1.介绍
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
Swin-Unet:用于医学图像分割的类Unet纯Transformer
2022年发表在 Computer Vision – ECCV 2022 Workshops
Paper Code
2.摘要
在过去的几年里,卷积神经网络(CNN)在医学图像分析方面取得了里程碑式的成就。特别是基于U型结构和跳跃连接的深度神经网络,已经广泛应用于各种医学图像任务中。然而,尽管CNN取得了优异的性能,但由于卷积运算的局部性,它不能很好地学习全局和远程语义信息交互。在本文中,我们提出了Swin-Unet,这是一个Unet-like纯Transformer医学图像分割。标记化的图像块被馈送到基于变换器的U形编码器-解码器架构中,具有用于局部全局语义特征学习的跳过连接。具体来说,我们使用分层Swin Transformer与移位窗口作为编码器来提取上下文特征。并设计了一个基于对称Swin变换的解码器,该解码器具有补丁扩展层,用于执行上采样操作,以恢复特征图的空间分辨率。在对输入和输出进行4倍直接下采样和上采样的情况下,对多器官和心脏分割任务的实验表明,纯基于transformer的U形Encoder-Decoder网络的性能优于采用全卷积或transformer和卷积相结合的方法。代码和训练模型将在https://github.com/HuCaoFighting/Swin-Unet上公开。
Keywords:U-Net、Swin Transformer、多器官分割
3.Introduction
现有的医学图像分割方法主要依赖于具有U形结构的全卷积神经网络(FCNN)。典型的U形网络U-Net 由具有跳跃连接的对称编码器-解码器组成。在编码器中,使用一系列卷积层和连续下采样层来提取具有大感受野的深度特征。然后,解码器将提取的深度特征上采样到输入分辨率,进行像素级语义预测,并将来自编码器的不同尺度的高分辨率特征通过跳跃连接进行融合,以减轻下采样造成的空间信息丢失。凭借如此优雅的结构设计,U-Net在各种医学成像应用中取得了巨大的成功。遵循这一技术路线,已经开发了许多算法,如3D U-Net,Res-UNet,U-Net++和UNet 3 +,用于各种医学成像模式的图像和体积分割。这些基于模糊神经网络的方法在心脏分割、器官分割和病变分割中的出色表现证明了CNN具有很强的学习判别特征的能力。由于卷积运算的内在局部性,基于CNN的方法很难学习显式的全局和长距离语义信息交互。一些研究试图通过使用atrous卷积层,自我注意机制和图像金字塔来解决这个问题。然而,这些方法在建模远程依赖关系时仍然存在局限性。最近,受Transformer在自然语言处理(NLP)领域的巨大成功的启发,研究人员试图将Transformer引入视觉领域,出现视觉Transformer(ViT)来执行图像识别任务。以具有位置嵌入的2D图像块作为输入并在大型数据集上进行预训练,ViT实现了与基于CNN的方法相当的性能。此外,还有人提出了数据高效图像Transformer(DeiT),这表明Transformer可以在中等大小的数据集上训练,并且可以通过将其与蒸馏方法相结合来获得更鲁棒的Transformer。后续开发了分层Swin Transformer。以Swin Transformer作为视觉骨干,在图像分类、对象检测和语义分割方面实现了最先进的性能。