准备工作
本笔记是假设您已经安装了Windows系统或Ubuntu系统的Anaconda(或 Miniconda)、Jupyter Notebook、TensorFLow,稍微了解Python语言,并可以进行一点点操作的基础上进行的。
如果您还不具备这个条件,去看我的政安晨笔记里关于准备工作的文章:
基于Anaconda安装TensorFlow并尝试一个神经网络小实例![]() https://blog.csdn.net/snowdenkeke/article/details/135841281示例讲解机器学习工具Jupyter Notebook入门(超级详细)
https://blog.csdn.net/snowdenkeke/article/details/135841281示例讲解机器学习工具Jupyter Notebook入门(超级详细)![]() https://blog.csdn.net/snowdenkeke/article/details/135880886实例讲解深度学习工具PyTorch在Ubuntu系统上的安装入门(基于Miniconda)(非常详细)
https://blog.csdn.net/snowdenkeke/article/details/135880886实例讲解深度学习工具PyTorch在Ubuntu系统上的安装入门(基于Miniconda)(非常详细)![]() https://blog.csdn.net/snowdenkeke/article/details/135887509
https://blog.csdn.net/snowdenkeke/article/details/135887509
基于Ubuntu系统的Miniconda安装Jupyter Notebook![]() https://blog.csdn.net/snowdenkeke/article/details/135919533
https://blog.csdn.net/snowdenkeke/article/details/135919533
基于Ubuntu系统的Miniconda安装TensorFlow并使用Jupyter Notebook在多个Conda虚拟环境下管理测试![]() https://blog.csdn.net/snowdenkeke/article/details/135905122
https://blog.csdn.net/snowdenkeke/article/details/135905122
当您准备好了之后,让咱们开始接下来有趣的旅程。
一、走一个机器学习里的“Hello World”
打开Jupyter Notebook,新建一个笔记文件:tf-hellloworld。
(虽然这个程序我在我另外的文章中示例过了,但它比较典型,可以着重使用一下)
将下述代码复制到笔记本的cell单元格中:
import tensorflow as tf
mnist = tf.keras.datasets.mnist(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10, activation='softmax')
])model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)如下图所示:
