机器学习基础了解
概念
机器学习是人工智能的一个实现途径
深度学习是机器学习的一个方法发展而来
定义:从数据中自动分析获得模型,并利用模型对特征数据【数据集:特征值+目标值构成】进行预测
算法
数据集的目标值是类别的话叫做分类问题;目标值是连续的数值的话叫做回归问题;统称监督学习;
另一类是无监督学习,这一类的数据集没有目标值,典型:聚类;
做什么
可以进行传统预测、图像识别、自然语言处理
传统预测
店铺销量预测、量化投资、广告推荐、企业客户分类、sql语言安全检测分类
图像识别
街道交通标志检测、人脸识别
自然语言处理
文本分类、情感分析、自动聊天、文本检测、翻译、写报纸、简单的新闻报告等
机器学习开发流程
数据收集、数据清洗(过滤、缺失处理、异常处理)、特征工程、数据建模 、模型评估
数据清洗是指处理数据中的错误、不完整或不准确的部分,以确保数据的质量和准确性。数据清洗通常涉及处理缺失值、异常值、重复值和错误值等。
特征工程是指根据数据的特性和业务需求,对原始数据进行转换、组合和提取,以提取出对建模和分析有用的特征。特征工程通常涉及对原始数据进行标准化、归一化、离散化、特征选择、特征组合等处理。
因此,数据清洗主要关注数据的准确性和完整性,而特征工程主要关注如何从原始数据中提取出对建模和分析有用的特征。两者都是数据预处理的重要环节,对于最终的数据分析和建模结果都有着重要的影响。
特征工程
定义:特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程
数据集
Kaggle网址:https://www.kaggle.com/
UCI网址:https://archive.ics.uci.edu/
scikit-learn:https://scikit-learn.org/stable/index.html
scikit-learn
Classification 分类; Regression 回归; Clustering 聚类;
Dimensionality reduction降维; Model selection 模型选择 ;Preprocessing 特征工程;
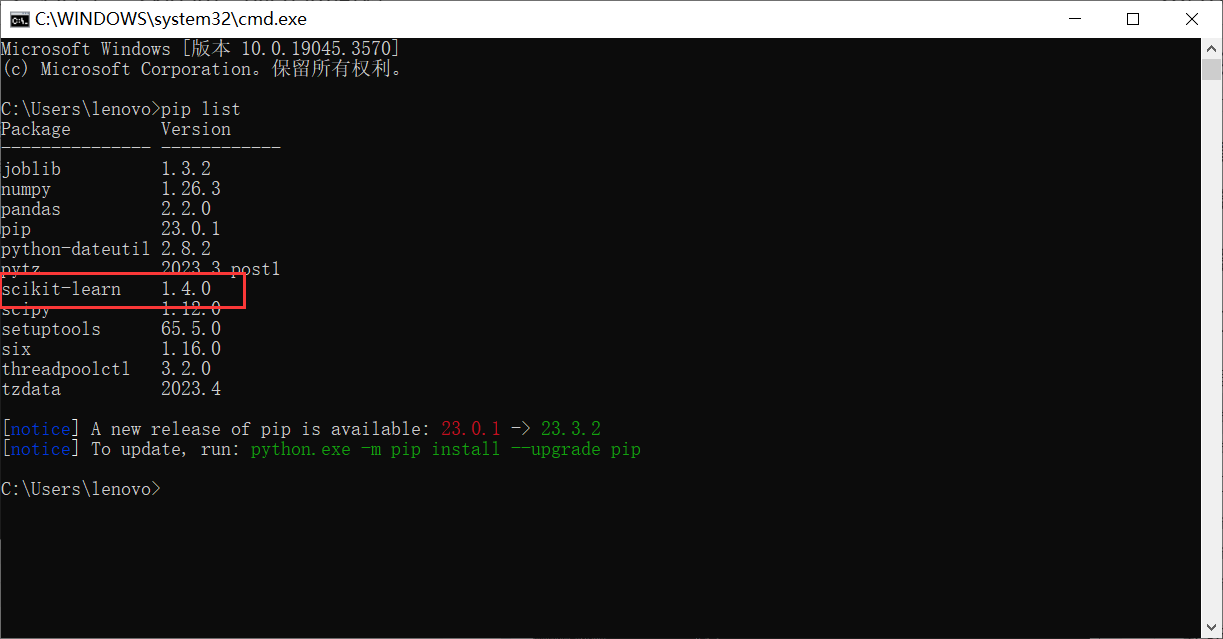
安装步骤:1.安装相关库【numpy+mkl和scipy】:步骤为下载相关库安装包,打开下载文件夹,shift+鼠标打开‘在此处打开Powershell窗口,使用pip install 名字安装;2.win+R输入cmd,进入cmd命令框;使用命令pip install -U scikit-learn安装 具体见笔记;
验证一下,打开cmd命令框,查看版本pip list;
数据集使用
特征提取:load(获取小规模数据集)、fetch(获取大规模数据集)
返回Bunch数据类型
数据集划分
使用:sklearn.model_selection.train_test_split
训练数据:用于训练,构建模型
测试数据:模型检验使用,用于评估模型是否有效,一般20%-30%
特征工程步骤
特征提取【特征值化】:
使用:sklearn.feature_extraction
将任意数据(如文本图像)转换为可用于机器学习的数字特征,目的是为了计算机能够更好的理解数据,如字典特征提取【特征离散化】、文本特征提取、图像特征提取【深度学习】
字典特征抽取【将特征当中存在的类别信息做one-hot编码处理】
应用场景:
1)数据集中类别特征比较多时,可以先将数据集特征转化为字典类型,然后使用sklearn.feature_extraction.DictVectorizer类转换【调用fit_transform(数据集)方法,默认是系数矩阵;用get_feature_names()方法返回类别名称】;2)数据集本身就是字典类型
