文章目录
- 背景
- 问题发现
- 排查CSI provision
- 排查kube-controller-manager
- 查看controller log
- 紧急恢复
- 求助chatgpt
- 面试题
- daemonset 的toleration
- kubelet 的配置
- node的status 字段
- k8s 如何保证节点状态?
背景
2023年4月21日10:38:07,在集群中测试RBAC的时候,在kuboard的界面神出鬼没的删除了几个clusterRole。练习一个CKA的练习题目.
Create a new ServiceAccount processor in Namespace project-hamster Create a Role and RoleBinding, both named processor as well. These should allow the new SAto only create Secrets and ConfigMapsin that Namespace
因为我发现每个ns下都有default sa 。 用auth can-i 测试一直没测通
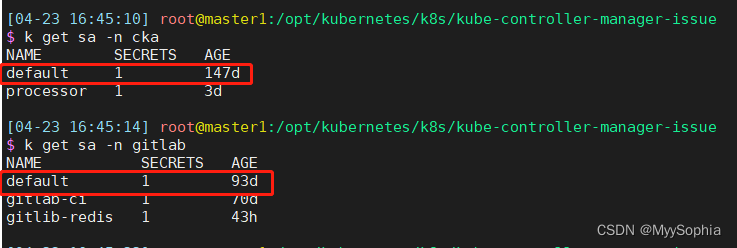
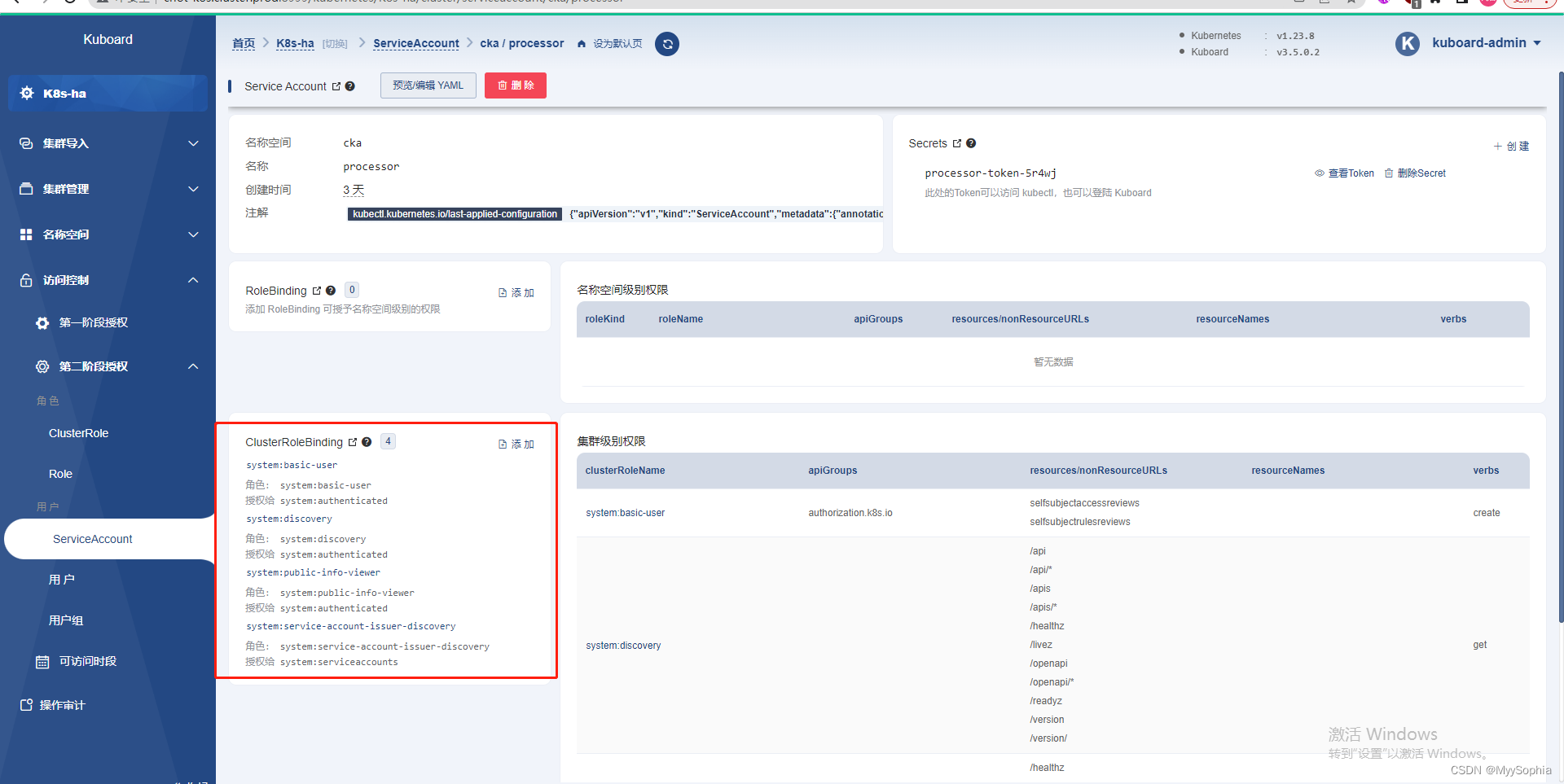
想着要怎么把这个default sa给删除了神不知鬼不觉的就操作了这个界面,删除了几个clusterRolebinding 和clusterrole。

据我记忆就是这个界面.
