1. 爬虫的基本原理
爬虫就是在网页上爬行的蜘蛛,每爬到一个节点就能够访问该网页的信息,所以又称为网络蜘蛛;
网络爬虫就是自动化从网页上获取信息、提取信息和保存信息的过程;
2. URL的组成部分
URL全称为Uniform Resource Locator,即统一资源定位符,指定了我们要查找资源的地址。
主机名就是我们要访问的计算机的名字。
2.1 http协议
HyperText Transfer Protocol,简称http,超文本传输协议。
HTTP协议是互联网数据传输的一种规则,它规定了数据的传输方式;
HTTP协议定义了客户端和服务器之间传递消息的内容和步骤。
当URL的协议部分写的是http时,表明服务器传输数据使用的是HTTP协议。
HTTP协议在进行数据传输时,内容是未加密的,传输内容可能被窃听或篡改,安全性比较差。
HTTPS并非是全新的协议,只是在传输之前加了一层保护,让内容安全不易被窃听。
2.2 主机名
“//”为分隔符,表示后面的字符串是主机名。
主机名后面的“/”表明,要在后面写上文件地址,如果不写一般默认为主页。
2.3 文件地址
文件路径能够指定访问资源的具体地址;

3. HTTP请求&响应
(1)HTTP协议:
1. 【浏览器】会先发送HTTP请求,告诉Web服务器需要的数据。
2. 【Web服务器】收到请求后,按照请求执行,并返回HTTP响应消息。
3. 【浏览器】收到返回的数据后,会将源代码解析成网页展示出来。
(2)请求头&&响应头
HTTP发送的请求(Request)消息主要包含两部分“对什么”和“怎么做”;
由于浏览器发送请求时,将“对什么”和“做什么”信息放在头部。所以,存放这些信息的地方又叫请求头;
在HTTP协议中:Web服务器收到请求消息后,会根据请求进行处理。并将响应(Response)消息返回给浏览器;
响应消息的头部叫做响应头(Response Headers),响应头中的数据用于告诉浏览器此次请求执行失败还是成功;
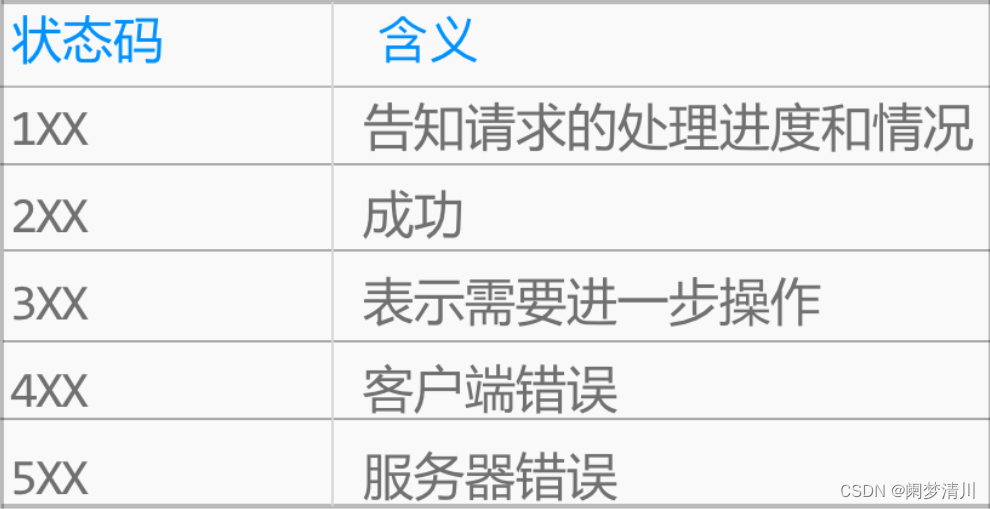
4. 状态码
响应头(Response Headers)中用于告知浏览器执行结果成功或失败的叫做状态码。
状态码是由3位的数字构成的,主要用于告知客户端的HTTP请求的执行结果。
状态码可以让我们了解到服务器是正常执行结果,还是出现了错误。