新零售商业模式
商业模式通常是由客户价值、企业资源和能力、盈利方式三个方面构成。其最主要的用途是为实现客户价值最大化。
商业模式通过把能使企业运行的内外各要素整合起来,从而形成一个完整的、高效率的、具有独特核心竞争力的运行系统,并通过最优实现形式满足客户需求、实现客户价值,同时促使系统达成持续赢利目标。
如果想测试自己商业模式的可行性,就需要了解另一个概念——商业模式画布,英文缩写BMC。BMC的核心作用之一便是帮助创业者测试自己商业模式的可行性,从而帮助创业者避免挥霍资金或者盲目地叠加功能。
BMC主要由九个要素组成,分别是客户细分、价值主张、渠道通路、客户关系、核心资源、重要合作、关键业务、成本结构、收入来源。
BMC做为通用的商业逻辑,在新零售中也同样适用,不同的是新零售的商业模式,会结合零售行业自身的特点,以及新零售的发展特征。
其中客户细分没有必要、渠道通路和关键业务走向趋同、收益来源和成本结构大同小异,所以新零售的BMC其实主要集中在六个要素上。
表1-1 新零售的BMC

好的商业模式,各要素之间是相互促进的。新零售的商业模式又需要具备怎样的思维来实现“1+1>2”的效应呢?
升维体验
了解升维体验之前,先来聊聊“降维打击”。该词出自中国科幻作家刘慈欣的经典作品《三体》,书中是指外星人使用“二向箔”将太阳系由三维空间降至二维空间的一种攻击方式。
现在多用来指改变对方所处环境,使其无法适应,从而凸显出己方的优越性,属于一种战略手段。
随着互联网的高速发展,带来一系列的变更,使得“降维打击”无处不在,想要生存就先要“升维思考”。
传统的零售业,借助信息不对称,价差这样的所谓优势维度去打击竞争对手,即价格战,已经是很低的维度了。
而新零售想要继续向前,需要自己从这个圈子里跳出来,站在更高的维度、更多的维度去思考问题,找到核心优势。也就是我们接下来要讨论的“升维”。
升维主要有三种模式:体验升维、营销升维、价值升维。新零售的升维主要是围绕着升维体验的变革。
