Text2MDT :从医学指南中,构建医学决策树
- 提出背景
- Text2MDT 逻辑
- Text2MDT 实现
- 框架
- 管道化框架
- 端到端框架
- 效果
提出背景
论文:https://arxiv.org/pdf/2401.02034.pdf
代码:https://github.com/michael-wzhu/text2dt
假设我们有一本医学指南,其中包含关于诊断和治疗某种疾病的指导。
首先,通过标准化和结构化的方法,我们定义出哪些文本片段表示条件判断(例如,病人年龄超过60岁),哪些表示决策(例如,使用药物A治疗)。
然后,使用构建的Text2MDT基准数据集训练NLP模型,使其能够从类似的医学文本中自动识别和提取这些条件判断和决策。
最终,通过应用预训练模型和特定的算法流程,从文本中抽取出的信息被转化成一个结构化的MDT,明确显示了从条件判断到最终决策的完整路径。
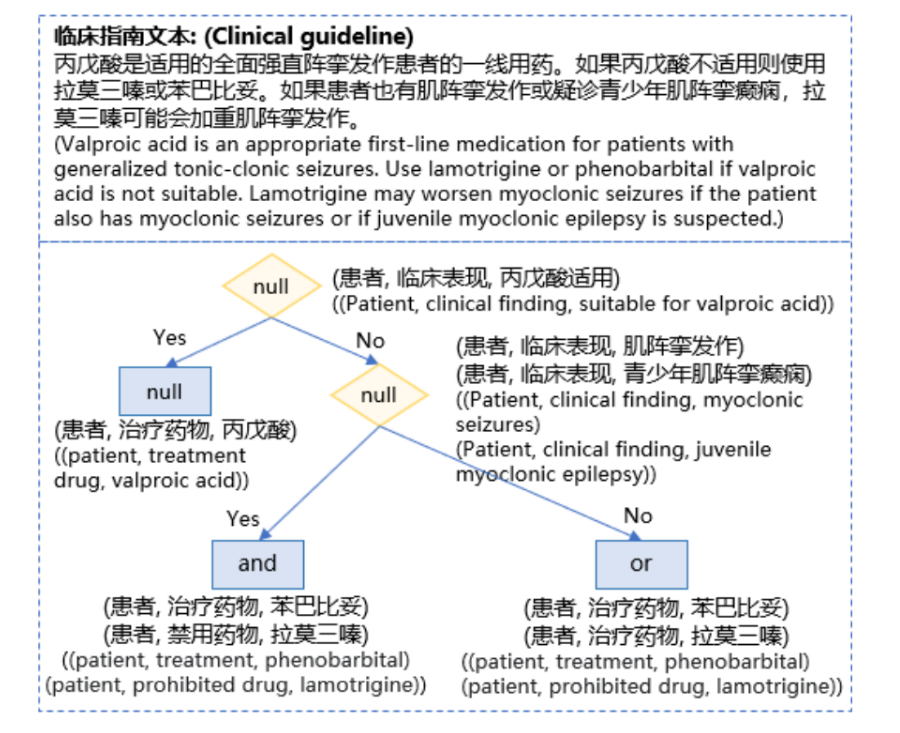
