作者:来自 Elastic Jeff Vestal

本博客在第 1 部分的基础上进行了扩展,介绍了基于 RAG 的搜索系统的功能齐全的 Web UI。最后,你将拥有一个将检索、搜索和生成过程结合在一起的工作界面,同时使事情易于调整和探索。
不想读完整个内容?没问题,去克隆应用程序并开始搜索!
在第 1 部分中,我们介绍了如何设置搜索索引、使用 Open Crawler 抓取 Elastic 博客内容、为 LLM 配置推理 API,以及如何在 Kibana 中使用 Elastic 的 Playground 测试我们的 RAG 设置。
现在,在第 2 部分中,我将履行本博客结尾处的承诺,返回一个功能齐全的 Web UI!
本指南将引导你完成:
- 应用程序的工作原理。
- 用户可用的关键控制和自定义选项。
- 改进搜索、检索和响应生成的增强功能。
应用程序的功能概述
从高层次来看,该应用程序接收用户的搜索查询或问题,并按照以下步骤进行:
- 使用混合搜索(结合文本匹配和语义搜索)检索相关文档。
- 显示匹配的文档摘要,并提供指向完整内容的链接。
- 使用检索到的文档和预定义的指令构建提示。
- 从大型语言模型(LLM)生成响应,并提供来自 Elasticsearch 结果的相关文档作为支撑。
- 提供控制选项,允许用户修改生成的提示和 LLM 的响应。
探索 UI 控件
该应用程序提供了多种控件来优化搜索和响应生成。以下是主要功能的细分:

- 1 搜索框
用户像使用搜索引擎一样输入查询。 查询通过词汇和向量搜索进行处理。
- 2 生成的响应面板
显示基于检索文档生成的 LLM 响应。 用于生成响应的来源会列出以供参考。 包括展开/收起切换按钮以调整面板大小。
- 3 Elasticsearch 结果面板
展示从Elasticsearch检索的排名靠前的文档。 包括文档标题、高亮部分和指向原始内容的链接。 帮助用户查看哪些文档影响了LLM的响应。
- 4 源过滤控制
用户可以在初次搜索后选择使用哪些数据源进行检索。 这允许用户专注于特定领域的内容。
- 5 源过滤控制
用户可以选择是否允许 LLM 在生成响应时使用其训练数据,而不依赖于基础上下文。 这为生成超出传递给 LLM 内容的扩展答案提供了可能性。
- 6 来源数量选择器
允许用户调整传递给 LLM 的结果数量。 增加来源通常有助于提高响应的基础,但过多的来源可能会导致不必要的 token 费用。
- 7 块与文档切换按钮
决定是否使用完整文档或相关的分块内容作为推理的基础。 通过将长文本分解成可管理的部分,分块提高了搜索的粒度。
- 8 LLM 提示面板
允许用户查看传递给 LLM 以生成响应的完整提示。 帮助用户更好地理解答案是如何生成的。
应用程序架构
该应用程序是一个 Next.js Web 应用程序,它提供了与基于 RAG 的搜索系统交互的用户界面。
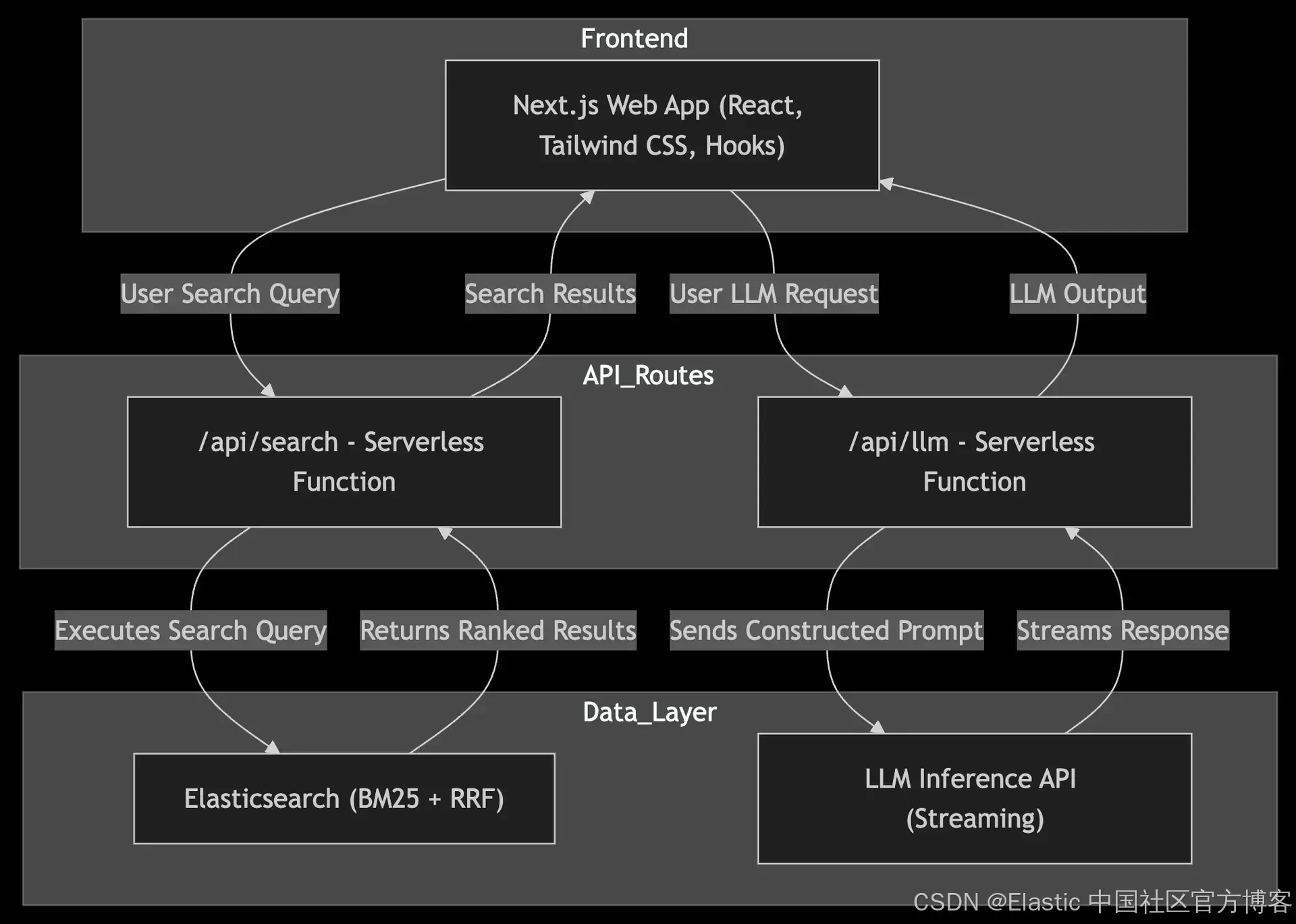
这种架构消除了对单独后端服务的需求,利用 Next.js API 路由实现无缝搜索和 LLM 处理集成。
代码片段
让我们看一下与该应用程序最相关的几个代码段,如果你想修改它以使用不同的数据集,这些代码段可能会很有用。
ES 查询
Elasticsearch 查询非常简单。
/app/api/search/route.ts
const esQuery: any = {retriever: {// hybrid search retriever using reciprocal rank fusionrrf: {retrievers: [// Standard lexical search across multiple fields. Boosting `body`{ standard: { query: { multi_match: { query, fields: ["body^2", "title", "meta_description"] } } } },// Semantic search on the semantic representation of the body text{ standard: { query: { semantic: { field: "semantic_body", query } } } },],rank_constant: 1, // Controls how aggressively ranking adjusts across retrieversrank_window_size: 50, // Number of documents considered for RRF ranking},},_source: false, // Exclude _source to minimize response sizefields: ["title", "url_path", "url_path_dir1.keyword", "body", "semantic_body"], // Return only necessary fieldshighlight: {fields: {body: {}, // Return matched text in the `body` semantic_body: { type: "semantic", number_of_fragments: 2, order: "score" }, // Return semantically relevant chunks},},aggs: {lab_sources: { terms: { field: "url_path_dir1.keyword" } }, // Aggregation to get the list of blog sites},