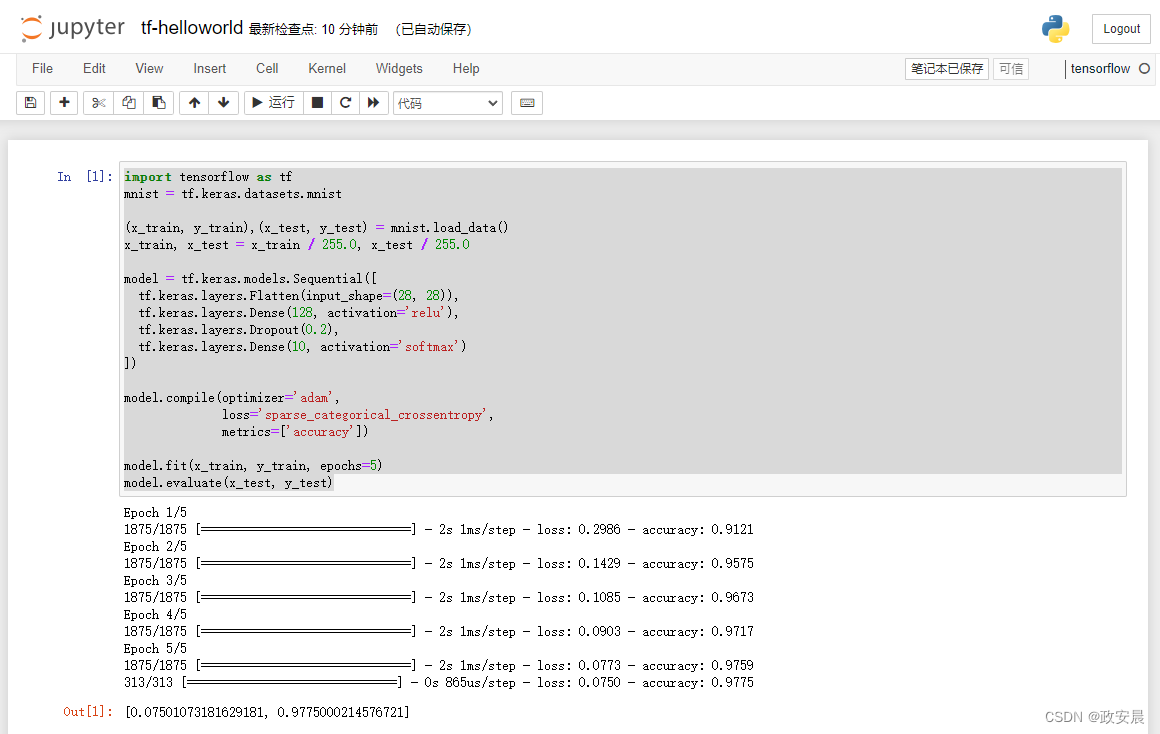
完成训练后,您也完成了这个Hello World,同时也证明您电脑中的TensorFlow是可用的,咱们就可以往下继续了。
二、再做一个简单的机器学习示例并说明一下
咱们新建一个文件(ExampleofKeras):
在笔记的单元格中输入如下代码:
import tensorflow as tfmnist = tf.keras.datasets.mnist(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10)
])predictions = model(x_train[:1]).numpy()
predictionstf.nn.softmax(predictions).numpy()loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)loss_fn(y_train[:1], predictions).numpy()model.compile(optimizer='adam',loss=loss_fn,metrics=['accuracy'])model.fit(x_train, y_train, epochs=5)model.evaluate(x_test, y_test, verbose=2)probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()
])probability_model(x_test[:5])
保存并执行一下:
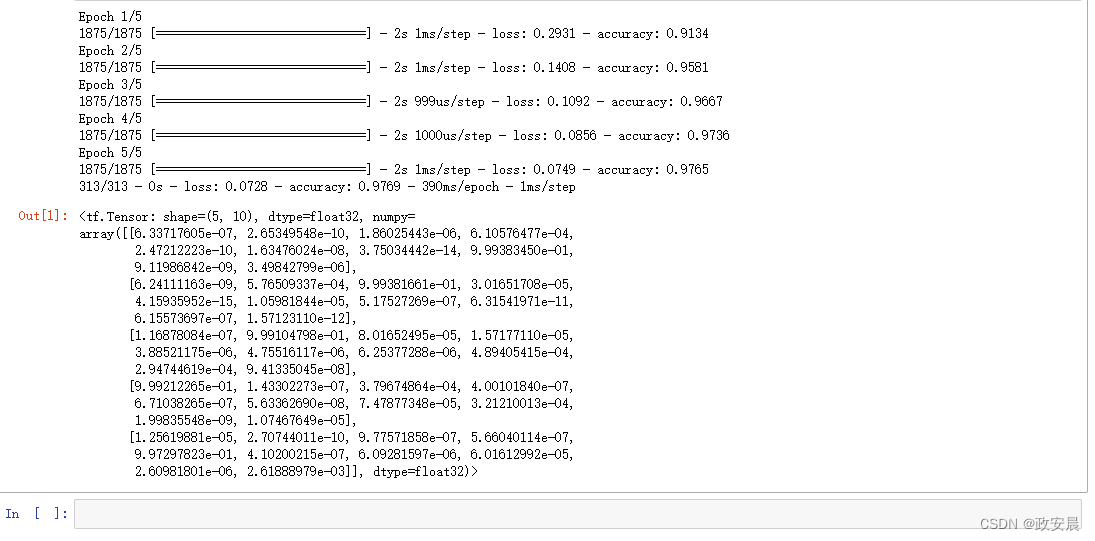
上面这个程序做了如下这么几件事:
- 加载一个预构建的数据集。
- 构建对图像进行分类的神经网络机器学习模型。
- 训练此神经网络。
- 评估模型的准确率。
接下来分步骤分析一下:
第一步:设置 TensorFlow
首先将 TensorFlow 导入到您的程序:
import tensorflow as tf第二步: 加载数据集
加载并准备MNIST数据集。将样本数据从整数转换为浮点数:
mnist = tf.keras.datasets.mnist(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0第三步:构建机器学习模型
通过堆叠层来构建tf.keras.Sequential模型。
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10)
])对于每个样本,模型都会返回一个包含logits或log-odds分数的向量,每个类一个。
predictions = model(x_train[:1]).numpy()
predictionslogits:
分类模型生成的原始(非规范化)预测向量,通常会将其传递给规范化函数。如果模型解决的是多类分类问题,对数通常会成为 softmax 函数的输入。然后,softmax 函数会生成一个(归一化)概率向量,每个可能的类别都有一个值。
log-odds:
某些事件发生的几率的对数。
tf.nn.softmax函数将这些 logits 转换为每个类的概率:
