文献来源:Saggi M K, Jain S. A survey towards an integration of big data analytics to big insights for value-creation[J]. Information Processing & Management, 2018, 54(5): 758-790.
下载链接:链接:https://pan.baidu.com/s/14IGaCOc-plxAiaVhwOgUvA
提取码:4w8k
如何设计BDA-DM(Big data analytics & decision-making framework (BDA-DMF))框架?
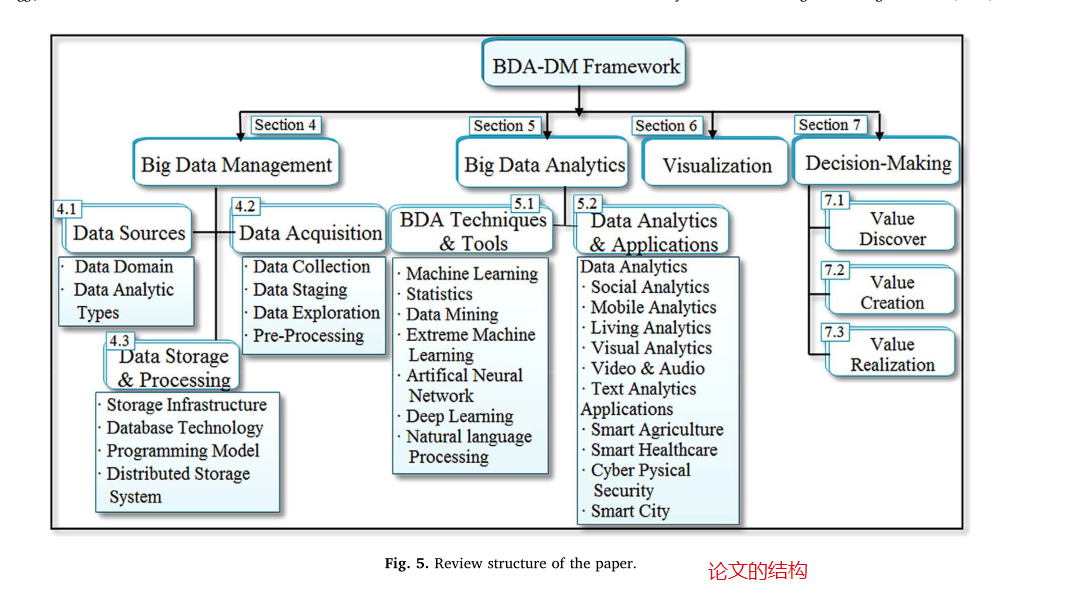
大数据分析与决策框架(BDA-DMF)框架如图5所示,旨在发现商业生态系统中的价值。该图显示了大数据管理、大数据分析、数据可视化和价值创造决策,分别在第4、5、6和7节中讨论。
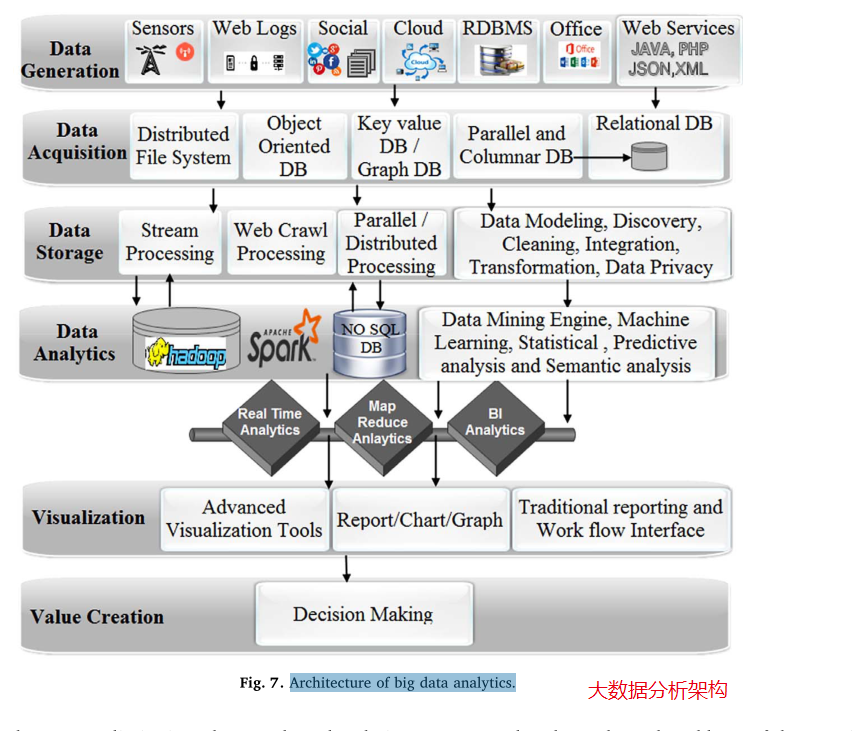
如何设计BDA-DM框架?大数据分析是一种数据密集型架构,它提供了用于数据生成、数据采集、数据存储、高级数据分析、可视化和价值创造决策等各个阶段的各种技术和平台,如图7所示。它遵循自上而下的方法。它包括各种技术,如Hadoop、HBase、Cassandra、MongoDB, NoSQL等。由于其局限性,这些工具和技术无法解决数据存储、数据搜索、数据共享、数据可视化以及实时分析等现实问题。
大数据管理(BDM)为大数据分析提供了基础设施,可以应用数据管理技术、工具和平台,包括存储、预处理、处理和安全。BDM中涉及的组件描述如下:
