文章目录
- 文章介绍
- 文章模型
- encoder部分
- ATE任务
- TOWE任务
- ATSA任务
- 番外
文章地址: https://arxiv.org/abs/2110.07303v1
文章介绍
目前的关于ASTE三元组提取的方面级情感分析论文大多关注于简单的句式,比如一个方面实体仅有一个意见词加以修饰,但在一些情况下,由于我们通常会对事物的不同的属性做出不同的评价,因此对于某一个事物的最终情感将取决于这些不同意见词的总和。为了应对上述问题,这篇论文在ASTE方面级情感三元组提取任务的基础上提出了方面级情感多意见修饰三元组提取任务(aspect Sentiment Multiple Opinions Triplet Extraction, ASMOTE),并提出了一个方面指导框架( Aspect-Guided Framework, AGF)来解决上述问题。AGF首先会识别语句中含有的方面实体,再通过序列标注注意力(Sequence Labeling Attention, SLA)辅助识别对应的意见词和情感。
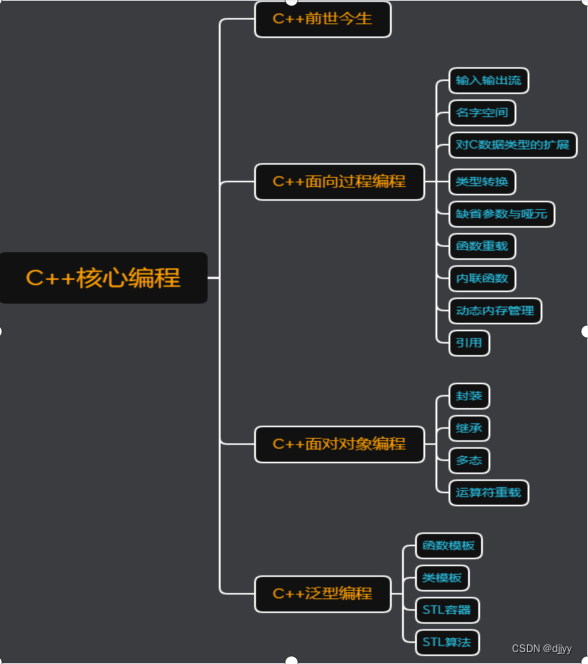
文章模型
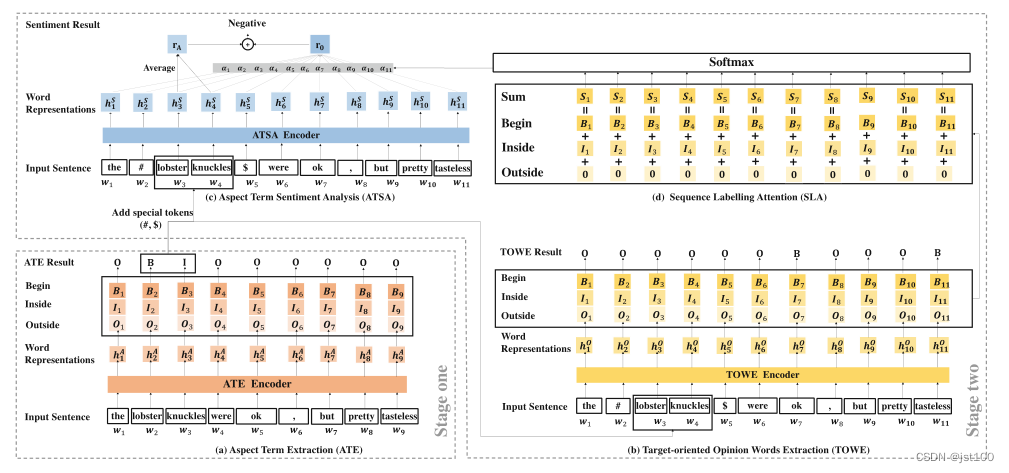
encoder部分
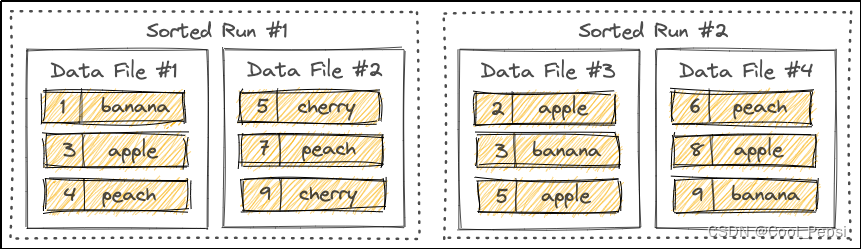
根据上述框架所示,对于不同的任务(ATE、TOWE、ATSA)作者是用了三种不同的模型。ATE是BERT+BiLSTM,TOWE是BERT,ATSA是BERT+BiLSTM,(感觉都用BERT+BiLSTM也行)。
ATE任务
该项任务比较简单,作者采用了BIO标注体系,对于每一个token来讲就为一个三分类任务,通过一个softmax函数输出类别最高的概率。
