前言
目前,大型模型在复杂故事可视化任务方面依然面临着重大挑战。这是因为此类任务需要对框架描述中的代词(例如He、她、他们、他们)进行解析,即在分辨率和确保跨帧的角色和背景融合方面进行详细解剖。尽管存在这些挑战,新兴的大语言模型(LLM)表现出强大的推理能力,能够通过模糊的参考和广泛的序列导航。
为了应对这些挑战,引入了一种被称为Storygpt-V的模型,它充分利用了隐扩散模型(LDM)和LLM的优势,以生成在给定故事描述下具有一致且高质量角色的图像。首先,通过训练角色吸引的LDM,该模型将角色增强的语义嵌入作为输入,并使用角色分割掩码监督跨意义地图,旨在提高角色生成的准确性和忠诚度。在第二阶段,通过对齐LLM的输出和位于第一阶段模型输入空间中的字符增强的嵌入,充分利用了LLM的解决模糊参考的推理能力以及记忆上下文的理解能力。
通过在两个视觉故事可视化基准上进行全面实验,该模型报告了较高的定量结果,并在产生具有出色质量的准确特征方面保持了一致性,同时内存消耗较低。
概述
图像生成算法在逼近达到人类水平的熟练程度方面取得了显著进展。然而,即使是强大的图像生成器在故事可视化任务中也面临挑战,其中涉及生成一系列保持语义连贯性的帧,以呈现通过多个句子在一系列帧中展开的对象交互的叙事。过去的研究在故事可视化领域有所探索,但没有充分考虑参考解析的问题。本研究旨在通过利用强大的文本到图像模型和大型语言模型来解决这些挑战,实现基于共指帧描述的故事可视化。为了提高角色生成的高度忠实性,我们改进了预训练的潜在扩散模型,并利用大型语言模型来解决模糊的参考问题。我们的方法通过以低内存消耗的方式将图像处理为LLM输入空间中的令牌序列,从而有效地保留上下文。
本文详细介绍了一种文本表示增强方法,该方法基于视觉特征和字符分割掩码,以及一种基于字符感知的LDM模型,用于生成更准确的角色。同时,模型还采用LLM模型,将文本和图像输入进行交错,以实现对先前上下文的隐式推理和生成视觉响应。该模型在故事可视化基准测试中展现了准确和连贯的角色和背景生成,同时能够以低内存消耗生成长篇故事。
实现步骤
最近,通过基于扩散模型的文本到图像方法在提升图像质量和增强多样性方面取得了显著进展。然而,现有的文本到图像方法主要侧重于对齐基于文本描述的个别生成图像,未考虑故事可视化任务中涉及多帧人物和场景一致性的重要方面。
在多模态大型语言模型方面,一些研究从LLM表示的隐藏嵌入中学到额外的视觉输出,将其映射到冻结的预训练文本到图像生成模型的输入空间。本研究采用了一种多模态LLM的方法,将交错的图像和参考文本描述作为输入,通过将输出与第一阶段Char-LDM的字符感知融合嵌入对齐,引导LLM进行隐式推导参考。
在故事可视化方面,StoryGAN提出了一种顺序条件生成网络框架,具有双重框架和故事级判别器,以提高图像质量和叙事连贯性。其他方法如DuCoStoryGAN、VLCStoryGAN和StoryDALL-E在利用视频字幕、改造交叉注意力层等方面进行了尝试,但它们未考虑文本描述中的歧义引用。相较之下,StoryLDM首次引入了参考解析,采用了带有记忆注意力模块的自回归扩散框架来解决歧义引用问题。然而,该方法在解析引用上存在困难,并且由于需要在像素空间中保留所有以前的上下文,具有较高的内存消耗。为了有效地保持上下文,本研究采用了强大的因果推理LLM进行参考解析,将视觉特征映射为LLM输入中的几个token嵌入。
实现方法
