作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
阶段4、深入jdk其余源码解析
阶段5、深入jvm源码解析
码哥源码部分
码哥讲源码-原理源码篇【2024年最新大厂关于线程池使用的场景题】
码哥讲源码【炸雷啦!炸雷啦!黄光头他终于跑路啦!】
码哥讲源码-【jvm课程前置知识及c/c++调试环境搭建】
码哥讲源码-原理源码篇【揭秘join方法的唤醒本质上决定于jvm的底层析构函数】
码哥源码-原理源码篇【Doug Lea为什么要将成员变量赋值给局部变量后再操作?】
码哥讲源码【你水不是你的错,但是你胡说八道就是你不对了!】
码哥讲源码【谁再说Spring不支持多线程事务,你给我抽他!】
终结B站没人能讲清楚红黑树的历史,不服等你来踢馆!
打脸系列【020-3小时讲解MESI协议和volatile之间的关系,那些将x86下的验证结果当作最终结果的水货们请闭嘴】
引言
《菜鸟也能“种”好二叉树!》一文中提到了:为了方便查找,需要进行分层分类整理。而满足这种目标的数据结构之一就是树。
树的叶子节点可以看作是最终要搜寻的目标物;叶子节点以上的每一层,都可以看作是一个大类别、层中的每个节点都可以看作是一个小类别。
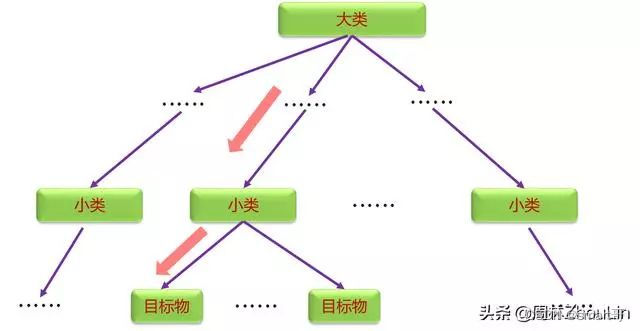
从上图可以看出,要定位目标物,就需要从最上面的大类依次向下定位目标物所属的小类。
定位的效率(时间复杂度)取决于两个因素:
- 非叶子节点的分岔数:分岔数越多,表示大类包含的小类数目也就越多,那么为了定位到底属于哪个小类,比较次数也就越多,从而时间开销也就越大。
- 树的高度(或称为深度):树越深(高),从根节点(最大类)到叶子节点(目标物)的路径也就越长,也就意味着时间开销越大。
研究问题都讲究由简到繁,那就让我们先来看看最简单的情形——分岔数最小的情形——二叉树。
二叉树的每层节点只有两个节点,这表示只有两个小类。定位属于哪个小类时,需要做比较。比较的次数越少、比较的方法越简单,效率也就越高。
比较次数再怎么少也得1次、最简单的比较方法就是比大小。为了满足这个目标,前辈们就对一般二叉树加了如下规则:
每个非叶子节点的左孩子的值不大于该节点本身的值;右孩子的值不小于该节点本身的值。
这样的二叉树就称为“二分查找树”。
二分查找树的数学思想
将二分查找树从根节点(最大类)到叶子节点(目标物)的路径扒出来,垂直放置之后就如下图左部所示。再倒”下来水平放置之后,就如下图右部所示。

由此可以看出,从最大类到目标物的查找过程,其实就是从大类不断逼近目标物的过程。
这个思想的本质其实就是数学的“逼近法”——不断缩小范围、直至不可再小,最终剩下的即为所求。
“逼近法”思想大量在数学中应用。牛顿当年发明微积分,其证明过程其实采用的也是“逼近法”。具体可以参见牛顿的旷世巨著《自然哲学的数学原理》第一编《物体的运动》的第1章《初量与终量的比值方法》的引理2。

