文章目录
- 01 引言
- 02 连接器依赖
- 2.1 kafka连接器依赖
- 2.2 base基础依赖
- 03 使用方法
- 04 序列化器
- 05 指标监控
- 06 项目源码实战
- 6.1 包结构
- 6.2 pom.xml依赖
- 6.3 配置文件
- 6.4 创建sink作业
01 引言
KafkaSink 可将数据流写入一个或多个 Kafka topic
实战源码地址,一键下载可用:https://gitee.com/shawsongyue/aurora.git
模块:aurora_flink_connector_kafka
主类:KafkaSinkStreamingJob
02 连接器依赖
2.1 kafka连接器依赖
<!--kafka依赖 start--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>3.0.2-1.18</version></dependency><!--kafka依赖 end-->
2.2 base基础依赖
若是不引入该依赖,项目启动直接报错:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/connector/base/source/reader/RecordEmitter
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-base</artifactId><version>1.18.0</version></dependency>
03 使用方法
Kafka sink 提供了构建类来创建 KafkaSink 的实例
DataStream<String> stream = ...;KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers(brokers).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic("topic-name").setValueSerializationSchema(new SimpleStringSchema()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();stream.sinkTo(sink);以下属性在构建 KafkaSink 时是必须指定的:
Bootstrap servers, setBootstrapServers(String)
消息序列化器(Serializer), setRecordSerializer(KafkaRecordSerializationSchema)
如果使用DeliveryGuarantee.EXACTLY_ONCE 的语义保证,则需要使用 setTransactionalIdPrefix(String)
04 序列化器
-
构建时需要提供
KafkaRecordSerializationSchema来将输入数据转换为 Kafka 的ProducerRecord。Flink 提供了 schema 构建器 以提供一些通用的组件,例如消息键(key)/消息体(value)序列化、topic 选择、消息分区,同样也可以通过实现对应的接口来进行更丰富的控制。 -
其中消息体(value)序列化方法和 topic 的选择方法是必须指定的,此外也可以通过
setKafkaKeySerializer(Serializer)或setKafkaValueSerializer(Serializer)来使用 Kafka 提供而非 Flink 提供的序列化器
KafkaRecordSerializationSchema.builder().setTopicSelector((element) -> {<your-topic-selection-logic>}).setValueSerializationSchema(new SimpleStringSchema()).setKeySerializationSchema(new SimpleStringSchema()).setPartitioner(new FlinkFixedPartitioner()).build();
05 容错恢复
`KafkaSink` 总共支持三种不同的语义保证(`DeliveryGuarantee`)。对于 `DeliveryGuarantee.AT_LEAST_ONCE` 和 `DeliveryGuarantee.EXACTLY_ONCE`,Flink checkpoint 必须启用。默认情况下 `KafkaSink` 使用 `DeliveryGuarantee.NONE`。 以下是对不同语义保证的解释:
DeliveryGuarantee.NONE不提供任何保证:消息有可能会因 Kafka broker 的原因发生丢失或因 Flink 的故障发生重复。DeliveryGuarantee.AT_LEAST_ONCE: sink 在 checkpoint 时会等待 Kafka 缓冲区中的数据全部被 Kafka producer 确认。消息不会因 Kafka broker 端发生的事件而丢失,但可能会在 Flink 重启时重复,因为 Flink 会重新处理旧数据。DeliveryGuarantee.EXACTLY_ONCE: 该模式下,Kafka sink 会将所有数据通过在 checkpoint 时提交的事务写入。因此,如果 consumer 只读取已提交的数据(参见 Kafka consumer 配置isolation.level),在 Flink 发生重启时不会发生数据重复。然而这会使数据在 checkpoint 完成时才会可见,因此请按需调整 checkpoint 的间隔。请确认事务 ID 的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务 不会互相影响!此外,强烈建议将 Kafka 的事务超时时间调整至远大于 checkpoint 最大间隔 + 最大重启时间,否则 Kafka 对未提交事务的过期处理会导致数据丢失。
05 指标监控
Kafka sink 会在不同的范围(Scope)中汇报下列指标。
| 范围 | 指标 | 用户变量 | 描述 | 类型 |
|---|---|---|---|---|
| 算子 | currentSendTime | n/a | 发送最近一条数据的耗时。该指标反映最后一条数据的瞬时值。 | Gauge |
06 项目源码实战
6.1 包结构
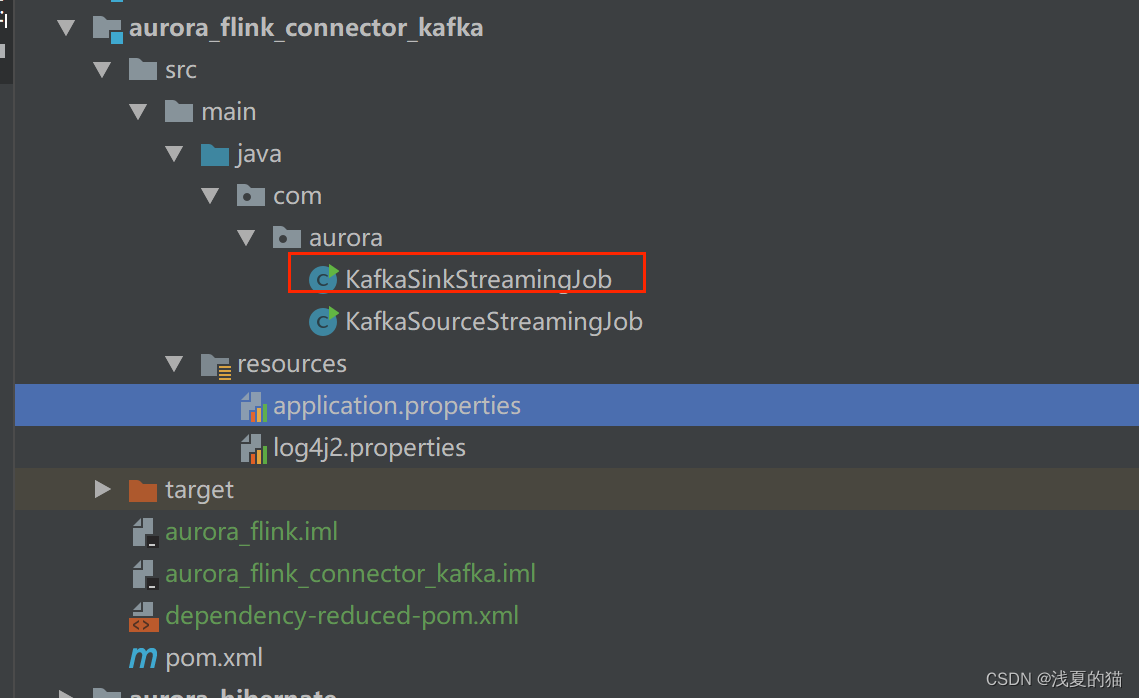
