都是非负矩阵。
为了求解上述问题,我们可以使用梯度下降法来更新矩阵 W W W和 H H H,具体来说,我们需要计算误差矩阵 E = X − W H E=X-WH E=X−WH和梯度矩阵 G = W E H T G=WEH^T G=WEHT,然后根据学习率和梯度矩阵来更新矩阵 W W W和 H H H。
然而,在实际应用中,直接使用梯度下降法可能会导致分解结果不满足非负性约束,因此我们需要进行一些特殊的处理。其中,计算 Φ 1 Φ 1 T − γ ⋅ tmp \Phi_1\Phi_1^T-\gamma \cdot \text{tmp} Φ1Φ1T−γ⋅tmp这一步的作用就是为了确保分解结果满足非负性约束。
具体来说,我们首先通过将 W W W和 H H H中所有小于零的元素置为零来保证非负性约束。然后,我们可以发现,将 W W W和 H H H中所有小于零的元素置为零相当于将矩阵 W W W和 H H H投影到非负空间中,即 W = Proj ( W ) , H = Proj ( H ) W=\text{Proj}(W),H=\text{Proj}(H) W=Proj(W),H=Proj(H)。因此,我们可以将梯度矩阵 G G G投影到切空间中,然后再将其投影到非负空间中,得到一个新的梯度矩阵 G ′ = Proj W , H ( G ) G'=\text{Proj}{W,H}(G) G′=ProjW,H(G),其中 Proj W , H ( ⋅ ) \text{Proj}{W,H}(\cdot) ProjW,H(⋅)表示将矩阵投影到 W W W和 H H H的切空间中,然后再投影到非负空间中。接着,我们可以根据学习率和新的梯度矩阵 G ′ G' G′来更新矩阵 W W W和 H H H。而计算$\Phi_1\Phi_1^T-\gamma \cdot
好家伙又断线了
让他继续解释
…然后,我们可以发现,将矩阵 W W W和 H H H中所有小于零的元素置为零相当于将矩阵 W W W和 H H H投影到非负空间中,即 W = Proj ( W ) , H = Proj ( H ) W=\text{Proj}(W),H=\text{Proj}(H) W=Proj(W),H=Proj(H)。因此,我们可以将梯度矩阵 G G G投影到切空间中,然后再将其投影到非负空间中,得到一个新的梯度矩阵 G ′ = Proj W , H ( G ) G'=\text{Proj}{W,H}(G) G′=ProjW,H(G),其中 Proj W , H ( ⋅ ) \text{Proj}{W,H}(\cdot) ProjW,H(⋅)表示将矩阵投影到 W W W和 H H H的切空间中,然后再投影到非负空间中。接着,我们可以根据学习率和新的梯度矩阵 G ′ G' G′来更新矩阵 W W W和 H H H。
为了实现投影操作,我们可以使用旋转矩阵 Ω \Omega Ω,即:
W ′ = W Ω , H ′ = H Ω W'=W\Omega,H'=H\Omega W′=WΩ,H′=HΩ
其中, Ω \Omega Ω是一个刚性旋转矩阵,它可以将矩阵 W W W和 H H H投影到非负空间中。
我们希望找到一个最优的旋转矩阵 Ω \Omega Ω,使得投影后的矩阵 W ′ W' W′和 H ′ H' H′能够最小化误差矩阵 E ′ = X − W ′ H ′ T E'=X-W'H'^T E′=X−W′H′T。因此,我们可以将上述目标函数转化为:
min Ω 1 2 ∣ ∣ X − W Ω H T Ω T ∣ ∣ F 2 \min_{\Omega}\frac{1}{2}||X-W\Omega H^T\Omega^T||^2_F minΩ21∣∣X−WΩHTΩT∣∣F2
s . t . Ω ∈ O ( k ) s.t.\ \Omega\in O(k) s.t. Ω∈O(k)
其中, O ( k ) O(k) O(k)表示大小为 k k k的正交矩阵集合,即 O ( k ) = Ω ∈ R k × k ∣ Ω T Ω = I k O(k)={\Omega\in\mathbb{R}^{k\times k}|\Omega^T\Omega=I_k} O(k)=Ω∈Rk×k∣ΩTΩ=Ik, I k I_k Ik表示大小为 k k k的单位矩阵。
将上述目标函数展开可得:
1 2 ∣ ∣ X − W Ω H T Ω T ∣ ∣ F 2 \frac{1}{2}||X-W\Omega H^T\Omega^T||^2_F 21∣∣X−WΩHTΩT∣∣F2
= 1 2 ∣ ∣ X − W H T − vec ( W ) vec ( H T ) T vec ( Ω ) vec ( Ω ) T ∣ ∣ F 2 =\frac{1}{2}||X-WH^T-\text{vec}(W)\text{vec}(H^T)^T\text{vec}(\Omega)\text{vec}(\Omega)^T||^2_F =21∣∣X−WHT−vec(W)vec(HT)Tvec(Ω)vec(Ω)T∣∣F2
其中, vec ( A ) \text{vec}(A) vec(A)表示将矩阵 A A A展开成一列向量。