牛顿

《自然哲学的数学原理》
二分查找法
基于二分查找树数据结构的搜索算法称为“二分查找法”。
二分查找树是一个递归定义,所以很容易得出递归版的二分查找法。
下面以链表形式存储的二分查找树为例,数组形式存储的,可以根据父子节点下标的线性关系(《菜鸟也能“种”好二叉树!》一文中的推论5.2.1),类似推导,在此就不赘述了。
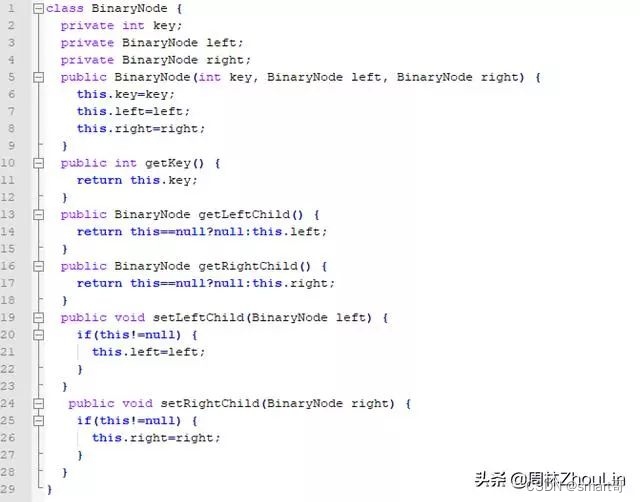

还是根据《史上最猛之递归屠龙奥义》一文中的老套路,转换成非递归版本:

整个算法的时间开销主要由do-while循环体的循环次数决定。很显然,在最坏情况下,循环次数等于二叉查找树的高度。假设树的节点总数为N,则根据《菜鸟也能“种”好二叉树!》一文中的结论,高度等于logN,从而时间复杂度等于O(logN)。
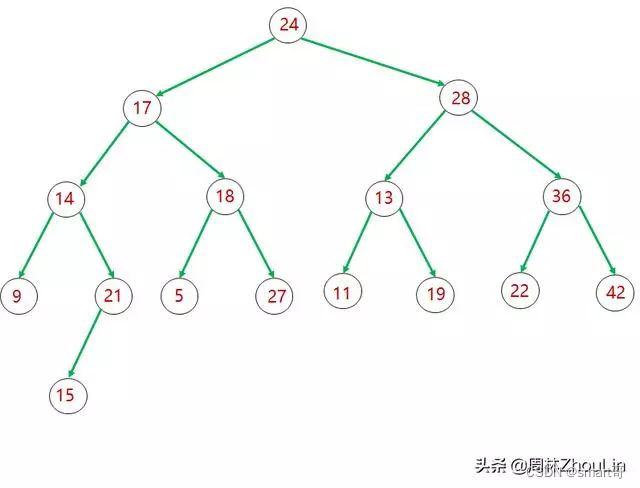
二分查找树的节点插入算法
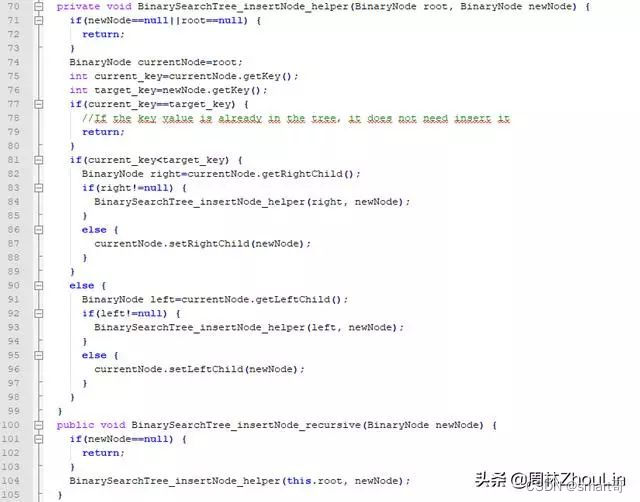
向二分查找树插入新节点很简单,从根节点开始,根据定义逐层比较、进入对应子树下沉、直至叶子节点:


对应的递归版算法代码如下:
还是根据《史上最猛之递归屠龙奥义》一文中的老套路,转换成非递归版本:

