简言
parseChildren函数是在baseParse函数中作为createRoot函数的子节点参数传入的,今天来探索下parseChildren函数。
parseChildren在 compiler-core/src/parse.ts文件内。
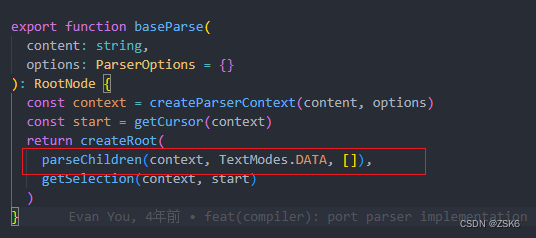
parseChildren
这个函数就是用来解析模板字符串内容的 ,里面有个while循环以栈的形式不断读取模板字符串进行解析,直到解析完毕,然后进行空白处理并返回对应的节点数据。
传参:
- context ---- 解析上下文(createParserContext函数根据模板字符串和配置得到的)。
- mode ---- 文本模式 。vue将模板字符串分为5个类型(见下面:DATA代表普通的元素标签,RCDATA代表textarea标签,RAWTEXT代表文本)。
- ancestors — 祖先节点,类型为元素节点数组。
文本模式:
export const enum TextModes {// | Elements | Entities | End sign | Inside ofDATA, // | ✔ | ✔ | End tags of ancestors |RCDATA, // | ✘ | ✔ | End tag of the parent | <textarea>RAWTEXT, // | ✘ | ✘ | End tag of the parent | <style>,<script>CDATA,ATTRIBUTE_VALUE
}
源码
function parseChildren(context: ParserContext,mode: TextModes,ancestors: ElementNode[]
): TemplateChildNode[] {const parent = last(ancestors)const ns = parent ? parent.ns : Namespaces.HTMLconst nodes: TemplateChildNode[] = []while (!isEnd(context, mode, ancestors)) {__TEST__ && assert(context.source.length > 0)const s = context.sourcelet node: TemplateChildNode | TemplateChildNode[] | undefined = undefinedif (mode === TextModes.DATA || mode === TextModes.RCDATA) {if (!context.inVPre && startsWith(s, context.options.delimiters[0])) {// '{{'node = parseInterpolation(context, mode)} else if (mode === TextModes.DATA && s[0] === '<') {// https://html.spec.whatwg.org/multipage/parsing.html#tag-open-stateif (s.length === 1) {emitError(context, ErrorCodes.EOF_BEFORE_TAG_NAME, 1)} else if (s[1] === '!') {// https://html.spec.whatwg.org/multipage/parsing.html#markup-declaration-open-stateif (startsWith(s, '<!--')) {node = parseComment(context)} else if (startsWith(s, '<!DOCTYPE')) {// Ignore DOCTYPE by a limitation.node = parseBogusComment(context)} else if (startsWith(s, '<![CDATA[')) {if (ns !== Namespaces.HTML) {node = parseCDATA(context, ancestors)} else {emitError(context, ErrorCodes.CDATA_IN_HTML_CONTENT)node = parseBogusComment(context)}} else {emitError(context, ErrorCodes.INCORRECTLY_OPENED_COMMENT)node = parseBogusComment(context)}} else if (s[1] === '/') {// https://html.spec.whatwg.org/multipage/parsing.html#end-tag-open-stateif (s.length === 2) {emitError(context, ErrorCodes.EOF_BEFORE_TAG_NAME, 2)} else if (s[2] === '>') {emitError(context, ErrorCodes.MISSING_END_TAG_NAME, 2)advanceBy(context, 3)continue} else if (/[a-z]/i.test(s[2])) {emitError(context, ErrorCodes.X_INVALID_END_TAG)parseTag(context, TagType.End, parent)continue} else {emitError(context,ErrorCodes.INVALID_FIRST_CHARACTER_OF_TAG_NAME,2)node = parseBogusComment(context)}} else if (/[a-z]/i.test(s[1])) {node = parseElement(context, ancestors)// 2.x <template> with no directive compatif (__COMPAT__ &&isCompatEnabled(CompilerDeprecationTypes.COMPILER_NATIVE_TEMPLATE,context) &&node &&node.tag === 'template' &&!node.props.some(p =>p.type === NodeTypes.DIRECTIVE &&isSpecialTemplateDirective(p.name))) {__DEV__ &&warnDeprecation(CompilerDeprecationTypes.COMPILER_NATIVE_TEMPLATE,context,node.loc)node = node.children}} else if (s[1] === '?') {emitError(context,ErrorCodes.UNEXPECTED_QUESTION_MARK_INSTEAD_OF_TAG_NAME,1)node = parseBogusComment(context)} else {emitError(context, ErrorCodes.INVALID_FIRST_CHARACTER_OF_TAG_NAME, 1)}}}if (!node) {node = parseText(context, mode)}if (isArray(node)) {for (let i = 0; i < node.length; i++) {pushNode(nodes, node[i])}} else {pushNode(nodes, node)}}// Whitespace handling strategy like v2let removedWhitespace = falseif (mode !