};
通过使用混合检索器,我们可以支持基于关键词的搜索以及更符合自然语言的问题搜索,而这正逐渐成为人们日常搜索的常态。
你会注意到,在这个查询中我们使用了高亮(highlight)功能。这使我们能够在 Elasticsearch 结果部分轻松提供匹配文档的相关摘要。同时,当我们构建 LLM 的提示词并选择使用匹配片段作为支撑时,高亮功能还能帮助我们利用这些匹配片段进行内容补充。
提取 Elasticsearch 结果
接下来,我们需要从 Elasticsearch 中提取结果
/app/api/search/route.ts
// Extract Hits
const rawHits = result?.body?.hits?.hits || result?.hits?.hits;if (!rawHits || !Array.isArray(rawHits)) {console.error("⚠️ Unexpected Elasticsearch response format:", JSON.stringify(result, null, 2));return NextResponse.json({error: "Unexpected response format from Elasticsearch", response: result},{status: 500});
}我们从 Elasticsearch 响应中提取搜索结果(hits),确保它们存在并以预期的数组格式返回。
如果结果缺失或格式不正确,我们将记录错误并返回 500 状态码。
解析搜索结果(hits)
我们已经获取了搜索结果,但需要将其解析为可用于在 UI 中显示给用户的格式,并用于构建 LLM 的提示词。
/app/api/search/route.ts
// Process search hits into frontend-friendly format
const results = rawHits.map((hit: any, index: number) => {const main_text = hit.highlight?.semantic_body?.[0] || "No preview available"; // Always for UI displayconst prompt_context = useChunk? hit.highlight?.semantic_body?.[0] || "No chunk content available" // Use highlighted chunk: hit.fields?.body?.[0] || "No full document content available"; // Use full document textreturn {id: hit._id || `hit-${index}`,title: hit.fields?.title?.[0] || "Untitled",url_path: hit.fields?.url_path?.[0]?.startsWith("https://www.elastic.co")? hit.fields?.url_path?.[0]: `https://www.elastic.co${hit.fields?.url_path?.[0] || "#"}`,main_text, // Always uses highlight.semantic_body for UIprompt_context, // This will be used in the LLM promptcitations: hit.highlight?.body || [],};
});在这段代码中,发生了几个关键操作:
- 我们使用
semantic_body的顶级匹配高亮内容作为每个 Elasticsearch 文档的摘要片段进行显示。 - 根据用户的选择,我们将提示上下文存储为
semantic_body(作为片段)或完整的body(作为正文)。 - 提取
title(标题)。 - 提取博客的 URL,并确保其格式正确,以便用户可以点击访问博客。
实验来源点击处理
最后的处理步骤是解析聚合值。
/app/api/search/route.ts
// Extract Aggregations (Lab Sources)
console.log("📊 Extracting Aggregation Data...");
