本篇文章主要记录DolphinScheduler-3.2.0 集群部署流程。
注:参考文档:
DolphinScheduler-3.2.0生产集群高可用搭建_dophinscheduler3.2.0 使用说明-CSDN博客文章浏览阅读1.1k次,点赞25次,收藏23次。DolphinScheduler-3.2.0生产集群高可用搭建,DolphinScheduler原数据存储mysql设置,分布式存储采用hdfs高可用集群_dophinscheduler3.2.0 使用说明https://blog.csdn.net/Brother_ning/article/details/135149045?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170748435816800213031806%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170748435816800213031806&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-135149045-null-null.142%5Ev99%5Epc_search_result_base1&utm_term=dolphinscheduler3.2.0%E5%AE%89%E8%A3%85&spm=1018.2226.3001.4187
一、基础环境准备
1.1 组件下载地址
DolphinScheduler-3.2.0官网下载地址:
https://dolphinscheduler.apache.org/zh-cn/download/3.2.0![]() https://dolphinscheduler.apache.org/zh-cn/download/3.2.0
https://dolphinscheduler.apache.org/zh-cn/download/3.2.0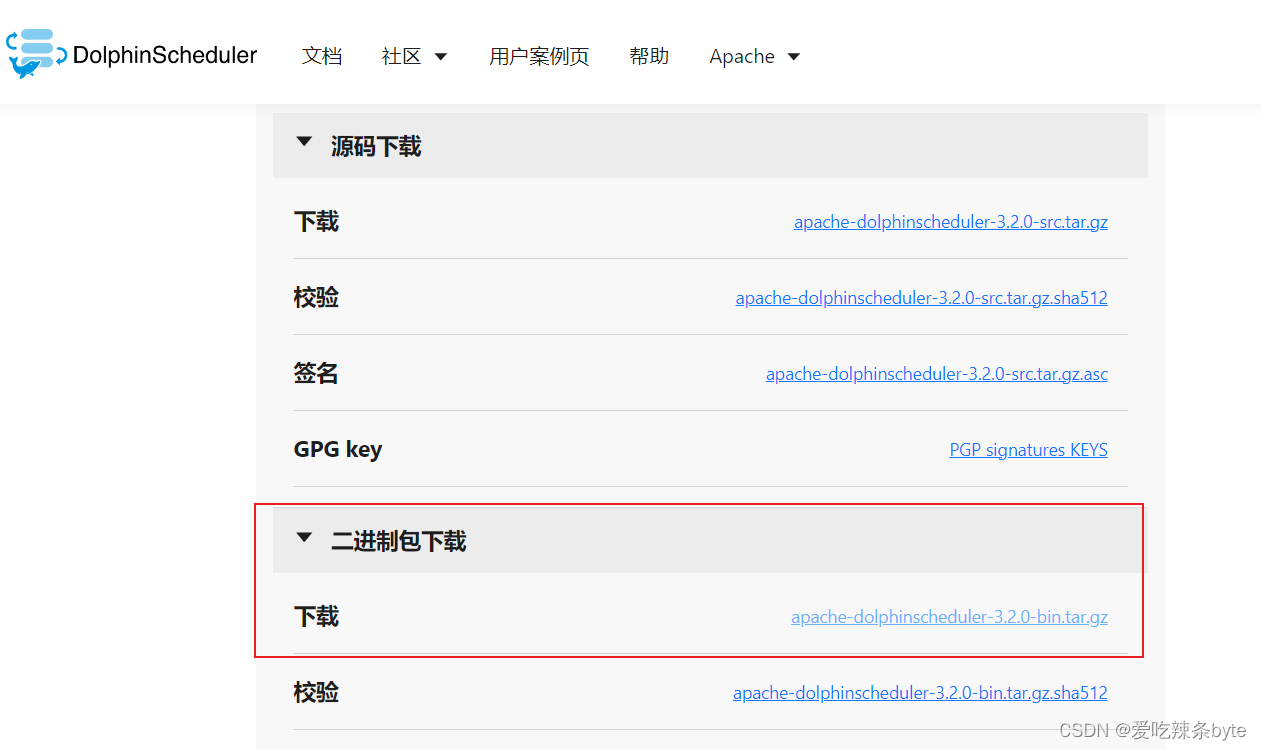
官网安装文档:https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/guide/installation/pseudo-cluster![]() https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/guide/installation/pseudo-cluster
https://dolphinscheduler.apache.org/zh-cn/docs/3.2.0/guide/installation/pseudo-cluster
1.2 前置准备工作
- JDK:下载JDK (1.8+),安装并配置
JAVA_HOME环境变量,并将其下的bin目录追加到PATH环境变量中。
[root@bigdata102 logs]# vim /etc/profile.d/my_env.sh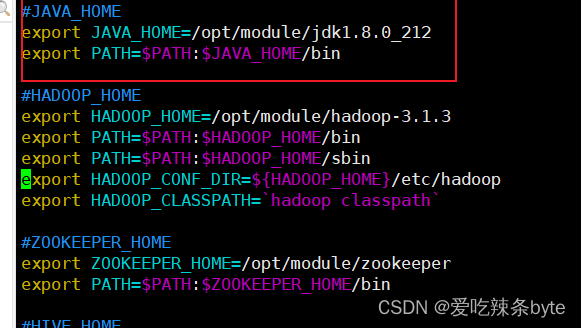
- 数据库:PostgreSQL (8.2.15+) 或者 MySQL (5.7+),两者任选其一即可,如 MySQL 则需要 JDBC Driver 8.0.16 及以上的版本。(这块后面会详细介绍)
[root@bigdata102 ~]$ mysql -h 192.168.10.102 -u root -P3306 -p
#密码123456
- 注册中心:ZooKeeper (3.8.0+)
ps:集群zk版本用的是3.5.7暂时没出问题
二、 DolphinScheduler集群部署
部署规划:
| 组件名称 | bigdata102 | bigdata103 | bigdata104 |
| DolphinScheduler3.2.0 | MasterServer | ||
| WorkerServer | WorkerServer | WorkerServer | |
| AlertServer | |||
| ApiApplicationServer | |||
| Zookeeper-3.5.7 | zk | zk | zk |
| Mysql-5.7.16 | mysql | ||
| mysql-connector-j-8.3.0.jar | mysql-connector-j-8.3.0.jar | mysql-connector-j-8.3.0.jar |