ViT、DeiT和Swin Transformer在图像识别任务中的成功证明了Transformer在视觉领域的应用潜力。受Swin Transformer成功的启发,本文提出Swin-Unet来利用Transformer的功能,在这项工作中进行2D医学图像分割。Swin-Unet是第一个纯基于Transformer的U形架构,由编码器,瓶颈,解码器和跳过连接组成。编码器、瓶颈和解码器都是基于Swin Transformer块构建的。将输入的医学图像分割成不重叠的图像补丁块,每个补丁都被视为一个令牌,并被馈送到基于transformer的编码器中,以学习深度特征表示。提取的上下文特征由解码器通过补丁扩展层进行上采样,并通过跳过连接与来自编码器的多尺度特征融合,以恢复特征图的空间分辨率并进一步执行分割预测。在多器官和心脏分割数据集上的实验表明,该方法具有良好的分割精度和鲁棒的泛化能力。
具体而言,本文的工作可以概括为:(1)基于Swin Transformer模块,构建了一个具有跳跃连接的对称编解码器结构。在编码器中,实现了从局部到全局的自注意力;在解码器中,将全局特征上采样到输入分辨率,以进行相应的像素级分割预测。(2)在不使用卷积或插值操作的情况下,开发了一个补丁扩展层来实现上采样和特征维数的增加。(3)实验中发现跳跃连接对Transformer也有效,因此最终构造了一种基于transformer的U型跳跃连接编解码器结构Swin-Unet。
4.网络结构详解
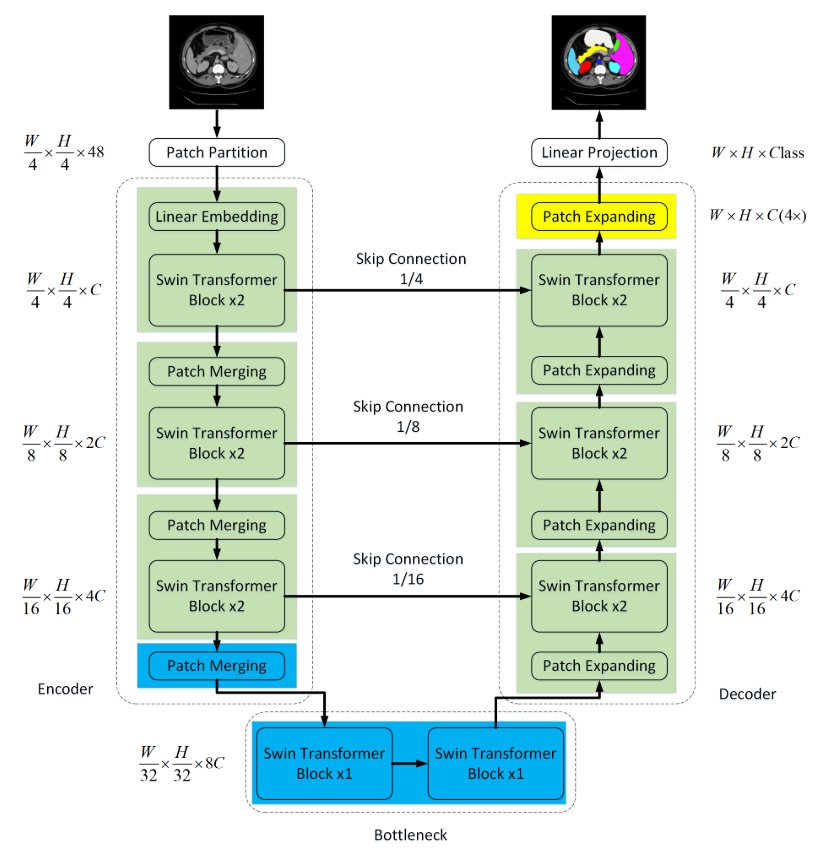
拟议的Swin-Unet的总体架构如图所示。Swin-Unet由编码器、瓶颈、解码器和跳跃连接组成。Swin-Unet的基本单元是Swin Transformer块。
对于编码器,首先为了将输入转换为序列嵌入,图像经过Patch partition被分割成具有4 × 4的块大小的非重叠块,这样每个块的特征维数变为4 × 4 × 3 = 48。此外,线性嵌入层Linear embedding被应用于将特征维度投影到任意维度(表示为C)。然后变换后的patch tokens(即图像补丁块)通过几个Swin Transformer块和补丁合并层patch merging来生成分层特征表示。其中,补丁合并层负责下采样和增加维度,Swin Transformer块负责特征表示学习。
受U-Net 的启发,本文是一个基于对称transformer的解码器。解码器由Swin Transformer模块和补丁扩展层patch expending组成。提取的上下文特征通过跳跃连接与来自编码器的多尺度特征融合,以补充由下采样引起的空间信息的损失。与补丁合并层相比,补丁扩展层被专门设计用于执行上采样。补丁扩展层将相邻维度的特征图重塑为具有2倍分辨率上采样的大特征图。最后,利用最后一个补丁扩展层进行4倍上采样,将特征图的分辨率恢复到输入分辨率(W×H),然后对这些上采样后的特征应用线性投影层,输出像素级分割预测。
Swin Transformer块
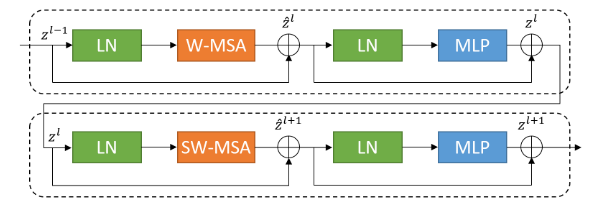
与传统的多头自注意(MSA)模块不同,Swin Transformer块是基于移位窗口构建的。在上图中给出了两个连续的swin Transformer块。每个Swin Transformer模块由LayerNorm(LN)层、多头自注意模块、残差连接和具有GELU非线性的2层MLP组成。基于窗口的多头自注意(W-MSA)模块和基于移位窗口的多头自注意(SW-MSA)模块分别应用于两个连续的Transformer块。基于这样的窗口划分机制,连续的swin Transformer块可以被公式化为:
