一、需求背景
对于博客或者文章来说,摘要是普遍性的需求。但是我们不可能让作者自己手动填写摘要或者直接暴力截取文章的部分段落作为摘要,这样既不符合逻辑又不具有代表性,那么,是否有相关的算法或者数学理论能够完成这个需求呢?我想,MMR(Maximal Marginal Relevance)是处理文章自动摘要的杰出代表。
二、最大边界相关算法—MMR
MMR算法又叫最大边界相关算法,此算法在设计之初是用来计算Query文本与被搜索文档之间的相似度,然后对文档进行rank排序的算法。算法公式如下:

仔细观察下公式方括号中的两项,其中前一项的物理意义指的是待抽取句子和整篇文档的相似程度,后一项指的是待抽取句子和已得摘要的相似程度,通过减号相连,其含义是希望:抽取的摘要既能表达整个文档的含义,有具备多样性 。而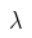 则是控制摘要多样性程度的一个超参数,你可以根据自己的需求去调节。
则是控制摘要多样性程度的一个超参数,你可以根据自己的需求去调节。
三、使用MMR算法实现文章自动摘要
3.1 具体算法实现
具体的代码实现如下:
import com.microblog.util.tools.FileUtils;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.util.*;
import java.util.Map.Entry;
import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** 文本摘要提取文中重要的关键句子,使用top-n关键词在句子中的比例关系**/
public class SummaryUtil {//保留关键词数量int N = 50;//关键词间的距离阀值int CLUSTER_THRESHOLD = 5;//前top-n句子int TOP_SENTENCES = 20;//最大边缘相关阀值double λ = 0.4;//停用词列表private static final Set<String> stopWords = new HashSet<>();//句子编号及分词列表Map<Integer, List<String>> sentSegmentWords = null;/*** 加载停词(文章摘要的停顿/分割词)*/public static void initStopWords(String[] paths) {for (String path : paths) {try {File file = new FileUtils().readFileFromNet(path);InputStreamReader read = new InputStreamReader(Files.newInputStream(file.toPath()), StandardCharsets.UTF_8);if (file.isFile() && file.exists()) {BufferedReader br = new BufferedReader(read);String txt = null;while ((txt = br.readLine()) != null) {stopWords.add(txt);}br.close();}}catch (IOException e) {e.printStackTrace();}}}/*** 利用正则将文本拆分成句子*/private List<String> SplitSentences(String text) {List<String> sentences = new ArrayList<String>();String regEx = "[!?。!?.]";Pattern p = Pattern.compile(regEx);String[] sents = p.split(text);Matcher m = p.matcher(text);int sentsLen = sents.length;if (sentsLen > 0) { //把每个句子的末尾标点符号加上int index = 0;while (index < sentsLen) {if (m.find()) {sents[index] += m.group();}index++;}}for (String sentence : sents) {//处理掉的html的标志sentence = sentence.replaceAll("(”|“|—|‘|’|·|"|↓|•)", "");sentences.add(sentence.trim());}return sentences;}/*** 这里使用IK进行分词* @param text 待处理句子* @return 句子分词列表*/private List<String> IKSegment(String text) {List<String> wordList = new ArrayList<String>();Reader reader = new StringReader(text);IKSegmenter ik = new IKSegmenter(reader, true);Lexeme lex = null;try {while ((lex = ik.next()) != null) {String word = lex.getLexemeText();if (word.equals(" ") || stopWords.contains(word) || "\t".equals(word)) continue;if (word.length() > 1 ) wordList.add(word);}}catch (IOException e) {e.printStackTrace();}return wordList;}/*** 每个句子得分 (keywordsLen*keywordsLen/totalWordsLen)** @param sentences 分句* @param topnWords keywords top-n关键词*/private Map<Integer, Double> scoreSentences(List<String> sentences, List<String> topnWords) {Map<Integer, Double> scoresMap = new LinkedHashMap<Integer, Double>();//句子编号,得分sentSegmentWords = new HashMap<>();int sentence_idx = -1;//句子编号for (String sentence : sentences) {sentence_idx += 1;List<String> words = this.IKSegment(sentence);//对每个句子分词sentSegmentWords.put(sentence_idx, words);List<Integer> word_idx = new ArrayList<Integer>();//每个关词键在本句子中的位置for (String word : topnWords) {if (words.contains(word)) {word_idx.add(words.indexOf(word));}}if (word_idx.size() == 0) continue;Collections.sort(word_idx);//对于两个连续的单词,利用单词位置索引,通过距离阀值计算一个族List<List<Integer>> clusters = new ArrayList<List<Integer>>();//根据本句中的关键词的距离存放多个词族List<Integer> cluster = new