作者:京东物流 数据专家 刘敬斌
小编导读:
京东集团 2007 年开始自建物流,2017 年 4 月正式成立京东物流集团,截至目前,京东物流已经构建了一套全面的智能物流系统,实现服务自动化、运营数字化及决策智能化。
京东物流在运营数字化及决策智能化过程中,实时化运营分析的业务需求越来越多,原有平台架构中的数据孤岛、查询性能低、运维难度大、开发效率低等问题日益凸显。2022 年,京东物流基于 StarRocks 打造了 Udata 统一查询引擎,高效解决了数据服务与数据分析的众多痛点。
近两年来,京东物流在 StarRocks 的使用中不断进行性能提升优化,取得了良好的效果。在 StarRocks Summit 2023 上,京东物流数据专家刘敬斌为大家介绍了 StarRocks 的应用经验,并重点分享了湖仓查询的优化经验和效果。另外,据刘敬斌介绍,在 2023 年京东双十一大促期间,京东物流 StarRocks 集群规模已经达到了 3 万核以上。
京东物流的用数特征和痛点
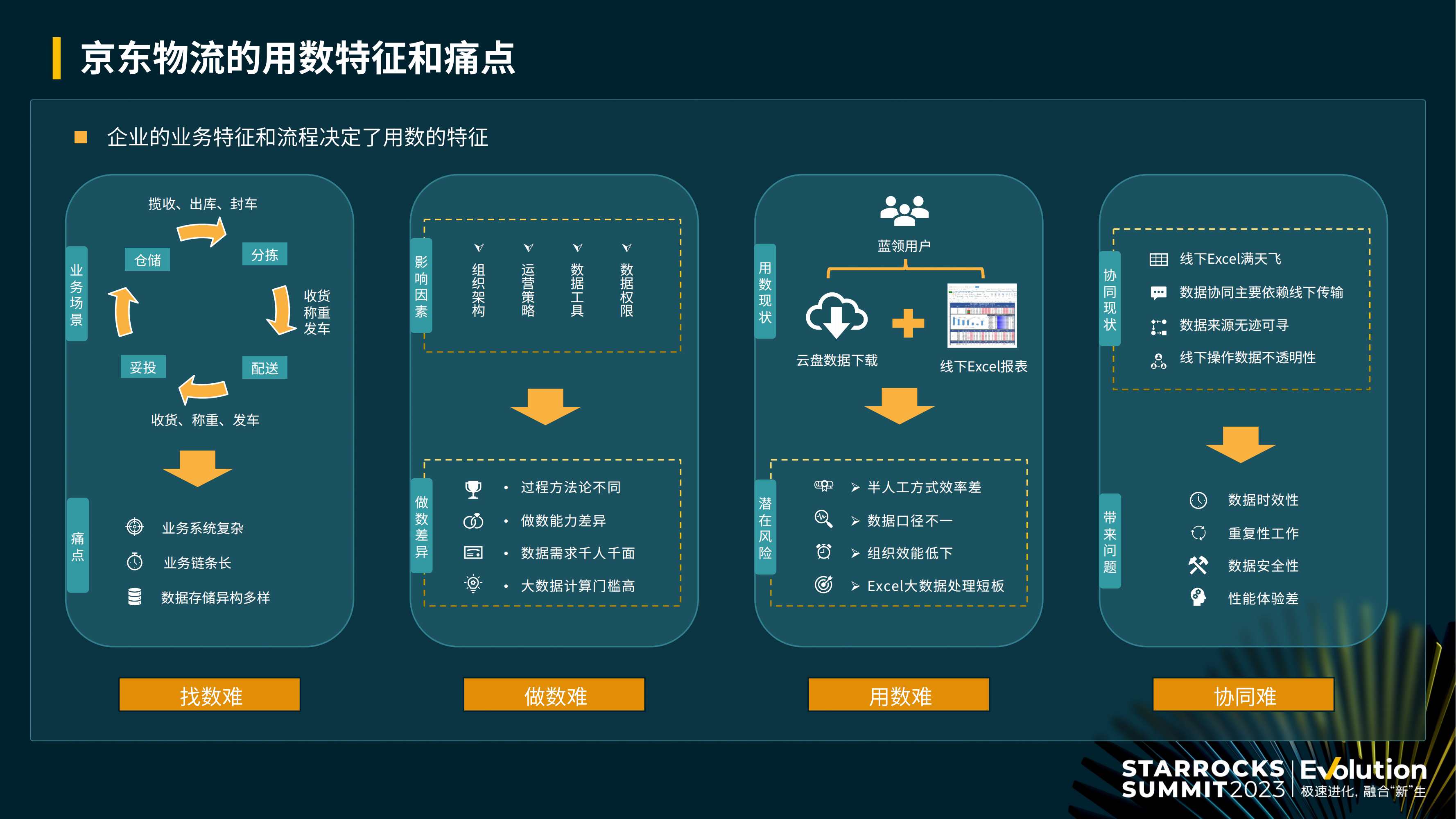
一个企业的业务特征决定了用户的用数习惯,而用数习惯往往会演变出一些用数痛点,在京东物流的数据分析服务场景中存在 4 大痛点。
找数难
在我们的业务场景中,当一个订单从商城域进入物流域后,会经过很多环节,从仓储到分拣,再到配送、拓投,链条非常长,中间系统特别多,数据也比较多,各个系统产生的数据被存储到各种各样的异构存储里,一线运营人员在找数据时存在一定困难。