可以看出,整个算法结构与二分查找树的搜索算法类似,时间复杂度也是O(logN)。
二分查找树的节点删除算法
直接删除节点,会破坏二叉树的结构,需要进行调整。
首先需要有节点补上被删节点的空缺。这个“补漏”有两个策略:
- 直接计算出到底哪个节点最终应该到这个位置
- 先用一个节点顶上,然后再进行下推调整
稍微想一想,就会知道第一种策略比较复杂,因为你需要在一开始就通盘考虑,复杂度很高;
第二种策略其实是一种局部性原理思想——先局部求解、再逐步递进到全局解。这种局部性原理思想在整个计算机科学中大量使用:比如虚拟内存管理、人工智能的爬山算法等等。
第二种策略其实我们在上一篇《二叉堆“功夫熊猫”的速成之路》中的“Top N”章节中也提到了。有兴趣的朋友也可以翻回去看看。
具体实操上,和“Top N”的方法一样,我们用尾节点“补漏”被删节点。
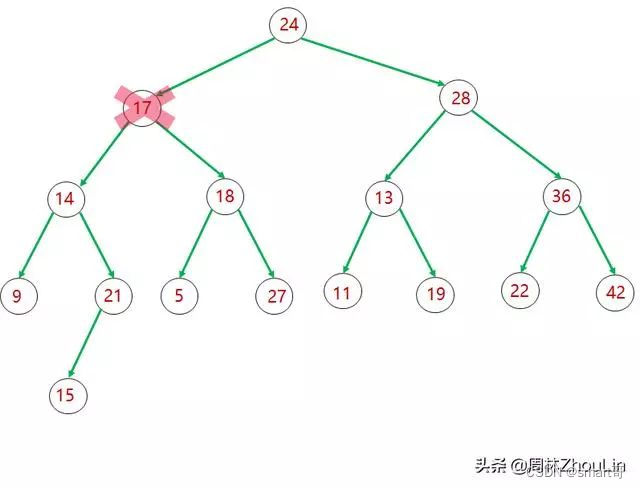
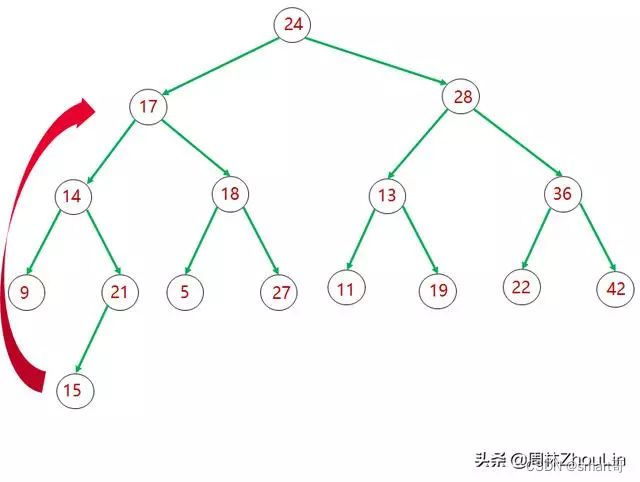
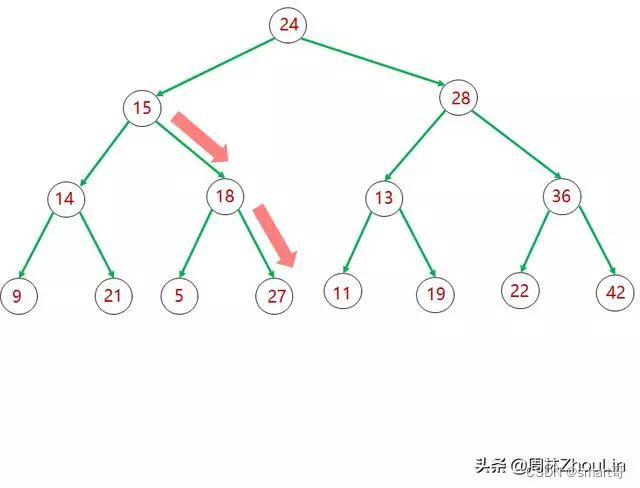
上面三张图形象描绘了整个替换、下推调整的过程。
这里啰嗦一句:因为要先得到尾节点的位置,然后再回到待删节点位置——这涉及到遍历和回溯,若采用链表存储整个二叉查找树的话,就不是很方便。所以针对节点删除场景,用数组更简单。
但为了“炫技”,笔者在这里就挑最复杂的单向链表式、非递归版算法来实现一下:)
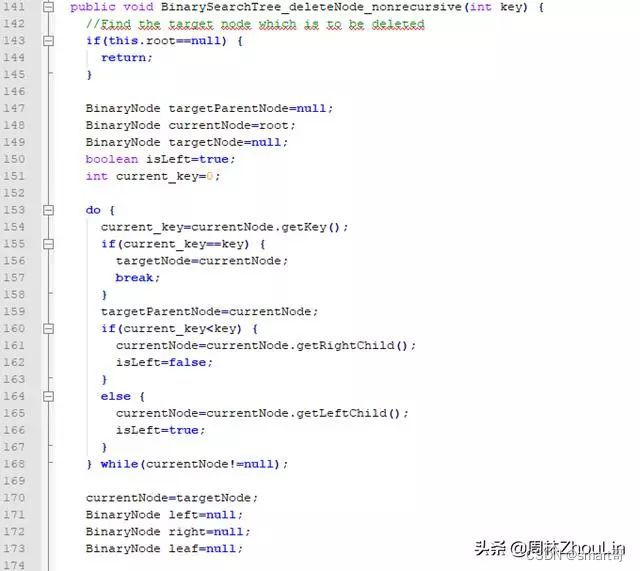