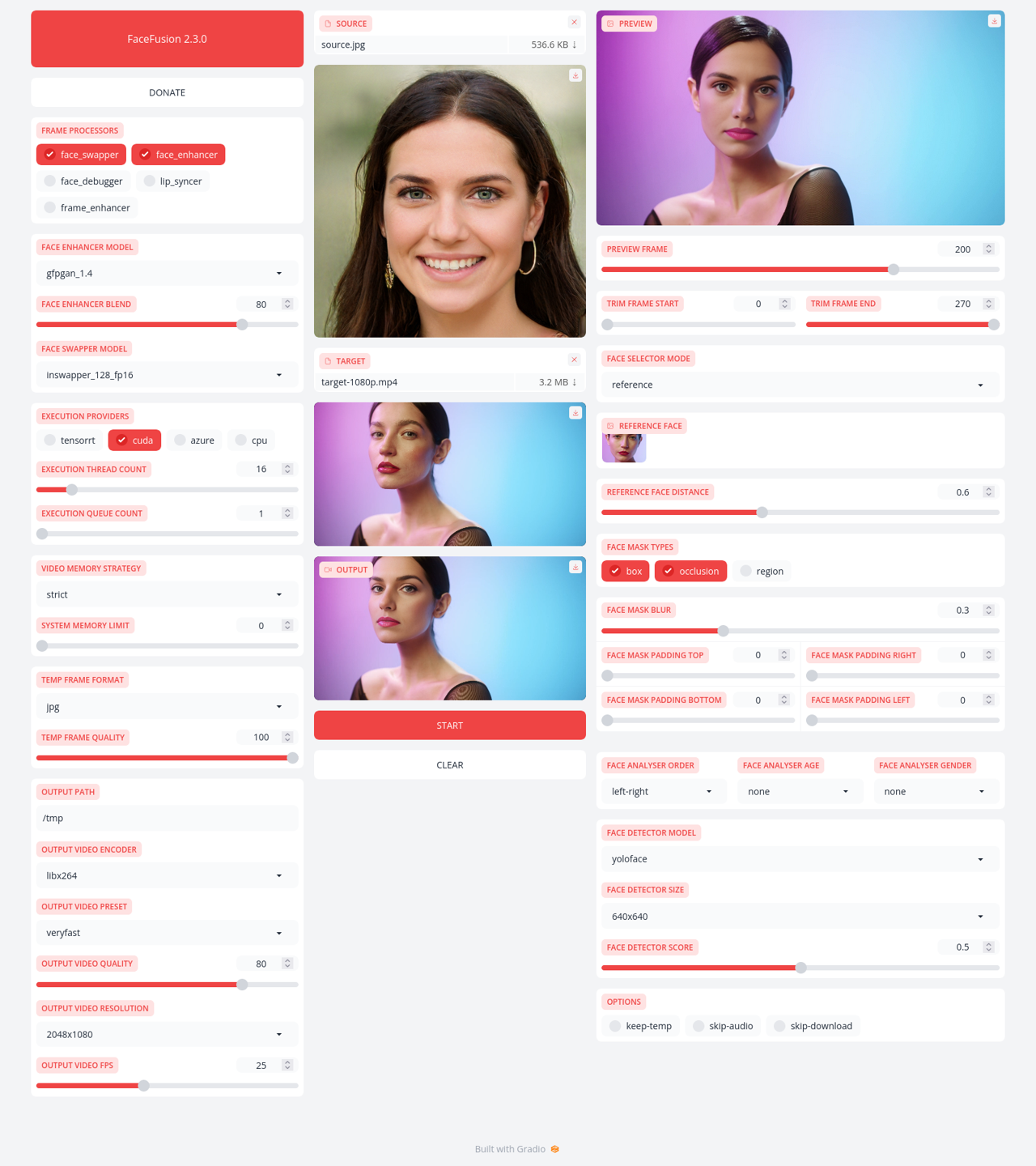
这张图展示的是一个医学决策树(MDT),用于辅助医学决策过程。
是根据某个癫痫临床指南中的内容构建的。
决策树的每个节点代表一个临床决策点,其中包含条件(橙色菱形)和决策节点(蓝色矩形)。
图决策树是这样的:
-
最顶部的框包含了一个临床指南建议:对于普通强直-阵挛发作的患者,首选药物是丙戊酸(Valproic acid)。如果丙戊酸不适合,可以使用拉莫三嗪(Lamotrigine)或苯巴比妥(Phenobarbital)。如果患者还有肌阵挛发作或疑似有儿童肌阵挛发作,则不适合使用拉莫三嗪。
-
在决策树的左侧,如果患者对丙戊酸适应(“Yes”),则继续向下走,如果不适应(“No”),则考虑其他药物。
-
在左侧分支中,如果患者对丙戊酸适应且有其他指定条件(在图中以"null"表示),则选择使用丙戊酸。
-
在右侧分支中,首先判断患者是否有肌阵挛发作,如果没有(“No”),则选择使用苯巴比妥;如果有(“Yes”),则进一步判断是否是儿童肌阵挛发作,是的话(“Yes”),避免使用拉莫三嗪,否则(“No”),使用苯巴比妥或拉莫三嗪。