令 P = vec ( W ) vec ( H T ) T P=\text{vec}(W)\text{vec}(H^T)^T P=vec(W)vec(HT)T, Q = vec ( Ω ) vec ( Ω ) T Q=\text{vec}(\Omega)\text{vec}(\Omega)^T Q=vec(Ω)vec(Ω)T,则上述目标函数可以进一步化简为:
1 2 ∣ ∣ X − W H T − P Q ∣ ∣ F 2 \frac{1}{2}||X-WH^T-PQ||^2_F 21∣∣X−WHT−PQ∣∣F2
s . t . Q ∈ O ( k ) s.t.\ Q\in O(k) s.t. Q∈O(k)
其中, Q ∈ O ( k ) Q\in O(k) Q∈O(k)表示 Q Q Q是一个大小为 k k k的正交矩阵。
我们可以使用旋转矩阵的奇异值分解(SVD)来
又妈妈生的了,来继续
我们可以使用旋转矩阵的奇异值分解(SVD)来求解上述问题。具体地,我们将矩阵 P H T PH^T PHT做SVD分解,即:
P H T = U S V T PH^T=USV^T PHT=USVT
其中, U U U和 V V V是正交矩阵, S S S是大小为 r × r r\times r r×r的对角矩阵,其中 r r r是矩阵 P H T PH^T PHT的秩。注意,我们这里使用了 P H T PH^T PHT的SVD分解,而不是 P P P和 H H H各自的SVD分解。这是因为我们要优化的是 W W W和 H H H的乘积 W H T WH^T WHT,而不是它们各自的矩阵分解。
接着,我们可以将旋转矩阵 Ω \Omega Ω表示为 V U T VU^T VUT,即:
Ω = V U T \Omega=VU^T Ω=VUT
则我们的目标函数可以进一步化简为:
1 2 ∣ ∣ X − W H T − P V U T U V S T ∣ ∣ F 2 \frac{1}{2}||X-WH^T-PVU^TUVS^T||^2_F 21∣∣X−WHT−PVUTUVST∣∣F2
= 1 2 ∣ ∣ X − W H T − P U V S T ∣ ∣ F 2 =\frac{1}{2}||X-WH^T-PUVS^T||^2_F =21∣∣X−WHT−PUVST∣∣F2
s . t . U , V ∈ O ( k ) s.t.\ U,V\in O(k) s.t. U,V∈O(k)
其中, U , V ∈ O ( k ) U,V\in O(k) U,V∈O(k)表示 U U U和 V V V是大小为 k k k的正交矩阵。
将上述目标函数展开,我们可以得到:
1 2 tr ( X T X ) − tr ( X T W H T ) − tr ( H W P T ) − 1 2 tr ( S T U T V T P T P U T V S ) \frac{1}{2}\text{tr}(X^TX)-\text{tr}(X^TWH^T)-\text{tr}(HWP^T)-\frac{1}{2}\text{tr}(S^TU^TV^TP^TPU^TVS) 21tr(XTX)−tr(XTWHT)−tr(HWPT)−21tr(STUTVTPTPUTVS)
注意到 tr ( H W P T ) \text{tr}(HWP^T) tr(HWPT)和 tr ( S T U T V T P T P U T V S ) \text{tr}(S^TU^TV^TP^TPU^TVS) tr(STUTVTPTPUTVS)不依赖于 Ω = V U T \Omega=VU^T Ω=VUT,因此我们可以将它们忽略,得到:
1 2 tr ( X T X ) − tr ( X T W H T ) \frac{1}{2}\text{tr}(X^TX)-\text{tr}(X^TWH^T) 21tr(XTX)−tr(XTWHT)
s . t . U , V ∈ O ( k ) s.t.\ U,V\in O(k) s.t. U,V∈O(k)
接下来,我们可以使用梯度下降等优化算法来求解上述目标函数,从而得到最优的旋转矩阵 Ω \Omega Ω。具体地,我们可以在每次迭代中使用以下更新规则:
U ← U − η ∂ ∂ U tr ( X T W H T ) U\leftarrow U-\eta\frac{\partial}{\partial U}\text{tr}(X^TWH^T) U←U−η∂U∂tr(XTWHT)
V ← V − η ∂ ∂ V tr ( X T W H T ) V\leftarrow V-\eta\frac{\partial}{\partial V}\text{tr}(X^TWH^T) V←V−η∂V∂tr(XTWHT)
其中, η \eta η是学习率, ∂ ∂ U tr ( X T W H T ) \frac{\partial}{\partial U}\text{tr}(X^TWH^T) ∂U∂tr(XTWHT)和 ∂ ∂ V tr ( X T W H T ) \frac{\partial}{\partial V}\text{tr}(X^TWH^T) ∂V∂tr(XTWHT)分别是目标函数对 U U U和 V V V的梯度。在每次迭代中,我们可以将 U U U和 V V V更新为它们的投影矩阵,以保证它们满足$U,V
同时是正交矩阵。