问题发现
当时这么操作之后并没有及时发现问题 (这里是不是应该有告警?pod 大面积不ready,当时看到的情况是grafana、minio、prometheus、gitlab … 均不能访问,都报503错误码)。
2023年4月21日17:38:07 :创建一个有CSI的pod时,pod一直不ready,一路排查下来发现是pvc一直绑不上pv。

注 : 当时测试不涉及CSI 的pod是可以创建成功的。
排查CSI provision
2023年4月21日22:03:21
使用的是nfs作为持久化存储,nfs-provisioner动态供应。
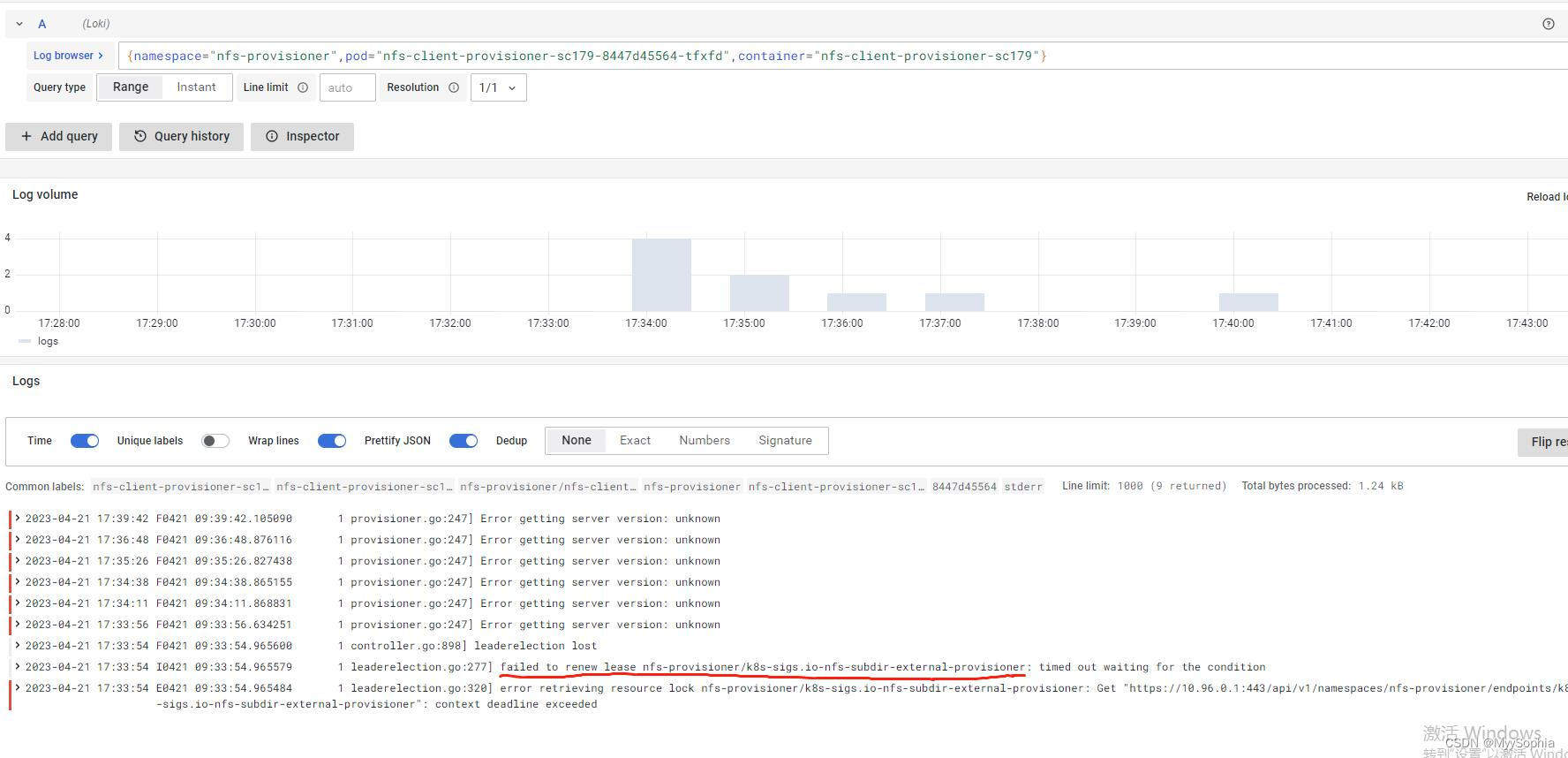
查看 nfs-client-provisioner的日志发现有报错。
lease renew failed, 首先就想到kube-controller-manager和kube-scheduler有问题。
kube-scheduler是负责调度的应该不是问题所在,应该是kube-controller-manager的问题,因为nfs-provisioner本质也是一个controller。controller manager是所有controller的管理者是k8的大脑。
排查kube-controller-manager
这块的排查耗时最久,究其原因是对k8s组件的认证鉴权机制不够了解。
2023年4月23日08:40:29
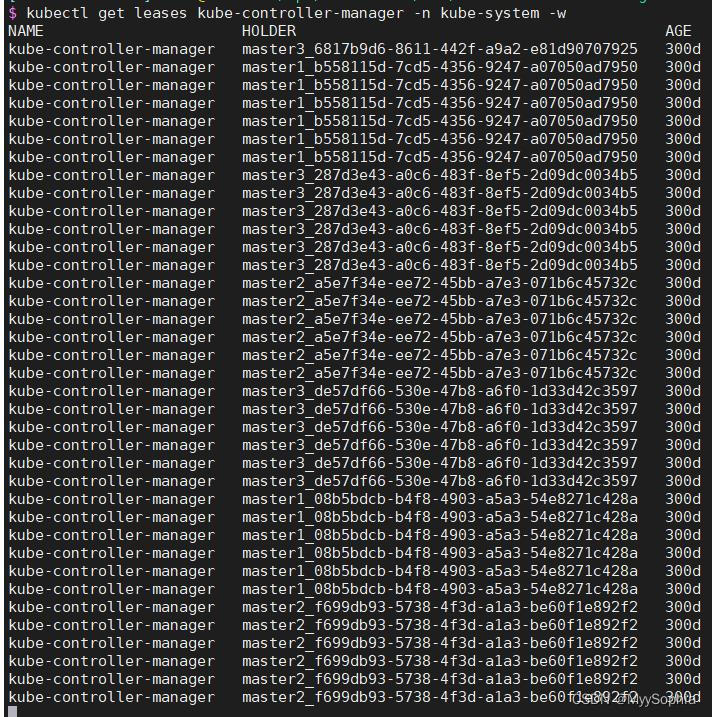
kube-controller-manager 是高可用部署,共三个节点。
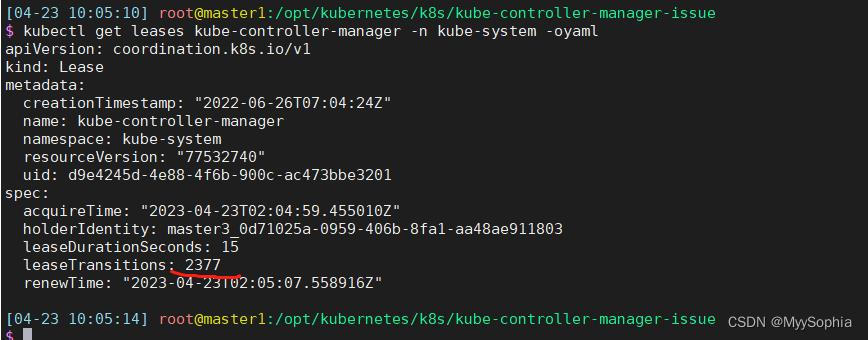
当时发现kube-controller-manager 不停的进行election,不停的重启。
controller election状态
schedule election状态
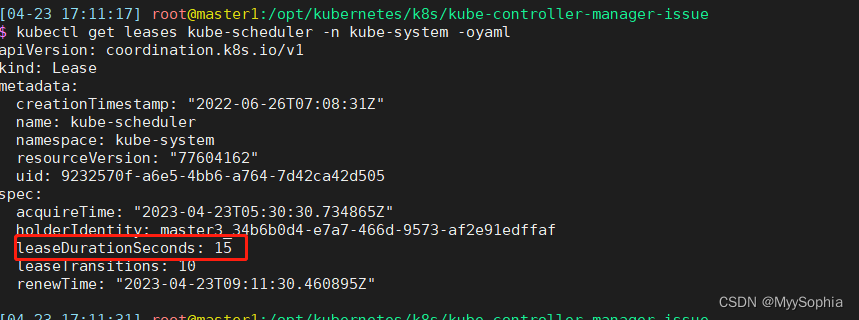
很明显controller的election一直在election 疯狂更新renewtime,这里也能解释nfs-provisioner为何会timeout。因为master一直变来变去。而且每次竞选成功都会有不同的uid。
查看controller log
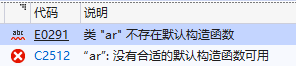
E0423 11:37:21.236103 11401 configmap_cafile_content.go:242] key failed with : missing content for CA bundle "client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file"
F0423 11:37:27.860197 11401 controllermanager.go:233] error building controller context: failed to wait for apiserver being healthy: timed out waiting for the condition: failed to get apiserver /healthz status: forbidden: User "system:kube-controller-manager" cannot get path "/healthz"