ArrayList<Integer>();cluster.add(word_idx.get(0));int i = 1;while (i < word_idx.size()) {if ((word_idx.get(i) - word_idx.get(i - 1)) < this.CLUSTER_THRESHOLD) {cluster.add(word_idx.get(i));} else {clusters.add(cluster);cluster = new ArrayList<>();cluster.add(word_idx.get(i));}i += 1;}clusters.add(cluster);//对每个词族打分,选择最高得分作为本句的得分double max_cluster_score = 0.0;for (List<Integer> clu : clusters) {int keywordsLen = clu.size();//关键词个数int totalWordsLen = clu.get(keywordsLen - 1) - clu.get(0) + 1;//总的词数double score = 1.0 * keywordsLen * keywordsLen / totalWordsLen;if (score > max_cluster_score) max_cluster_score = score;}scoresMap.put(sentence_idx, max_cluster_score);}return scoresMap;}/*** 利用最大边缘相关自动文摘*/public String SummaryMMRNTxt(String text) {//将文本拆分成句子列表List<String> sentencesList = this.SplitSentences(text);//利用IK分词组件将文本分词,返回分词列表List<String> words = this.IKSegment(text);//统计分词频率Map<String, Integer> wordsMap = new HashMap<>();for (String word : words) {Integer val = wordsMap.get(word);wordsMap.put(word, val == null ? 1 : val + 1);}//使用优先队列自动排序Queue<Entry<String, Integer>> wordsQueue = new PriorityQueue<>(wordsMap.size(), (o1, o2) -> o2.getValue() - o1.getValue());wordsQueue.addAll(wordsMap.entrySet());if (N > wordsMap.size()) {N = wordsQueue.size();}//取前N个频次最高的词存在wordsListList<String> wordsList = new ArrayList<>(N);//top-n关键词for (int i = 0; i < N; i++) {Optional.ofNullable(wordsQueue.poll()).ifPresent(entry -> {wordsList.add(entry.getKey());});}//利用频次关键字,给句子打分,并对打分后句子列表依据得分大小降序排序Map<Integer, Double> scoresLinkedMap = scoreSentences(sentencesList, wordsList);//返回的得分,从第一句开始,句子编号的自然顺序List<Entry<Integer, Double>> sortedSentList = new ArrayList<>(scoresLinkedMap.entrySet());//按得分从高到底排序好的句子,句子编号与得分sortedSentList.sort((o1, o2) -> o2.getValue().compareTo(o1.getValue()));if (sentencesList.size() == 2) {return sentencesList.get(0) + sentencesList.get(1);} else if (sentencesList.size() == 1) {return sentencesList.get(0);}Map<Integer, String> keySentence = new TreeMap<Integer, String>();dealWithCommentWithMMR(sentencesList, sortedSentList, keySentence);StringBuilder sb = new StringBuilder();for (int index : keySentence.keySet())sb.append(keySentence.get(index));return sb.toString();}/*** 使用MMR算法处理句子** @param sentencesList 句子列表* @param sortedSentList 排好序的句子(句子编号及其得分)* @param keySentence 处理结果*/private void dealWithCommentWithMMR(List<String> sentencesList, List<Entry<Integer, Double>> sortedSentList, Map<Integer, String> keySentence) {int count = 0;Map<Integer, Double> MMR_SentScore = MMR(sortedSentList);for (Entry<Integer, Double> entry : MMR_SentScore.entrySet()) {count++;int sentIndex = entry.getKey();String sentence = sentencesList.get(sentIndex);keySentence.put(sentIndex, sentence);if (count == this.TOP_SENTENCES) break;}}/*** 最大边缘相关(Maximal Marginal Relevance),根据λ调节准确性和多样性* max[λ*score(i) - (1-λ)*max[similarity(i,j)]]:score(i)句子的得分,similarity(i,j)句子i与j的相似度* User-tunable diversity through λ parameter* - High λ= Higher accuracy* - Low λ= Higher diversity** @param sortedSentList 排好序的句子,编号及得分*/private Map<Integer, Double> MMR(List<Entry<Integer, Double>> sortedSentList) {double[][] simSentArray = sentJSimilarity();//所有句子的相似度Map<Integer, Double> sortedLinkedSent = new LinkedHashMap<>();for (Entry<Integer, Double> entry : sortedSentList) {sortedLinkedSent.put(entry.getKey(), entry.getValue());}Map<Integer, Double> MMR_SentScore = new