6.2 pom.xml依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.xsy</groupId><artifactId>aurora_flink_connector_kafka</artifactId><version>1.0-SNAPSHOT</version><!--属性设置--><properties><!--java_JDK版本--><java.version>11</java.version><!--maven打包插件--><maven.plugin.version>3.8.1</maven.plugin.version><!--编译编码UTF-8--><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!--输出报告编码UTF-8--><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><!--json数据格式处理工具--><fastjson.version>1.2.75</fastjson.version><!--log4j版本--><log4j.version>2.17.1</log4j.version><!--flink版本--><flink.version>1.18.0</flink.version><!--scala版本--><scala.binary.version>2.11</scala.binary.version></properties><!--通用依赖--><dependencies><!-- json --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fastjson.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><!--================================集成外部依赖==========================================--><!--集成日志框架 start--><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version></dependency><!--集成日志框架 end--><!--kafka依赖 start--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>3.0.2-1.18</version></dependency><!--kafka依赖 end--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-base</artifactId><version>1.18.0</version></dependency></dependencies><!--编译打包--><build><finalName>${project.name}</finalName><!--资源文件打包--><resources><resource><directory>src/main/resources</directory></resource><resource><directory>src/main/java</directory><includes><include>**/*.xml</include></includes></resource></resources><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>org.apache.flink:force-shading</exclude><exclude>org.google.code.flindbugs:jar305</exclude><exclude>org.slf4j:*</exclude><excluder>org.apache.logging.log4j:*</excluder></excludes></artifactSet><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>org.aurora.KafkaStreamingJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><!--插件统一管理--><pluginManagement><plugins><!--maven打包插件--><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring.boot.version}</version><configuration><fork>true</fork><finalName>${project.build.finalName}</finalName></configuration><executions><execution><goals><goal>repackage</goal></goals></execution></executions></plugin><!--编译打包插件--><plugin><artifactId>maven-compiler-plugin</artifactId><version>${maven.plugin.version}</version><configuration><source>${java.version}</source><target>${java.version}</target><encoding>UTF-8</encoding><compilerArgs><arg>-parameters</arg></compilerArgs></configuration></plugin></plugins></pluginManagement></build><!--配置Maven项目中需要使用的远程仓库--><repositories><repository><id>aliyun-repos</id><url>https://maven.aliyun.com/nexus/content/groups/public/</url><snapshots><enabled>false</enabled></snapshots></repository></repositories><!--用来配置maven插件的远程仓库--><pluginRepositories><pluginRepository><id>aliyun-plugin</id><url>https://maven.aliyun.com/nexus/content/groups/public/</url><snapshots><enabled>false</enabled></snapshots></pluginRepository></pluginRepositories></project>
6.3 配置文件
(1)application.properties
#kafka集群地址
kafka.bootstrapServers=localhost:9092