这种决策树是临床决策支持系统中的一个工具,可以帮助医生根据患者具体情况作出更加精确的药物选择。英文翻译已在图中的括号中提供。
Text2MDT 逻辑
问题:如何从非结构化的医学文本中提取结构化的知识,并构建医学决策树(MDTs)。
解法:Text2MDT 逻辑(从文本到医学决策树的自动化提取)
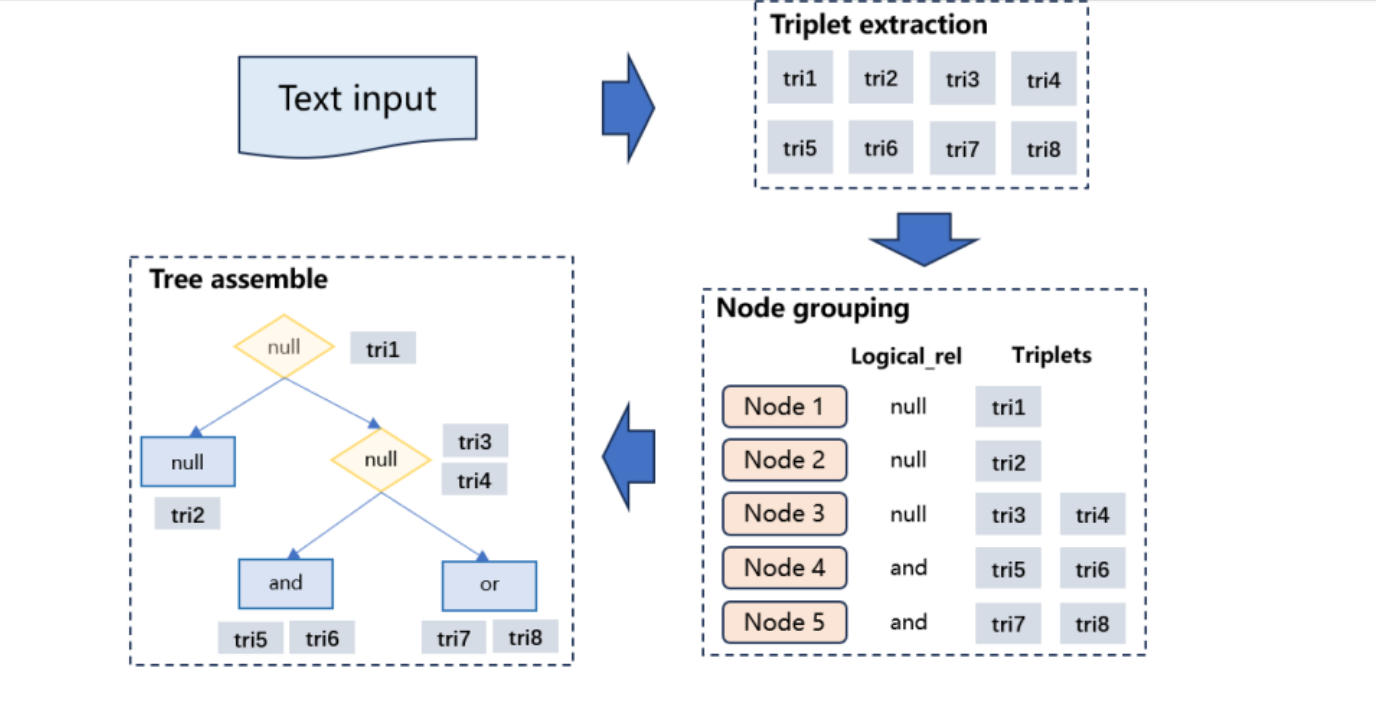
文本输入: 表示任务的起始点,输入的是医学文本。
三元组提取: 从文本中提取出主体、关系、客体组成的三元组信息。
节点分组: 根据三元组和逻辑关系(如AND、OR)将提取的信息分组到不同的节点。
树组装: 将节点按照逻辑关系组装成一个完整的决策树。
特征1 (节点角色识别):识别决策树中的节点角色,区分条件节点(表示为菱形)和决策节点(表示为矩形)。
首先,我们识别出文本中描述病人状态的部分,这将构成条件节点;然后识别出治疗方案的部分,这将构成决策节点。
为什么需要节点角色识别?