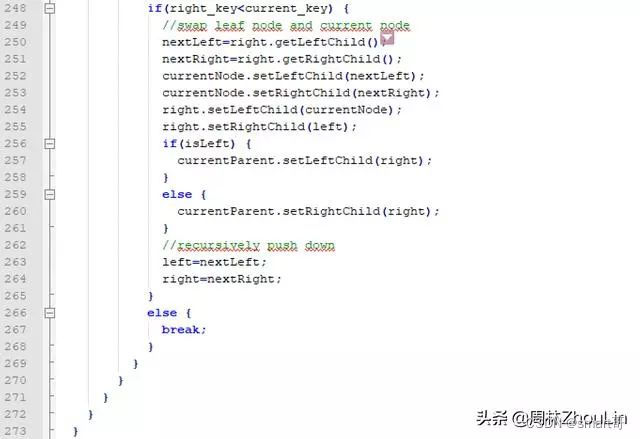
最坏情况无外乎删除根节点——这种情况下下推的距离最长——极限情况下,要下推整个二分查找树的高度。所以这个算法的时间复杂度不超过O(logN)。
至于数组式、递归版算法,读者可以根据《史上最猛之递归屠龙奥义》和《二叉堆“功夫熊猫”的速成之路》中讲到的套路,自行推导。
做一棵“稳重的”二分查找树
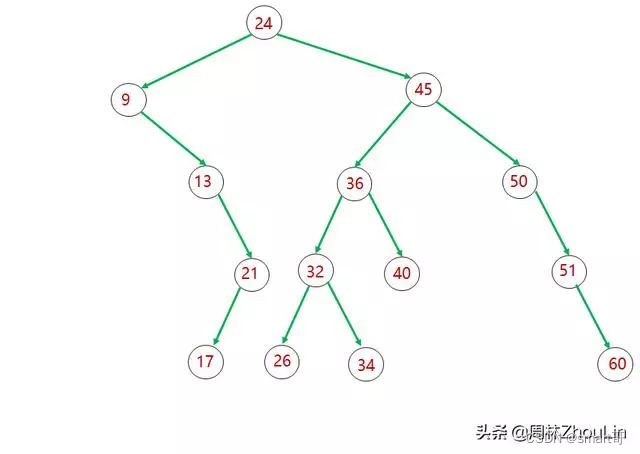
上面两棵二分查找树是等价的,但是可以很明显看出:第一棵一些分支会向一边倾斜,而第二棵就显得“稳重”多了。
试想,你要搜索值为17的节点。按照前面二分查找树的搜索算法,对于第一棵树,从根节点开始,一共需要进行4次比较才能找到;而对于第二棵树,只需要进行1次比较就能找到!
为什么会有这么大的差别呢?
答案在于:第二棵树是一棵“平衡二叉树”,它的“稳重”特点实现了一个目标——平均查找长度最短。
下一篇文章我们就来“盘盘”平衡二叉树。