升维体验,包含三个维度:消费场景、数据赋能、会员营销,传统的零售企业会在三个维度任选其一。新零售以互联网技术为基础,将不同维度的体验进行升维,从而形成体验之间“1+1>2”的协同效应。
今天,主要围绕“数据赋能”这个维度,深入讨论,新零售如何在这个维度上深耕。
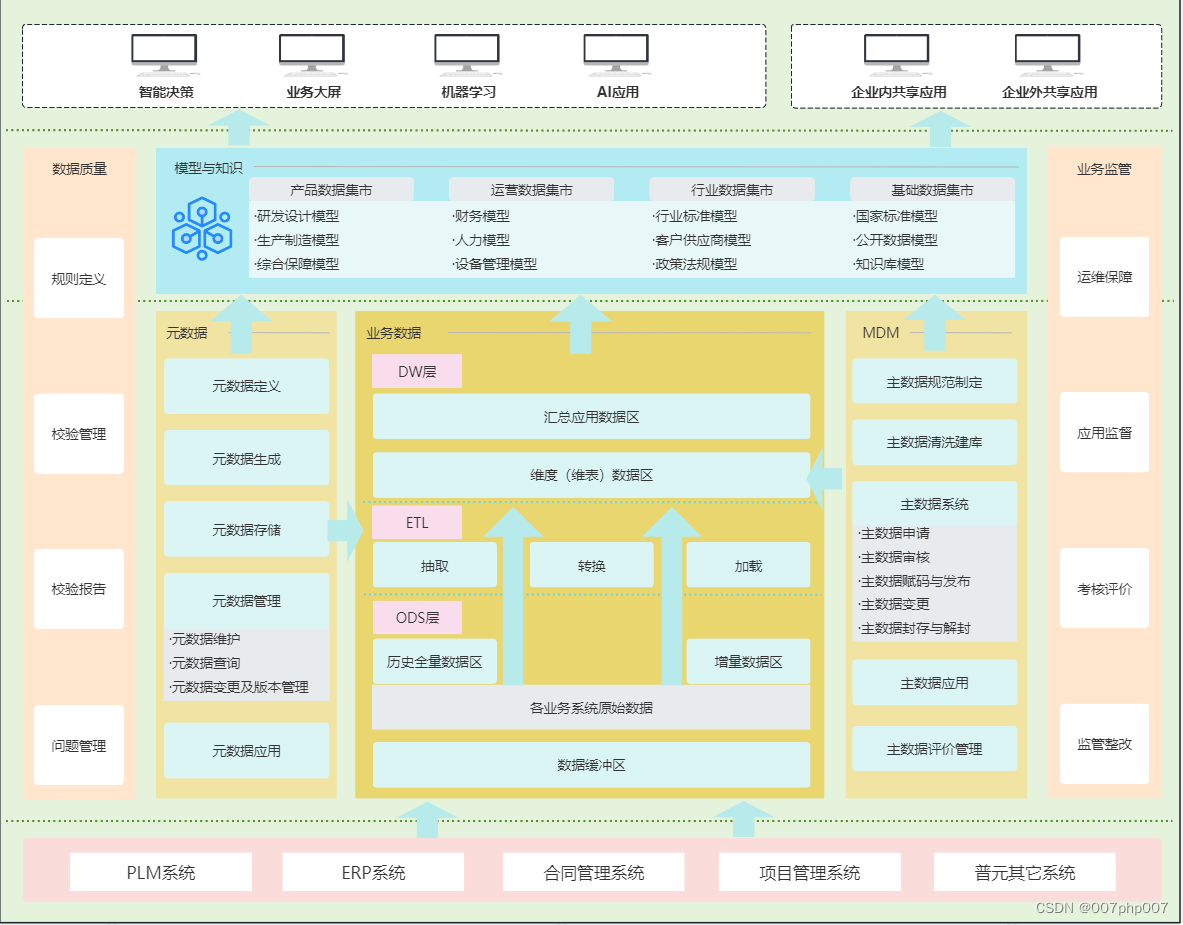
大数据平台
我们自己的数据资产,主要通过自有的大数据平台采集数据,数据类型主要包括用户画像的各种属性:社会属性、生活习惯、消费行为等。
此外,还会有各式各样的活动数据、评价信息、消息订阅数据、线上数据库、线下数据库、客服信息等,组成了庞大而复杂的数据源。
我们尝试通过用户的浏览数据、购买数据、或者评价信息,形成用户的购物画像,进而更加精准的推送信息。
这一系列的尝试,都源于“数据”的采集。数据被采集之后,最终被存储在我们的数据仓库中,从而拥有属于我们自己的大数据平台。
随着云技术的升级,云平台逐渐成为我们的首选数据仓库。
图1-2 数据赋能的四个基础工作

GaussDB:数据库上云的优先选择
华为云GaussDB,为企业核心业务数字化转型提供了坚实数据底座。它具有高安全、高性能、高可用、高弹性、高智能等五个方面的强大优势。

作为国内首个AI-Native数据库,华为云GaussDB提供了全流程智能化,支持智能索引推荐、智能分布列推荐、智能故障根因分析等,诊断效率提升5倍以上。
对于业务中常见的核心系统超高并发、海量存储,业务低时延等高要求问题,提供了解决方案:
- 可靠性:具备PB级海量数据存储能力和企业级高可靠能力
- 时延低:采用Ustore存储引擎,8H滚降值降低81%,存储空间降低17%
- 服务高连续性:业务不中断,主备集群满足金融核心应用7*24小时服务连续性要求
数据库系统
华为云GaussDB提供了两种类型的数据库实例类型:主备版和分布式。
1、主备版