== TextModes.RAWTEXT && mode !== TextModes.RCDATA) {const shouldCondense = context.options.whitespace !== 'preserve'for (let i = 0; i < nodes.length; i++) {const node = nodes[i]if (node.type === NodeTypes.TEXT) {if (!context.inPre) {if (!/[^\t\r\n\f ]/.test(node.content)) {const prev = nodes[i - 1]const next = nodes[i + 1]// Remove if:// - the whitespace is the first or last node, or:// - (condense mode) the whitespace is between twos comments, or:// - (condense mode) the whitespace is between comment and element, or:// - (condense mode) the whitespace is between two elements AND contains newlineif (!prev ||!next ||(shouldCondense &&((prev.type === NodeTypes.COMMENT &&next.type === NodeTypes.COMMENT) ||(prev.type === NodeTypes.COMMENT &&next.type === NodeTypes.ELEMENT) ||(prev.type === NodeTypes.ELEMENT &&next.type === NodeTypes.COMMENT) ||(prev.type === NodeTypes.ELEMENT &&next.type === NodeTypes.ELEMENT &&/[\r\n]/.test(node.content))))) {removedWhitespace = truenodes[i] = null as any} else {// Otherwise, the whitespace is condensed into a single spacenode.content = ' '}} else if (shouldCondense) {// in condense mode, consecutive whitespaces in text are condensed// down to a single space.node.content = node.content.replace(/[\t\r\n\f ]+/g, ' ')}} else {// #6410 normalize windows newlines in <pre>:// in SSR, browsers normalize server-rendered \r\n into a single \n// in the DOMnode.content = node.content.replace(/\r\n/g, '\n')}}// Remove comment nodes if desired by configuration.else if (node.type === NodeTypes.COMMENT && !context.options.comments) {removedWhitespace = truenodes[i] = null as any}}if (context.inPre && parent && context.options.isPreTag(parent.tag)) {// remove leading newline per html spec// https://html.spec.whatwg.org/multipage/grouping-content.html#the-pre-elementconst first = nodes[0]if (first && first.type === NodeTypes.TEXT) {first.content = first.content.replace(/^\r?\n/, '')}}}return removedWhitespace ? nodes.filter(Boolean) : nodes
}下面的流程只描述大致的流程信息,若有误请联系作者改正。
流程:
- 创建nodes数组用来承载解析的数据,进入while循环。
- 执行isEnd函数判断是否读取完毕,是则跳出while循环。
- 创建node用于承载此次循环解析的数据,并获取当前读取的内容。
- TextModes.DATA和TextModes.RCDATA下进行特定的分类解析。
- 若是是否是以{{开头,parseInterpolation函数进行文本插值解析。
- 若是TextModes.DATA下且以<开头,进行标签解析,进入标签类型的解析。
- 若以<开头且下一个字符是!,说明是注释标签、文档声明标签、<![CDATA[]]>标签(忽略xml的转义);分别进行对应的解析。
- 若以<开头且下一个字符是/,有可能是闭合标签,则进行parseTag函数标签解析。
- 若以<开头且下一个字符是a-z任意字符(不分大小写),进行parseElement函数解析。
- 若node还没值,执行parseText函数按文本进行解析。
- 将node的值添加到nodes中,执行第2步
- 将nodes值按照配置的空白策略进行空白处理
- 返回nodes。
使用到的一些函数
只挑选用到的一些函数进行分析。
isEnd
判断是否读取完毕。
参考:
- startsWith函数是 以什么开头。
- startsWithEndTagOpen 是否是完整的相匹配的闭合标签。
true的情况: - TextModes.DATA下以</开头且是匹配的闭合标签,返回true
- TextModes.RCDATA(textarea)和TextModes.RAWTEXT(文本)下,存在父节点,且匹配父节点的闭合标签,返回true。
- TextModes.CDATA(xml中的忽略转义的写法)下,以]]>开头,返回true。
- s 为假值,返回true
function isEnd(context: ParserContext,mode: TextModes,ancestors: ElementNode[]
