引言
在机器学习的无监督学习领域,聚类算法是一种关键的技术,用于发现数据集中的内在结构和模式。与传统的基于距离的聚类方法(如K-Means)不同,密度聚类关注于数据分布的密度,旨在识别被低密度区域分隔的高密度区域。这种方法在处理具有复杂形状和大小的聚类时表现出色,尤其擅长于识别噪声和异常值。本文将详细介绍密度聚类的概念、主要算法及其应用。
一、概述
密度聚类基于一个核心思想:聚类可以通过连接密度相似的点来形成,即一个聚类是由一组密度连续且足够高的点组成的。这意味着聚类的形成不依赖于任何预定的形状,而是由数据本身的分布决定。密度聚类的优点在于它不仅能够识别出任意形状的聚类,还能在聚类过程中有效地识别并处理噪声点。
二、主要算法
2.1 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
DBSCAN是最著名的密度聚类算法之一,它根据高密度区域的连通性来进行聚类。DBSCAN的核心概念包括:
- 核心点:在指定半径( \epsilon )内含有超过最小数量( MinPts )的点。
- 边缘点:在( \epsilon )半径内点的数量少于( MinPts ),但属于核心点的邻域。
- 噪声点:既不是核心点也不是边缘点的点。
DBSCAN算法的步骤如下:
- 对每个点,计算其( \epsilon )邻域内的点数。
- 标记满足核心点条件的点。
- 对每个核心点,如果它还没有被分配到任何聚类,创建一个新的聚类,并递归地将所有密度可达的核心点添加到这个聚类。
- 将边缘点分配给相邻的核心点的聚类。
- 剩下的点标记为噪声。
2.2 OPTICS(Ordering Points To Identify the Clustering Structure)
OPTICS算法是对DBSCAN的一种改进,旨在克服DBSCAN在处理不同密度区域的数据集时的局限性。OPTICS不直接进行聚类划分,而是创建一个达到顺序的点列表,这个顺序反映了数据结构的内在聚类。通过这个列表,可以根据需要生成不同密度阈值的聚类结果。
OPTICS算法的关键在于它引入了两个新概念:
- 核心距离:对于任何核心点,其核心距离是到达( MinPts )个最近邻的距离。
- 可达距离:点A到点B的可达距离是核心点A的核心距离与A到B的实际距离中的较大值。
通过这两个度量,OPTICS评估并排序数据点,以揭示数据的聚类结构。
2.3举例
下面是一个使用Python中的sklearn库来实现DBSCAN算法的简单示例。这个例子将展示如何使用DBSCAN对二维数据进行聚类分析。
首先,我们需要安装sklearn库(如果尚未安装):
pip install scikit-learn
然后,可以使用以下代码来生成一些模拟数据并应用DBSCAN算法进行聚类:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN# 生成模拟数据
X, _ = make_moons(n_samples=300, noise=0.1, random_state=42)# 应用DBSCAN算法
# eps: 邻域的大小
# min_samples: 形成一个簇所需的最少样本点数
dbscan = DBSCAN(eps=0.2, min_samples=5)
dbscan.fit(X)# 获取聚类标签
labels = dbscan.labels_# 绘制结果
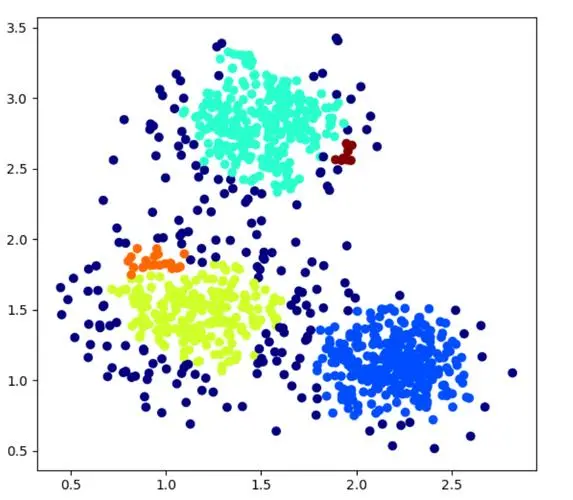
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', marker='o', s=50, edgecolor='k')
plt.title('DBSCAN Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.colorbar()
plt.show()# 打印噪声点(标记为-1的点)
noise = np.sum(labels == -1)
print(f"Detected noise points: {noise}")
在这个例子中,我们首先使用make_moons函数生成了300个样本点,这些点形成了两个半圆形(或称为月牙形)的分布,这是一个非常典型的用于测试聚类算法性能的数据集,因为它的聚类结构不是全局线性可分的。
接着,我们创建了一个DBSCAN实例,并设置了两个关键参数:eps和min_samples。eps参数定义了搜索邻居的半径大小,而min_samples定义了一个区域内点的最小数量,这个数量足以让这个区域被认为是一个密集区域。通过调整这两个参数,可以控制聚类的粒度。
最后,我们使用.fit()方法对数据进行拟合,并通过.labels_属性获取每个点的聚类标签。我们使用matplotlib库绘制了聚类结果,并通过颜色区分了不同的聚类。
三、密度聚类的应用
密度聚类在许多领域都有广泛的应用,特别是在那些传统聚类方法难以处理的复杂数据集中。以下是一些典型的应用场景:
- 异常检测:通过识别噪声点,密度聚类可以用于识别异常值或离群点。
- 地理空间数据分析:如根据地理位置信息对地点进行聚类,找出热点区域。
- 生物信息学:在基因表达数据分析中,密度聚类能够帮助识别具有相似表达模式的基因。
- 图像分割:将图像分割成若干区域,每个区域由相似密度的像素点组成。

四、结语
密度聚类提供了一种强大的工具,用于发现数据集中的自然聚类和噪声点。通过关注数据的局部密度特征,它能够识别出任意形状的聚类,并有效处理噪声和异常值。DBSCAN和OPTICS等算法的发展,使得密度聚类成为处理复杂数据集的有力方法。随着数据科学领域的不断进步,密度聚类仍将是未来数据分析和模式识别研究的重要方向之一。








![[office] 怎么在Excel2003菜单栏自定义一个选项卡 #其他#微信#知识分享](https://img-blog.csdnimg.cn/img_convert/55b73e208349e2367688f1525240527f.jpeg)