目录
✊请求报文--解析
流程图 && 状态机
状态机 -- 状态转移图
主状态机
从状态机
http 报文解析
HTTP_CODE 含义
从状态机 逻辑
主状态机 逻辑
🐞请求报文--响应
基础API
stat
mmap
iovec
writev
流程图
HTTP_CODE 含义(2)
代码分析
do_request
process_write
http_conn::write
✊请求报文--解析
流程图 && 状态机
状态机 -- 状态转移图
从状态机 -- 读取一行
主状态机 -- 解析该行
(主状态机内部调用从状态机,从状态机驱动主状态机)
👆状态机转移图(结合以下文本理解)
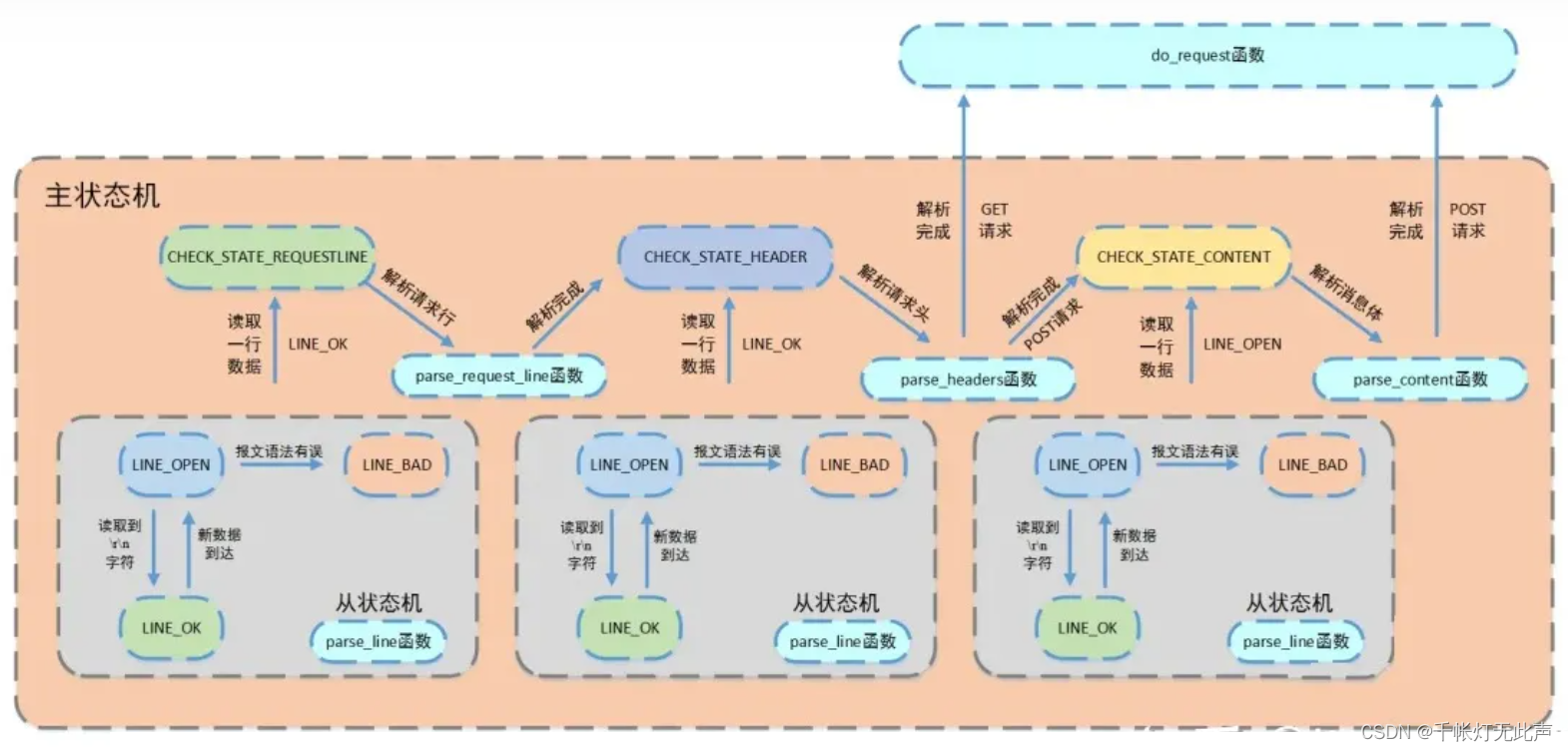
主状态机
三种状态,标识解析位置
- CHECK_STATE_REQUESTLINE -- 解析 请求行
- CHECK_STATE_HEADER -- 解析 请求头
- CHECK_STATE_CONTENT -- 解析 消息体,仅用于解析 POST请求
从状态机
三种状态,标识解析一行的读取状态
- LINE_OK,完整读取一行
- LINE_BAD,报文语法有误
- LINE_OPEN,读取的行不完整
http 报文解析
流程
上一篇博客,介绍了,服务器接收 http请求 的流程
也就是,浏览器发出 http连接请求,服务器 主线程创建 http对象 接收,
并将所有数据读入对应的 buffer,
将该对象插入任务队列后,工作线程从任务队列取出一个任务并处理
各子线程,通过 process() 函数,处理任务,调用 process_read() 函数 和 process_write() 函数,分别完成 报文解析 和 报文响应
void http_conn::process()
{// 调用 process_read() 处理请求// 并返回 HTTP_CODE 枚举类型状态码HTTP_CODE read_ret = process_read();// 请求不完整,需要继续接收if (read_ret == NO_REQUEST) {// 注册并监听 读事件,等待下一次数据到来modfd(m_epollfd, m_sockfd, EPOLLLIN);return;}// 调用 process_write() 完成响应bool write_ret = process_write(read_ret);// 响应失败 -- 关闭连接if (!write_ret) close_conn();// 响应成功 -- 注册并监听 写事件,等待下一次写入响应数据modfd(m_epollfd, m_sockfd, EPOLLOUT);
}HTTP_CODE 含义
HTTP请求的处理结果
头文件初始化了 8 种
报文解析涉及 4 种
- NO_REQUEST
- 请求不完整,需要继续读取请求报文数据
- GET_REQUEST
- 获得了完整的HTTP请求
- BAD_REQUEST
- 语法错误
- INTERNAL_ERROR
- 服务器内部错误,该结果在 主状态机 逻辑switch 的 default 下,一般不会触发
解析报文 整体流程
process_read 通过 while 循环,对主从状态机进行封装,循环处理报文每一行
- 判断条件
- 主状态机 转移到 CHECK_STATE_CONTENT(解析消息体)
- 从状态机 转移到 LINE_OK(解析请求行和请求头部)
- 两者为 或 关系,条件为真则继续循环,否则退出
- 循环体
- 从状态机 读取数据
- 调用 get_line() 函数,通过 m_start_line() 将 从状态机 读取的数据间接赋给 text
- 主状态机 解析 text
// m_start_line 是行在 buffer 起始位置
// 该位置后面的数据赋给 text
// 此时的从状态机,已提前将一行的末尾字符
// \r\n 变为 \0\0,所以text可直接取出完整的行解析
char* get_line() {return m_read_buf + m_start_line;
}http_conn::HTTP_CODE http_conn::process_read()
{// 初始化从状态机状态,HTTP请求解析结果LINE_STATUS line_status = LINE_OK;HTTP_CODE ret = NO_REQUEST;char* text = 0;// 为什么要写两个判断条件?第一个判断条件// 为什么这样写?