): boolean {const s = context.sourceswitch (mode) {case TextModes.DATA:if (startsWith(s, '</')) {// TODO: probably bad performancefor (let i = ancestors.length - 1; i >= 0; --i) {if (startsWithEndTagOpen(s, ancestors[i].tag)) {return true}}}breakcase TextModes.RCDATA:case TextModes.RAWTEXT: {const parent = last(ancestors)if (parent && startsWithEndTagOpen(s, parent.tag)) {return true}break}case TextModes.CDATA:if (startsWith(s, ']]>')) {return true}break}return !s
}
parseInterpolation
解析文本插值内容,也就是{{表达式}}这种,最后返回文本插值类型的结构数据节点。
参考:
- parseTextData ---- 处理 {{表达式}}内的表达式。
- getCursor — 获取当前读取位置
- advanceBy — 改变上下文中的source
- advancePositionWithMutation ---- 修正读取位置信息描述的函数。
文本插值大家都知道,它是vue的数据在模板显示的主要方式之一,里面可以填表达式或者静态字符串,所以{{}}里面的内容使用parseTextData函数解析,这个函数要返回文本字符串,要么返回一个解析好后的html实体。
function parseInterpolation(context: ParserContext,mode: TextModes
): InterpolationNode | undefined {const [open, close] = context.options.delimiters__TEST__ && assert(startsWith(context.source, open))const closeIndex = context.source.indexOf(close, open.length)if (closeIndex === -1) {emitError(context, ErrorCodes.X_MISSING_INTERPOLATION_END)return undefined}const start = getCursor(context)advanceBy(context, open.length)const innerStart = getCursor(context)const innerEnd = getCursor(context)const rawContentLength = closeIndex - open.lengthconst rawContent = context.source.slice(0, rawContentLength)const preTrimContent = parseTextData(context, rawContentLength, mode)const content = preTrimContent.trim()const startOffset = preTrimContent.indexOf(content)if (startOffset > 0) {advancePositionWithMutation(innerStart, rawContent, startOffset)}const endOffset =rawContentLength - (preTrimContent.length - content.length - startOffset)advancePositionWithMutation(innerEnd, rawContent, endOffset)advanceBy(context, close.length)return {type: NodeTypes.INTERPOLATION,content: {type: NodeTypes.SIMPLE_EXPRESSION,isStatic: false,// Set `isConstant` to false by default and will decide in transformExpressionconstType: ConstantTypes.NOT_CONSTANT,content,loc: getSelection(context, innerStart, innerEnd)},loc: getSelection(context, start)}
}
parseComment
解析注释的函数,返回注释类型的结构数据节点。
参考:
- emitError 触发报错的函数。
- getSelection 返回包含目标内容的位置信息对象。
function parseComment(context: ParserContext): CommentNode {__TEST__ && assert(startsWith(context.source, '<!--'))const start = getCursor(context)let content: string// Regular comment.const match = /--(\!)?>/.exec(context.source)if (!match) {content = context.source.slice(4)advanceBy(context, context.source.length)emitError(context, ErrorCodes.EOF_IN_COMMENT)} else {if (match.index <= 3) {emitError(context, ErrorCodes.ABRUPT_CLOSING_OF_EMPTY_COMMENT)}if (match[1]) {emitError(context, ErrorCodes.INCORRECTLY_CLOSED_COMMENT)}content = context.source.slice(4, match.index)// Advancing with reporting nested comments.const s = context.source.slice(0, match.index)let prevIndex = 1,nestedIndex = 0while ((nestedIndex = s.indexOf('<!--', prevIndex)) !== -1) {advanceBy(context, nestedIndex - prevIndex + 1)if (nestedIndex + 4 < s.length) {emitError(context, ErrorCodes.NESTED_COMMENT)}prevIndex = nestedIndex + 1}advanceBy(context, match.index + match[0].length - prevIndex + 1)}return {type: NodeTypes.COMMENT,content,loc: getSelection(context, start)}
}
parseElement
解析元素内容的函数,返回元素类型的结构数据节点。
