一、序列模型的例子

二、数学符号定义

X^{(i)<t>}:训练样本 i 的输入序列的第 t 个元素。
T_{X}^{i}:训练样本 i 的输入序列的长度。
Y^{(i)<t>}:训练样本 i 的输出序列的第 t 个元素。
T_{Y}^{i}:训练样本 i 的输出序列的长度。
三、举例:识别人名
【输入和输出序列长度相同】
1、数据表示
准备 Vocabulary/Dictionary
将所有要用到的单词放在一起,做成清单 —— 将每个单词用一位 one-hot 表示

遇见没见过的单词,常见新标记 Unknown Word,使用 <UNK> 来表示
2. 标准神经网络存在的问题

-
对于不同的例子,输入和输出会有不同的长度
-
不共享从文本的不同位置学到的特征
3. 循环神经网络 (RNN)
(1) 构建 RNN
循环神经网络从左向右扫描数据,每一步所用的参数是共享的

缺点:只使用当前输入之前的序列信息来做预测 —— 解决方法:双向循环神经网络(BRNN)
(2) 前向传播

损失函数:
用向量简化符号:
(3)通过时间的反向传播

四、不同类型的循环神经网络

多对多型(如机器翻译)、多对一型、一对一型(标准的小型神经网络)、一对多型、注意力结构
如音乐生成: 、机器翻译:
、机器翻译: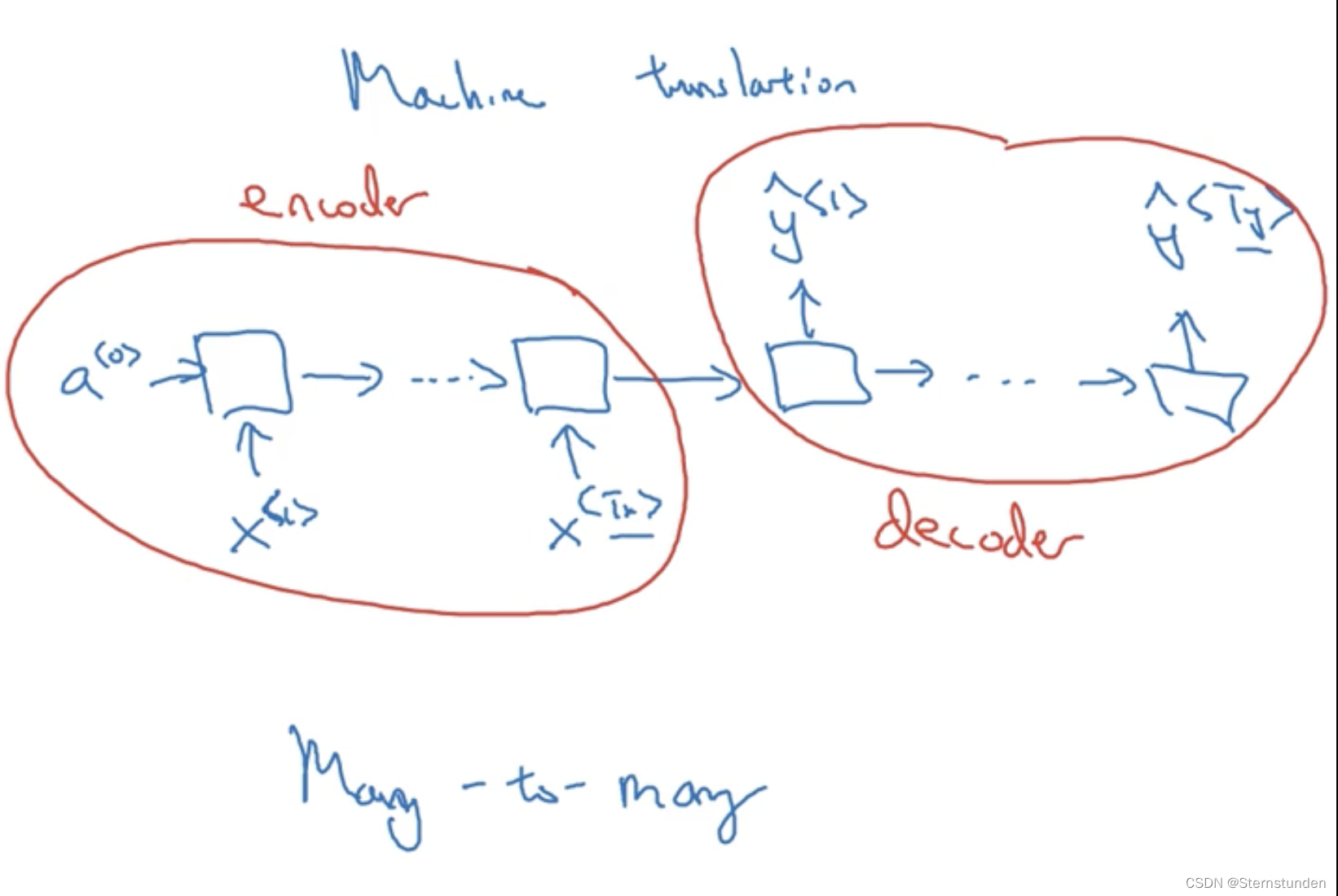
五、RNN 构建语言模型
1. 定义语言模型
用 y^{<i>} 来表示输入的文本序列 x^{<i>} = y^{<i-1>}
训练集: 大量的英文文本 语料库 (large corpus)
句子结尾:增加额外的标记 EOS (可选)
未知词:增加额外的标记 UNK
2. 建立 RNN 模型

通过前面输入的单词,预测下一个输出单词的概率。
-
定义代价函数 (softmax):
L (\overline{y}^{<t>}, y^{<t>}) = -\sum{y_{i}^{<t>} log\overline{y}_{i}^{<t>}}
L = \sum{L^{<t>} (\overline{y}^{<t>}, y^{<t>})}
-
给定新句子输出的概率:
P(y^{<1>}, y^{<2>},...,y^{<n>}) = P(y^{<1>})P(y^{<2>}|y^{<1>})...P(y^{<n>}|y^{<1>}y^{<2>}...y^{<n-1>})
3. 新序列采样
序列模型:模拟了任意特定单词序列的概率
新序列采样:对上述概率分布进行采样,根据训练好的模型,生成新的单词序列/随机的句子。

绝大多数使用基于词汇的语言模型,基于字母的语言模型将得到太长的序列,消耗算力。
六、双向循环神经网络 (BRNN)
两个前向传播:一个从前往后、一个从后往前 —— 既可知道以前的信息,也可以知道未来的信息

基本单元可以是标准 RNN 单元,也可以是 GRU 单元或 LSTM 单元
常见:带有 LSTM 单元的双向 RNN 模型
缺点:需要完整的数据序列
七、深层循环神经网络 (DRNNs)
a^{[l]<t>}:第 l 层 t 时刻的激活值

基本单元可以是标准 RNN 单元,也可以是 GRU 单元或 LSTM 单元
![[大厂实践] Netflix容器平台内核panic可观察性实践](https://img-blog.csdnimg.cn/img_convert/2a4b58f5c32cbc76b3acfb94b975b9a1.png)


![[算法前沿]--059-大语言模型Fine-tuning踩坑经验之谈](https://img-blog.csdnimg.cn/direct/fea644b86b684eb4a833e45aa5ff4932.png)




![【蓝桥杯冲冲冲】[NOIP2017 提高组] 宝藏](https://img-blog.csdnimg.cn/img_convert/0133354571d6164ee90cda7abb9e9549.png)