因为医学决策树需要区分条件和决策,这是逻辑流程中的关键部分。
特征2 (三元组提取):从医学文本中提取三元组,每个三元组由主体(sub)、关系(rel)、客体(obj)组成,用于描述医学内容。
从这些部分中提取三元组。例如,如果文本说“如果患者对药物A过敏,使用药物B”,我们将提取三元组(患者,对…过敏,药物A)和(使用,药物,药物B)。
为什么需要三元组提取?
因为决策树的每个节点都基于一组特定的医学事实,这些事实最好以结构化的数据表示,例如三元组。
特征3 (逻辑关系理解):确定节点内三元组之间的逻辑关系,可能是AND、OR或NULL(不存在明确关系)。
确定三元组之间的逻辑关系。在这个例子中,因为药物B的使用取决于对药物A的过敏反应,我们可能会标记这个关系为条件关系(IF-THEN)。
为什么需要理解逻辑关系?
因为医学决策是基于一系列逻辑关系,正确理解这些关系对于构建准确的决策树至关重要。
特征4 (条件判断映射):将条件节点中的条件判断映射到决策树的分支逻辑,即根据条件判断结果是"Yes"或"No"决定接下来的路径。
在决策树中,如果条件判断为“Yes”,我们会向左移动到决策树的下一个节点;如果为“No”,则向右。
为什么需要条件判断映射?
因为决策树的路径取决于条件判断的结果,映射这些结果对于树的结构和最终的决策路径至关重要。
特征5 (决策序列生成):生成节点的预定序列来唯一表示医学决策树。
确定节点的预定序列。
根据前面的条件和决策,我们可以构建一个节点序列,从而生成整个决策树。
为什么需要生成决策序列?
因为最终的目标是生成一个可以代表医学决策过程的结构化决策树,而这需要所有节点和路径按特定顺序排列。
Text2MDT 实现
Text2MDT 实现 = 特征1 + 特征2 + 特征3 + 特征4 + 特征5
特征1:预训练语言模型的应用
- 描述:利用像BERT这样的预训练语言模型(PLMs)来处理医学NLP任务。
特征2:信息提取技术的发展
- 描述:应用不同的模型架构,如Seq2Seq生成模型,来处理不同的细粒度信息提取任务。
特征3:医学信息提取的特殊性
- 描述:考虑医学领域中不连续或嵌套实体的复杂性,以及条件三元组的概念。
特征4:Text2Tree任务的历史和应用
- 描述:从给定文本中提取树结构的NLP任务,如句法分析和语义分析。
特征5:模型架构的趋势
- 描述:从专门的模型过渡到更统一的模型架构,比如利用预训练的编码器模型来提高Text2Tree任务的性能。
例如,在处理一篇关于糖尿病治疗的论文时,模型首先识别出治疗方案、药物剂量和患者条件等实体。