// 具体主状态机逻辑--后面讲解// parse_line 为从状态机的具体实现while ( (m_check_state == CHECK_STATE_CONTENT &&line_status == LINE_OK) ||((line_status=parse_line()) ==LINE_OK) ) {text = get_line();// m_start_line 是每一个数据行在m_read_buf的起始位置// m_checked_edx 从状态机 在m_read_buf中读取的位置m_start_line = m_checked_idx;// 主状态机 3 种状态转移逻辑switch(m_check_state) {case CHECK_STATE_REQUESTLINE:{// 解析请求行ret = parse_request_line(text);if (ret == BAD_REQUEST)return BAD_REQUEST;break;}case CHECK_STATE_HEADER:{// 解析请求头ret = parse_headers(text);if (ret == BAD_REQUEST)return BAD_REQUEST;break;}case CHECK_STATE_CONTENT:{// 解析消息体ret = parse_content(text);// 完整解析POST请求后,跳转报文响应函数if (ret == GET_REQUEST)return do_request();// 解析完消息体即完成报文解析,避免再次进入循环// 更新 line_statusline_status = LINE_OPEN;break;}default:return INTERNAL_ERROR;}}return NO_REQUEST;
}从状态机 逻辑
补充个基础知识👇
HTTP报文中,每一行数据由 \r\n 作为结束字符,空行只有 \r\n
因此,可以通过查找 \r\n 将报文拆解为单独的行进行解析
本项目即利用了这点
从状态机 读取 buffer 中的数据,将每行数据末尾的 \r\n 设置为 \0\0
并更新 从状态机 在 buffer 中读取的位置 m_checked_idx
以此驱动 主状态机 解析

- 从状态机从 m_raed_buf 中,逐字节读取,判断当前的字节是否为 \r
- 接下来的字符是 \n,将 \r\n 修改为 \0\0,将 m_checked_idx 指向下一行的开头,则返回LINE_OK
- 接下来到达 buffer 末尾,表示 buffer 还需要继续接收,返回 LINE_OPEN
- 否则,语法错误,返回 LINE_BAD
- 当前字节不是 \r,判断是否是 \n(如果上次读取到 \r 就到了 buffer 末尾,没有接收完整,再次接收会出现这个情况)
- 如果前一个字符是 \r,则将 \r\n 修改为 \0\0,将 m_checked_idx 指向下一行开头,返回 LINE_OK
- 当前字节,不是 \r,也不是 \n
- 表示接收不完整,需要继续接收,返回 LINE_OPEN
// 从状态机,用于分析出一行的内容
// 返回值为行的读取状态,有:
// LINE_OK, LINE_BAD, LINE_OPEN// m_read_idx 指向缓冲区 m_read_buf 数据末尾下一字节
// m_checked_idx 指向从状态机当前分析的字节http_conn::LINE_STATUS http_conn::parse_line()
{char temp;for (; m_checked_idx < m_read_idx; ++m_checked_idx){// temp 要分析的字节temp = m_read_buf[m_checked_idx];// 如果当前是 \r,则有可能读取到完整行if (temp == '\r') {// 下一字符达到了 buffer 结尾,则接收不完整,继续接收if (m_checked_idx + 1 == m_read_idx)return LINE_OPEN;// 下一字符是 \n,将 \r\n 改为 \0\0else if (m_read_buf[m_checked_idx+1] == '\n') {m_read_buf[m_checked_idx++] = '\0';m_read_buf[m_checked_idx++] = '\0';return LINE_OK;}// 都不符合,返回 语法错误return LINE_BAD;}// 如果当前字符是 \n,也可能读取到完整的行// 一般是上次读取到 \r,就到 buffer 末尾,没有接收完整// 再次接收时,就会出现这种情况else if (temp == '\n') {// 前一字符是 \r 则接收完整if (m_checked_idx > 1 && m_read_buf[m_checked_idx-1] == '\r'){m_read_buf[m_checked_idx-1] = '\0';m_read_buf[m_checked_idx] = '\0';return LINE_OK;}return LINE_BAD;}}// 没有找到 \r\n 需要继续接收return LINE_OPEN;
}主状态机 逻辑
(1) 处理请求行
主状态机 初始状态是 CHECK_STATE_REQUESTLINE,通过调用 从状态机 驱动 主状态机
主状态机 解析前,从状态机已经将每一行末尾的 \r\n 改为 \0\0
以便主状态机直接取出对应字符串进行处理
- 状态(1)CHECK_STATE_REQUESTLINE
- 主状态机 初始状态,调用 parse_request_line() 解析 请求行
- 解析函数从 m_read_buf 中解析 HTTP请求行,获得请求方法,目标URL,HTTP版本号