ps: 为了书写方便,下文中的DolphinScheduler 直接简称为ds
2.1 解压安装包
将ds安装包上传到bigdata102节点的/opt/software目录下,并直接解压到当前目录(ps:此处的解压目录不是最终的安装目录)
[root@bigdata102 software]# tar -zxvf apache-dolphinscheduler-3.2.0-bin.tar.gz2.2 配置数据库
ds元数据存储在关系型数据库中,故需创建相应的数据库和用户。
mysql -h 192.168.10.102 -u root -P3306 -p
//创建数据库
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
//创建用户
//修改 {user} 和 {password} 为你希望的用户名和密码
mysql> CREATE USER '{user}'@'%' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%';
mysql> CREATE USER '{user}'@'localhost' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost';
mysql> FLUSH PRIVILEGES;
若出现以下错误信息,表明新建用户的密码过于简单。
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
可提高密码复杂度或者执行以下命令降低MySQL密码强度级别。
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
赋予用户相应权限
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
mysql> flush privileges;
ps:非常关键的一步:
如果使用 MySQL作为ds的元数据库,还需要将mysql-connector-java 驱动 ( 8.0.16 及以上的版本) 移动到ds的每个模块的 libs 目录下,其中包括 api-server/libs , alert-server/libs , master-server/libs ,worker-server/libs, tools/libs
本集群中:是将 mysql-connector-j-8.3.0.jar 移动到上述五个libs目录下

2.3 准备 DolphinScheduler 启动环境
2.3.1 配置用户免密及权限
创建部署用户,并且一定要配置 sudo 免密。以创建 dolphinscheduler 用户为例。
# 创建用户需使用 root 登录
useradd dolphinscheduler# 添加密码
echo "dolphinscheduler" | passwd --stdin dolphinscheduler# 配置 sudo 免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers# 修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler-*-bin 目录有操作权限
chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-*-bin
chmod -R 755 apache-dolphinscheduler-*-bin2.3.2 配置机器 SSH 免密登陆
由于ds是集群部署模式,安装的时候,由单节点向其他节点发送资源,各节点间需要能 SSH 免密登陆。
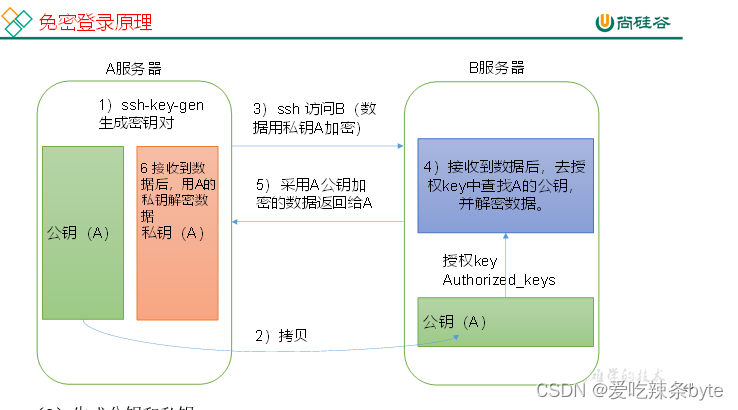
免密登陆配置过程:
- 生成公钥和私钥
[dolphinscheduler@bigdata102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
- 将公钥拷贝到要免密登录的目标机器上
[dolphinscheduler@bigdata102 .ssh]$ ssh-copy-id bigdata102
[dolphinscheduler@bigdata102 .ssh]$ ssh-copy-id bigdata103