然后,它使用Seq2Seq模型来理解这些实体如何在不同条件下相互作用,比如哪些药物是在餐前使用,哪些是餐后使用。
再接着,模型识别出特定的医学条件三元组,例如,某种药物可能只适用于2型糖尿病患者。
最后,所有这些信息被整合成一个决策树,其中每个节点根据患者的具体情况指导特定的医疗行为。
例如,根节点可能是“患者是否有心脏疾病的病史”,如果答案是肯定的,那么下一个节点可能是“是否应该减少某种药物的剂量”。
而如果答案是否定的,下一个节点可能是“是否可以使用标准剂量”。
这个统一的模型框架可以自动化地从医学文本中提取这些决策点,并构建成一个有助于医生和病人理解和遵循的决策树。
通过这种方式,Text2MDT任务可以帮助将大量的非结构化医学知识转化为结构化的、可操作的决策支持工具。
框架
Text2MDT任务的模型化方法被拆解为两个主要框架:
- 管道化(pipelined)框架
- 端到端(end-to-end)框架
由于没有现有的神经网络方法能直接处理这个新颖的任务,作者提出了两种方法群体:
-
(a) 管道化方法:将Text2MDT任务分解为三个子任务,并利用现有的方法来完成这些子任务。
-
(b) 端到端方法:这是一个具有挑战性的方法,不能由基于编码器的模型处理。研究中利用了最新的开源大型语言模型(LLM)和思路链提示方法(chain-of-thought prompting)来应对端到端方法。
管道化框架
管道化框架将Text2MDT任务分为三个主要步骤:
-
三元组提取:
- 使用统一的三元组提取模型(TEModel)从医学文本中提取代表决策或条件的三元组。
- 三元组由实体对和它们之间的关系组成,关系类型由之前提到的表格定义。
-
节点分组:
- 将提取出的三元组根据逻辑关系分组成不同的节点,这些节点将成为MDT的主要组成部分。
- 使用节点分组双仿射模型(NG-Biaffine)来实现这一步骤。
-
树组装:
- 组装节点以构建医学决策树,涉及为每个节点分配角色(条件或决策)以及确定节点间的连接。
- 树组装也可以看作是实体类型分类和关系提取的联合任务。
端到端框架
端到端框架考虑使用生成性语言模型来一次性完成整个Text2MDT任务。这种方法的关键特点包括:
-
直接生成:
- 询问语言模型(LM)直接根据文本输入生成整个MDT。
-
COT风格生成:
- 鉴于任务的复杂性,考虑了不同的COT风格提示和响应,例如:
- COT-Generation-1: 按照管道框架的步骤,让LM首先生成三元组,然后进行节点分组,最后组装树。
