欢迎关注我们组的微信公众号,更多好文章在等你呦!
微信公众号名:碳硅数据
公众号二维码:
 今天看代码看到了一个很好的关于batchsampler的实现,做了一些测试,记录一下
今天看代码看到了一个很好的关于batchsampler的实现,做了一些测试,记录一下
import torch
from torch.utils.data import Dataset
from torch.utils.data.sampler import Sampler
from torch.utils.data import DataLoader
import numpy as np class SingleCellDataset(Dataset):"""Dataloader of single-cell data"""def __init__(self, adata, use_layer='X'):"""create a SingleCellDataset objectParameters----------adataAnnData object wrapping the single-cell data matrix"""self.adata = adataself.shape = adata.shapeself.use_layer = use_layerdef __len__(self):return self.adata.shape[0]def __getitem__(self, idx):if self.use_layer == 'X':if isinstance(self.adata.X[idx], np.ndarray):x = self.adata.X[idx].squeeze().astype(float)else:x = self.adata.X[idx].toarray().squeeze().astype(float)else:if self.use_layer in self.adata.layers:x = self.adata.layers[self.use_layer][idx]else:x = self.adata.obsm[self.use_layer][idx]domain_id = self.adata.obs['batch'].cat.codes.iloc[idx]return x, domain_id, idxclass BatchSampler(Sampler):"""Batch-specific Samplersampled data of each batch is from the same dataset."""def __init__(self, batch_size, batch_id, drop_last=False):"""create a BatchSampler objectParameters----------batch_sizebatch size for each samplingbatch_idbatch id of all samplesdrop_lastdrop the last samples that not up to one batch"""self.batch_size = batch_sizeself.drop_last = drop_lastself.batch_id = batch_iddef __iter__(self):batch = {}sampler = np.random.permutation(len(self.batch_id))for idx in sampler:c = self.batch_id[idx]if c not