- 解析完成后,主状态机状态变为 CHECK_STATE_HEADER
// 解析http请求行,获得请求方法,目标URL,http版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{// HTTP报文中,请求行用来说明:// 请求类型,要访问的资源,所使用的HTTP版本号// 其中各个部分之间,通过 \t 或 空格 分隔// 请求行中,最先含有 空格 和 \t 任一字符的位置并返回m_url = strpbrk(text, " \t");// 如果没有 空格 或 \t,则报文格式有误if (!m_url) return BAD_REQUEST;// 该位置改为 \0,用于取出前面数据*m_url++ = '\0';// 取出数据,并通过与 GET 和 POST 比较,以确定请求方式char *method = text;if (strcasecmp(method,"GET") == 0)m_method = GET;else if (strcasecmp(method,"POST") == 0) {m_method = POST;cgi = 1;}else return BAD_REQUEST;// m_url 此时跳过了第一个空格或\t字符,但不知道之后是否还有// 将 m_url 向后偏移,通过查找,继续跳过空格和\t字符,// 指向请求资源的第一个字符m_url += strspn(m_url, " \t");// 使用与判断请求方式相同的逻辑,判断 HTTP 版本号m_version = strpbrk(m_url, " \t");if (!m_version)return BAD_REQUEST;*m_version++ = '\0';m_version += strspn(m_verison, " \t");// 仅支持 HTTP/1.1if (strcasecmp(m_verison, "HTTP/1.1") != 0)return BAD_REQUEST;// 对请求资源前 7 个字符进行判断// 这里,有些报文的请求资源会代有 http://// 要单独处理这种情况if (strncasecmp(m_url, "http://", 7) == 0) {m_url += 7;m_url = strchar(m_url, '/');}// 同样的 https 情况if (strncasecmp(m_url, "https://", 8) == 0) {m_url += 8;m_url = strchar(m_url, '/');}// 一般不会带有上述两种符号,// 而是,单独的 / 或 /后带访问资源if (!m_url || m_url[0] != '/')return BAD_REQUEST;// 当 url 为 / 时,显示欢迎界面if (strlen(m_url) == 1) strcat(m_url, "judge.html");// 请求行 处理完毕,将主状态机转移去处理 请求头m_check_state = CHECK_STATE_HEADER;return NO_REQUEST;
}(2) 处理请求头
解析完 请求行 后,主状态机继续分析请求头
报文中,请求头 和 空行的处理,使用同一个函数
通过判断当前 text 首位,是不是 \0 字符
是 -- 当前处理的是 空行
不是 -- 当前处理的是 请求头
- 状态(2)CHECK_STATE_HEADER
- 调用 parse_headers() 解析 请求头
- 判断空行 OR 请求头
- 是空行的话,进而判断 content-length 是否为 0(不是 0,即 POST请求,那么状态转移到 CHECK_STATE_CONTENT)(是 0,说明是 GET 请求,则报文解析结束)
- 若解析的是 请求头部字段,则主要分析 connection 字段,content-length 字段,其他字段可以直接跳过
- connection 字段,判断是 keep_alive 还是 close,决定是长连接还是短连接
- content-length 字段,用于读取 post 请求的 消息体长度
// 解析http请求的一个头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char *text)