tf.nn.softmax(predictions).numpy()虽然还可以将tf.nn.softmax烘焙到网络最后一层的激活函数中。虽然这可以使模型输出更易解释,但不建议使用这种方式,因为在使用 softmax 输出时不可能为所有模型提供精确且数值稳定的损失计算。
使用SparseCategoricalCrossentropy为训练定义损失函数,它会接受 logits 向量和 True 索引,并为每个样本返回一个标量损失。
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)此损失等于 true 类的负对数概率:如果模型确定类正确,则损失为零。
这个未经训练的模型给出的概率接近随机(每个类为 1/10),因此初始损失应该接近 -tf.math.log(1/10) ~= 2.3。
loss_fn(y_train[:1], predictions).numpy()在开始训练之前,使用 Keras model.compile 配置和编译模型。将optimizer类设置为 adam,将 loss 设置为您之前定义的 loss_fn 函数,并通过将 metrics 参数设置为 accuracy 来指定要为模型评估的指标。
model.compile(optimizer='adam',loss=loss_fn,metrics=['accuracy'])第四步:训练并评估模型
使用model.fit方法调整您的模型参数并最小化损失
model.fit(x_train, y_train, epochs=5)方法通常在 "Validation-set" 或 "Test-set" 上检查模型性能。
model.evaluate(x_test, y_test, verbose=2)Validation-set 说明:
针对训练好的模型进行初始评估的数据集子集。通常情况下,在根据测试集评估模型之前,要根据验证集多次评估训练有素的模型。
传统上,数据集中的示例分为以下三个不同的子集:
训练集
验证集
测试集
理想情况下,数据集中的每个示例应只属于前面的一个子集。例如,一个例子不应同时属于训练集和验证集。
Test-set 说明:
数据集的子集,用于测试训练有素的模型。
传统上,我们将数据集中的示例分为以下三个不同的子集:
训练集
验证集
测试集
数据集中的每个示例只能属于前面的一个子集。例如,一个例子不应同时属于训练集和测试集。
训练集和验证集都与模型的训练密切相关。由于测试集仅与训练间接相关,因此测试损失是一个比训练损失或验证损失更少偏差、更高质量的指标。
现在,这个照片分类器的准确度已经达到 98%。
如果您想让模型返回概率,可以封装经过训练的模型,并将 softmax 附加到该模型:
probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()
])probability_model(x_test[:5])结论
恭喜小伙伴!您已经利用Keras API 基于预构建数据集成功训练了一个机器学习模型。这是全新的开始,是您在机器学习领域深入探索的第一步。这是全新的领域,充满挑战,但同时,也充满着机会。





![[Vue3] useRoute、useRouter](https://img-blog.csdnimg.cn/direct/7df1ed7e6b9c4818a27d60e5f09e4a97.png)