Python并行处理文件:加快数据处理效率
Python作为一种高级编程语言,广泛应用于数据分析,大数据处理,机器学习等领域。在处理大量数据时,串行处理速度较慢,甚至可能耗费数小时或数天的时间。因此,引入并行处理的技术,可以大大提高数据处理的效率。本文将重点介绍如何使用Python并行处理文件。
什么是并行处理
在计算机科学领域,顺序执行是一项基本操作。但并发处理(亦称为并行处理)旨在同时执行多项任务。通过并行化程序,计算机便可更快地处理数据。在多核计算机或集群上,并行处理可为程序加速,减少执行时间。
Python并行处理框架
Python 提供了许多并行处理框架来帮助程序员并行处理数据。其中,在Python 3.2及以上的版本中,内置的 concurrent.futures 库提供了对并行处理的支持。
该库提供了两个类 — ThreadPoolExecutor 和 ProcessPoolExecutor,以实现线程和进程的并发处理。ThreadPoolExecutor 支持线程并发处理数据。ProcessPoolExecutor 则更适合于 CPU 密集型的计算,并可并发的执行较长时间的任务。
以以下代码为例,我们展示了 ThreadPoolExecutor 的使用方法:
from concurrent.futures import ThreadPoolExecutor
import timedef sleep(n):time.sleep(n)return ndef main():with ThreadPoolExecutor(max_workers=10) as executor:results = executor.map(sleep, [5,1,3,2,4])for result in results:print(result)if __name__ == '__main__':main()
在以上示例中,我们定义了一个 sleep 函数模拟一些长时间运行的任务,同时创建一个 ThreadPoolExecutor 对象,最大工作线程数为10。将任务列表 [5, 1, 3, 2, 4] 传递给 map 函数,并对其进行迭代以读取结果。
并行处理文件
在实际应用中,我们通常需要从文件中读取大量数据。通过并行处理,我们可以快速地读取和处理文件中的数据。以下是并行处理文件的一些实用技巧。
1. 多线程读取文件
在 Python 中,使用多线程读取文件是一个简单且有效的方法。由于 Python 的全局解释器锁(GIL)的限制,单个线程无法充分利用多核 CPU。因此,多线程处理可能会更适合 I/O 密集型操作。
from concurrent.futures import ThreadPoolExecutordef read_file(filename):with open(filename, 'r') as f:data = f.read()return datadef main():with ThreadPoolExecutor(max_workers=10) as executor:results = executor.map(read_file, ["file1.txt", "file2.txt", "file3.txt"])for result in results:print(result)if __name__ == '__main__':main()
在以上例子中,我们定义了一个 read_file 函数读取文件的内容,并创建了一个 ThreadPoolExecutor 对象以并发的执行任务。在实际应用中,我们可以使用 map 函数来并发的读取多个文件。
2. 多进程处理文件
在处理 CPU 密集型任务时,多进程的技术可以很好地利用多核 CPU 的能力。Python 的 ProcessPoolExecutor 类可以用于处理 CPU 密集型任务。
from concurrent.futures import ProcessPoolExecutordef process_file(filename):# do some heavy processingreturn resultdef main():with ProcessPoolExecutor(max_workers=4) as executor:results = executor.map(process_file, ["file1.txt", "file2.txt", "file3.txt"])for result in results:print(result)if __name__ == '__main__':main()
在以上例子中,我们定义了一个 process_file 函数来读取文件并进行一些计算处理,并创建了一个 ProcessPoolExecutor 对象以并行的执行任务。
结论
Python 并行处理文件是提高数据处理效率的一种常用方法。在本文中,我们介绍了 Python 并行处理的基本概念,并重点介绍了 Python 中的 concurrent.futures 库的使用方法。我们还介绍了多线程和多进程处理文件的方法,以及如何使用这些技术来处理 I/O 密集型任务和 CPU 密集型任务。使用并行技术,可以大大提高数据处理速度,减少处理时间。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲
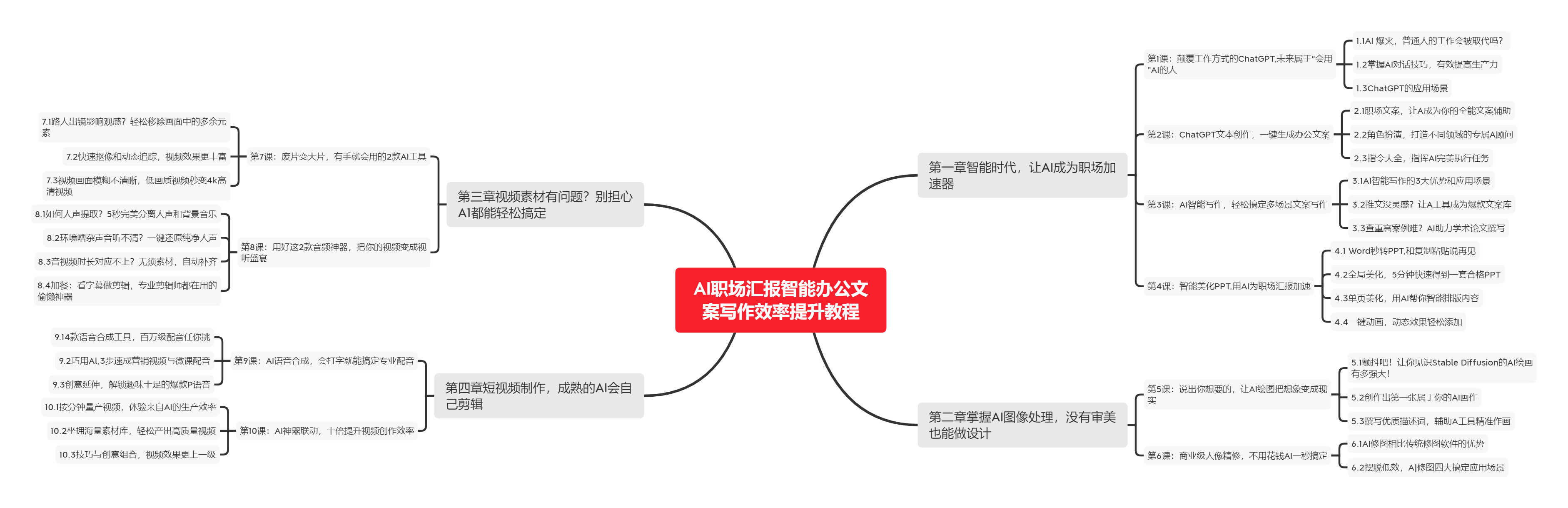

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |


![[047量化交易]python获取股票 量比 换手率 市盈率-动态 市净率 总市值 流通市值](https://img-blog.csdnimg.cn/dc1ebb666dad45e7906e811caac7337a.png)