{// 判断 空行 还是 请求行if (text[0] == '\0') { // 空行// 判断 GET 还是 POST 请求if (m_content_length != 0) { // POST 请求// POST 需跳转到 消息体 处理状态m_check_state = CHECK_STATE_CONTENT;return NO_REQUEST;}return GET_REQUEST; // GET 请求}// 解析请求头部 连接字段else if (strncasecmp(text, "Connection:", 11) == 0) {text += 11;// 跳过 空格 和 \t 字符text += strspn(text, " \t");if (strcasecmp(text, "keep-alive") == 0) {// 如果是长连接,将 linger 标志设置为 truem_linger = true;}}// 解析请求头部 内容长度字段else if (strncasecmp(text, "Content-length:", 15) == 0) {text += 15;text += strspn(text, " \t");m_content_length = atol(text);}// 解析请求头部 HOST字段else if (strncasecmp(text, "Host:", 5) == 0) {text += 5;text += strspn(text, " \t");m_host = text;}else printf("oop! unknown header: %s\n", text);return NO_REQUEST;
}(3)处理消息体
如果仅仅是 GET 请求,比如项目中的欢迎界面,那么 主状态机 只设置前两个状态即可
根据之前所说,GET 和 POST 请求报文的区别:有无消息体部分。
GET 请求没有消息体,当解析完空行后,便完成了报文解析
但后续的登录和注册功能,为了避免将用户名和密码,直接暴露在URL中,我们在项目中改用了 POST 请求,将用户名和密码,添加在报文中,作为消息体进行封装
为此,我们需要在解析报文中,添加 解析消息体 的模块
while (
(m_check_state==CHECK_STATE_CONTENT && line_status==LINE_OK)
||
( (line_status=parse_line() )==LINE_OK)
)判断条件为什么写成这样呢?👆
👆解析
GET 请求报文中,每一行都是 /r/n 结尾,所以对报文进行拆解时,仅用从状态机的状态
( line_status = parse_line() ) == LINE_OK
但,在 POST 请求报文中,消息体的末尾没有任何字符,所以不能使用 从状态机 的状态
这里转而使用 主状态机 的状态,作为循环条件入口
那后面的 && line_status == LINE_OK 又为什么?👆
解析完消息体后,报文的完整解析就完成了
但此时 主状态机 的状态,还是 CHECK_STATE_CONTENT
也就是说,符合循环入口条件
还会再次进入循环,这不是我们所希望的
为此,增加了下面语句,并在完成 消息体 解析后,将 line_status 变量更改为 LINE_OPEN
此时可以跳出循环,完成报文解析任务
- 状态(3)CHECK_STATE_CONTENT
- 仅用于解析 POST 请求,调用 parse_content() 解析 消息体
- 用于保存 post请求 消息体,为后面登录和注册做准备
// 判断 http请求 是否被完整读入
http_conn::HTTP_CODE http_conn::parse_content(char *text)
{// 判断 buffer 中是否读取了消息体if (m_read_idx >= (m_content_length + m_checked_idx)) {text[m_content_length] = '\0';// POST请求 中最后,是输入的用户名和密码m_string = text;return GET_REQUEST;}return NO_REQUEST;
}状态机 和 HTTP报文解析 是 TinyWebServer 最繁琐的部分
需要 多读 + 画图 来理解
🐞请求报文--响应
本博客,上半部分,我们对 状态机 和 HTTP请求 -- 解析,作了介绍
下面,再介绍 服务器如何响应 http请求报文,并将该报文发送给浏览器
基础API
stat, mmap, iovec, writev
为了更好的源码阅读体验,这里对源码使用的部分 API 进行介绍
stat
stat() 函数 -- 取得指定文件的文件属性,并将文件属性存储在 结构体 stat 中
#include<sys/types.h>
#include<sys/stat.h>
#include<unistd.h>// 获取文件属性,存储在 statbuf 中
int stat(const char *pathname, struct stat *statbuf);struct stat {mode_t st_mode; // 文件类型和权限off_t st_size; // 文件大小,字节数
};mmap
将一个文件 或 其他对象,映射到内存,提高文件访问速度
- start -- 映射区的开始地址,设置为 0 时,表示,由系统决定映射区起始地址
- length -- 映射区长度
- prot -- 期望的内存保护标志,不能与文件的打开模式冲突
- PROT_RAED 表示 页内容可以被读取
- flags -- 指定映射对象的类型,映射选项和映射页是否可以共享
- MAP_PRIVATE 建立一个写入时拷贝的私有映射,内存区域的写入不会影响到原文件
- fd -- 有效的文件描述符,一般是由 open() 函数返回
- off_toffset -- 被映射对象内容的起点