goroutine 295 [running]:
k8s.io/kubernetes/vendor/k8s.io/klog/v2.stacks(0x1)/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/klog/v2/klog.go:1038 +0x8a
k8s.io/kubernetes/vendor/k8s.io/klog/v2.(*loggingT).output(0x779aa60, 0x3, 0x0, 0xc0007220e0, 0x0, {0x5f1425a, 0x1}, 0xc000e7c9a0, 0x0)/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/klog/v2/klog.go:987 +0x5fd
k8s.io/kubernetes/vendor/k8s.io/klog/v2.(*loggingT).printf(0x0, 0x0, 0x0, {0x0, 0x0}, {0x477c449, 0x25}, {0xc000e7c9a0, 0x1, 0x1})/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/klog/v2/klog.go:753 +0x1c5
k8s.io/kubernetes/vendor/k8s.io/klog/v2.Fatalf(...)/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/klog/v2/klog.go:1532
k8s.io/kubernetes/cmd/kube-controller-manager/app.Run.func1({0x4e4a690, 0xc00033f080}, 0xc000922b40, 0x48b9d38)/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:233 +0x1bb
k8s.io/kubernetes/cmd/kube-controller-manager/app.Run.func3({0x4e4a690, 0xc00033f080})/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:295 +0xe3
created by k8s.io/kubernetes/vendor/k8s.io/client-go/tools/leaderelection.(*LeaderElector).Run/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/client-go/tools/leaderelection/leaderelection.go:211 +0x154goroutine 1 [select (no cases)]:
k8s.io/kubernetes/cmd/kube-controller-manager/app.Run(0xc000435408, 0xc0000a0360)/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:326 +0x7d7
k8s.io/kubernetes/cmd/kube-controller-manager/app.NewControllerManagerCommand.func2(0xc0008d2500, {0xc000585e40, 0x0, 0x16})/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/app/controllermanager.go:153 +0x2d1
k8s.io/kubernetes/vendor/github.com/spf13/cobra.(*Command).execute(0xc0008d2500, {0xc00004c190, 0x16, 0x17})/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/spf13/cobra/command.go:860 +0x5f8
k8s.io/kubernetes/vendor/github.com/spf13/cobra.(*Command).ExecuteC(0xc0008d2500)/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/spf13/cobra/command.go:974 +0x3bc
k8s.io/kubernetes/vendor/github.com/spf13/cobra.(*Command).Execute(...)/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/github.com/spf13/cobra/command.go:902
k8s.io/kubernetes/vendor/k8s.io/component-base/cli.run(0xc0008d2500)/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/component-base/cli/run.go:146 +0x325
k8s.io/kubernetes/vendor/k8s.io/component-base/cli.Run(0xc0000001a0)/workspace/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/vendor/k8s.io/component-base/cli/run.go:46 +0x1d
main.main()_output/dockerized/go/src/k8s.io/kubernetes/cmd/kube-controller-manager/controller-manager.go:35 +0x1egoroutine 6 [chan receive]:
.....