做数难
京东物流划分了很多省区,每个省区都有自己的运营策略,一线运营人员各自都有不同的做数方法论去适配自己的运营策略,而数据分析平台目前面对的用户大部分都是一线运营人员,数据需求千人千面,此外我们还希望让运营人员能像使用 Excel 一样的去使用大数据,降低大数据使用门槛,这也是我们面临的重要任务。
用数难
Hadoop 平台把数据算出来之后,一线运营人员通过内部的云盘系统,将数据下载到本地,然后导入到本地 Excel,这种用数模式存在一些问题:
-
整个过程中有很多半人工方式,效率非常低;
-
每个省区的数据来源都不一致,可能会导致数据口径不统一;
-
Excel 对于大数据的处理能力有很多缺陷;
协同难
报表生成之后,有时需要互相传阅,在 Excel 非常多的情况下,大家互相传输,有时会用到一些线下的传输工具,导致数据来源不明晰,由于传输过程中有很多人工参与,协同比较困难,数据的时效性、安全性都得不到保障,并且存在大量重复性工作,性能体验非常差。
基于 StarRocks 的解决方案
京东物流 Udata 里面关于数据分析服务有两个概念:
-
数据服务:当数据通过 SQL 方式提供对外赋能时,SQL 比较固化,查询场景也比较固定;
-
数据分析:类似 Ad-hoc 查询,用户进行数据探索;
数据分析
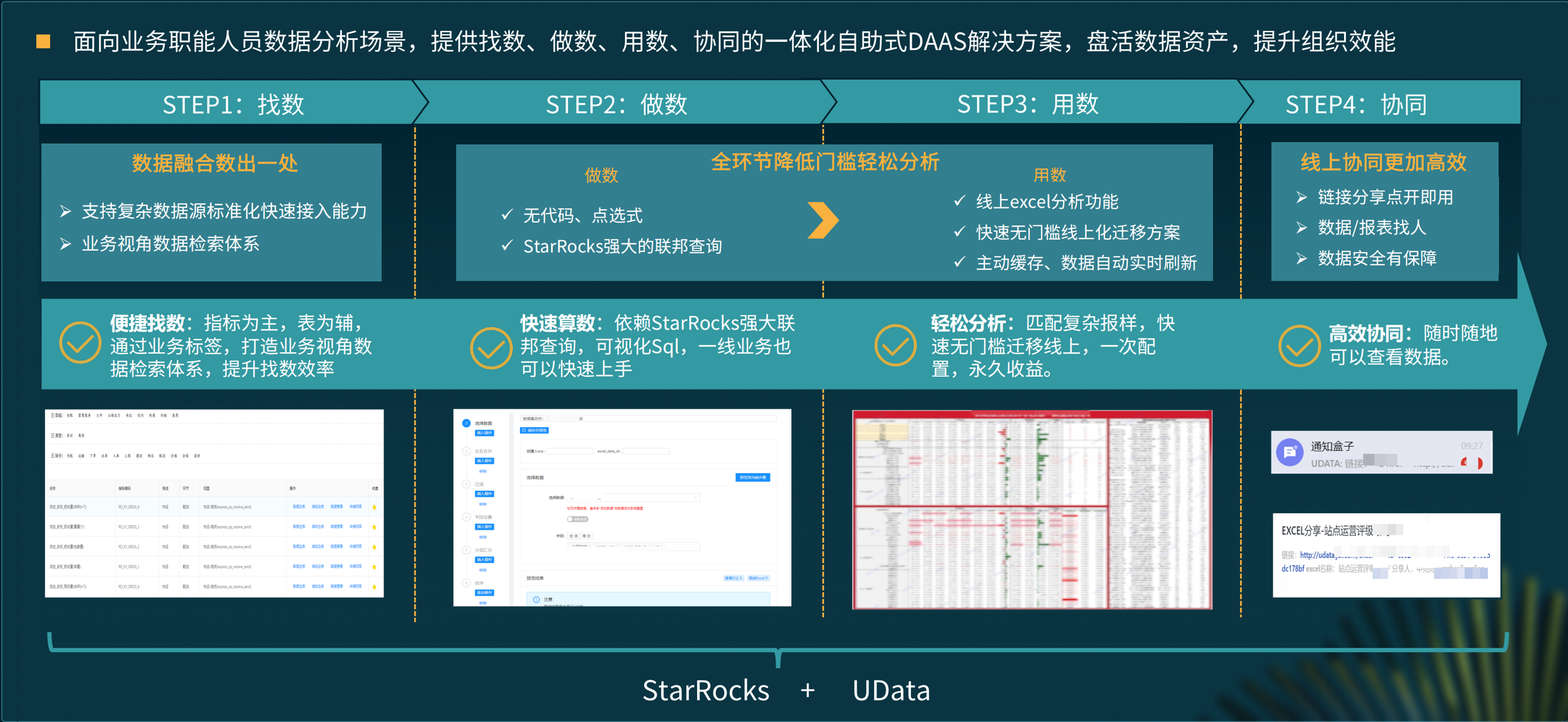