void* mmap(void* start, size_t length, int prot,int flags, int fd, off_t offset);int munmap(void* start, size_t length);iovec
定义一个 向量 元素,用作一个 多元素数组
- iov_base 指向数据的地址
- iov_len 表示数据长度
struct iovec {void *iov_base; // starting address of buffersize_t iov_len; // size of buffer
};writev
在一次函数调用中,写多个 非连续缓冲区,有时也将该函数成为 聚集写
- filedes 表示文件描述符
- iov 为 前述 io 向量机制结构体 iovec
- iovcnt 结构体个数
#include<sys/uio.h>
ssize_t writev(int filedes, const struct iovec *iov, int iovcnt);成功则返回 已写字节数,出错返回 -1
writev 以顺序 iov[0],iov[1] 到 iov[iovcnt - 1] 从缓冲区中聚集输出数据
writev 返回输出的字节总数,通常,等于所有缓冲区长度之和
特别注意
循环调用 writev() 时,需要重新处理 iovec 中的指针 和 长度
该函数不会对这两个成员做任何处理
writev() 的返回值为 已写字节数,但这个返回值的实用性不高
因为参数传入的是 iovec 数组,计量单位是 iovcnt,而不是字节数
还需要通过遍历 iovec 来计算新的基址
另外,写入数据的 “结束点” 可能位于一个 iovec 中间的某个位置
因此需要调整临界的 iovec 的 io_base 和 io_len
流程图
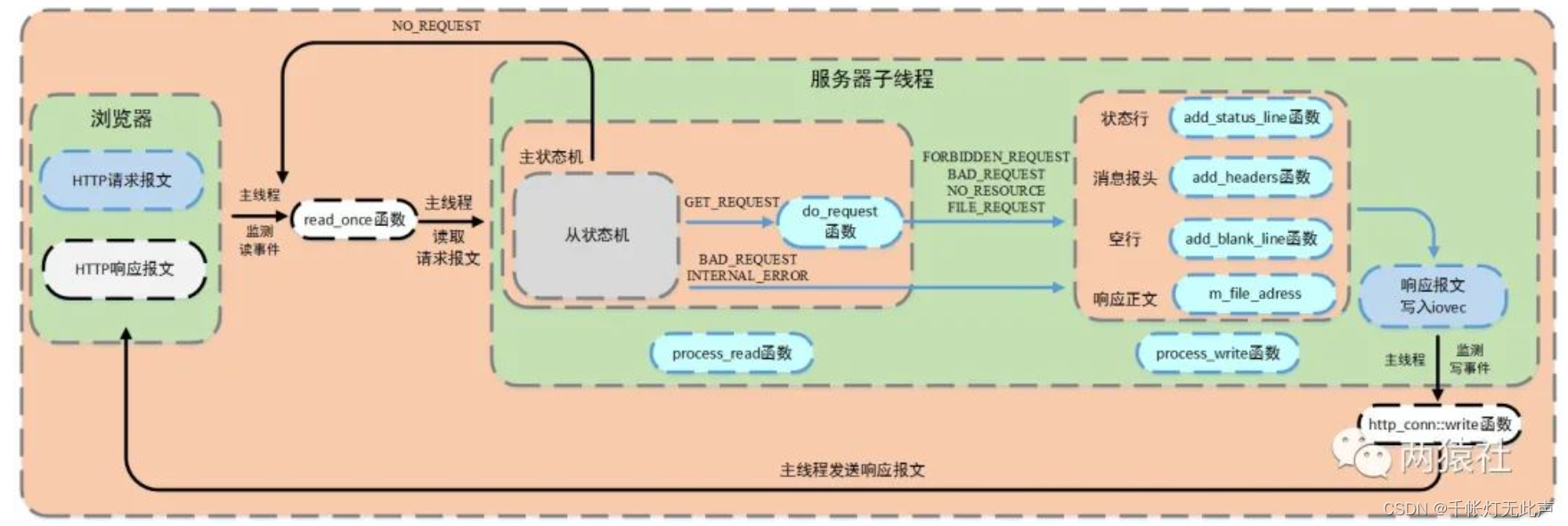
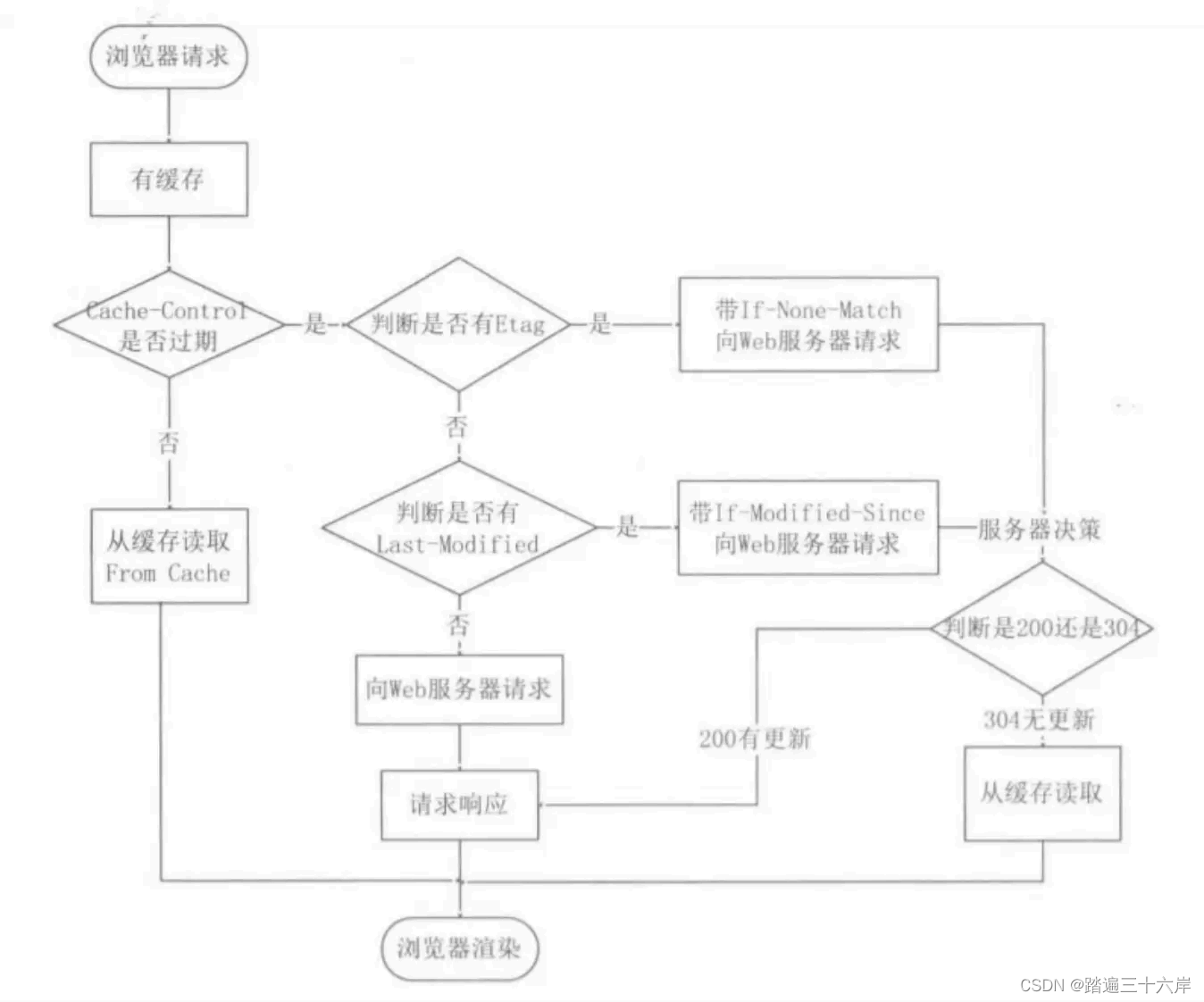
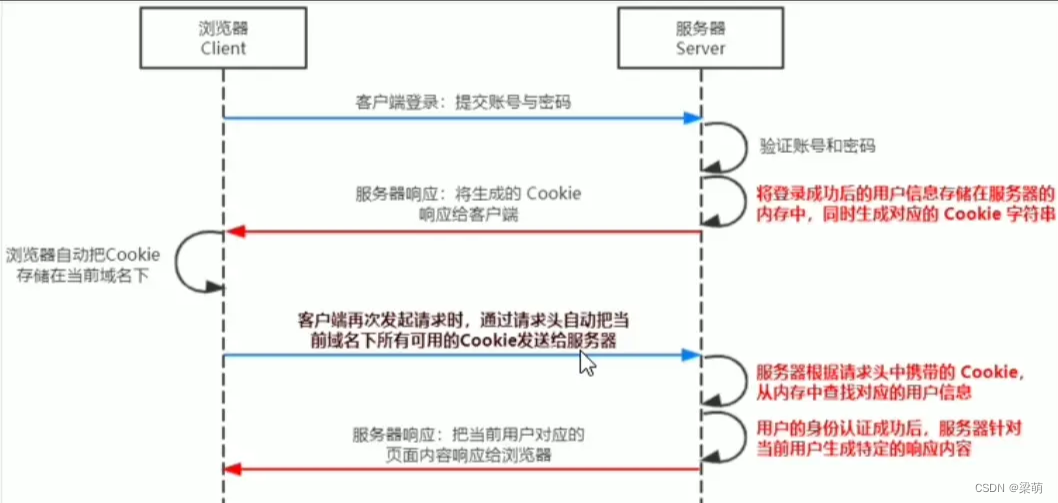
浏览器 发出HTTP请求报文,服务器接收该报文,并调用 process_read() 解析,根据解析结果 HTTP_CODE,进入相应的逻辑和模块
其中,服务器 子线程 完成报文的解析与响应;
主线程监测 独写事件,调用 read_once 和 http_conn::write 完成数据的 读取与发送
HTTP_CODE 含义(2)
表示 HTTP请求 的处理结果
头文件初始化了 8 种
报文 解析与响应 用到 7 种
NO_REQUEST
请求不完整,需要继续读取请求报文数据
跳转主线程继续监测读事件
GET_REQUEST
获得了完整的HTTP请求
调用do_request完成请求资源映射
NO_RESOURCE
请求资源不存在
跳转process_write完成响应报文
BAD_REQUEST
HTTP请求报文有语法错误或请求资源为目录
跳转process_write完成响应报文
FORBIDDEN_REQUEST
请求资源禁止访问,没有读取权限
跳转process_write完成响应报文
FILE_REQUEST
请求资源可以正常访问
跳转process_write完成响应报文
INTERNAL_ERROR
服务器内部错误,该结果在主状态机逻辑switch的default下,一般不会触发
代码分析
do_request
process_read() 返回值是,对请求文件分析后的结果
一部分是语法错误导致的 BAD_REQUEST
一部分是 do_request() 返回的结果
该函数将 网站根目录 和 url文件 拼接,再通过 stat 判断该文件属性
另外,为了提高访问速度,通过 mmap 进行映射,将 普通文件 映射到 内存逻辑地址
为了更好的理解请求资源的 访问流程
这里介绍各种 页面跳转机制
浏览器网址栏的字符,即 url,可以抽象成 ip:prot/xxx
xxx 通过 html 文件的 action 属性设置
m_url -- 请求报文中解析出的 请求资源,以 / 开头,也就是 /xxx
TinyWebServer 中解析后的 m_url 有 8 种情况
- /
- GET 请求,跳转到 judge.html(欢迎页面)
- /0
- POST 请求,跳转到 register.html(注册页面)
- /1
- POST 请求,跳转到 log.html(登陆页面)
- /2CGISQL.cgi
- POST 请求,进行登录校验
- 验证成功 -- 跳转 welcome.html(资源请求成功页面)
- 验证失败 -- 跳转 logError.html(登录失败页面)
- /3CGISQL.cgi
- POST 请求,进行注册校验
- 成功 -- 跳转 log.html(登录页面)
- 失败 -- 跳转 registerError.html(注册失败页面)
- /5
- POST 请求,跳转 picture.html(图片请求页面)
- /6
- POST 请求,跳转 vedio.html(视频请求页面)
- /7