[dolphinscheduler@bigdata102 .ssh]$ ssh-copy-id bigdata104
免密配置完成后,用命令 ssh localhost 判断是否成功,如果不需要输入密码就能ssh登陆,则证明配置成功。

2.3.3 启动 zookeeper集群
不赘述,zk集群部署流程请自行百度。
2.3.4 修改install_env.sh 文件
vim bin/env/install_env.sh
# Example for hostnames: ips="ds1,ds2,ds3,ds4,ds5", Example for IPs: ips="192.168.8.1,192.168.8.2,192.168.8.3,192.168.8.4,192.168.8.5"
ips=${ips:-"bigdata102,bigdata103,bigdata104"}# Port of SSH protocol, default value is 22. For now we only support same port in all `ips` machine
# modify it if you use different ssh port
sshPort=${sshPort:-"22"}# A comma separated list of machine hostname or IP would be installed Master server, it
# must be a subset of configuration `ips`.
# Example for hostnames: masters="ds1,ds2", Example for IPs: masters="192.168.8.1,192.168.8.2"
masters=${masters:-"bigdata102"}# A comma separated list of machine <hostname>:<workerGroup> or <IP>:<workerGroup>.All hostname or IP must be a
# subset of configuration `ips`, And workerGroup have default value as `default`, but we recommend you declare behind the hosts
# Example for hostnames: workers="ds1:default,ds2:default,ds3:default", Example for IPs: workers="192.168.8.1:default,192.168.8.2:default,192.168.8.3:default"
workers=${workers:-"bigdata102:default,bigdata103:default,bigdata104:default"}# A comma separated list of machine hostname or IP would be installed Alert server, it
# must be a subset of configuration `ips`.
# Example for hostname: alertServer="ds3", Example for IP: alertServer="192.168.8.3"
alertServer=${alertServer:-"bigdata102"}# A comma separated list of machine hostname or IP would be installed API server, it
# must be a subset of configuration `ips`.
# Example for hostname: apiServers="ds1", Example for IP: apiServers="192.168.8.1"
apiServers=${apiServers:-"bigdata102"}# The directory to install DolphinScheduler for all machine we config above. It will automatically be created by `install.sh` script if not exists.