(一)数据源
大数据生成是指从各种相关来源生成数据。它可以由人、机器、业务流程和具有描述性、预测性和规定性的数据技术生成。
(1)大数据生成
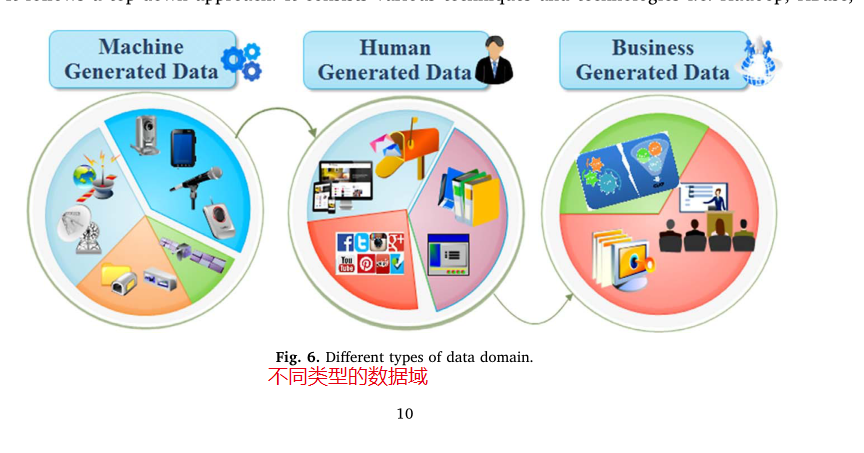
数据领域蓬勃发展的数据领域由各种描述性术语表示,例如:结构化、非结构化、机器和传感器生成的数据、批处理和实时处理数据、生物识别数据、人为生成的数据和业务生成的数据。图6显示了各代大数据分析领域的相关性
•机器生成数据:机器生成的数据来自多个计算机网络、传感器、卫星、音频、视频流、移动电话应用程序和安全漏洞预测。
•人工生成数据:它可以由人收集,例如:识别细节,包括他们的姓名,地址,年龄,职业,工资,资格等。然而,真正的流数据可以由各种文件、文档、日志文件、研究、电子邮件和社交媒体网站(如Facebook、Twitter、YouTube、LinkedIn)生成。
•业务生成数据:全球所有公司的业务数据量估计每1.2年翻一番,如交易数据、企业数据和政府机构数据。当讨论BDA的商业智能(BI)时,它意味着:商业智能领域内的价值(数据是否包含任何对我的业务需求有价值的信息?),可见性(对问题的洞察力和远见的重点以及与之相关的适当解决方案)和判决(基于问题,计算能力和资源的决策者的潜力)(Wu, Buyya, & Ramamohanarao, 2016a)。
(2)数据类型
以下是三种类型的分析,组织和行业可以使用它们来学习和获得洞察力,以促进他们的业务。
•描述性:它由各种技术和代表当前和以前发生过程的推断数据的摘要组成。标准报告、特别报告、指示板、查询和向下钻取是描述性分析的各种示例。它被定义为回顾过去,以便得出一些推论。“出什么事了?”