这篇文章介绍了一种双阶段方法,目的是将文本叙述转换为相应的视觉帧,从而生成准确且高质量的角色。首先,通过使用角色分割掩码监督,将文本表示与角色的视觉特征融合在一起,对Char-LDM进行优化,以实现高质量的角色生成。接着,充分利用LLM的推理能力,通过将LLM的输出与Char-LDM的输入空间对齐,解决了模糊引用问题,从而实现了时间上的一致性故事可视化。
在预备知识方面,文章提到了文本条件扩散模型中的交叉注意力。在扩散模型中,每个扩散步骤都包括通过u型网络以文本嵌入为条件,从噪声代码中预测噪声。U-Net中的交叉注意力层接受空间潜代码和文本嵌入作为输入,然后将它们投影为Q。在这一情境下,交叉注意力中的每个条目量化了从第k个文本标记到位置(i, j)的潜在像素的信息传播幅度。
此外,文章还介绍了具有注意力控制的字符感知LDM,以及在故事可视化中将视觉特征与文本条件相结合的方法。为了实现准确、高质量的角色描述,通过增加相应角色的视觉特征,增强了文本描述,并引导了文本条件的注意力更多地关注相应角色的合成。利用CLIP文本编码器和图像编码器获取文本嵌入向量和图像中出现字符的视觉特征,并通过连接token嵌入和相应字符的视觉特征,输入到MLP中,从而获得增强的文本嵌入。每个增广标记嵌入c中的形式如下所示:
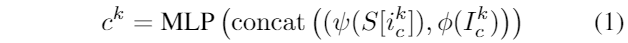
然后使用增强嵌入c作为第二阶段训练的监督。
控制文本标记的注意力。首先,我们获得对应字符的离线分割掩码作为监督信号。然后,我们鼓励为标记索引位置的每个字符绘制交叉注意力图,与二进制分割掩码对齐,公式如下:

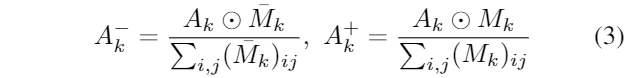
通过降低损失,增加对各自字符相关像素的注意力,同时减少对不相关区域的注意力,实现了对字符标记的更有效控制。此外,由于token嵌入丰富了对应字符的视觉特征,这种注意力控制不仅深化了增强的语义空间和潜在像素去噪之间的联系,还提高了合成字符的质量。
在第一阶段Char-LDM中,重点放在了基于单个标题的图像生成质量上。然而,在可视化一系列故事方面,仍然存在超越文本到图像生成器能力的挑战。首先,故事可视化要求角色和背景之间的一致性,这是第一阶段增强未覆盖的方面。此外,冗长描述中包含he、she或they等参考术语,对于LDM来说,实现准确推理是一项重大挑战。相比之下,LLM能够熟练地推断出歧义文本所指的预期字符。为了解决这个问题,本文利用了LLM强大的推理能力,以消除这类引用的歧义。
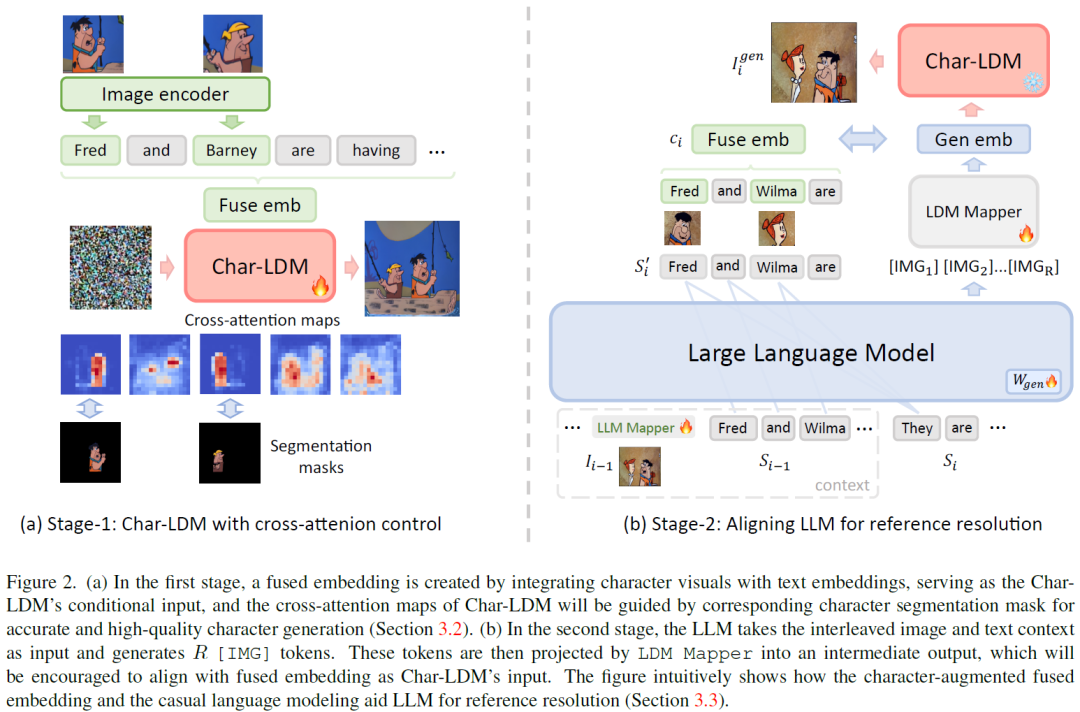
为了使LLM能够基于先验上下文自回归地生成图像并解决模糊的引用,该模型需要具备以下能力:1) 处理图像;2) 生成图像;3) 隐含地推断所指的主体。
为了实现这些目标,模型通过学习将视觉特征映射到LLM输入空间的线性映射来理解图像。它通过将隐藏状态与Char-LDM所需的条件输入对齐,生成图像,即第一阶段Char-LDM的文本与视觉编码器融合嵌入的编码。这通过将字符的视觉特征融入到文本嵌入中来实现。这种字符增强的嵌入,以及因果语言建模 (CLM),将引导LLM进行参考输入的隐式推断,并生成正确的字符,如图2 (b)所示。
LLM的输入由交错的共指文本描述和具有灵活帧长n的故事框架组成。首先,从视觉嵌入和剪辑视觉中枢中提取特征,同时使用可训练的学习Mapper矩阵。此外,为了表示视觉输出,添加了额外的 [IMG] 标记,并将可训练矩阵 W 合并到LLM中。训练目标是最小化以先前交叉的图像/文本标记为条件生成 [IMG] 标记的负对数似然:

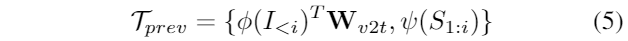