在数据分析场景中,我们要解决 4 个问题:
-
找数,运营人员对业务非常了解,他们的需求和业务语义比较贴近,但是数据保存在大数据库,和研发人员更加贴近,这中间不可避免存在割裂,如何让运营人员用业务语义去找到对应的数据表?我们会把数据以指标表维度打上业务标签,建立数据视图,让一线找数的人员可以按照业务视角,通过图数据库的数据血缘关系快速找到想要的数。 -
做数,一线运营人员对于决策非常了解,但是如何生成 SQL?Udata 通过无代码点选式的方式来让一线用户只需在线拖拖拽拽,就能将业务意图翻译成 SQL 语句。我们希望构建覆盖京东生态全部数据源的接入能力,让用户可以随时随地查询各种各样的数据,StarRocks 强大的联邦查询能力起到了非常关键的作用。 -
用数,借助 Udata 的线上 Excel 能力,实现了将线下报表快速迁移到线上的方案,并且报表一次配置永久生效,通过 StarRocks 包括物化视图在内的一些高级特性,可以高效地得到查询结果。 -
协同,当报表线上化之后,能够通过链接、邮件等方式实现 PC 和移动端随时随地看数的目标。
数据服务

物流的业务发展比较快,当角色发生变化后,业务管理者需要及时看到数据,这对于数据的交付要求越来越高。一方面,数据的性能要求很高,另一方面,数据的可复用性比较低,因此我们需要投入更多的研发资源来应付大量的数据需求。