const aggregationData = result?.aggregations?.lab_sources?.buckets;if (!aggregationData || !Array.isArray(aggregationData)) {console.warn("⚠️ Aggregation data is missing or not in expected format!");
} else {console.log("✅ Raw Aggregation Buckets:", JSON.stringify(aggregationData, null, 2));
}const labSources = aggregationData?.map((bucket: any, index: number) => ({id: index + 1,text: bucket.key,checked: true,
})) || [];
我们这样做是为了提供一个可点击的 “Labs” 来源列表,方便用户查看搜索结果的来源。这样,用户可以选择他们想要包含的特定来源,并在重新搜索时,已选中的实验室将作为过滤条件。
状态管理
SearchInterface 组件是应用的核心组件。它使用 React 的状态管理钩子来处理所有数据和配置。
/components/SearchInterface.tsx
const [searchResults, setSearchResults] = useState<any[]>([]);
const [generatedResponse, setGeneratedResponse] = useState("");
const [generatedPrompt, setGeneratedPrompt] = useState("");
const [numSources, setNumSources] = useState(3);
const [useChunk, setUseChunk] = useState(true);前面三行用于跟踪 Elasticsearch 的搜索结果、LLM 生成的响应,以及用于指示 LLM 的生成提示词。
最后两行用于跟踪用户在 UI 中的设置,包括:
- 选择用于 LLM 支撑的来源数量。
- 决定 LLM 是仅使用匹配片段(chunks)进行支撑,还是使用完整的博客文章。
处理搜索查询
当用户点击提交按钮时,handleSearch 函数接管搜索流程。
/components/SearchInterface.tsx
const handleSearch = async (query: string) => {console.log(`🔍 Sending search request for query: "${query}"`);setGeneratedResponse("");setGeneratedPrompt(""); const selectedSources = labSources.filter((source) => source.checked).map((source) => source.text);try {const response = await fetch("/api/search", {method: "POST",headers: {"Content-Type": "application/json"},body: JSON.stringify({query,apiKey,apiUrl,selectedLabSources: selectedSources,numSources,useChunk,}),});const data = await response.json();setSearchResults(data.results);
该函数将查询发送到 /api/search(如前面的代码片段所示),并包括用户选择的来源、支撑设置以及 API 凭证。响应被解析并存储在状态中,从而触发 UI 更新。
来源提取
在获取到搜索结果后,我们会创建一个 sources 对象。
/components/SearchInterface.tsx
const sources = data.results.slice(0, numSources).map((doc, index) => ({id: `Source ${index + 1}`,title: doc.title,url: doc.url_path,content: doc.prompt_context,
}));
这个 sources 对象稍后将作为提示的一部分传递给 LLM。LLM 会被指示在生成响应时引用它所使用的任何来源。
构建和发送 LLM 提示
提示是基于用户的设置动态生成的,并且包括来自 Elasticsearch 的支撑文档。
/components/SearchInterface.tsx
