人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客
本篇目录
一、什么是神经网络模型
二、机器学习的类型
2.1 监督学习
2.2 无监督学习
2.3 半监督学习
2.4 强化学习
三、网络模型结构基础
3.1 单层网络
编辑
3.2 多层网络
3.3 非线性多层网络
四、 神经网络解决回归问题实操:使用Python和NumPy实现波士顿房价预测任务
一、什么是神经网络模型
简而言之:神经网络模型是拟合现实问题的函数方程,通过输入得到输出。
只不过这个函数是用神经网络的参数来拟合的,神经网络的参数是通过大量数据的训练获得,训练效果越好,则函数越逼近现实情况,就可以用来解决各种实际任务。
一个简单的网络模型函数如下:
y=w1*x1 + w2*x2 + w3*x3...
其中,y是函数值(模型输出的预测值),x1,x2, x3...是输入值(又叫特征值),w1, w2, w3...是网络参数。
机器学习最根本的目的在于训练出在某个问题上泛化能力强的模型。泛化能力强是指在某问题的所有数据上都能很好地反应输入和输出之间的关系,无论是训练数据,还是测试数据,还是任何属于该问题的未知数据
神经网络经常处理的问题包括:回归问题,图像分类问题,目标检测问题,自然语言处理,喜好推荐等等。
二、机器学习的类型
根据训练期间接受的监督数量和监督类型,可以将机器学习分为以下四种类型:监督学习、非监督学习、半监督学习和强化学习。
2.1 监督学习
在监督学习中,提供给算法的包含所需解决方案的训练数据,成为标签或标记。

简单地说,就是监督学习是包含自变量和因变量(有Y),同时可以用于分类和回归。下来常见的算法都是监督学习算法。
- K近邻算法
- 线性回归
- logistic回归
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
2.2 无监督学习
无监督学习的训练数据都是未经标记的,算法会在没有指导的情况下自动学习。

简单地说,就是训练数据只有自变量没有因变量(就是没有Y)。
无监督学习的常见算法如下:
- 聚类算法
- K均值算法(K-means)
- 基于密度的聚类方法(DBSCAN)
- 最大期望算法
- 可视化和降维
- 主成分分析
- 核主成分分析
- 关联规则学习
- Apriori
- Eclat
比如说,我们有大量的购物访客的数据,包括一个月内的到达次数、购买次数、平均客单价、购物时长、购物种类、数量等,我们可以通过聚类算法,自动的把这些人分成几个类别,分类后,我们可以人工的把这些分类标记,如企业客户、家庭主妇等,也可以分成更细的分类。

另一种任务是降维,降维的目的在于不丢失太多的信息的情况下简化数据。方法之一就是讲多个特征合并为一个特征,特变是特征之间存在很大的相关性的变量。如汽车的里程和使用年限是存在很大的相关性的,所以降维算法可以将它们合并为一个表示汽车磨损的特征。这个过程就叫做特征提取。
另一个典型的无监督学习的是异常检测,如可以从检测信用卡交易中发现异常,并且这些异常我们实现没有标记的,算法可以自动发现异常。

2.3 半监督学习
有些算法可以处理部分标记的训练数据,通常是大量未标记的数据和少量标记的数据,这种成为半监督学习。
如照片识别就是很好的例子。在线相册可以指定识别同一个人的照片(无监督学习),当你把这些同一个人增加一个标签的后,新的有同一个人的照片就自动帮你加上标签了。
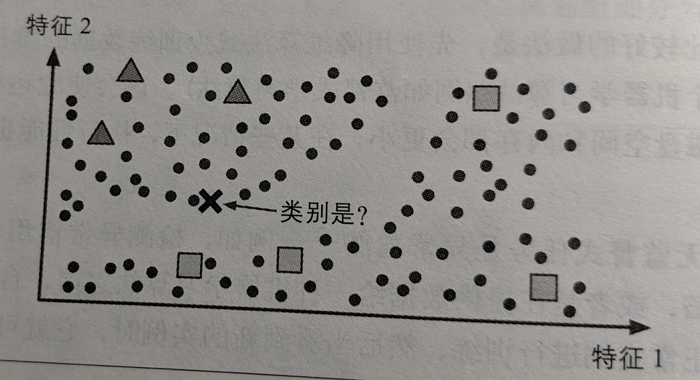
大多数半监督学习算法都是无监督和监督算法的结合。例如深度信念网络(DBN)基于一种相互堆叠的无监督式组件。
2.4 强化学习
强化学习是一个非常与众不同的算法,它的学习系统能够观测环境,做出选择,执行操作并获得回报,或者是以负面回报的形式获得惩罚。它必须自行学习什么是最好的策略,从而随着时间推移获得最大的回报。

