ATC 2021 Paper 论文阅读笔记整理
问题
现代键值(KV)存储采用LSM树作为管理KV对的核心数据结构,但存在较高的写放大和读放大问题。现有的LSM树优化通常需要做出设计权衡,并无法同时在写入、读取和扫描方面实现高性能。
现有方法局限性
一个工作方向是放松LSM树的每个级别中的完全排序性质,从而减轻压缩开销[17,52,55]。然而,随着完全排序的程度放松,扫描性能也会下降。
另一个工作方向是基于KV分离,在LSM树中只保留密钥(按完全排序)并在专用存储区域中执行值管理[10,20,38,42,49,51,63]。然而,它会降低扫描性能,尤其是对于实践中常见的中小尺寸的值[5,9],因为每次扫描都需要向不再完全排序的密钥范围内的值发出随机I/O。此外,KV分离会产生额外的垃圾收集(GC)开销[10],从而触发LSM树中压缩之外的额外I/O开销。
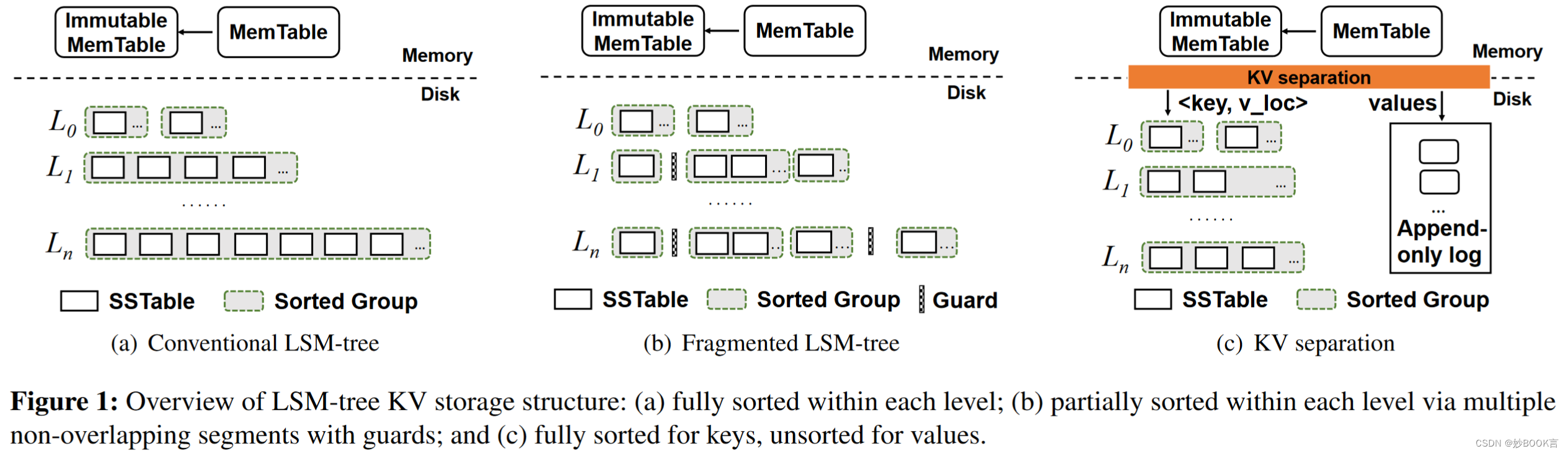
现有的LSM树优化仍然受到读、写和扫描之间的性能关系的限制,这取决于(i)键和值的排序程度,(ii)不同大小的KV对的管理。
本文方法
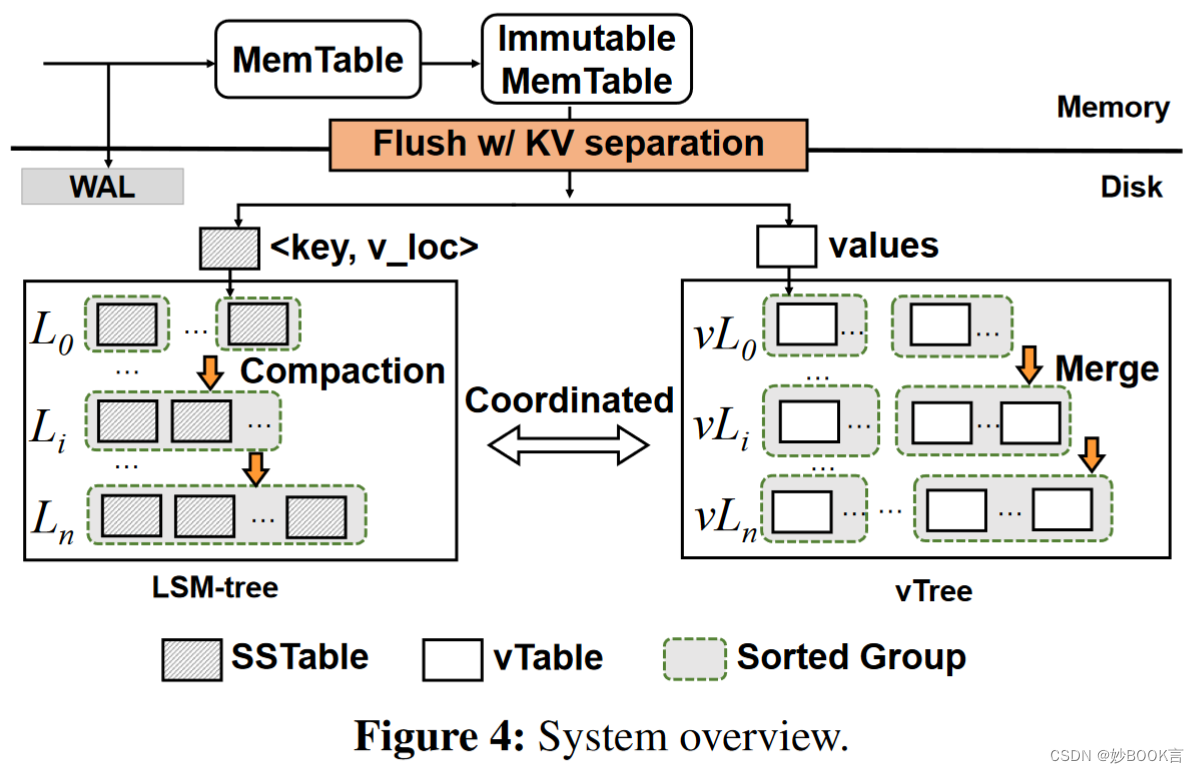