const promptInstruction = useContextOnly? `ONLY use the provided documents for your response. Do not use any prior knowledge. If the answer is not in the provided documents return "I'm unable to provide an answer using the included context." Cite ONLY the sources you actually reference in your response.`: `Prefer using the provided documents, but if they lack sufficient details, you may use prior knowledge. If you do, explicitly state: "[This response includes knowledge beyond the provided context.]" Cite ONLY the sources you actually reference in your response.`;// ✅ Sources list (for reference) — LLM will decide what to cite
const sourcesList = sources.map((source) => `- **${source.id}**: ${source.title} (${source.url})`).join("\n");const prompt = `The user has asked a question: ${query}. Use the following documents to answer the question:${formattedDocs}${promptInstruction}Format the response with:- Proper Markdown headings (### for sections)- Clear bullet points for lists- Extra line breaks for readability- Paragraph spacing between sections- **At the end of the response, include a "*Sources Used*" section listing ONLY the document titles that were actually referenced.**### Sources Used:(Only include sources that were directly referenced in your response.)`;console.log("📤 Sending prompt to LLM:", prompt);
setGeneratedPrompt(prompt); // ✅ Store the generated prompt for UI display
streamLLMResponse(prompt);} catch (error) {console.error("❌ Error fetching search results:", error);
}默认情况下,我们指示 LLM 仅使用提供的支撑文档来生成答案。然而,我们也提供了一个设置,允许 LLM 使用其自身的训练 “知识” 来构建更广泛的响应。当允许 LLM 使用其自身的训练时,还会进一步指示它在响应的末尾附加警告。
我们指示 LLM 引用所提供的文档作为来源,但仅限于它实际使用的文档。
我们还提供了一些关于如何格式化响应的指令,以便在 UI 中提高可读性。
最后,我们将其传递给 /api/llm 进行处理。
流式传输 AI 响应
在 Elasticsearch 的文档被解析并立即返回到前端之后,我们调用 LLM 来生成对用户问题的回答。
/components/SearchInterface.tsx
const streamLLMResponse = async (prompt: string) => {try {const response = await fetch("/api/llm", {method: "POST",headers: {"Content-Type": "application/json"},body: JSON.stringify({prompt, apiKey, apiUrl}),});if (!response.body) throw new Error("LLM response body is empty");const reader = response.body.getReader();const decoder = new TextDecoder();let resultText = "";const processStream = async () => {while (true) {const {value, done} = await reader.read();if (done) break;const