- COT-Generation-2: 将任务分解为更细粒度的子任务,如先生成实体,然后三元组,接着节点分配和角色,最后整个树。
- COT-Generation-3: 要求LM首先提取三元组,然后生成整个MDT。
- COT-Generation-4: 进一步分解三元组提取子任务,让LM先提取实体,然后生成三元组,最后生成整个MDT。
- 鉴于任务的复杂性,考虑了不同的COT风格提示和响应,例如:
管道化框架通过逐步处理每个任务的子部分,逐渐建立起决策树的结构。
而端到端框架则利用生成性语言模型的能力,一次性或通过COT风格的逐步推理生成完整的决策树。
这两种框架各有优势:管道化框架的模块化设计使问题变得更容易管理和优化,而端到端框架更直接和效率高,但需要更复杂的数据处理和训练过程。
效果
Ground Truth(实际情况)、Prediction(预测):
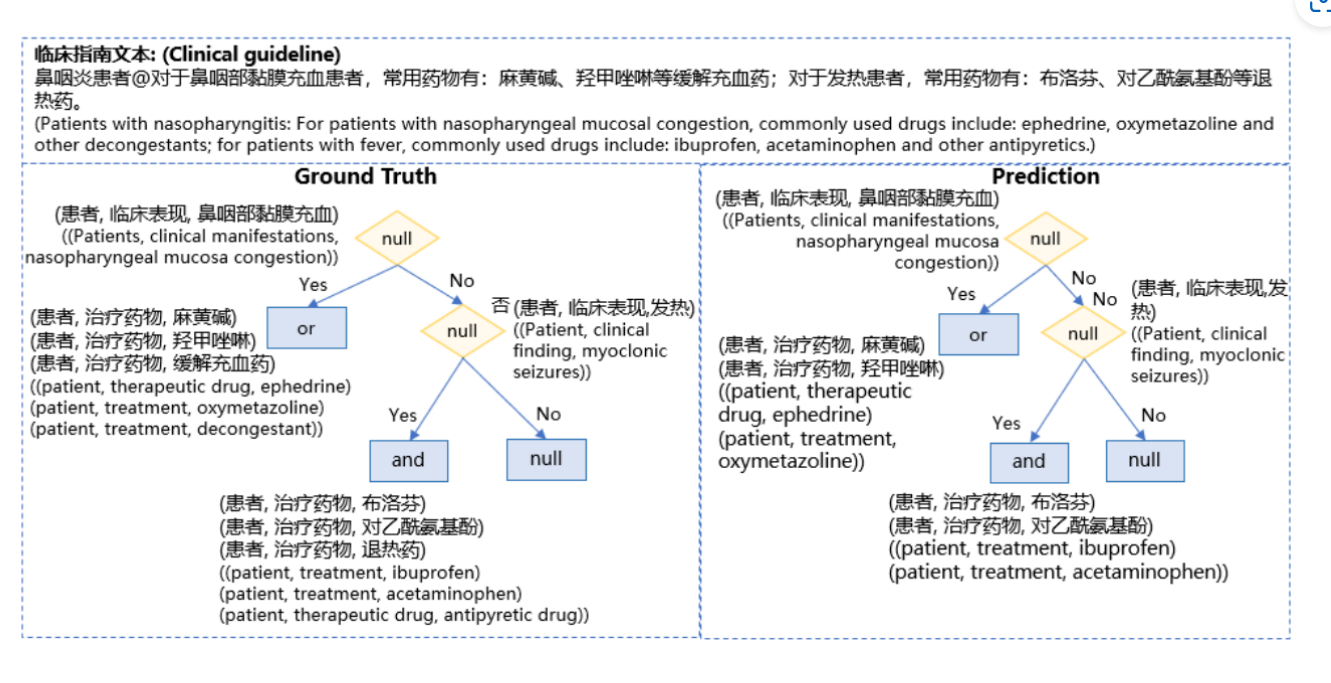
临床指南提及患有鼻咽炎的患者通常会使用的药物,包括治疗鼻塞、发烧时常用的药物,如布洛芬、对乙酰氨基酚等。
- Ground Truth中提及了正确的药物和情况,包括使用药物治疗鼻塞的情况。
- Prediction部分出现错误,它没有预测出应使用的药物,比如未能预测布洛芬和对乙酰氨基酚。

临床指南提及对于低钠血症且年龄超过65岁的男性患者,不建议使用去氨加压素。
- Ground Truth正确识别了患者的基本情况以及不应该使用去氨加压素的指南。
- Prediction部分未能正确预测不应使用去氨加压素,而是错误地将其作为治疗药物。
目前系统的局限性包括:
- 节点的逻辑表达受限,仅限于“和”和“或”逻辑关系,而在更复杂的情况下,可能需要多种逻辑关系的组合。
- 树的表现力有限,当前的决策树在达到一个决策点后就终止,但实际场景应该是一个连续判断和决策的过程。
- 文本长度有限,当前方法仅旨在提取一个段落的医学文本,而实际上,医学知识可能需要基于多个部分或章节。
COT-Generation-3 尽管是一个有前途的方法,但它在三元组提取阶段仍有提升空间,特别是在处理复杂的医学知识时。
- COT-Generation-3可能是一个特定版本的Chain of Thought生成模型,而Text2MDT是它试图解决的任务。
该研究表明,虽然Text2MDT模型在处理某些任务上取得了进展,但还存在局限性和改进空间。
未来的工作将需要解决逻辑表达的多样性、决策树的连续性以及处理更长文本的能力,以便更准确地从复杂医学文本中提取MDT。