基于 StarRocks,我们得以通过界面的方式快速地开发数据服务接口。目前已经在很多场景应用了数据服务快速开发能力,基本能达到当日交付的响应速度。与传统方式相比,数据资产变现效率提升了 5 倍,开发成本降低了 80%,支持了我们很多的业务。
Udata 数据分析平台
Udata 数据分析平台产品设计
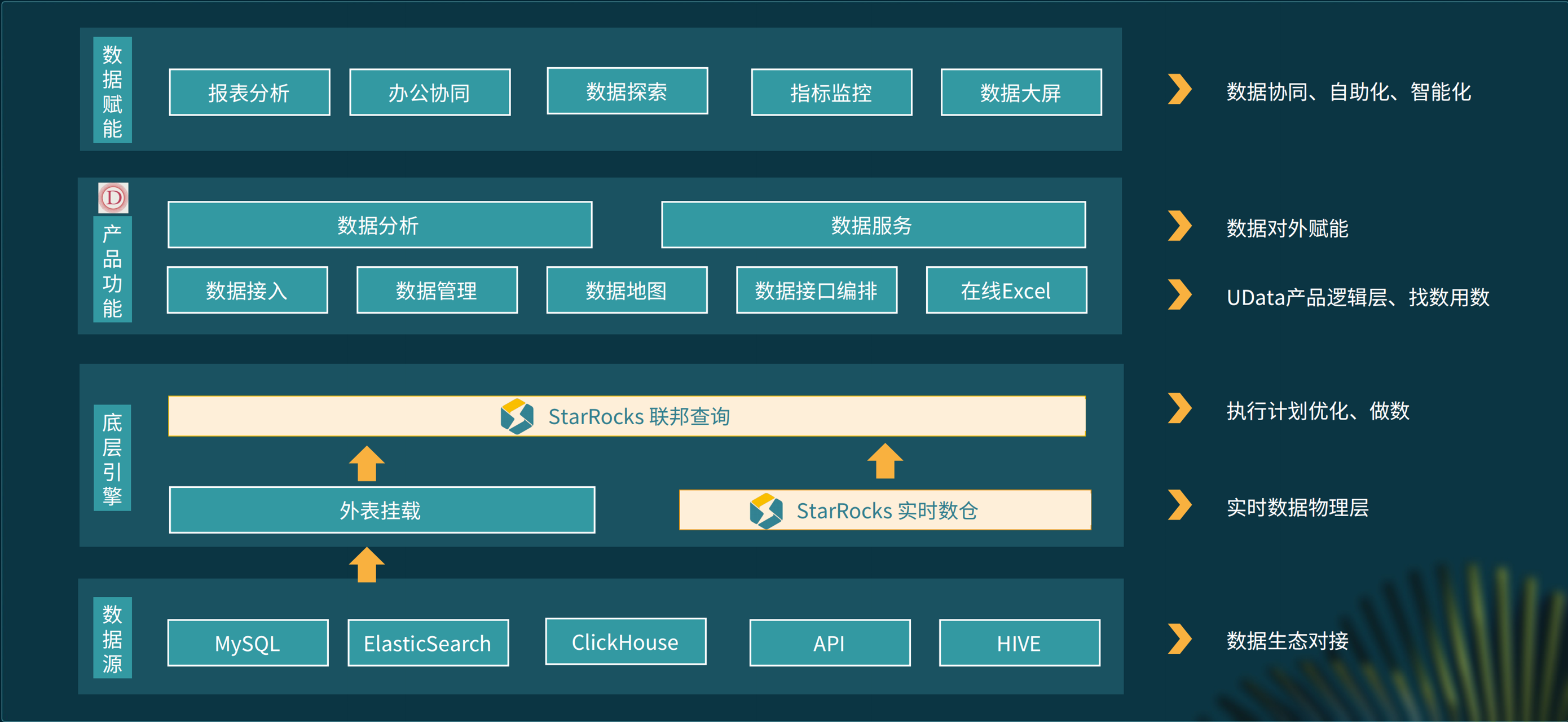
图中是 Udata 数据分析平台的产品设计,从下往上看分为 4 个部分:
-
数据源,现在可以兼容的数据源包括 MySQL、Elasticsearch、ClickHouse、Hive 等,还有一些 API,覆盖了京东大部分数据源,完成了京东生态对接; -
底层引擎,基于 StarRocks 打造,数据源会以外表挂载形式接入到查询引擎,底层的查询引擎分为两层:StarRocks 实时数仓,应用了 StarRocks 的数据快速摄入能力和高性能的数据查询能力。基于 StarRocks 打造的联邦查询,实现各种数据源跨数据源跨集群的查询,只要数据接入到系统就能进行查询。 -
产品功能,从数据接入到数据管理、数据使用,以及数据接口编排、在线 Excel,涵盖了数据的生命周期,解决了找数用数的问题。 -
数据赋能,主要通过数据分析和数据服务来对外赋能,支持的业务场景包含报表分析、办公协同、数据探索、指标监控、数据大屏等等。
湖仓新范式下的数据全景图
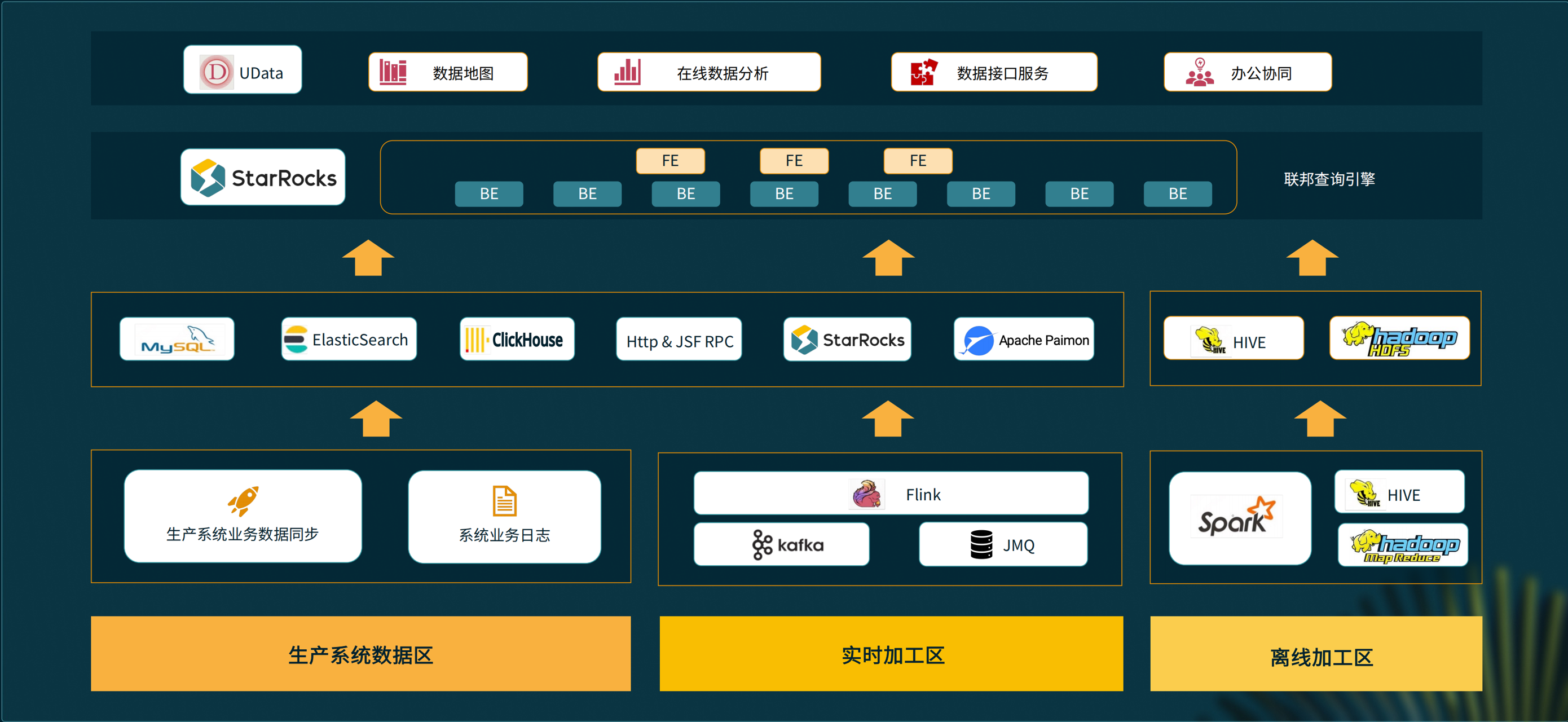