one-hot编码:One-hot编码是一种将分类变量转换为二进制向量的编码方法。在这种编码中,每个分类变量的取值被表示为一个长度为n的二进制向量,其中n是分类变量的取值个数。在这个向量中,只有对应分类变量取值的索引位置上的值为1,其他位置的值都为0。这种编码方法可以使分类变量在机器学习算法中更容易处理和分析。
文本特征抽取
应用场景:
1)统计每个样本特征词出现的个数,用sklearn.feature_extraction.text.CountVectorizer类进行转换【调用fit_transform(文本)方法】;
2)统计一个字或者一个词对一个文件集或一个语料库中其中一份文件的重要程度,即统计在某一类类别文章出现次数很多,但其他类别文章当中出现较少的关键词,用sklearn.feature_extraction.text.TfidfTransformer类进行转换【调用fit_transform(文本)方法】,即tf-idf【term frequency词频,inverse document frequency逆向文档频率】方法;
扩展:
jieba可以用来中文分词
安装jieba库方法如下
使用命令pip install jieba
安装成功

特征预处理
The sklearn.preprocessing package provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream estimators.
解释:通过一些转换函数将特征数据转换为更加适合算法模型的特征数据过程
数值型数据的无量纲化:
为什么要进行归一化和标准化:
特征的单位或者大小相差较大,或者某特征的方差要比其他特征要大出几个数量级, 容易影响(支配)目标结果,使得一些算法无法学习到其他目标;所以为了使不同规格数据转换为同一规格要使用无量纲化(归一化和标准化)
比较:
对于归一化来说,如果出现异常点,会影响最大值和最小值,结果会发生变化
对于标准化来说,如果出现异常点,由于具有一定的数据量,少量的异常点对于平均值的影响不大,从而方差【标准差代表数据的集中程度】影响较小
1)归一化
定义:对原始数据进行变换把数据映射到(默认【0,1】)之间 公式:
使用场景:因为最值是变化的且容易受异常点影响,所以这种方法鲁棒性【健壮性】较差,只适合传统精确小数据场景

使用:sklearn.preprocessing.MinMaxScaler
调用sklearn.preprocessing.minmax_scale(X, feature_range=(0, 1)【最小最大值放缩】,先读取数据,然后实例化对象【调用fit_transform()方法即可】,如下
数据,文件名:dating.txt
milage,Liters,Consumtime,target
40920,8.326976,0.953952,3
14488,7.153469,1.673904,2
26052,1.441871,0.805124,1
75136,13.147394,0.428964,1
38344,1.669788,0.134296,1
代码
import pandas as pd
from sklearn.preprocessing import MinMaxScalerdef minman_demo():"""归一化:return:"""# 1.获取数据data = pd.read_csv("dating.txt")data = data.iloc[:,:3] # 每行都要,前3列print("data:\n", data)# 2.实例化转换器类transfer = MinMaxScaler()# 3.调用转换器类data_new = transfer.fit