启动之后第一时间有一个Fatal的日志
error building controller context: failed to wait for apiserver being healthy: timed out waiting for the condition: failed to get apiserver /healthz status: forbidden: User "system:kube-controller-manager" cannot get path "/healthz"
报错说的也比较明显 : controller 无法获取apiserver的健康状况,原因是没权限访问/healthz
–update 2023年7月3日14:24:54
为什么会报这个错误呢?
kube-controller-manager 会每隔–node-monitor-period时间去检查 kubelet 的状态,默认是 5s。但是没有权限get 这个/healthz 。 因为system:kube-controller-manager 这个user被干掉了。
紧急恢复
在另外一个集群把clusterrole 和clusterrolebinding -oyaml找出来重建。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:annotations:rbac.authorization.kubernetes.io/autoupdate: "true"labels:kubernetes.io/bootstrapping: rbac-defaultsname: system:kube-controller-manager
rules:
- apiGroups:- ""- events.k8s.ioresources:- eventsverbs:- create- patch- update
- apiGroups:- coordination.k8s.ioresources:- leasesverbs:- create
- apiGroups:- coordination.k8s.ioresourceNames:- kube-controller-managerresources:- leasesverbs:- get- update
- apiGroups:- ""resources:- endpointsverbs:- create
- apiGroups:- ""resourceNames:- kube-controller-managerresources:- endpointsverbs:- get- update
- apiGroups:- ""resources:- secrets- serviceaccountsverbs:- create
- apiGroups:- ""resources:- secretsverbs:- delete
- apiGroups:- ""resources:- configmaps- namespaces- secrets- serviceaccountsverbs:- get
- apiGroups:- ""resources:- secrets- serviceaccountsverbs:- update
- apiGroups:- authentication.k8s.ioresources:- tokenreviewsverbs:- create
- apiGroups:- authorization.k8s.ioresources:- subjectaccessreviewsverbs:- create
- apiGroups:- '*'resources:- '*'verbs:- list- watch