- POST 请求,跳转 fans.html(关注页面)
// 网站根目录,文件夹内存放 请求资源 和跳转的 html 文件
const char* doc_root = "/home/qgy/github/ini_tinywebserver/root";http_conn::HTTP_CODE http_conn::do_request()
{// 网站根目录doc_root的内容 复制到 m_real_filestrcpy(m_real_file, doc_root);int len = strlen(doc_root);// 找到 m_url 中 / 的位置const char *p = strrchr(m_url, '/');// 实现 登录和注册 校验if (cgi == 1 && (*(p+1) == '2' || *(p+1) == '3') ) {// 根据标志,判断 登录 OR 注册 检测// 同步线程登录校验// CGI多进程登录校验}// 请求资源为 /0,表示跳转 注册页面if (*(p+1) == '0') {char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/register.html");// 将 网站目录 和 /register.html 拼接// 更新到 m_real_filestrncpy(m_real_file + m_url_real, strlen(m_url_real));free(m_url_real);}// 请求资源为 /1,表示跳转 登录页面else if (*(p+1) == '1') {char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/log.html");// 网站目录 和 /log.html 拼接// 更新到 m_real_filestrncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}// 既不是登录,也不是注册,直接将 url 与 网站根目录 拼接// 这里是 welcome 界面,请求服务器的一个图片else strncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1);// 通过 stat 获取 请求资源文件信息,成功 则将信息更新到// m_file_stat 结构体// 失败 返回 NO__RESOURCE 状态,表示 资源不存在if (stat(m_real_file, &m_file_stat) < 0)return NO_RESOURCE;// 判断文件权限,是否可读,不可读 则返回 FORBIDDEN_REQUEST状态if (!(m_file_stat.st_mode&S_IROTH))return FORBIDDEN_REQUEST;// 判断文件类型,目录 则返回 BAD_REQUEST,请求报文有误if (S_ISDIR(m_file_stat.st_mode))return BAD_REQUEST;// 以只读方式获取文件描述符,通过 mmap 映射文件到内存int fd = open(m_real_file, O_RDONLY);m_file_address = (char*)mmap(0, m_file_stat.st_size,PROT_READ, MAP_PRIVATE, fd, 0);// 避免文件描述符的浪费和占用close(fd);// 请求文件存在,且可以访问return FILE_REQUEST;
}process_write
根据 do_request() 的返回状态,服务器子线程调用 process_wirte() 向 m_write_buf
写入响应报文
- add_status_line() -- 添加状态行:http/1.1 状态码 状态消息
- add_headers() -- 添加消息报头,内部调用 add_content_length() 和 add_linger() 函数
- content_length -- 响应报文长度,用于 浏览器 判断 服务器 是否发送完数据
- connection -- 连接状态,用于告诉 浏览器 保持长连接
- add_blank_line() -- 添加空行
上面涉及的 5 个函数,内部均调用 add_response() 更新 m_write_idx 指针 和 缓冲区
m_write_buf 的内容
bool http_conn::add_response(const char* format, ...)
{// 写入内容超出 m_write_buf 大小就报错if (m_write_idx >= WRITE_BUFFER_SIZE)return false;// 定义可变参数列表va_list arg_list;// 变量 arg_list 初始化为传入参数va_start(arg_list, format);// 数据 format 从可变参数列表 写入 缓冲区写,返回写入数据长度int len = vsnprintf(m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list);// 写入数据长度超过缓冲区剩余空间,则报错if (len >= (WRITE_BUFFER_SIZE - 1 - m_write_dix)) {va_end(arg_list);return false;}// 更新 m_write_idx 位置m_write_idx += len;// 清空可变参数列表va_end(arg_list);return true;