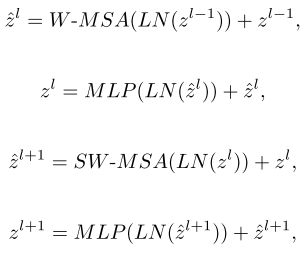
其中,zl分别表示第l个块的(S)W-MSA模块和MLP模块的输出。
自注意力的计算如下:
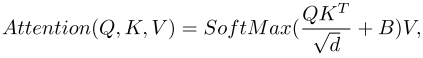
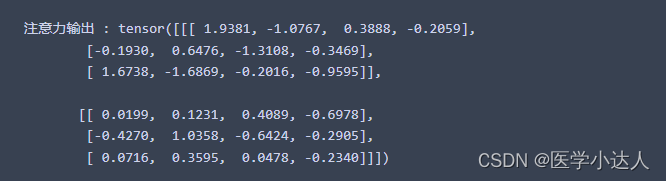
其中 Q , K , V ∈ R M 2 × d Q,K,V ∈ R^{M^2 ×d} Q,K,V∈RM2×d 表示查询、键和值。 M 2 M^2 M2和d分别表示窗口中补丁的数量以及查询或键的维度。并且,B中的值取自偏置矩阵 B ′ ∈ R ( 2 M − 1 ) × ( 2 M + 1 ) B' ∈ R^{(2 M −1)×(2 M +1)} B′∈R(2M−1)×(2M+1)。
编码器
在编码器中,将分辨率为H/4 ×W/4的C维标记化输入送入两个连续的Swin Transformer块进行表征学习,特征维数和分辨率保持不变。同时,补丁合并层将减少token的数量(2倍下采样),并将特征维度增加到原始维度的2倍。此过程将在编码器中重复三次。
Patch merging:输入patch被分为4部分,并通过Patch merging连接在一起。通过这种处理,特征分辨率将被下采样2倍。而且,由于连接操作导致特征维度增加4倍,因此在连接的特征上应用线性层以将特征维度统一到2倍原始维度。
Bottleneck 瓶颈
由于Transformer太深而无法收敛,因此仅使用两个连续的Swin Transformer块来构建瓶颈以学习深度特征表示。在瓶颈区域,特征尺寸和分辨率保持不变。(即在底端不改变尺寸与分辨率)
解码器
与编码器相对应,基于Swin Transformer模块构建了对称解码器。为此,与编码器中使用的补丁合并层相比,在解码器中使用补丁扩展层来对提取的深度特征进行上采样。补丁扩展层将相邻维度的特征图重塑为更高分辨率的特征图(2倍上采样),并相应地将特征维度减少到原始维度的一半。贴片展开层:以第一个面片扩展层为例,在上采样之前,在输入特征(W/32 × H/32 × 8C)上应用线性层,以将特征维度增加到原始维度(W/32 × H/32 × 16C)的2倍。然后,利用重排操作将输入特征的分辨率扩展到2×输入分辨率,将特征维数降低到输入维数的四分之一(W/32 × H/32 × 16C→ W/16 × H/16 × 4C)。
跳跃连接
与U-Net类似,跳跃连接用于将来自编码器的多尺度特征与上采样特征融合。将浅层特征和深层特征连接在一起,以减少由下采样引起的空间信息损失。接着是线性层,级联特征的维度保持与上采样特征的维度相同。
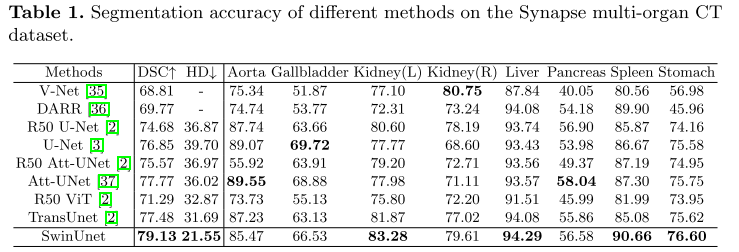
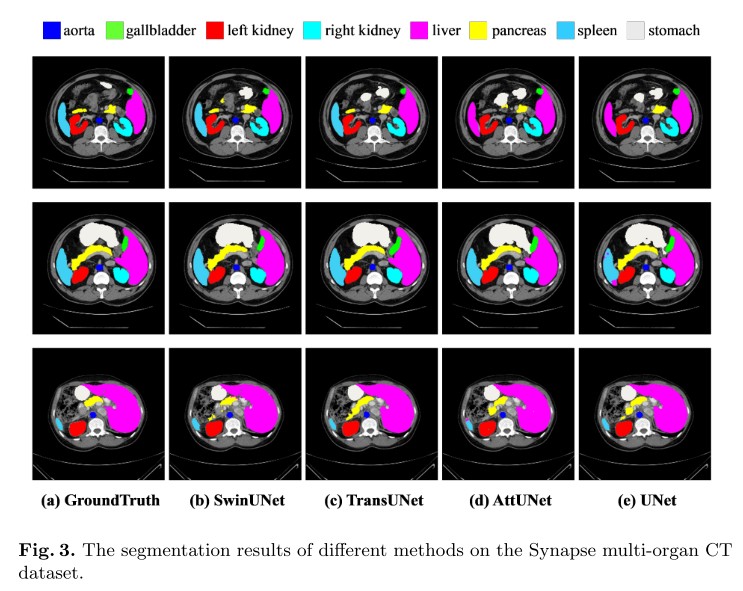
5.实验与结果
Swin-Unet基于Python 3.6和Pytorch 1.7.0实现。对于所有训练案例,使用翻转和旋转等数据增强来增加数据多样性。输入图像大小和补丁大小分别设置为224×224和4。在具有32 GB内存的Nvidia V100 GPU上训练模型。在ImageNet上预训练的权重用于初始化模型参数。在训练期间,批量大小为24,并且使用动量为0.9且权重衰减为1 e-4的流行SGD优化器来优化我们的反向传播模型。