例如,许多机器人通过强化学习算法来学习如何行走。AlphaGo项目也是一个强化学习的好例子。
三、网络模型结构基础
3.1 单层网络
(输入层) --w--> (输出层)
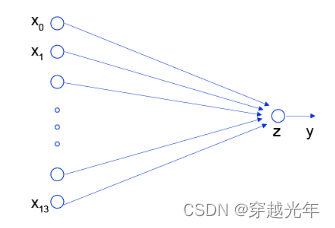
3.2 多层网络
(输入层) --w--> (隐含层) --w--> (隐含层) ... --> (输出层)
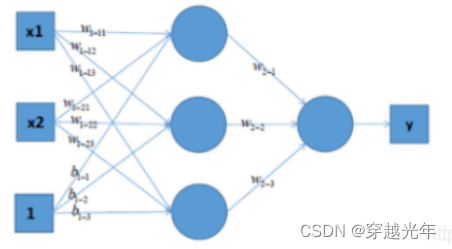
3.3 非线性多层网络
单层网络和多层网络默认只能表达线性变换,加入非线性激活函数后,可以表达非线性函数:
(输入层) --w--> (隐含层) --> (激活函数) --w--> (隐含层) --> (激活函数) ... --> (输出层)

加入非线性激励函数后,神经网络就有可能学习到平滑的曲线来分割平面,而不是用复杂的线性组合逼近平滑曲线来分割平面,使神经网络的表示能力更强了,能够更好的拟合目标函数。 这就是为什么我们要有非线性的激活函数的原因。
关于激活函数,可以参考:卷积神经网络中的激活函数sigmoid、tanh、relu_卷积神经网络激活函数_chaiky的博客-CSDN博客
四、 神经网络解决回归问题实操:使用Python和NumPy实现波士顿房价预测任务
神经网络模型预测数据中比较常见的是回归问题,根据输入的数值得到输出的数值。使用Python来实现波士顿房价预测是AI课程里类似“hello world”的经典入门案例,主要有以下一些要点需注意:
1. 样本数据需要归一化,使得后续的神经网络模型参数可表征有效的权重。样本数据归一化是以列(特征值)为单位的。注意,在用测试集测试模型时,模型输出的函数预测值需要进行反归一化。
2. 数据集划分:80%用于训练,20%用于测试,训练和测试数据集必须分开,才能验证网络的有效性。
3. 影响波士顿房价的样本数据有13个特征值,每个特征值会有不同的权重,因此神经网络模型的可调参数为13个,分别代表不同特征值对最终房价影响的权重:y=w1*x1 + w2*x2 + ... +w13*x13
4. 损失函数是模型输出的值与样本数据中实际值偏差的一种表达函数,损失函数的选择既要考虑准确衡量问题的“合理性”,也还要考虑“易于优化求解”。
5. 训练过程就是通过不断调整网络模型参数,将损失函数的值降到最小(收敛)的过程, 损失函数的收敛需要通过梯度下降法来不断训练。以房价预测任务为例,影响房价的特征值有13个,因此我们需要调教的模型参数也是13个,这13个特征值和损失函数的值共同构成一个14维的空间,在这个空间中存在一个方向(13个参数构成向量决定这个方向)使得损失函数的值(预测值和实际值之偏差)下降最快。我们步进地将13个参数构成的向量朝此方向做出微调,再重新计算损失函数的值,如此往复,直到损失函数的值收敛趋于最小,则参数训练完成。
6. 数据集采用分批训练的方式,batch的取值会影响模型训练效果,batch过大,会增大内存消耗和计算时间,且训练效果并不会明显提升(每次参数只向梯度反方向移动一小步,因此方向没必要特别精确);batch过小,每个batch的样本数据没有统计意义,计算的梯度方向可能偏差较大。由于房价预测模型的训练数据集较小,因此将batch设置为10