图中为湖仓新范式下数据全景图,从下往上看分为 4 层:
-
最下层左侧是生产系统数据区;中间是实时数据加工区,通过 Flink 接收众多系统接入的消息队列消息,然后加工到 OLAP 层;右侧是离线加工区,京东有很多历史数据都存在 Hadoop 里,我们会通过 Spark、Hive 来加工,存到 HDFS、Hive 里。
-
往上一层是 OLAP 层,包含 MySQL、Elasticsearch、ClickHouse 等数据库,另外还有 StarRocks、Paimon。右则是离线区,采用了 Hive 和 HDFS。
-
再往上是采用 StarRocks 搭建的一个支持超级联邦查询的集群引擎。
-
最上层是 Udata 对外赋能提供的能力,包括数据地图、在线分析、数据服务、办公协同等。
为什么选择 StarRocks
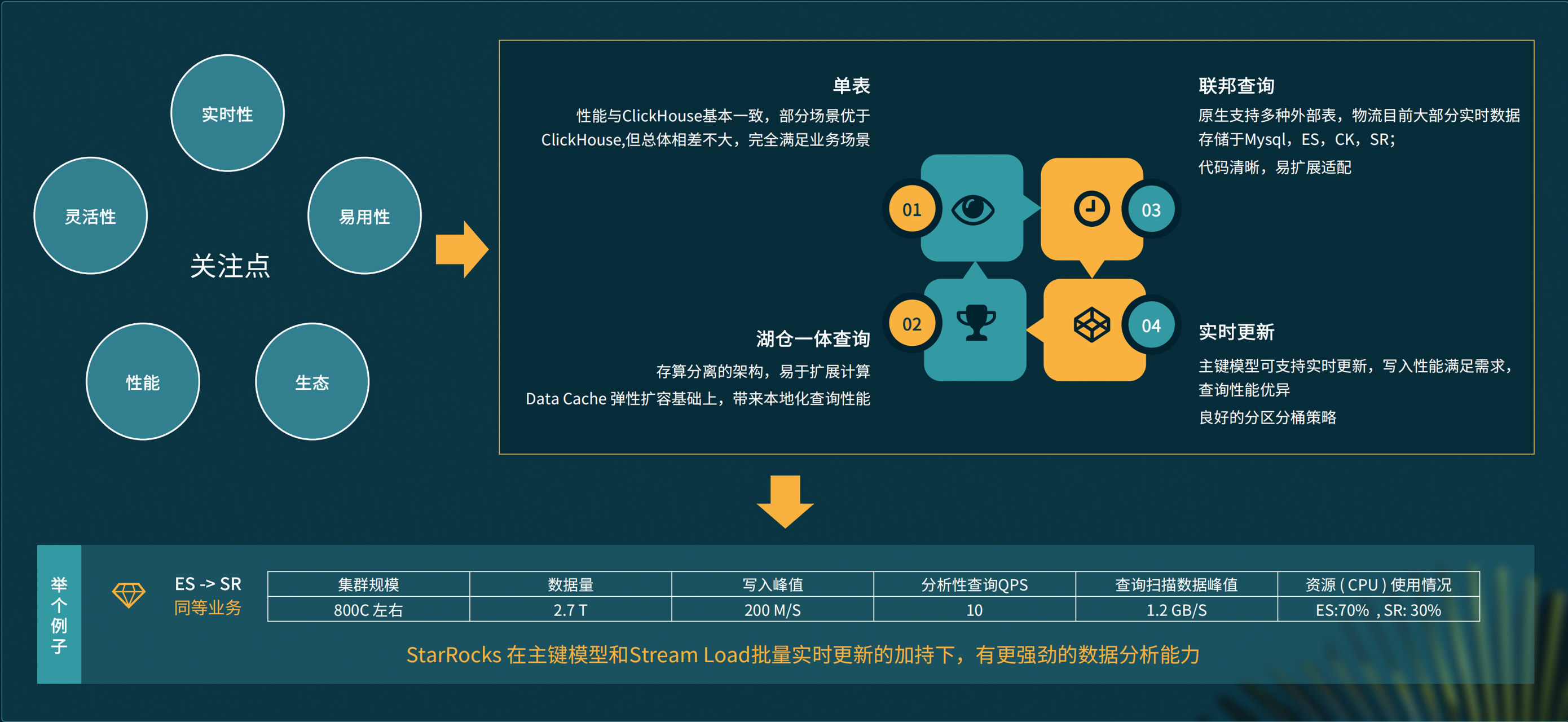
每个公司选择分析型数据库产品时都有很多关注点,我们主要关注的是实时性、应用性、灵活性、性能、生态等 5 个方面,StarRocks 在这些方面的表现都非常优秀,联邦查询、湖仓一体查询、实时更新等特性完全符合我们的需求,其中,湖仓一体查询是我们现在的主打方向。
因为一些历史原因,京东采用了很多 Elasticsearch,Elasticsearch 在搜索和倒排索引方面非常优秀,用来进行数据分析却可能不太适合,我们曾经接到过一个业务需求,需要从 Elasticsearch 