chunk = decoder.decode(value, {stream: true});// 🛠️ Parse each eventchunk.split("\n").forEach((line) => {if (line.startsWith("data:")) {try {const jsonData = JSON.parse(line.replace("data: ", "").trim());if (jsonData.completion) {const deltaText = jsonData.completion.map((c: any) => c.delta).join("");resultText += deltaText;// Update state dynamicallysetGeneratedResponse((prev) => prev + deltaText);}} catch (error) {console.error("⚠️ Error parsing LLM event stream:", error);}}});}};await processStream();console.log("✅ LLM Streaming Complete:", resultText);} catch (error) {console.error("❌ Error streaming LLM response:", error);}
};
这部分代码虽然有很多行,但本质上是调用 /api/llm(稍后会详细介绍)并处理流式响应。我们希望 LLM 的响应能够在生成时流式返回到 UI,因此我们在每次返回事件时解析它,允许 UI 动态更新。
我们需要解码流,进行一些清理操作,并用新接收到的文本更新 resultText。
调用 LLM
我们通过 Elasticsearch 的推理 API 调用 LLM。这使我们能够将数据的管理集中在 Elasticsearch 中。
/app/api/llm/route.ts
const response = await fetch(`${apiUrl}/_inference/completion/azure_openai_gpt-4o/_stream`, {method: "POST",headers: {"Content-Type": "application/json",Authorization: `ApiKey ${apiKey}`,},body: JSON.stringify({ input: prompt }),
});这段代码相对简单。我们将请求发送到我们在设置过程中创建的流式推理 API 端点(见下文的 “让系统运行” 部分),然后将流式响应返回。
处理流
我们需要按块读取流数据,逐块接收并处理它。
/app/api/llm/route.ts
const reader = response.body.getReader();
const decoder = new TextDecoder();
const stream = new ReadableStream({start(controller) {async function push() {while (true) {const { value, done } = await reader.read();if (done) {controller.close();return;}controller.enqueue(decoder.decode(value, { stream: true }));}}push();},
});在这里,我们逐块解码流式返回的 LLM 响应,并将每个解码部分实时转发到前端。
让系统运行
现在我们已经审查了代码中的一些关键部分,让我们来安装并启动系统。
Completion Inference API
如果你尚未在 Elasticsearch 中配置完成推理 API,你需要先进行配置,以便能够生成对用户问题的回答。
我使用了 Azure OpenAI 并选择了 gpt-4o 模型,但你应该也能够使用其他服务。关键是它必须是支持流式推理 API 的服务。
PUT _inference/completion/azure_openai_completion
{"service": "azureopenai","service_settings": {"api_key": "<api_key>","resource_name": "<resource_name>","deployment_id": "<deployment_id>","api_version": "2024-02-01"}
}service_settings 的具体配置取决于你使用的服务和模型。有关更多信息,请参考推理 API 文档。
克隆
如果你已安装并配置了 GitHub CLI,你可以将 UI 仓库克隆到你选择的目录中。
git clone git@github.com:jeffvestal/rag-really-tied-the-app-together.git你也可以下载 zip 文件,然后解压它。