我们提出了DiffKV,基于KV分离,精心管理键和值的排序。DiffKV使用传统的LSM树管理键,在LSM树的每个级别内具有完全排序,同时以一种协调的方式管理值,使其相对于键的完全排序具有部分排序的顺序,以保持高扫描性能。通过状态感知的惰性GC方案来实现高空间效率和高性能。提出了细粒度的KV分离,区分小型、中型和大型KV对的管理,以实现在混合工作负载下平衡的性能。提出了热感知多日志设计,用于有效管理大型KV对。
开源代码:https://github.com/ustcadsl/diffkv
实验结果表明,DiffKV可以在所有方面同时实现最佳性能,超过了现有的LSM树优化的KV存储。
实验
实验环境:12核Intel Xeon E5-2650v4 CPU、16 GB内存、三星860 EVO 480 GB SSD。运行Ubuntu 18.04 LTS和Linux内核4.15。
数据集:用YCSB-C生成Facebook类似负载[9,48,54]
实验对比:吞吐量、尾延迟、空间使用量、范围搜索性能
总结
同时优化LSM-tree的读、写、范围查询性能。作者提出使用传统的LSM树管理键,在LSM树的每个级别内具有完全排序,同时以一种协调的方式管理值,使其相对于键的完全排序具有部分排序的顺序,以保持高扫描性能;通过状态感知的惰性GC方案来实现高空间效率和高性能;提出了细粒度的KV分离,区分小型、中型和大型KV对的管理,以实现混合工作负载下性能平衡;提出了热感知多日志设计,用于有效管理大型KV对。