2、分布式

综合两种的特点,分布式更符合我们的业务需要。
数据库使用
创建数据库用户
创建了一个用户名为yeyiyi,密码为********的用户:
gaussdb=# CREATE USER yeyiyi WITH PASSWORD "********";创建和管理数据库
使用如下命令创建一个新的数据库db_goods。
gaussdb=# CREATE DATABASE db_goods;规划存储模型
1、行存表
默认创建表的类型。数据按行进行存储,即一行数据是连续存储。适用于对数据需要经常更新的场景。
gaussdb=# CREATE TABLE good_t1
(good_ID CHAR(2),good_NAME VARCHAR2(40)
);2、列存表
数据按列进行存储,即一列所有数据是连续存储的。单列查询IO小,比行存表占用更少的存储空间。适合数据批量插入、更新较少和以查询为主统计分析类的场景。列存表不适合点查询。
gaussdb=# CREATE TABLE good_t2
(good_ID CHAR(2),good_NAME VARCHAR2(40)
)
WITH (ORIENTATION = COLUMN);数据库对象设计
华为云GaussDB还提供了开发设计建议,主要包括用户遵守的设计规则,这些规则能够保证业务的高效运行。
其中,数据库对象设计给了我许多开发灵感。
数据库对象设计包括:database和schema设计、表设计、字段设计、约束设计、视图和关联表设计。
1、database和schema设计中:华为云GaussDB给出了一个非常好的建议:从便捷性和资源共享效率上考虑,推荐使用Schema进行业务隔离。
2、表设计中:关于选择分区方案的建议,给了我一个提醒:将分区上边界的分区值定义为MAXVALUE,以防止可能出现的数据溢出。
CREATE TABLE good_d1
(
G_GOOD_SK INTEGER NOT NULL,
G_GOOD_ID CHAR(16) NOT NULL,
G_GOOD_NAME VARCHAR(20)
)DISTRIBUTE BY RANGE(G_GOOD_ID)
(SLICE s1 VALUES LESS THAN (10) DATANODE dn1,SLICE s2 VALUES LESS THAN (MAXVALUE) DATANODE dn2
);3、字段设计中:对于字符串数据的建议也十分中肯,之前业务中确实出现过类似问题。它的建议是:使用变长字符串数据类型,并指定最大长度。指定的最大长度大于需要存储的最大字符数,可避免超出最大长度时出现字符截断现象。
CREATE TABLE ExampleTable (PriKey int PRIMARY KEY, VarCharCol national character varying(10)) 4、约束设计中:对于,而列存表不支持检查约束的情况,给出了很好的建议:从命名上明确标识检查约束,例如,将检查约束命名为 “CK+字段名”。
5、视图和关联表设计中:视图设计的建议,提醒了我再设计时注意尽量避免视图嵌套,除非视图之间存在强依赖关系。
总结
本文从新零售商业模式开篇,引入升维体验的话题,主要是为了数据赋能做铺垫。
传统零售企业想要在“降维打击”有所突破,需要转换新思路——“升维打击”。而新零售的升维主要是围绕着升维体验的变革。
升维体验主要包括三个维度:消费场景、数据赋能、会员营销。传统的零售企业会在三个维度任选其一。新零售以互联网技术为基础,将不同维度的体验进行升维,从而形成体验之间“1+1>2”的协同效应。
依托于互联网技术的日益强大,数据赋能的深耕也有了更多的可选性。
数据赋能的基础是数据采集和数据存储,我们拥有自己独特的数据源,但是数据仓库却是可以多选的。随着云技术的升级,云平台逐渐成为我们的首选数据仓库。
借助华为云GaussDB的强助力,未来,我们的升维体验一定会有更多的突破。
作者:非职业「传道授业解惑」的开发者叶一一
简介:「趣学前端」、「CSS畅想」系列作者,华夏美食、国漫、古风重度爱好者,刑侦、无限流小说初级玩家。
如果看完文章有所收获,欢迎点赞👍 | 收藏⭐️ | 留言📝。