TOWE任务
这里作者首先对第一步提取出的aspect做了处理,在其起始位置和结束问题添加了特殊符号,新句子如下所示:
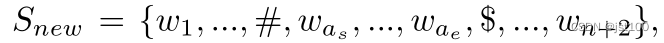
然后再通过一个线性层和一个softmax函数判断(仍然采用的是BIO标注)。
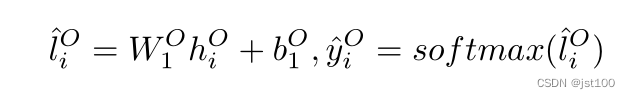
为了更好地获得相应的情感,作者这里引用了序列标注注意力机制(Sequence Labeling Attention,SLA),但是作者这里说的不明确只是给了一个这样的转换(具体可能要看代码):
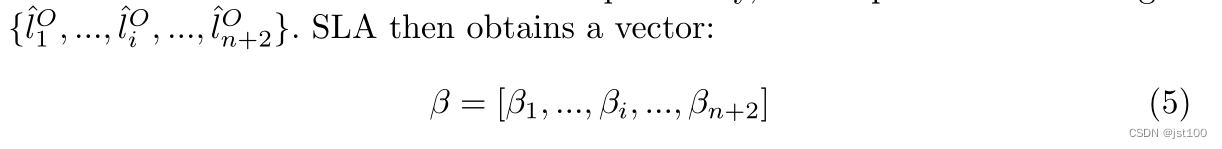
然后应用softmax函数得到注意力权重向量
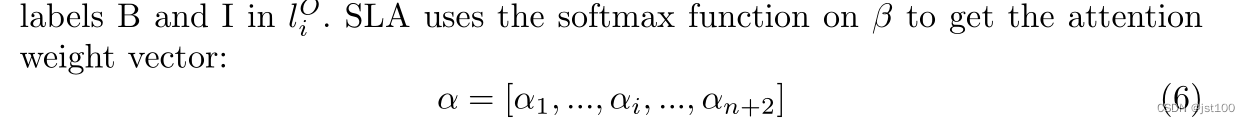
ATSA任务
作者这里首先对方面实体的表示做了相应的平均池化操作

然后通过上一步得到的对应方面实体的意见词表示的注意力权重向量与隐藏层输出表示相乘得到相应得分:
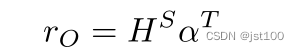
然后将二者拼接起来:
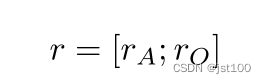
最后通过一个softmax判断:
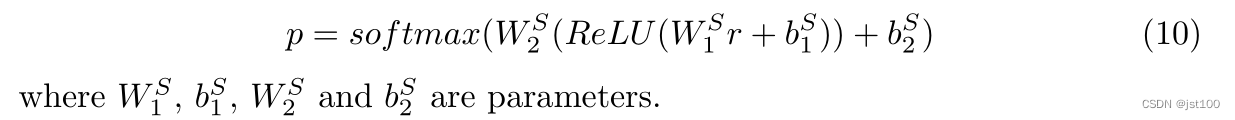
番外
感觉这篇文章与我之前读到的《A More Fine-Grained Aspect-Sentiment-Opinion Triplet Extraction Task》有点像,具体也不多说了,我对于这篇文章的阅读笔记:https://blog.csdn.net/jst100/article/details/124396658