•预测性:预测性分析建模是根本原因分析、蒙特卡罗模拟和数据挖掘。它有时用于实时或批处理过程。Siegal(2010)指出,通过采用这些预测分析来组织七个连续的目标,即竞争、成长、执行、改进、满足、学习和行动。它预测未来的趋势。-“会发生什么?”
•说明性:该技术适用于未来的场景,并根据预测提出解决方案或有见地的行动。Basu(2013)代表了规范性分析的五大支柱,即混合数据、综合预测和处方、处方和副作用、自适应算法和反馈机制。-“我们该怎么办?”
(二)数据采集
这里,数据采集涵盖了数据仓库或任何其他数据库中数据摄取的广泛收集、过滤和清理过程。(Chen, Mao, & Liu, 2014)研究了由于各种设备,数据采集支持异质性。
(1)数据采集
从现实环境中获取未处理的数据,并对其进行熟练开发的过程。日志文件广泛用于扩展由多个源和所有电子设备上的应用程序生成的数据收集,如扩展日志格式(W3C)、通用日志文件格式(NCSA)和IIS日志格式(Microsoft)。
传感器是测量物理量并通过数字信号将其转换为可读形式的另一种替代品。存在几种类型的传感器,如听觉,声音,汽车,振动,电流,天气,热,压力通过有线或无线网络传输。网络爬虫通常用于从各种基于网站的过程(如网络搜索引擎或网络缓存)收集数据或应用程序(Castillo, 2005)。
(2)数据暂存
此外,它被定义为收集各种数据集以及嘈杂的、冗余的和一致的数据的过程。它分为两种可选模型,即:流处理模型和批处理模型。流处理模型以最快的速度对数据进行分析,得出结果,数据以非常快的速度以连续的形式到达。为了支持它,有一些开源系统,包括Storm, S4和Kafka (Hu, Wen, Chua, & Li, 2014)。
在批处理模型中,首先存储数据,然后分析数据。在这个模型中,MapReduce (Dean & Ghemawat, 2008)已经成为主导平台。图8显示了(a)数据阶段分为数据探索和数据预处理两部分,(b)预测模型。
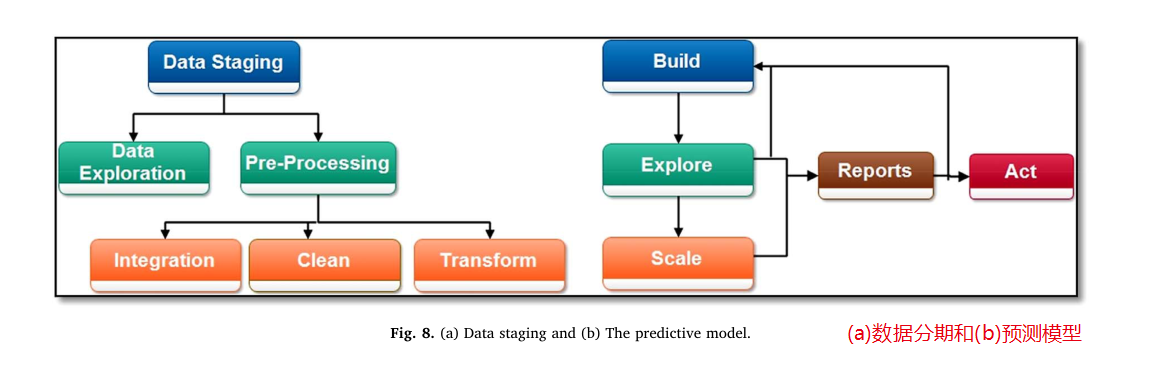