#kafka主题
kafka.topic=topic_a
#kafka消费者组
kafka.group=aurora_group
(2)log4j2.properties
rootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmprootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmp
6.4 创建sink作业
package com.aurora;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.KafkaSourceBuilder;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.runtime.state.StateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.ArrayList;/*** @author 浅夏的猫* @description kafka 连接器使用demo作业* @datetime 22:21 2024/2/1*/
public class KafkaSinkStreamingJob {private static final Logger logger = LoggerFactory.getLogger(KafkaSinkStreamingJob.class);public static void main(String[] args) throws Exception {//===============1.获取参数==============================//定义文件路径String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink_connector_kafka\\src\\main\\resources\\application.properties";//方式一:直接使用内置工具类ParameterTool paramsMap = ParameterTool.fromPropertiesFile(propertiesFilePath);//================2.初始化kafka参数==============================String bootstrapServers = paramsMap.get("kafka.bootstrapServers");String topic = paramsMap.get("kafka.topic");KafkaSink<String> sink = KafkaSink.<String>builder()//设置kafka地址.setBootstrapServers(bootstrapServers)//设置消息序列号方式.setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic(topic).setValueSerializationSchema(new SimpleStringSchema()).build())//至少一次.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();//=================4.创建Flink运行环境=================StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();ArrayList<String> listData = new ArrayList<>();listData.add("test");listData.add("java");listData.add("c++");DataStreamSource<String> dataStreamSource = env.fromCollection(listData);//=================5.数据简单处理======================SingleOutputStreamOperator<String> flatMap = dataStreamSource.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String record, Collector<String> collector) throws Exception {logger.info("正在处理kafka数据:{}", record);collector.collect(record);}});//数据输出算子flatMap.sinkTo(sink);//=================6.启动服务=========================================//开启flink的checkpoint功能:每隔1000ms启动一个检查点(设置checkpoint的声明周期)env.enableCheckpointing(1000);//checkpoint高级选项设置//设置checkpoint的模式为exactly-once(这也是默认值)env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//确保检查点之间至少有500ms间隔(即checkpoint的最小间隔)env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);//确保检查必须在1min之内完成,否则就会被丢弃掉(即checkpoint的超时时间)env.getCheckpointConfig().setCheckpointTimeout(60000);//同一时间只允许操作一个检查点env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//程序即使被cancel后,也会保留checkpoint数据,以便根据实际需要恢复到指定的checkpointenv.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);//设置statebackend,指定state和checkpoint的数据存储位置(checkpoint的数据必须得有一个可以持久化存储的地方)env.getCheckpointConfig().setCheckpointStorage("file:///E:/flink/checkPoint");env.execute();}}






![[VulnHub靶机渗透] dpwwn: 1](https://img-blog.csdnimg.cn/direct/c28880cbfe2a4faf8b7f8aa1d51ece7d.png)