- apiGroups:- ""resources:- serviceaccounts/tokenverbs:- create---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:annotations:rbac.authorization.kubernetes.io/autoupdate: "true"labels:kubernetes.io/bootstrapping: rbac-defaultsname: system:kube-controller-manager
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:kube-controller-manager
subjects:
- apiGroup: rbac.authorization.k8s.iokind: Username: system:kube-controller-manager重建之后,不再报错/healthz没权限访问的报错。
此时集群还没恢复,controller-manaer还有一个报错:
E0423 13:34:43.469843 10440 configmap_cafile_content.go:242] kube-system/extension-apiserver-authentication failed with : missing content for CA bundle "client-ca::kube-system::thentication::requestheader-client-ca-file"
E0423 13:34:43.470622 10440 configmap_cafile_content.go:242] key failed with : missing content for CA bundle "client-ca::kube-system::extension-apiserver-authentication::request
I0423 13:34:43.469918 10440 tlsconfig.go:178] "Loaded client CA" index=0 certName="client-ca::kube-system::extension-apiserver-authentication::client-ca-file,client-ca::kube-syser-authentication::requestheader-client-ca-file" certDetail="\"kubernetes\" [] groups=[k8s] issuer=\"<self>\" (2022-06-25 15:32:00 +0000 UTC to 2027-06-24 15:32:00 +0000 UTC (now=9890751 +0000 UTC))"求助chatgpt
这种报错在goole上竟然只能搜到1页的内容。在github issue list也没翻出来。只能求助chatgpt了。
根据chatgpt的提示重建了 extension-apiserver-authentication 这个cm。
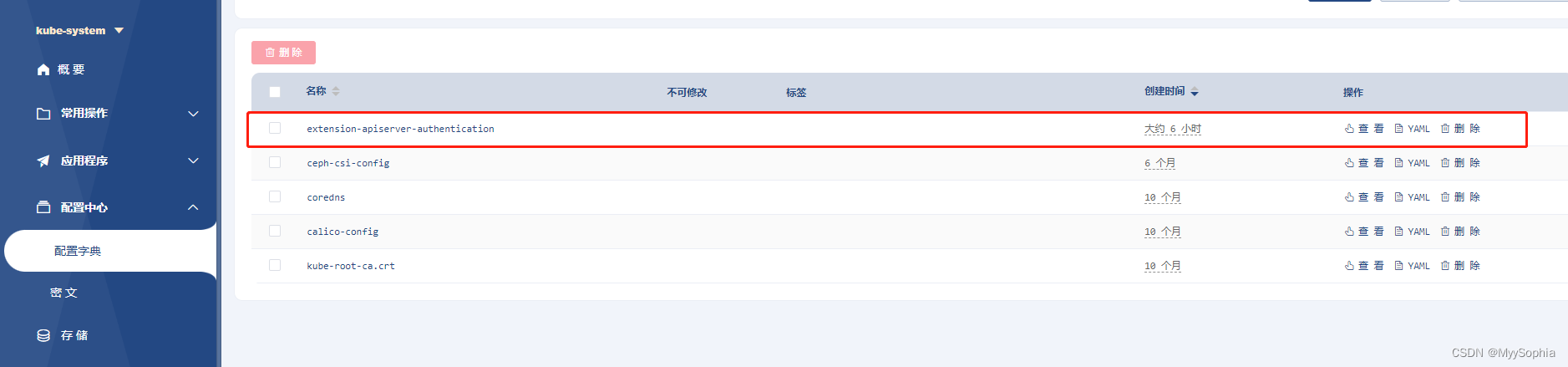
然并卵 …
然后又神不知鬼不觉的重启了一下kube-apiserver。竟然恢复了,原因不知道也可以问chatgpt.

面试题
bitget的一道面试题
面:什么时候节点的pod会被驱逐?
我: 节点承压的时候,内存cpu存储不足,kubelet会根据配置的软驱逐、硬驱逐策略进行驱逐。 或者手动排空节点。但是daemonset 的pod不会被驱逐。
面: 还有没有其他情况?
我: …
面: kubelet 怎么上报节点信息呢?
我: kubelet 会定时上报节点的内存、cpu…资源给kube-apiserver,然后更新node的status字段。具体频率可以在kubelet中的node-status-update-frequency设定(kubelet 向 API 服务器发送其节点状态的频率。 默认是10s)。可以理解为启动一个 goroutine 然后定期向 APIServer 发送消息。
面: 你知道lease对象吗?