in batch:batch[c] = []batch[c].append(idx)if len(batch[c]) == self.batch_size:yield batch[c]batch[c] = []for c in batch.keys():if len(batch[c]) > 0 and not self.drop_last:yield batch[c]def __len__(self):if self.drop_last:return len(self.batch_id) // self.batch_sizeelse:return (len(self.batch_id)+self.batch_size-1) // self.batch_size# scdata = SingleCellDataset(adata, use_layer="X") # Wrap AnnData into Pytorch Dataset
# batch_sampler = BatchSampler(64, adata.obs['batch'], drop_last=False)
# testloader = DataLoader(scdata, batch_sampler=batch_sampler, num_workers=0)
测试如下
from torch.utils.data import sampler
# 定义数据和对应的采样
data = list([17, 22, 3, 41, 8])
seq_sampler = sampler.SequentialSampler(data_source=data)
# 迭代获取采样器生成的索引
for index in seq_sampler:print("index: {}, data: {}".format(str(index), str(data[index])))结果如下
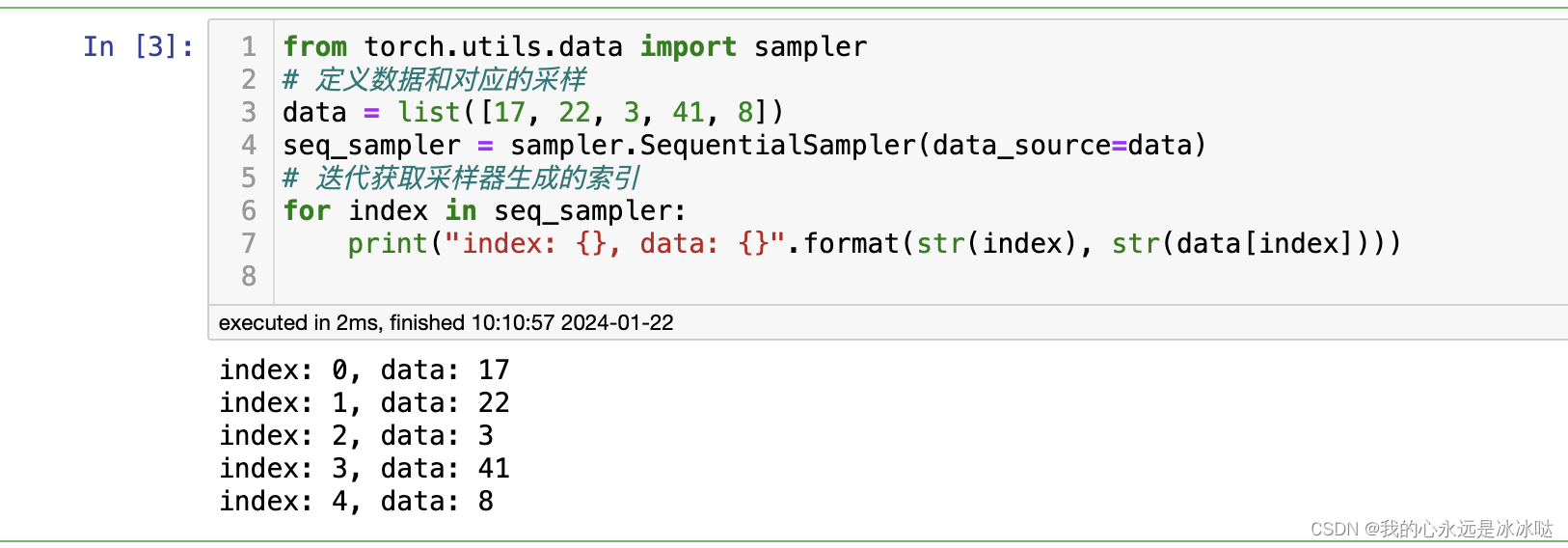
首先要搞清楚这个sampler和Dataloader之间的关系,从上面的额例子可以看到,seq_sampler是直接可以迭代输出看结果的
,这个对我很重要
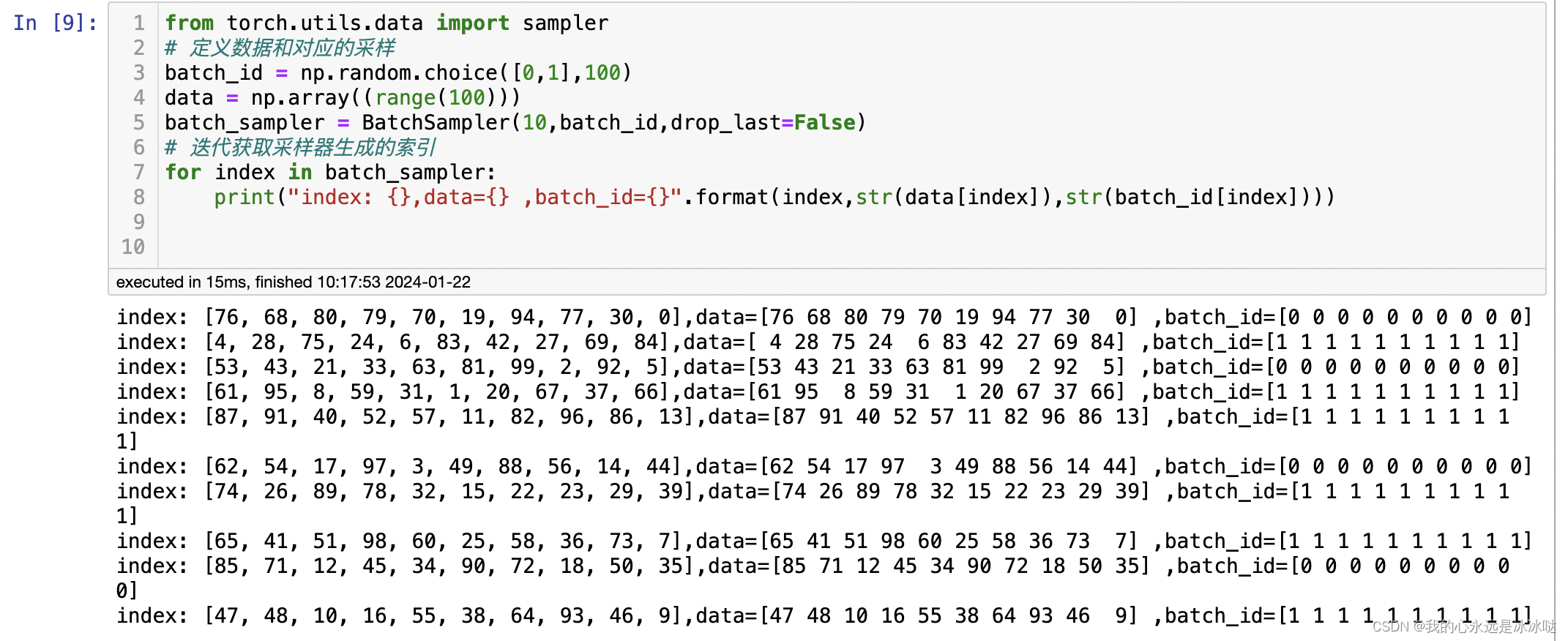
同样的我测试这个自定义的BatchSampler可以用同样的方式
from torch.utils.data import sampler
# 定义数据和对应的采样
batch_id = np.random.choice([0,1],100)
data = np.array((range(100)))
batch_sampler = BatchSampler(5,batch_id,drop_last=False)
# 迭代获取采样器生成的索引
for index in batch_sampler:print("index: {},data={} ,batch_id={}".format(index,str(data[index]),str(batch_id[index])))结果如下
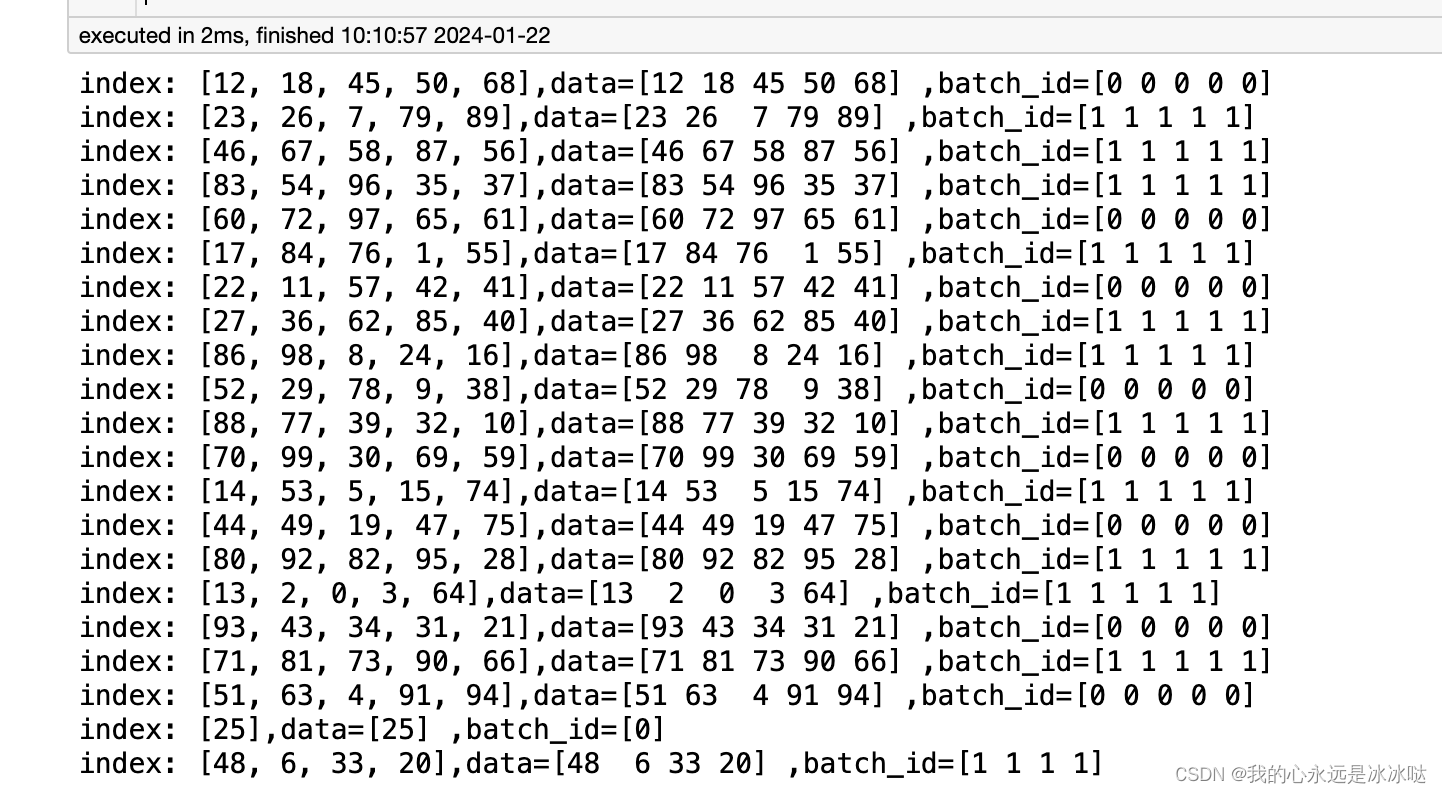
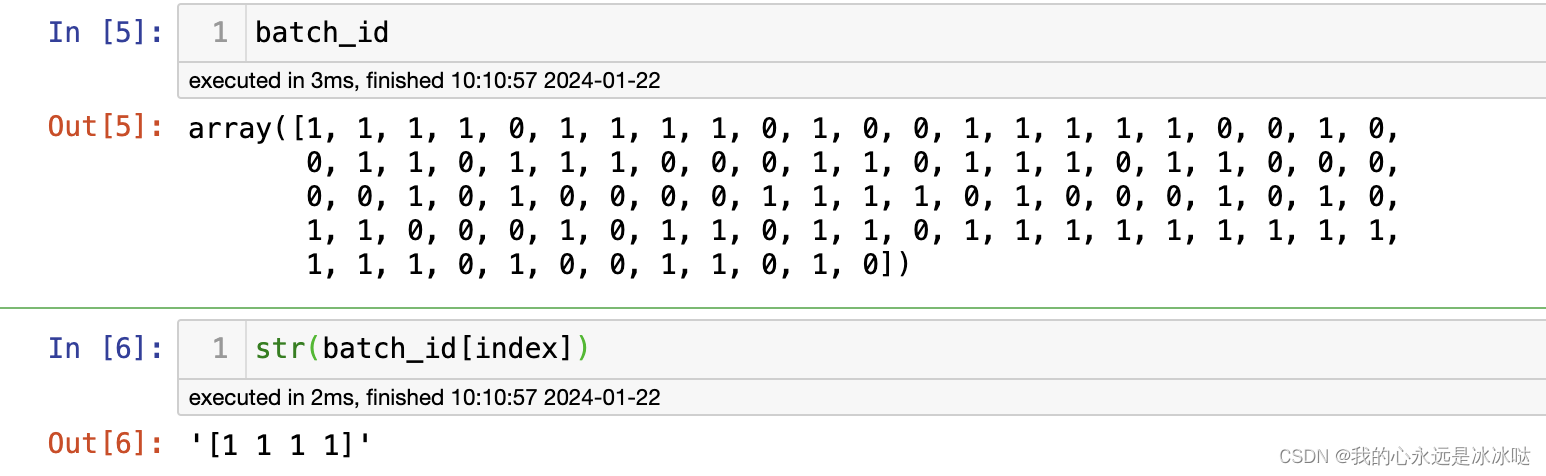 可以看到这个Batchsampler的作用就是每次抽样保证从同一个batch中抽,这个倒是我直接看代码看不出来的,我以为两个batch等量的抽呢,所以还是得测试,不然不懂
可以看到这个Batchsampler的作用就是每次抽样保证从同一个batch中抽,这个倒是我直接看代码看不出来的,我以为两个batch等量的抽呢,所以还是得测试,不然不懂