为了使LLM产生的[IMG]与LDM输入空间对齐,我们利用基于transformer的映射器LDM将[IMG]标记投影到具有可学习查询嵌入的第一阶段微调LDM的输入空间。训练目标是最小化Mapper的输出Gen Emb与LDM的增强条件文本表示之间的距离,表示为:
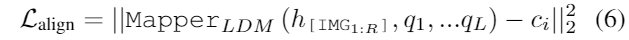
假设我们可以在没有引用标题编码的情况下访问原始嵌入文本。在这种情况下,使用增强模型的文本输入和每个视觉对象的编码器,生成了这种非参考文本,以增强字符的视觉特征,从而帮助LLM在语境中有效地消除歧义。
在推理过程中,该模型依次生成基于文本描述的故事可视化。首先处理初始帧的文本描述,专注于帧的生成,约束LLM仅生成特定的 [IMG] 标记。然后,将这些标记嵌入到第一阶段Char-LDM中,从而生成第一个帧。随后,LLM利用上下文历史,包括第一帧的文本描述、生成的第一帧以及第二帧的文本描述,作为输入。通过重复这个过程,逐步可视化整个故事。这种方法使得模型能够在不引用标题编码的情况下进行推理,而非参考文本的引入则有助于在生成过程中处理语境中的歧义。
测试代码
1.环境安装
# 创建并激活虚拟环境
conda env create -f environment.yaml
conda activate story# 安装外部包 LAVIS 用于文本-图像对齐评估
git clone https://github.com/salesforce/LAVIS.git
cd LAVIS
pip install -e .# 将 LAVIS 包中的 "lavis" 文件夹复制到 "eval" 文件夹中
cp -r lavis eval/lavis
2.数据下载
下载数据集并将放在 data/flintstone 和 data/pororo 下
FlintstonesSV:下载
PororoSV: 下载
3.训练
第一阶段:Char-LDM
# 使用脚本训练 Char-LDM
bash scripts/train_ldm.sh DATASET
在完成第一阶段训练后,执行以下步骤:
准备 CLIP 嵌入:
bash scripts/clip.sh DATASET CKPT_PATH
第二阶段:将 LLM 与 Char-LDM 对齐,您可以选择使用 OPT 或 Llama2:
bash scripts/train_llm.sh DATASET LLM_CKPT
这些脚本用于在两个训练阶段中训练模型。在第一阶段,使用train_ldm.sh脚本训练Char-LDM。然后,通过clip.sh脚本准备第一阶段后的 CLIP 嵌入。最后,在第二阶段,使用train_llm.sh脚本将 LLM 与 Char-LDM 对齐,可以选择使用 OPT 或 Llama2。
3.推理
# First Stage Evaluation
bash scripts/eval.sh DATASET 1st_CKPT_PATH# Second Stage Evaluation
bash scripts/eval_llm.sh DATASET 1st_CKPT_PATH 2nd_CKPT_PATH








![uniapp对接微信APP支付返回requestPayment:fail [payment微信:-1]General errors错误-全网总结详解](https://img-blog.csdnimg.cn/742bc7da3e274776bc2280299e3701aa.png)