我: 知道这个对象,这个类似于一把文件锁,kube-controller-manager、kube-schedule的高可用就是通过不断额更新当前master节点的lease 对象的renewtime来做到高可用的。
面: k8s 1.13之后引入的这个lease对象,每个节点都有一个lease对象,kubelet另外一种心跳方式就是每10s更新这个对象,如果40s未更新,节点就not ready,pod开始驱逐。
…
我就想到了这个惨案。
daemonset 的toleration
可以看到daemonset 很能容忍,not ready/ unreachable / disk-pressure / memory-pressure / pid-pressure / unscheduleable 这些污点都能忍。绝对是最“”忠实“”的负载。
tolerations:- effect: NoExecutekey: node.kubernetes.io/not-readyoperator: Exists- effect: NoExecutekey: node.kubernetes.io/unreachableoperator: Exists- effect: NoSchedulekey: node.kubernetes.io/disk-pressureoperator: Exists- effect: NoSchedulekey: node.kubernetes.io/memory-pressureoperator: Exists- effect: NoSchedulekey: node.kubernetes.io/pid-pressureoperator: Exists- effect: NoSchedulekey: node.kubernetes.io/unschedulableoperator: Existskubelet 的配置
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:anonymous:enabled: falsewebhook:cacheTTL: 0senabled: truex509:clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:mode: Webhookwebhook:cacheAuthorizedTTL: 0scacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
enforceNodeAllocatable:
- pods
evictionHard:imagefs.available: 10%memory.available: 256Minodefs.available: 10%nodefs.inodesFree: 5%
evictionMaxPodGracePeriod: 30
evictionPressureTransitionPeriod: 0s
evictionSoft:imagefs.available: 15%memory.available: 512Minodefs.available: 15%nodefs.inodesFree: 10%
evictionSoftGracePeriod:imagefs.available: 3mmemory.available: 1mnodefs.available: 3mnodefs.inodesFree: 1m
failSwapOn: false
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageGCHighThresholdPercent: 80
imageGCLowThresholdPercent: 70
imageMinimumGCAge: 0s
kind: KubeletConfiguration
kubeReserved:cpu: 200mephemeral-storage: 1Gimemory: 256Mi
kubeReservedCgroup: /kube.slice
logging: {}
maxPods: 200
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 5s
rotateCertificates: true
runtimeRequestTimeout: 5m0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
systemReserved:cpu: 300mephemeral-storage: 1Gimemory: 512Mi
systemReservedCgroup: /system.slice
volumeStatsAggPeriod: 0snode的status 字段
这些字段都是根据kubelet 上报的节点状态进行更新。 会有一个状态的message。
status:addresses:- address: 10.50.10.33type: InternalIP- address: master3type: Hostnameallocatable:cpu: "8"ephemeral-storage: "38634891201"hugepages-2Mi: "0"memory: 16296896Kipods: "110"capacity:cpu: "8"ephemeral-storage: 41921540Kihugepages-2Mi: "0"memory: 16399296Kipods: "110"conditions:- lastHeartbeatTime: "2022-09-06T10:13:43Z"lastTransitionTime: "2022-09-06T10:13:43Z"message: Calico is running on this nodereason: CalicoIsUpstatus: "False"type: NetworkUnavailable- lastHeartbeatTime: "2023-07-03T05:55:15Z"lastTransitionTime: "2023-04-21T09:37:25Z"message: kubelet has sufficient memory availablereason: KubeletHasSufficientMemorystatus: "False"type: MemoryPressure- lastHeartbeatTime: "2023-07-03T05:55:15Z"lastTransitionTime: "2023-06-27T10:35:21Z"message: kubelet has no disk pressurereason: KubeletHasNoDiskPressurestatus: "False"type: DiskPressure- lastHeartbeatTime: "2023-07-03T05:55:15Z"lastTransitionTime: "2023-04-21T09:37:25Z"message: kubelet has sufficient PID availablereason: KubeletHasSufficientPIDstatus: "False"type: PIDPressure- lastHeartbeatTime: "2023-07-03T05:55:15Z"lastTransitionTime: "2023-04-21T09:37:25Z"message: kubelet is posting ready statusreason: KubeletReadystatus: "True"type: ReadydaemonEndpoints:kubeletEndpoint:Port: 10250images:
..... 节点上的众多images
k8s 如何保证节点状态?
Kubernetes 节点发送的心跳帮助你的集群确定每个节点的可用性,并在检测到故障时采取行动。
对于节点,有两种形式的心跳:
更新节点的 .status
kube-node-lease 名字空间中的 Lease(租约)对象。 每个节点都有一个关联的 Lease 对象。
与 Node 的 .status 更新相比,Lease 是一种轻量级资源。 使用 Lease 来表达心跳在大型集群中可以减少这些更新对性能的影响。
kubelet 负责创建和更新节点的 .status,以及更新它们对应的 Lease。
当节点状态发生变化时,或者在配置的时间间隔内没有更新事件时,kubelet 会更新 .status。 .status 更新的默认间隔为 5 分钟(比节点不可达事件的 40 秒默认超时时间长很多)。
kubelet 会创建并每 10 秒(默认更新间隔时间)更新 Lease 对象。 Lease 的更新独立于 Node 的 .status 更新而发生。 如果 Lease 的更新操作失败,kubelet 会采用指数回退机制,从 200 毫秒开始重试, 最长重试间隔为 7 秒钟。