# Do not set this configuration same as the current path (pwd). Do not add quotes to it if you using related path.
installPath=${installPath:-"/opt/module/dolphinscheduler"}# The user to deploy DolphinScheduler for all machine we config above. For now user must create by yourself before running `install.sh`
# script. The user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled than the root directory needs
# to be created by this user
deployUser=${deployUser:-"dolphinscheduler"}# The root of zookeeper, for now DolphinScheduler default registry server is zookeeper.
# It will delete ${zkRoot} in the zookeeper when you run install.sh, so please keep it same as registry.zookeeper.namespace in yml files.
# Similarly, if you want to modify the value, please modify registry.zookeeper.namespace in yml files as well.
zkRoot=${zkRoot:-"/dolphinscheduler"}2.3.5 修改dolphinscheduler_env.sh 文件
# applicationId auto collection related configuration, the following configurations are unnecessary if setting appId.collect=log
#export HADOOP_CLASSPATH=`hadoop classpath`:${DOLPHINSCHEDULER_HOME}/tools/libs/*
#export SPARK_DIST_CLASSPATH=$HADOOP_CLASSPATH:$SPARK_DIST_CLASS_PATH
#export HADOOP_CLIENT_OPTS="-javaagent:${DOLPHINSCHEDULER_HOME}/tools/libs/aspectjweaver-1.9.7.jar":$HADOOP_CLIENT_OPTS