LinkedHashMap<>();//最终的得分(句子编号与得分)Entry<Integer, Double> Entry = sortedSentList.get(0);//第一步先将最高分的句子加入MMR_SentScore.put(Entry.getKey(), Entry.getValue());boolean flag = true;while (flag) {int index = 0;double maxScore = Double.NEGATIVE_INFINITY;//通过迭代计算获得最高分句子for (Map.Entry<Integer, Double> entry : sortedLinkedSent.entrySet()) {if (MMR_SentScore.containsKey(entry.getKey())) continue;double simSentence = 0.0;for (Map.Entry<Integer, Double> MMREntry : MMR_SentScore.entrySet()) {//这个是获得最相似的那个句子的最大相似值double simSen = 0.0;if (entry.getKey() > MMREntry.getKey()) simSen = simSentArray[MMREntry.getKey()][entry.getKey()];else simSen = simSentArray[entry.getKey()][MMREntry.getKey()];if (simSen > simSentence) {simSentence = simSen;}}simSentence = λ * entry.getValue() - (1 - λ) * simSentence;if (simSentence > maxScore) {maxScore = simSentence;index = entry.getKey();//句子编号}}MMR_SentScore.put(index, maxScore);if (MMR_SentScore.size() == sortedLinkedSent.size()) flag = false;}return MMR_SentScore;}/*** 每个句子的相似度,这里使用简单的jaccard方法,计算所有句子的两两相似度*/private double[][] sentJSimilarity() {//System.out.println("sentJSimilarity in...");int size = sentSegmentWords.size();double[][] simSent = new double[size][size];for (Entry<Integer, List<String>> entry : sentSegmentWords.entrySet()) {for (Entry<Integer, List<String>> entry1 : sentSegmentWords.entrySet()) {if (entry.getKey() >= entry1.getKey()) continue;int commonWords = 0;double sim = 0.0;for (String entryStr : entry.getValue()) {if (entry1.getValue().contains(entryStr)) commonWords++;}sim = 1.0 * commonWords / (entry.getValue().size() + entry1.getValue().size() - commonWords);simSent[entry.getKey()][entry1.getKey()] = sim;}}return simSent;}
}
3.2 文件读取工具
public class FileUtils {/*** 从网络地址读取文件** @param path 网络地址* @return 读取后的文件*/public File readFileFromNet(String path) throws IOException {File temporary = File.createTempFile("SensitiveWord", ".txt");URL url = new URL(path);InputStream inputStream = url.openStream();FileUtils.copyInputStreamToFile(inputStream, temporary);return temporary;}private static void copyInputStreamToFile(InputStream inputStream, File file) throws IOException {try (FileOutputStream outputStream = new FileOutputStream(file)) {int read;byte[] bytes = new byte[1024];while ((read = inputStream.read(bytes)) != -1) {outputStream.write(bytes, 0, read);}}}}
3.3 相关依赖
<dependency><groupId>com.github.magese</groupId><artifactId>ik-analyzer</artifactId><version>8.5.0</version>
</dependency>
3.4 调用算法,生成自动摘要
public static void main(String[] args) {SummaryUtil summary = new SummaryUtil();//停顿词我们一般放在OSS服务器上,而不是放在系统文件里面,方便灵活更换String[] paths = {"www.xxx.com/xxxxx(停顿词资源路径1)","www.xxx.com/xxxxx(停顿词资源路径2)"};//初始化停顿词initStopWords(paths);String text = "我国古代历史演义小说的代表作。明代小说家罗贯中依据有关三国的历史、杂记,在广泛吸取民间传说和民间艺人创作成果的基础上,加工、再创作了这部长篇章回小说。" +"作品写的是汉末到晋初这一历史时期魏、蜀、吴三个封建统治集团间政治、军事、外交等各方面的复杂斗争。通过这些描写,揭露了社会的黑暗与腐朽,谴责了统治阶级的残暴与奸诈," +"反映了人民在动乱时代的苦难和明君仁政的愿望。小说也反映了作者对农民起义的偏见,以及因果报应和宿命论等思想。战争描写是《三国演义》突出的艺术成就。这部小说通过惊心动魄的军事、政治斗争,运用夸张、对比、烘托、渲染等艺术手法,成功地塑造了诸葛亮、曹操、关羽、张飞等一批鲜明、生动的人物形象。《三国演义》结构宏伟而又严密精巧,语言简洁、明快、生动。有的评论认为这部作品在艺术上的不足之处是人物性格缺乏发展变化,有的人物渲染夸张过分导致失真。《三国演义》标志着历史演义小说的辉煌成就。在传播政治、军事斗争经验、推动历史演义创作的繁荣等方面都起过积极作用。《三国演义》的版本主要有明嘉靖刻本《三国志通俗演义》和清毛宗岗增删评点的《三国志演义》";String mmrSentences = summary.SummaryMMRNTxt(text);System.out.println("MMR算法获取到的摘要: " + mmrSentences);}

![WebAssembly核心编程[1]:wasm模块实例化的N种方式](https://img-blog.csdnimg.cn/img_convert/43a2802e9d0fd08c6e4ebf1e472906e7.png)