一个普通的元素包含: 开标签 + 子内容 + 闭标签;所以parseElement就是按这个顺序处理的,parseTag处理标签,parseChildren函数处理子内容。
参考:
- parseTag — 解析标签的函数。
- checkCompatEnabled — 判断是否可以进行兼容处理。
function parseElement(context: ParserContext,ancestors: ElementNode[]
): ElementNode | undefined {__TEST__ && assert(/^<[a-z]/i.test(context.source))// Start tag.const wasInPre = context.inPreconst wasInVPre = context.inVPreconst parent = last(ancestors)const element = parseTag(context, TagType.Start, parent)const isPreBoundary = context.inPre && !wasInPreconst isVPreBoundary = context.inVPre && !wasInVPreif (element.isSelfClosing || context.options.isVoidTag(element.tag)) {// #4030 self-closing <pre> tagif (isPreBoundary) {context.inPre = false}if (isVPreBoundary) {context.inVPre = false}return element}// Children.ancestors.push(element)const mode = context.options.getTextMode(element, parent)const children = parseChildren(context, mode, ancestors)ancestors.pop()// 2.x inline-template compatif (__COMPAT__) {const inlineTemplateProp = element.props.find(p => p.type === NodeTypes.ATTRIBUTE && p.name === 'inline-template') as AttributeNodeif (inlineTemplateProp &&checkCompatEnabled(CompilerDeprecationTypes.COMPILER_INLINE_TEMPLATE,context,inlineTemplateProp.loc)) {const loc = getSelection(context, element.loc.end)inlineTemplateProp.value = {type: NodeTypes.TEXT,content: loc.source,loc}}}element.children = children// End tag.if (startsWithEndTagOpen(context.source, element.tag)) {parseTag(context, TagType.End, parent)} else {emitError(context, ErrorCodes.X_MISSING_END_TAG, 0, element.loc.start)if (context.source.length === 0 && element.tag.toLowerCase() === 'script') {const first = children[0]if (first && startsWith(first.loc.source, '<!--')) {emitError(context, ErrorCodes.EOF_IN_SCRIPT_HTML_COMMENT_LIKE_TEXT)}}}element.loc = getSelection(context, element.loc.start)if (isPreBoundary) {context.inPre = false}if (isVPreBoundary) {context.inVPre = false}return element
}
parseText
解析文本内容,返回文本类型的结构数据节点。
function parseText(context: ParserContext, mode: TextModes): TextNode {__TEST__ && assert(context.source.length > 0)const endTokens =mode === TextModes.CDATA ? [']]>'] : ['<', context.options.delimiters[0]]let endIndex = context.source.lengthfor (let i = 0; i < endTokens.length; i++) {const index = context.source.indexOf(endTokens[i], 1)if (index !== -1 && endIndex > index) {endIndex = index}}__TEST__ && assert(endIndex > 0)const start = getCursor(context)const content = parseTextData(context, endIndex, mode)return {type: NodeTypes.TEXT,content,loc: getSelection(context, start)}
}
parseBogusComment
解析伪注释内容,返回注释类型的结构数据节点。
一些内容会被这个函数当作注释解析,并会给出警告信息。
function parseBogusComment(context: ParserContext): CommentNode | undefined {__TEST__ && assert(/^<(?:[\!\?]|\/[^a-z>])/i.test(context.source))const start = getCursor(context)const contentStart = context.source[1] === '?' ? 1 : 2let content: stringconst closeIndex = context.source.indexOf('>')if (closeIndex === -1) {content = context.source.slice(contentStart)advanceBy(context, context.source.length)} else {content = context.source.slice(contentStart, closeIndex)advanceBy(context, closeIndex + 1)}return {type: NodeTypes.COMMENT,content,loc: getSelection(context, start)}
}
结语
上篇:【vue3】vue3源码探索之旅:compiler-core(一)