把数据和业务迁移到 StarRocks,当时的集群规模约 800 CPU 左右,数据量约 2.5 TB,查询 QPS 大约 10,在业务同等满足的情况下,Elasticsearch 的 CPU 使用率高达70%,基本上无法再提供别的服务,StarRocks 的 CPU 使用率则在 30% 以下。显然,StarRocks 在主建模型和批量更新的加持之下,比 Elasticsearch 更适合这种数据分析。
StarRocks 的性能提升优化和效果
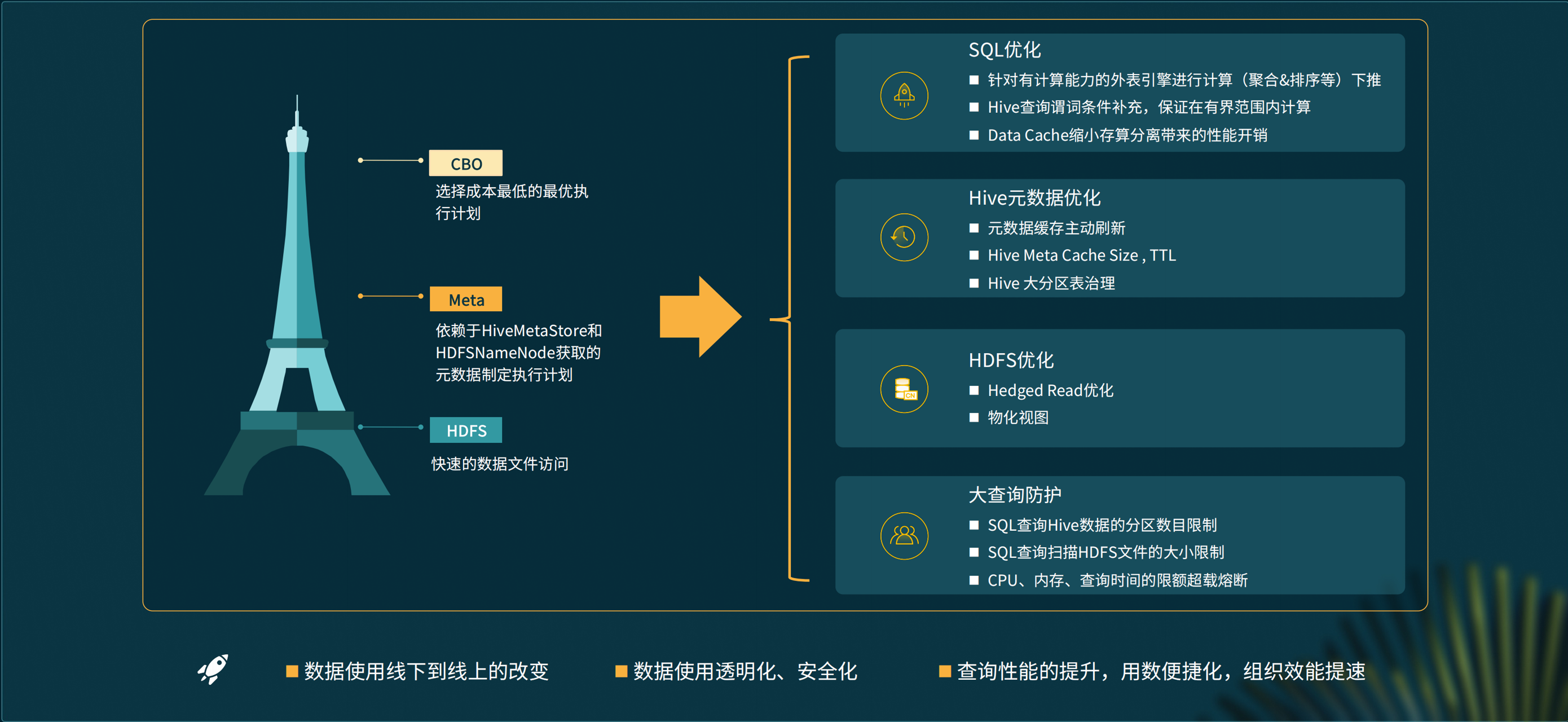
在 StarRocks 的使用中,我们进行了一些性能提升,其中对湖仓查询的性能优化尤为重视。我们的湖主要是 Hive,关于 Hive 的查询,首先 HDFS 需要快速的文件访问能力,其次元数据的拉取也要足够快,另外基于 CBO 的查询优化也非常关键,尤其在进行 Join 查询时,更加需要采用最优的执行计划。
SQL 优化
跨集群查询时,需要从另外一个集群里面拉取大量数据,网络开销比较多,所以针对有计算能力的外表引擎,我们进行了计算下推,就是把类似于 group by、limit 的聚合计算尽可能推到外表引擎上去,直接从跨级群拿到的是外表引擎里面已经计算后的结果,数据量会显著下降。
Hive 优化