•数据探索(Data Exploration:):数据探索有两个主要目的。首先,确定和理解数据的性质和特征。其次,确定可能严重影响模型的数据质量问题。数据探索和数据挖掘被广泛用于发现新的见解。例如:—数据质量报告(平均值、众数、中位数和范围);标准偏差和百分位数;条形图、直方图和箱形图)和数据质量问题(有效或无效)。
•预处理(Pre-Processing):为了从大数据中提取有意义的信息,需要通过各种工具,即Apache Hadoop、NoSQL和MapReduce,对数据进行清理、整合和转换。预处理涉及到一系列步骤,即如何整合数据、如何转换数据、如何选择正确的模型进行分析以及如何提供结果。
-清理:清理、解决数据质量和格式问题是预处理的一个基本目标。它使我们能够发现不精确、不充分或不节制的数据,这些数据需要改变、删除和提高数据质量。
-集成:使用提取、转换和加载(ETL)过程,可以对数据进行清洗、转换,使其适用于数据挖掘和各种在线分析。
-转换:对原始数据进行转换,使其适合于分析和成型,例如使用一些工具对数据进行整合和打包:ETL, DMT, Pig。可以在数据的实时格式中应用各种操作,例如拆分数据、合并数据、执行计算、将数据与外部数据域连接以及将数据传播到多个目的地。
(三)数据存储与处理
它是管理数据存储的过程。它并行执行活动以优化存储过程。数据集群、复制和索引是完成大数据管理中存储阶段的重要活动。
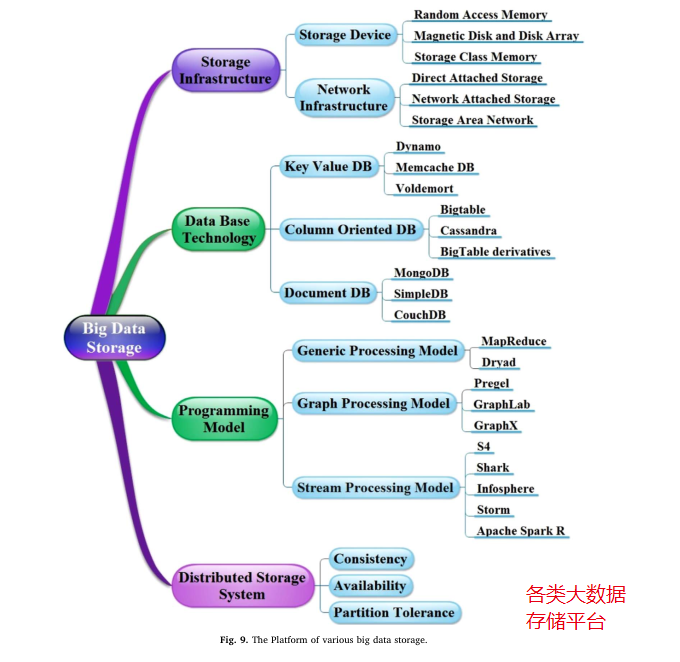
它是指从不同的来源收集数据后,可以以不同的形式存储多少类型的数据。有各种有用的大数据存储工具,即Hbase, NoSQL, Gluster, HDFS和GFS 。在消息传递接口上引入了一种创新的方法来并行化基于数据的应用程序。图9描述了不同平台的大数据存储情况。







![[SWPUCTF 2021 新生赛]easy_md5](https://img-blog.csdnimg.cn/direct/c356c14afe914b32a721df6e355f62a8.png)