#export SPARK_SUBMIT_OPTS="-javaagent:${DOLPHINSCHEDULER_HOME}/tools/libs/aspectjweaver-1.9.7.jar":$SPARK_SUBMIT_OPTS
#export FLINK_ENV_JAVA_OPTS="-javaagent:${DOLPHINSCHEDULER_HOME}/tools/libs/aspectjweaver-1.9.7.jar":$FLINK_ENV_JAVA_OPTS
# JAVA_HOME, will use it to start DolphinScheduler server
export JAVA_HOME=${JAVA_HOME:-/opt/module/jdk1.8.0_212}# Database related configuration, set database type, username and password# Tasks related configurations, need to change the configuration if you use the related tasks.
export HADOOP_HOME=${HADOOP_HOME:-/opt/module/hadoop-3.1.3}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/opt/module/hadoop-3.1.3/etc/hadoop}
export SPARK_HOME=${SPARK_HOME:-/opt/module/spark}
#export SPARK_HOME1=${SPARK_HOME1:-/opt/soft/spark1}
#export SPARK_HOME2=${SPARK_HOME2:-/opt/soft/spark2}
#export PYTHON_HOME=${PYTHON_HOME:-/opt/soft/python}
export JAVA_HOME=${JAVA_HOME:-/opt/module/jdk1.8.0_212}
export HIVE_HOME=${HIVE_HOME:-/opt/module/hive}
#export FLINK_HOME=${FLINK_HOME:-/opt/soft/flink}
#export DATAX_HOME=${DATAX_HOME:-/opt/datax/datax}export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$PATHexport SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-UTC}