数据分区分桶是 Hive 非常重要的特性,可以在查询时尽可能扫描更少的数据。在实际使用中,有些用户不太了解 Hive 里的分区键和列有哪些关系,对此,我们通过检查用户的 SQL 语句,帮助用户尽量将 Hive 的分区列应用到 SQL 里,这是我们对于湖的一个优化。 访问 HDFS 会带来远程 I/O 消耗,我们通过 data cache 减少了这部分性能开销。此外,第一次查询时因为要拉取大量的元数据,也会导致一些性能开销,而我们有一些表特别大,有时分区达到上百万,这也是我们在解决的一个问题,我们让 Hive 元数据的更新以事件通知到 FE,触发 FE 主动更新缓存,从而使第一次查询也能比较快。与此同时,我们还对 FE 里的 hive meta cache size、ttl 等也进行了改造。另外,我们把 Hive 里的一些大分区表尽也可能地进行了治理。
HDFS 优化
当 HDFS 集群有大量任务时,查询性能会有一些抖动,对此我们进行了 Heged read 的优化,优化之后效果非常显著。另外我们也希望在离线的湖上面的查询进行一些物化视图的加速。
大查询保护
Hive 上的数据都特别大,有时一次查询会占上百 G 的数据,甚至可能把集群的资源全部占用,为了避免这种情况,我们进行了一些防护,比如限制 Hive 分区数目、限制扫描的 HDFS 文件大小,对查询时间较长、CPU 占用较高的一些大查询进行熔断。 经过这些改造,目前京东物流已经落地的 Udata 产品做到了数据使用从线下到线上的转变。现在数据使用实现了透明化、安全化,使用过程中没有人为参与因素,查询性能也比较高。