Python源码 - 波士顿房价模型训练及测试:
# 导入需要用到的package
import numpy as np
import json
import matplotlib.pyplot as pltdef load_data():# 从文件导入数据datafile = './work/housing.data'data = np.fromfile(datafile, sep=' ')# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算训练集的最大值,最小值(找的是每一列的极值)global maximums, minimums#maximums, minimums = data.max(axis=0), data.min(axis=0)maximums, minimums = training_data.max(axis=0), training_data.min(axis=0)#print("max:", maximums, "min:", minimums)# 对数据进行归一化处理,按列归一化处理for i in range(feature_num):data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])#print("归一化后的数据:\n", data)# 训练集和测试集的划分比例training_data = data[:offset]test_data = data[offset:]return training_data, test_data# 获取数据
training_data, test_data = load_data()
x = training_data[:, :-1] #所有行+所有列(除了最后一列)
y = training_data[:, -1:] #所有行+最后一列#w = [1, 2, 3] #shape = (3,)
#w = [[1], [2], [3]] #shape = (3,1)
#w = [[1,1], [2,2], [3,3]] #shape = (3,2)
#x = np.array(w)
# 查看数据
#print(x.shape)
#print(y.shape)class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,# 此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)#print("init self.w", self.w)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.b #x是[404,13]的矩阵(404行,13列), w是[13, 1]的矩阵(13行,1列),做点乘return zdef loss(self, z, y):error = z - y#print(error.shape)cost = error * errorcost = np.mean(cost)return costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*x #梯度公式gradient_w = np.mean(gradient_w, axis=0) #对各列求均值gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b) return gradient_w, gradient_bdef update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_bdef train(self, x, y, iterations=100, eta=0.01):losses = []for i in range(iterations):z = self.forward(x)L = self.loss(z, y)gradient_w, gradient_b = self.gradient(x, y)self.update(gradient_w, gradient_b, eta)losses.append(L)if (i+1) % 10000 == 0:print('iter {}, loss {}'.format(i, L))return losses# 运行模式一:每次用所有数据进行训练
train_data, test_data = load_data()
x = train_data[:, :-1]
#print("x.shape:", x.shape)
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=100000
# 启动训练
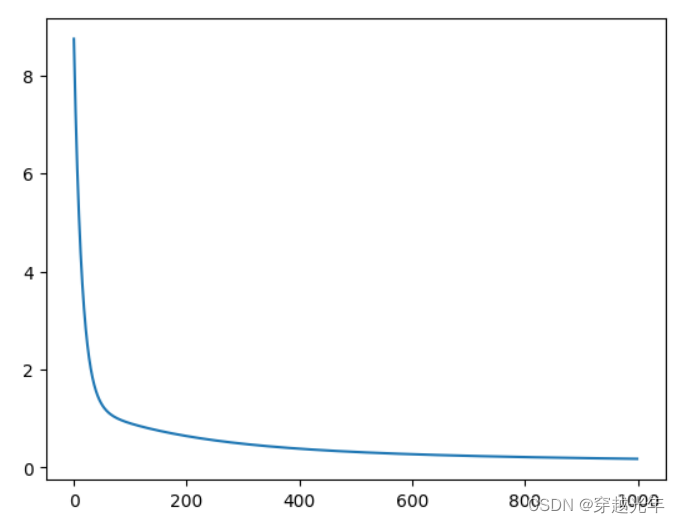
losses = net.train(x,y, iterations=num_iterations, eta=0.01)# 画出损失函数的变化趋势
"""
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
"""#对数据做反归一化处理
def restore_data(d):d = d* (maximums[-1] - minimums[-1]) + minimums[-1]return round(d,2)#用测试集做测试
print("测试集测试结果:")
x = test_data[:, :-1]
y = test_data[:, -1:]
z = net.forward(x)
print("样本数据", "\t", "预测数据")
print("-------------------------")
for i in range(x.shape[0]):print(restore_data(y[i][0]), "\t\t", restore_data(z[i][0]))



![[C# WPF] DataGrid选中行或选中单元格的背景和字体颜色修改](https://img-blog.csdnimg.cn/direct/d0c8baa916914d49b8b986a9e39bf959.png)