1. MQ的优缺点
优点:解耦,异步,削峰
缺点:
系统可用性降低 系统引入的外部依赖越多,越容易挂掉。万一 MQ 挂了,MQ 一挂,整套系统崩
溃,你不就完了?
系统复杂度提高 硬生生加个 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?问题一大堆。
一致性问题 A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是
BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
2. 常见消息队列比较

3. RabbitMQ中的AMQP协议
AMQP(Advanced Message Queuing Protocol)是一种用于消息传递的网络协议。
核心概念:
- Exchange(交换机):用于接收生产者发送的消息,并根据一定的路由规则将消息路由到一个或多个队列中。
- Queue(队列):用于存储消息的容器,消费者从队列中获取消息进行处理。
- Binding(绑定):用于将交换机和队列进行绑定,指定消息的路由规则。
- Message(消息):包含消息内容和一些元数据,如消息标识符、优先级、时间戳等。
 4. 为什么kafka不支持读写分离
4. 为什么kafka不支持读写分离
在kafka中,生产者写入消息,消费者读取消息的操作都是与 leader 副本进行交互的,从而实现的是一种主写主读的生产消费模型。kafka不支持读写分离,也就是主写从读。
读写分离有以下不足:
(1) 主从延时。类似 Redis ,数据从写入主节点,再同步到从节点中的过程需要耗费一些时间。如果对延时的要求比较高,读写分离并不太适用。
(2) 数据一致性问题。由于主节点数据同步到从节点,需要一定时间。主从节点之间的数据不一定会一致。
kafka只支持主写主读,有几个优点:
(1) 负载均衡。
读写分离可以均摊一定的负载,却不能做到完全的负载均衡,比如对于写压力很大而读压力很小的情况,从节点只能分摊很少的负载压力,而绝大部分压力还是主节点上。而kafka 的主写主读,可以做到负载均衡。
(2) 没有主从延时的影响。
(3) 副本稳定的情况下,不会出现数据不一定的情况。
5. kafka是如何做到消息顺序性的?
确定一个主题,只有一个分区partition,生产者和消费者都是单线程处理。
6. kafka为什么那么快?
1. Kafka 是基于操作系统 的页缓存(page cache)来实现文件写入的,我们也可以称之为 os cache,意思就是操作系统自己管理的缓存。Kafka 在写入磁盘文件的时候,可以直接写入这个 os cache 里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把 os cache 里的数据真的刷入磁盘文件中。通过这一个步骤,就可以将磁盘文件写性能提升很多了,因为其实这里相当于是在写内存,不是在写磁盘,原理图如下:

2. kafka 写数据的时候,是以磁盘顺序写的方式来写的,也就是说仅仅将数据追加到文件的末尾,不是在文件的随机位置来修改数据。
3. kafka写入数据,传统4次拷贝,零拷贝技术可以减少没有必要的拷贝。

Kafka 利用了 Linux 的 sendFile 技术(NIO)实现零拷贝。

7. 如何避免重复消费?
消费时做幂等性处理,类似于mysql中update order set count = 10 where id = 1;采用MVCC多版本并发控制,生产的时候带上数据的版本号。
8. RocketMQ如何保证高可用性
1. 主从机制
消息生产的高可用:创建topic时,把topic的多个message queue创建在多个broker组上。这样当一个broker组的master不可用后,producer仍然可以给其他组的master发送消息。
消息消费的高可用:消费者一般从master上进行消费,当master不可用或者繁忙的时候consumer会被自动切换到从slave读。注意:RocketMQ 是不支持自动主从切换的,当主节点挂掉之后,生产者就不能再给这个主节点生产消息了。
2. 刷盘机制
同步刷盘:当数据写如到内存中之后立刻刷盘(同步),在保证刷盘成功的前提下响应client。
异步刷盘:数据写入内存后,直接响应client。异步将内存中的数据持久化到磁盘上。
RocketMQ采用多住多从,同步复制和异步刷盘保证高可用性。 同步复制: 也叫 “同步双写”,也就是说,只有消息同步双写到主从节点上时才返回写入成功 。
异步复制: 消息写入主节点之后就直接返回写入成功 。

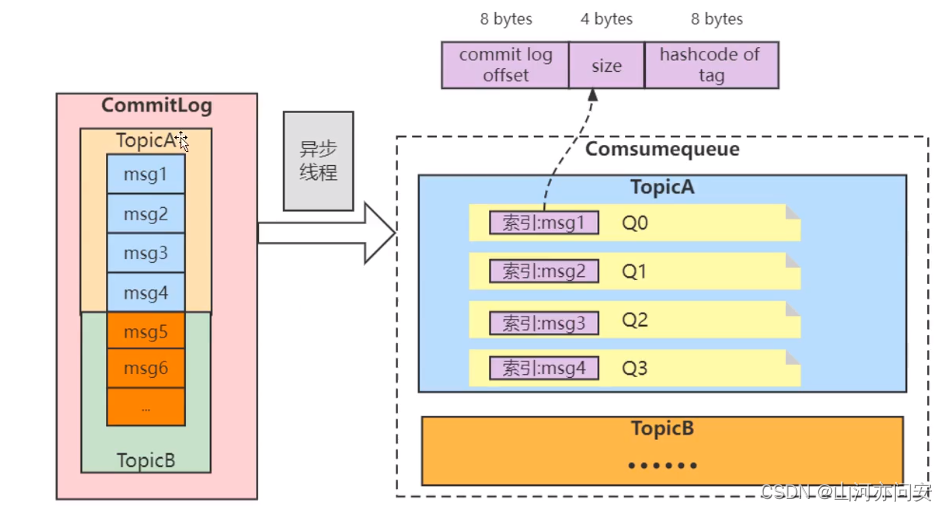
9. RocketMQ的存储机制
CommitLog: 消息主体以及元数据的存储主体,存储 Producer 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G ,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件。
ConsumeQueue: 消息消费队列,Consumer 即可根据 ConsumeQueue 来查找待消费的消息。其中,ConsumeQueue作为消费消息的索引,保存了指定 Topic 下的队列消息在 CommitLog 中的起始物理偏移量 offset ,消息大小 size 和消息 Tag 的 HashCode 值。consumequeue 文件可以看成是基于 topic 的 commitlog 索引文件。
IndexFile: IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。
10 RocketMQ性能比较高的原因
Netty高效的NIO框架,大量使用多线程异步,采用零拷贝技术MMAP,文件存储顺序读写,锁优化CAS机制无锁化,存储设计读写分离。