# Database related configuration, set database type, username and password
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
# export SPRING_DATASOURCE_DRIVER_CLASS_NAME=com.mysql.jdbc.Driver
export SPRING_DATASOURCE_URL="jdbc:mysql://192.168.10.102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME="root"
export SPRING_DATASOURCE_PASSWORD="123456"
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-bigdata102:2181,bigdata103:2181,bigdata104:2181}
export REGISTRY_ZOOKEEPER_BLOCK_UNTIL_CONNECTED=${REGISTRY_ZOOKEEPER_BLOCK_UNTIL_CONNECTED:30s}
ps: 这里有个坑:SPRING_DATASOURCE_URL参数最开始配置为:
export SPRING_DATASOURCE_URL="jdbc:mysql://192.168.10.102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8"
在【2.3.6 初始化数据库】的时候,程序报Unsupported record version Unknown-0.0
排查后发现是:jdbc连接开启了ssl协议,所以我在上述 SPRING_DATASOURCE_URL参数的最后面,添加了&useSSL=false,此bug解决了。
2.3.6 初始化数据库
经过上述步骤,已经为 ds创建了元数据数据库,通过Shell脚本一键初始化数据库(自动建表)

2.3.7 修改application.yaml文件
需要修改以下5个文件:
master-server/conf/application.yaml
api-server/conf/application.yaml
worker-server/conf/application.yaml
alert-server/conf/application.yaml
tools/conf/application.yaml
每个文件修改的部分相同,如截图:主要是参数driver-class-name 和 参数url
datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.10.102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456hikari:connection-test-query: select 1minimum-idle: 5auto-commit: truevalidation-timeout: 3000pool-name: DolphinSchedulermaximum-pool-size: 50connection-timeout: 30000idle-timeout: 600000leak-detection-threshold: 0initialization-fail-timeout: 1spring:config:activate:on-profile: mysqldatasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.10.102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456quartz:properties:org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
2.3.8 启动 DolphinScheduler
注意使用上面创建的部署用户dolphinscheduler 运行以下命令完成部署,部署后的运行日志位于logs 文件。

以master-server为例,日志存放在下列目录:

ps: 第一次部署可能出现 sh: bin/dolphinscheduler-daemon.sh: No such file or directory相关信息,此为非重要信息直接忽略即可
2.3.9 登录 DolphinScheduler
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统 UI。默认的用户名和密码是 admin/dolphinscheduler123
ps:这里的localhost的ip地址是api-server所在节点的地址(bin/env/install_env.sh 配置文件中指定的)


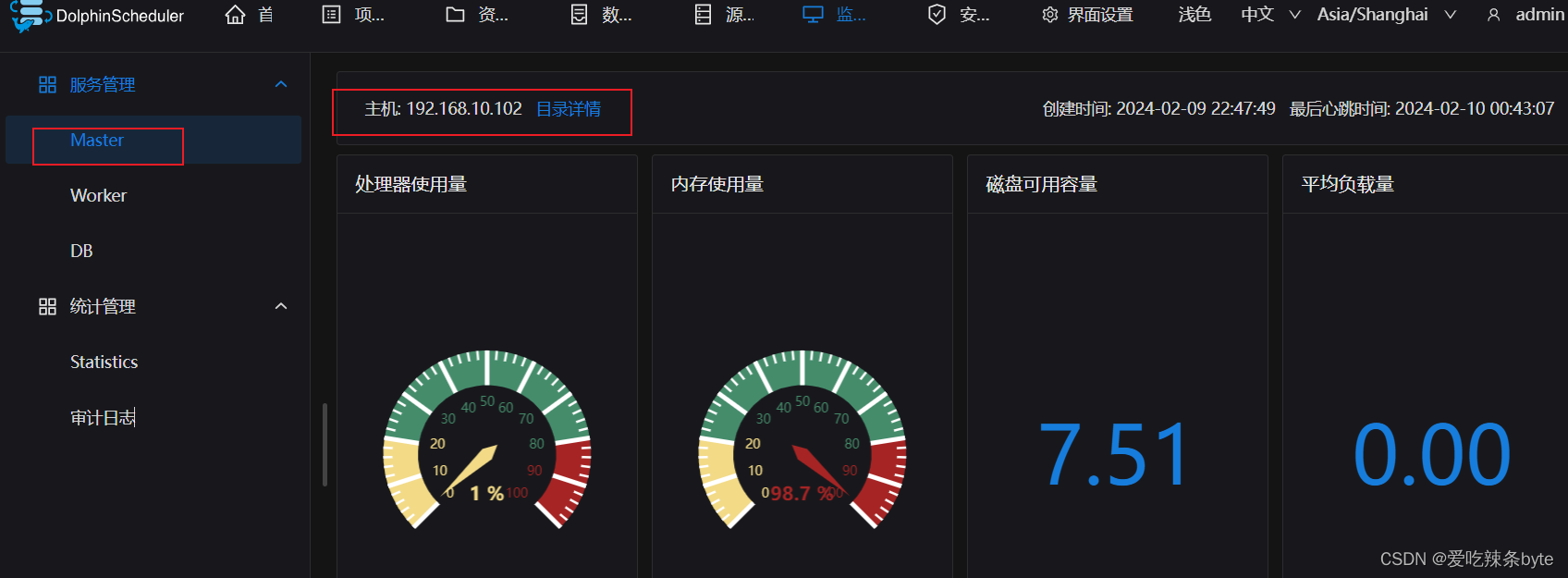
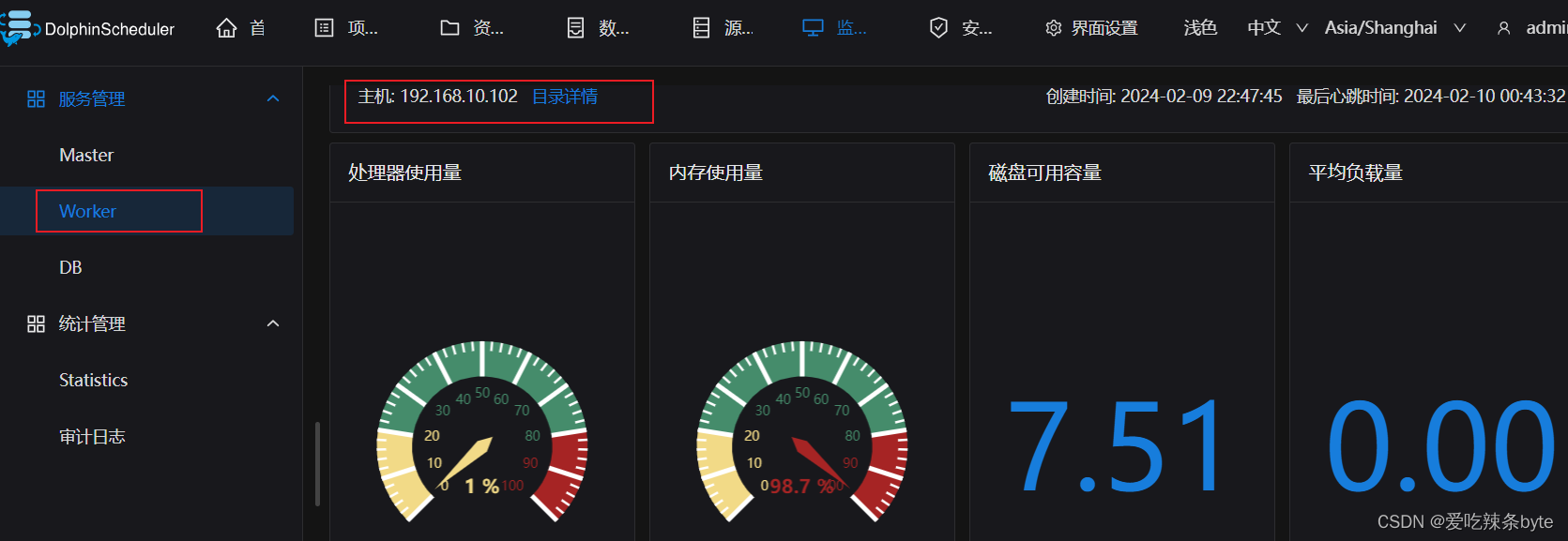
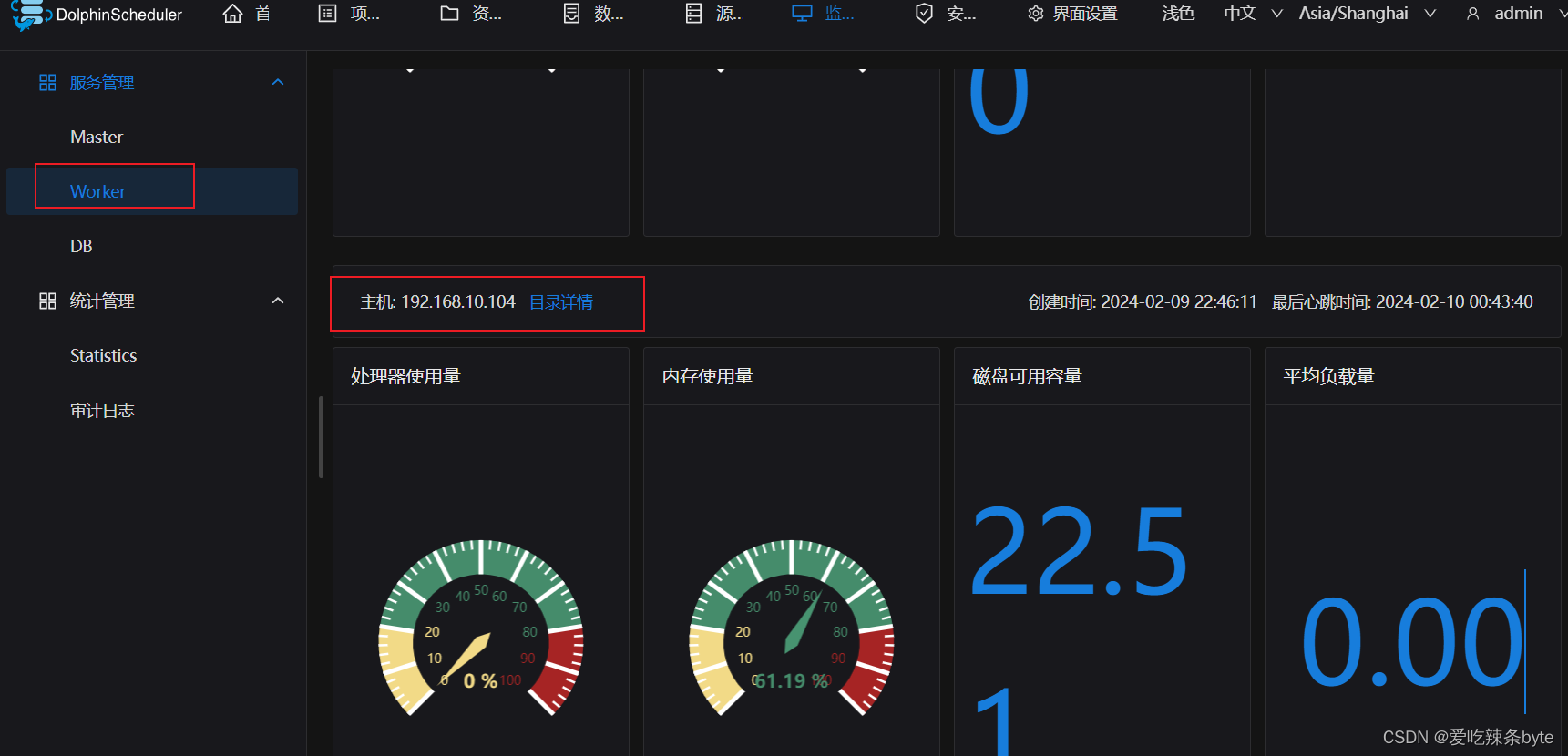
2.3.10 DolphinScheduler概览页
http://192.168.10.102:12345/dolphinscheduler/ui/home
用户/密码:admin/dolphinscheduler123






![[HTTP协议]应用层的HTTP 协议介绍](https://img-blog.csdnimg.cn/direct/343c5d44ee154b998ed27eb81e50a4a9.png)