}//添加 状态行
bool http::connadd_status_line(int status, const char* title)
{return add_address("%s %d %s\r\n", "HTTP/1.1", status, title);}// 添加 消息报头,具体的,添加 文本长度,连接状态,空行
bool http_conn::add_headers(int content_len)
{add_content_length(content_len);add_linger();add_blank_line();
}// 添加 Content-Length,响应报文长度
bool http_conn::add_content_length(int content_len)
{return add_response("Content-Length:%d\r\n", content_len);
}// 添加 文本类型,这里是 html
bool http_conn::add_content_type()
{return add_response("Content-Type:%s\r\n", "text/html");
}// 添加 连接状态,通知浏览器 保持连接 还是 关闭
bool http_conn::add_linger()
{return add_response("Connection:%s\r\n", (m_linger==true)?"keep-alive":"close");
}// 添加空行
bool http_conn::add_blank_line()
{return add_response("%s", "\r\n");
}// 添加 文本 content
bool http_conn::add_content(const char* content)
{return add_response("%s", content);
}响应报文分 2 种
一种是 请求文件存在,通过 io 向量机制 iovec
声明两个 iovec,第一个指向 m_write_buf,第二个指向 mmap 的地址 m_file_address
另一种是 请求出错,此时,只申请一个 iovec,指向 m_write_buf
- iovec 是一个结构体,里面有 2 个元素,指针成员 iov_base 指向一个缓冲区,这个缓冲区存放 writev 要发送的数据
- 成员 iov_len 表示 实际写入的长度
bool http_conn::process_write(HTTP_CODE ret)
{switch(ret){// 内部错误 500case INTERNAL_ERROR:{// 状态行add_status_line(500, error_500_title);// 消息报头add_headers(strlen(error_500_form));if (!add_content(error_500_form))return falsebreak;}// 报文语法有误,404case BAD_REQUEST:{add_status_line(404, error_404_tile);add_headers(strlen(error_404_form));if (!add_content(error_404_form))return false;break;}// 资源没有访问权限,403case FORBIDDEN_REQUEST:{add_status_line(403, error_403_title);add_headers(strlen(error_403_form));if(!add_content(error_403_form))return false;break;}// 文件存在,200case FILE_REQUEST:{add_status_line(200, ok_200_title);// 如果请求的资源存在if (m_file_stat.st_size != 0){add_headers(m_file_stat.st_size);// 第一个iovec指针指向响应报文缓冲区,长度指向m_write_dixm_iv[0].iov_base = m_write_buf;m_iv[0].iov_len = m_write_idx;// 第二个iovec指针指向mmap返回的文件指针,长度指向文件大小m_iv[0].iov_base = m_write_buf;m_iv[0].iov_len = m_file_stat.st_size;m_iv_count = 2;// 