接下来,我们考虑如何计算目标函数对 U U U和 V V V的梯度。具体地,我们可以使用梯度投影算法(Gradient Projection Algorithm,GPA)来计算梯度。GPA是一种基于投影的优化算法,它可以将一个点投影到一个约束集上,从而得到在该约束集上的最优解。
在本问题中,我们的约束集是 U , V ∈ O ( k ) U,V\in O(k) U,V∈O(k),即 U U U和 V V V是大小为 k k k的正交矩阵。因此,我们需要将梯度投影到正交矩阵集合 O ( k ) O(k) O(k)上。
具体地,我们可以将 U U U和 V V V写成特征值分解的形式:
U = Q Λ U T U=Q\Lambda U^T U=QΛUT
V = Q Γ V T V=Q\Gamma V^T V=QΓVT
其中, Q Q Q是正交矩阵, Λ \Lambda Λ和 Γ \Gamma Γ是对角矩阵, U T U^T UT和 V T V^T VT是 U U U和 V V V的转置矩阵。
接着,我们可以计算目标函数对 U U U和 V V V的梯度,分别为:
∂ ∂ U tr ( X T W H T ) = − ( X W H T − X U U T X W H T ) \frac{\partial}{\partial U}\text{tr}(X^TWH^T)=-(XWH^T-XUU^TXWH^T) ∂U∂tr(XTWHT)=−(XWHT−XUUTXWHT)
∂ ∂ V tr ( X T W H T ) = − ( X W H T − X V Γ Γ T V T X W H T ) \frac{\partial}{\partial V}\text{tr}(X^TWH^T)=-(XWH^T-XV\Gamma\Gamma^TV^TXWH^T) ∂V∂tr(XTWHT)=−(XWHT−XVΓΓTVTXWHT)
接下来,我们将梯度投影到正交矩阵集合 O ( k ) O(k) O(k)上,即求解以下最小化问题:
min Q , Λ 1 2 ∣ ∣ Q Λ U T X W H T − X W H T U Λ T Q T ∣ ∣ F 2 \min_{Q,\Lambda}\frac{1}{2}||Q\Lambda U^TXWH^T-XWH^TU\Lambda^TQ^T||^2_F minQ,Λ21∣∣QΛUTXWHT−XWHTUΛTQT∣∣F2
s . t . Q ∈ O ( k ) , Λ ∈ R k × k s.t.\ Q\in O(k),\Lambda\in\mathbb{R}^{k\times k} s.t. Q∈O(k),Λ∈Rk×k
这是一个典型的最小化问题,可以使用特征值分解等方法求解。具体地,我们可以将矩阵 U T X W H T U^TXWH^T UTXWHT做特征值分解,即:
U T X W H T = U D U T U^TXWH^T=UDU^T UTXWHT=UDUT
其中, D D D是对角矩阵, U U U是正交矩阵。然后,我们可以将 Q Q Q和 Λ \Lambda Λ分别设置为 U U U的前 k k k个特征向量和对应的特征值,即:
Q = U ( : , 1 : k ) Q=U(:,1:k) Q=U(:,1:k)
Λ = diag ( D 1 : k , 1 : k ) \Lambda=\text{diag}(D_{1:k,1:k}) Λ=diag(D1:k,1:k)
这样,我们就得到了最小化问题的最优解。最后,我们可以将 U U U和 V V V分别更新为 Q U T QU^T QUT和 Q Γ V T Q\Gamma V^T QΓVT,即:
U ← Q U T U\leftarrow QU^T U←QUT
V ← Q Γ V T V\leftarrow Q\Gamma V^T V←QΓVT
这样,我们就得到了更新后的 U U U和 V V V,从而得到了更新后的旋转矩阵$\Omega=VU
它终于bb完了,下来就是关键时刻,看看它能不能串起来

好吧它开始胡言乱语了
开始胡给代码了
在一次迭代中,梯度的方向并不一定是旋转矩阵。假设我们在当前迭代中希望找到一个旋转矩阵 R R R,使得目标函数 Q Q Q 最小化。在某个旋转矩阵 R 0 R_0 R0 的位置,我们可以计算出目标函数 Q Q Q 在 R 0 R_0 R0 处的梯度 G G G,并沿着梯度的反方向移动一定距离 α \alpha α,得到新的旋转矩阵 R 1 = R 0 − α G R_1 = R_0 - \alpha G R1=R0−αG。这里梯度 G G G 的方向不一定是旋转矩阵的方向,因为梯度方向只是指向最小值方向的一个向量,而旋转矩阵是由一系列矩阵乘法组成的,不一定与梯度方向一致。
在Varimax算法中,我们通过迭代多次梯度下降来逐步优化目标函数,并逐步逼近最优解。每次迭代都可以得到一个新的旋转矩阵,而这个矩阵是由上一次迭代的旋转矩阵和当前梯度方向共同作用得到的。因此,旋转矩阵的方向并不完全由梯度方向决定,而是由多次迭代的结果共同作用得到的。
到这里我们已经大概理解了整个算法步骤
但gpt显然不能把它串起来
因为维基上没有python的实现所以我们换成r试试

总结
干掉本科老师问题不大,但很显然它不能完全讲明白,即使在诱导提问的情况下,并且有很多错
所以可以暂时放下心,它应该替代不了高级的科研工作者