安装依赖项
按照 repo 中的 readme 文件中的步骤安装依赖项。
启动开发服务器
我们将以开发模式运行。这通过实时重新加载和调试来运行。有一种生产模式,可以运行优化的生产版本以供部署。
要以开发模式启动,请运行:
npm run dev这将启动服务器,如果没有错误,你将看到类似以下内容:
(rag-ties-the-app-together-frontend) rag-ties-the-app-together-frontend ❯ npm run dev> rag-ties-the-app-together-frontend@0.1.0 dev
> next dev▲ Next.js 14.2.16- Local: http://localhost:3000✓ Starting...✓ Ready in 1190ms如果你正在使用端口 3000 运行其他程序,则你的应用程序将开始使用下一个可用端口。只需查看输出即可了解它使用了哪个端口。如果你希望它在特定端口上运行,比如 4000,你可以运行以下命令:
PORT=4000 npm run dev进入用户界面
应用程序运行后,你可以尝试不同的配置以查看哪种配置最适合你。
连接设置
使用该应用程序之前你需要做的第一件事是设置你的连接凭据。为此,请单击右上角的齿轮图标⚙️。
当框弹出时,输入你的 API Key 和 Elasticsearch URL。

默认值
要开始,只需提出问题或在搜索栏中输入搜索查询。其余一切保持原样。

该应用程序将查询 Elasticsearch 以查找最相关的文档,在上面有关 rrf 的示例中,使用 rrf!包含简短片段、博客标题和可点击 URL 的文档将返回给用户。

前面提到的前三个片段将与一个提示一起组合,并发送给 LLM。生成的响应将以流式方式返回。
自定义游戏
一旦初始搜索结果和生成的响应显示出来,用户可以进行跟进,并对设置做出一些更改。

实验室来源 - Lab sources
所有在索引中搜索的博客站点将列在 “Lab Sources” 下。如果你在第一部分使用 Open Crawler 创建的索引中添加了额外的站点或来源,它们会显示在这里。
你可以选择仅包含你希望在搜索结果中考虑的来源,并重新点击搜索。随后的搜索将使用选中的来源作为 Elasticsearch 查询的过滤条件。
答案来源 - Anwer source
我们在 RAG(检索增强生成)中提到的一个优势是向 LLM 提供支撑文档。这有助于减少幻觉(虽然没有什么是完美的)。然而,你可能希望允许 LLM 使用其训练和其他 “知识”,超出支撑文档的内容来生成响应。取消勾选 “Context Only” 选项将允许 LLM 自由使用其自身的知识。
LLM 应在响应的末尾提供警告,告诉你是否在支撑文档之外进行了推理。正如许多 LLM 的行为一样,这并不是绝对保证的。因此,对于这些响应,还是要谨慎使用。
来源数量 - Number of sources
我们默认使用三个片段作为 LLM 的支撑信息。增加上下文片段的数量有时能为 LLM 提供更多的信息来生成响应。有时,提供整个关于某个专门主题的博客效果最佳。
这取决于主题的分布。一些主题会在多个博客中以不同的方式进行讨论。因此,提供更多来源可以产生更丰富的回答。对于某些更加深奥的主题,可能只会在一个博客中涉及,额外的片段可能不会有帮助。
片段或文档 - Chunk or doc
关于来源数量,将所有信息都传递给 LLM 通常不是生成答案的最佳方式。虽然大多数博客相比于许多其他文档来源相对较短,比如健康保险政策文件,但将长文档直接传递给 LLM 有几个缺点。首先,如果相关信息只在两段中,然而你提供了二十段,那么你就为十八段无用的内容付费。其次,这些无用信息会减慢 LLM 生成响应的速度。
通常,除非有充分的理由发送整个文档(在本例中是博客),否则最好坚持使用片段。
结语
希望这份操作指南帮助你确保在设置一个能够提供从 Elasticsearch 检索到的语义文档和由 LLM 生成的答案的 UI 时,不会感到陌生。
当然,我们可以添加很多功能,并调整一些设置,以使体验更加完善。但这已经是一个不错的开始。提供代码给社区的好处是,你可以根据自己的需求自由定制和调整。
敬请关注第 3 部分,我们将使用 Open Telemetry 对应用程序进行监控!
Elasticsearch 已经与行业领先的生成 AI 工具和服务提供商进行了原生集成。查看我们关于如何超越 RAG 基础,或如何构建生产就绪应用程序 Elastic 向量数据库的网络研讨会。
要为你的用例构建最佳搜索解决方案,可以开始免费云试用,或立即在本地机器上尝试 Elastic。
原文:ChatGPT and Elasticsearch revisited: Part 2 - The UI Abides - Elasticsearch Labs







![[Web 信息收集] Web 信息收集 — 手动收集域名信息](https://i-blog.csdnimg.cn/direct/2ba1ff7986ff497c8754a12e478ccfa5.png)