发送的全部数据为响应报文头部信息和文件大小bytes_to_send = m_write_idx + m_file_stat.st_size;return true;}else {// 如果请求的资源大小为 0,返回空白 html 文件const char* ok_string = "<html><body></body></html>";add_headers(strlen(ok_string));if (!add_content(ok_string))return false;}}default:return false;}// 除 FILE_REQUEST 状态外,其余状态只有申请一个 iovec// 指向响应报文缓冲区m_iv[0].iov_base = m_write_buf;m_iv[0].iov_len = m_write_idx;m_iv_count = 1;return true;
}http_conn::write
服务器子线程调用 process_write() 完成 响应报文,随后注册 epollout 事件
服务器主线程监测 写事件,并调用 http_conn::write() 函数,将响应报文发送给浏览器
具体逻辑👇
生成响应报文时初始化 byte_to_send,包括 头部信息 和 文件数据大小
通过 writev() 函数,循环发送响应报文数据,根据返回值更新 byte_have_send 和 iovec 结构体指针和长度,并判断响应报文整体是否发送成功
- 若 writev() 单次发送成功,更新 byte_to_send 和 byte_have_send 大小;
若响应报文整体发送成功,则取消 mmap 映射,并判断 是否长连接
- 长连接 -- 重置 http 类实例,注册读事件,不关闭连接
- 短链接 -- 直接关闭连接
- 若 writev() 单次发送不成功,判断 是否 缓冲区满了
- 若不是因为缓冲区满了失败,取消 mmap 映射,关闭连接
- 若 eagain 则缓冲区满了,更新 iovec 结构体的指针和长度,并注册写事件,等待下一次写事件触发
(当写缓冲区从不可写变为可写,触发 epollout)
在这期间,无法立即接收同一用户的下一请求,但可以保证连接的完整性
bool http_conn::wirte()
{int temp = 0;int newadd = 0;// 若要发送的数据长度为 0// 表示响应报文为空,一般不会出现该情况if (bytes_to_send == 0){modfd(m_epollfd, m_sockfd, EPOLLIN);init();return true;}while (1){// 将响应报文的状态行,消息头,空行,响应正文// 发送给浏览器temp = writev(m_sockfd, m_iv, m_iv_count);// 正常发送,temp 为发送的字节数if (temp > 0) {// 更新已发送字节bytes_have_send += temp;// 偏移文件 iovec 的指针newadd = bytes_have_send - m_write_idx;}if (temp <= -1) {// 判断缓冲区是否满了if (errno == EAGAIN) {// 第一个iovec头部信息的数据已发送完,发送第二个iovecif (bytes_have_send >= m_iv[0].iov_len) {// 不再继续发送头部信息m_iv[0].iov_len = 0;m_iv[1].iov_base = m_file_address + newadd;m_iv[1].iov_len = bytes_to_send;}// 继续发送第一个iovec头部信息的数据else {m_iv[0].iov_base = m_write_buf + bytes_to_send;m_iv[0].iov_len = m_iv[0].iov_len - bytes_have_send;}// 重新注册写事件modfd(m_epollfd, m_sockfd, EPOLLOUT);return true;}// 发送失败,但不是缓冲区问题,取消映射unmap();return false;}// 更新已发送 字节数bytes_to_send -= temp;// 判断条件,数据已全部发送完if (bytes_to_send <= 0) {ummap();// 在 epoll 树上重置 EPOLLONESHOT 事件modfd(m_epollfd, m_sockfd, EPOLLIN);// 浏览器的请求为 长连接if (m_linger) {// 重新初始化 HTTP 对象init();return true;}elsereturn false;}}
}《Linux高性能服务器》中, http_conn::write() 函数不够严谨,这里对其中的 BUG 进行了修复
-->👇
可以正常传输大文件






![[C# WPF] DataGrid选中行或选中单元格的背景和字体颜色修改](https://img-blog.csdnimg.cn/direct/d0c8baa916914d49b8b986a9e39bf959.png)