京东双十一的流量考验
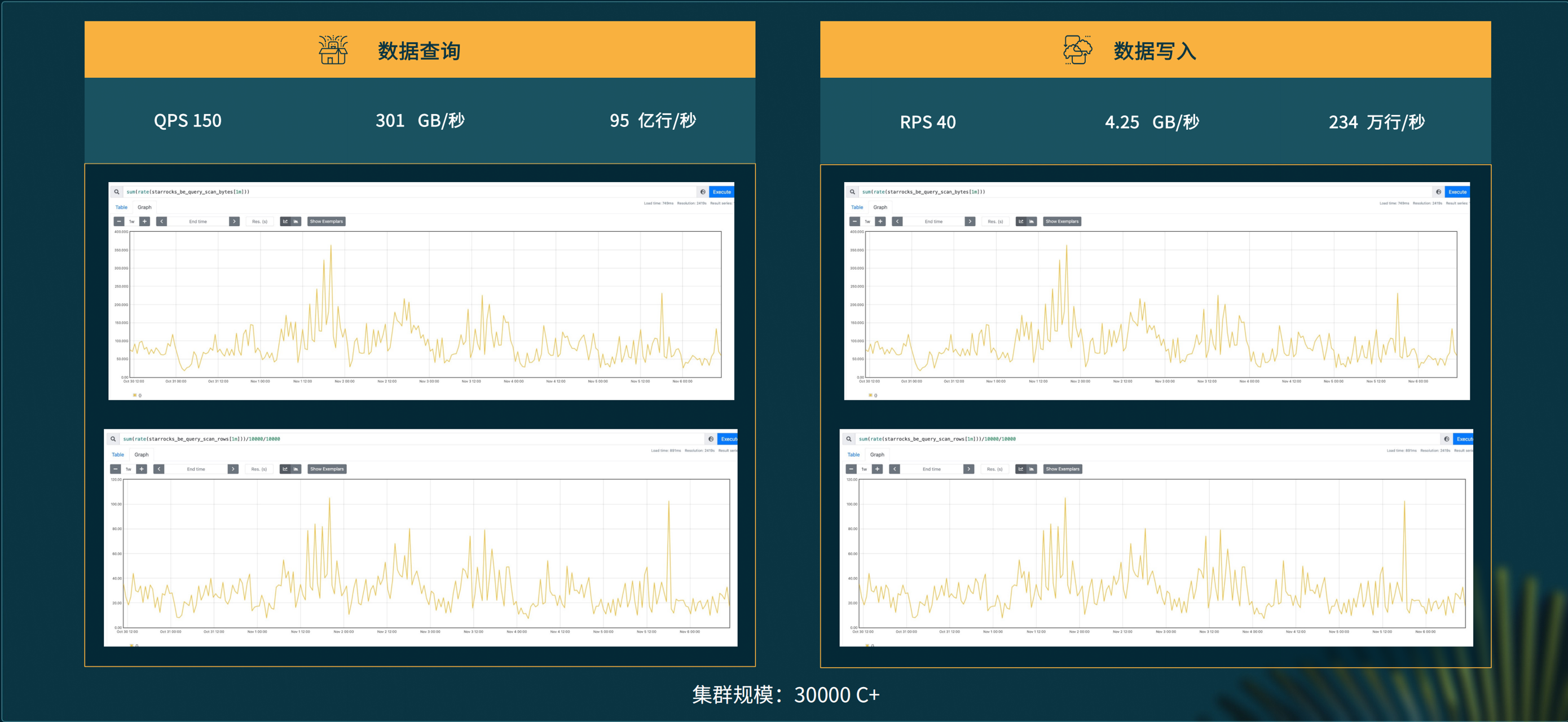
今年双十一大促期间,我们的数据查询 QPS 最高达到 150,相比平时呈几倍增长,并且通常要从海量数据里面进行查询,在 QPS 150 的情况下,扫描数据的峰值高达 300G 每秒,每秒扫描的数据行数达 95 亿行。对于数据写入,RPS 基本上是 40,数据写入峰值达 4.2G 每秒,每秒写入 234 万行。大促期间,StarRocks 集群规模已经达到了 3 万核以上。
未来规划探索
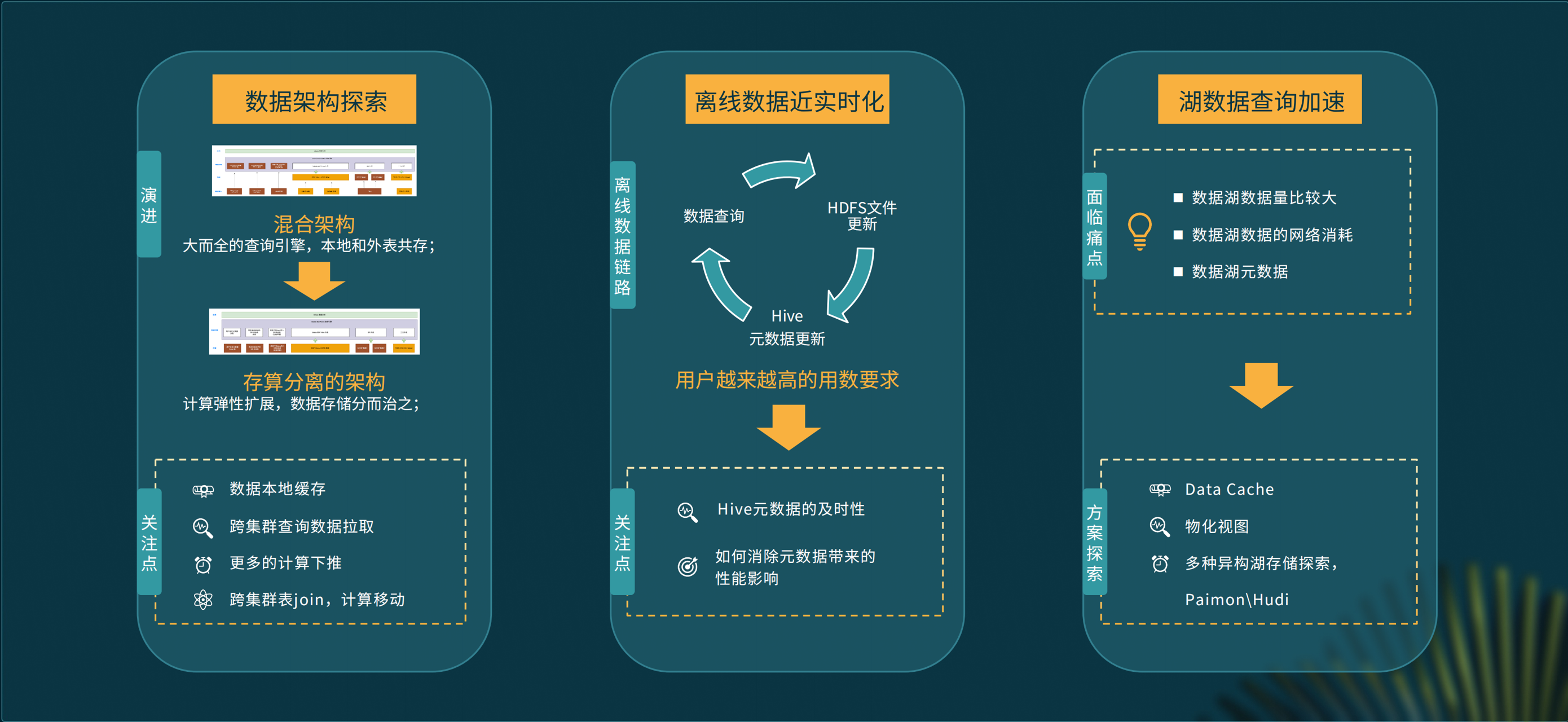
存算分离
我们目前采用的是混合架构,查询引擎多而全,本地表和外表共存,未来希望从这种架构迁移到存算分离架构,使计算可以弹性扩展,数据存储分而治之。
离线数据的实时化
我们希望当 Hive 里的数据、Hadoop 里的数据发生变化之后,能够快速查询最新数据,现在也在考虑如何让 Hive 的数据更新及时通知 FE 进行更新,同时尽量消除实时更新带来的性能影响。
数据湖加速
对于我们来说,数据湖的数据量都比较大,带来的网络开销非常大,另外元数据的性能开销也会影查询体验,现在我们在积极地尝试包含 data cache 在内的方式来减少远程 I/O,同时采用物化视图加速查询,此外我们还在探索包括 Paimon、Hudi 在内的多种异构湖存储。
本文由 mdnice 多平台发布