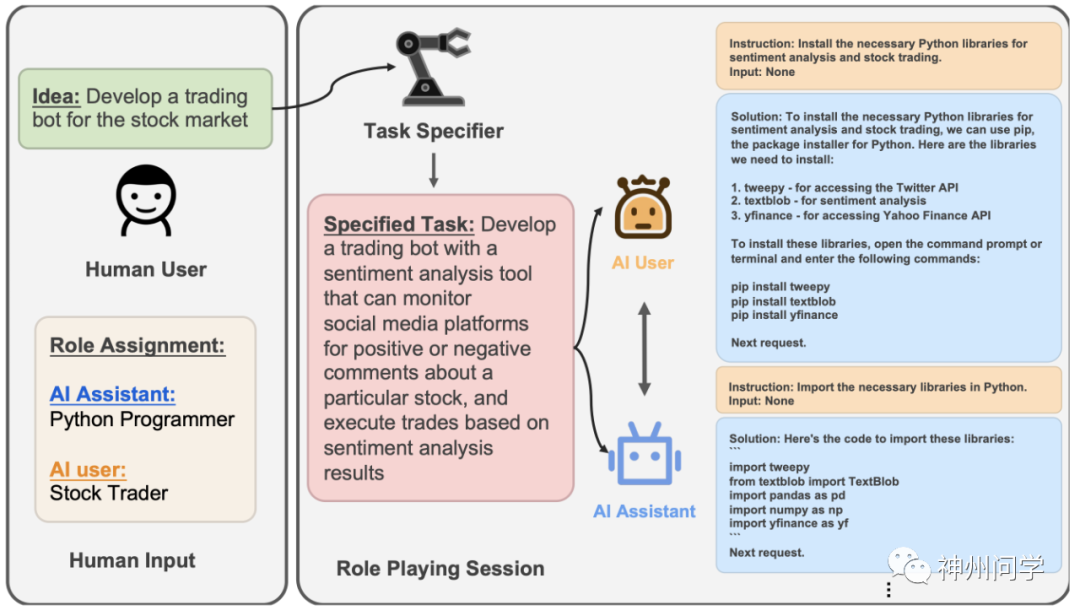
一. 爬虫
- 只爬取公开的信息,不能爬取未公开的后台数据
1.爬虫的合法性
- 法无禁止皆可为 -- 属于法律的灰色地带
- https://www.tencent.com/robots.txt -- 网站/robots.txt 可以查看禁止爬取的内容
2. URL
- Uniform Resource Locator 统一资源定位符
- https://www.baidu.com:443/index.html
3. 协议
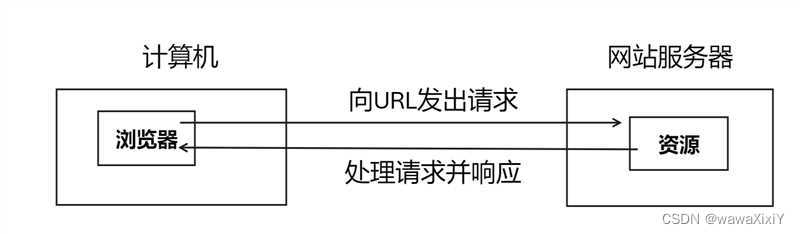
1.http的工作流程基于请求-响应模式:
a.客户端发出请求:
通常是通过浏览器向服务器发出一个http请求,请求包含以下几个部分
- 请求头:Request URL 请求的统一资源定位符、Request Method请求方法(一般get post)
- 元信息(metadata):浏览器类型、编码格式、缓存指令等
- 请求体:如果请求是post方法,可以携带表单等数据
b. 服务器处理请求
服务器会根据请求对请求进行相应的处理:
- 解析请求
- 检查请求是否合法
- 根据请求的方法进行相应的操作,例如查询数据库
- 准备响应
c. 服务器响应客户端
通过响应的方式下发给客户的
- 状态行:http版本号,状态码(200 OK)以及相关说明
- 响应头:内容类型、长度、缓存指令等
- 响应体:包含响应的实际东西:例如html文档、图像、音频等数据
d. 客户端处理响应
浏览器解释响应并且对响应进行展示处理:
- 解析响应
- 根据状态码判断是否成功
- 对响应体进行处理,渲染html页面
4. 爬虫的实现过程
1.获取网络数据
- requests: 一个python第三方库,允许发送http请求,并且获取服务器的响应,常用于网页爬取
- selenium:自动化测试工具,可以驱动浏览器自动运行程序,获取动态网页数据
2.解析数据
- 正则(re模块):使用正则表达式,从原始的html中去提取想要的信息
- bs4(beautifulSoup4):python库,使用css选择器等更加方便的提取html中的结构化数据
3.保存数据
- csv: 以逗号分隔值的结构化数据保存方式
- excel: 电子表格
- 数据库
5.HBuilderX前端项目
1. css文件夹:
存储的是网页样式文件, cascading(层叠) style sheets (层叠样式表)
2.img文件:
存储各种图片
3. js文件夹:
存储 java script 文件
4. index.html
6.requests 的基础内容介绍
import requestsresponse = requests.get(url='https://sh.zu.anjuke.com/')
print(response.status_code)
# 200 成功
# 1xx 服务器返回信息代码 2xx成功状态码 3xx重定向代码 4xx 客户端错误代码 5xx服务器错误代码
print(response.headers)
# 响应头:包含了服务器返回的元数据,例如内容类型 编码方式 时间等
print(response.content)
# 响应的原始字节数据print(response.text)
# 返回响应解码后的文本内容#response.json()
#尝试转为json格式'''
html 提供网页内容 超文本标签语言
css 设置内容的样式和布局
js 复杂页面的变化'''
例子1:下载百度的一个图片
import requestsresp = requests.get(url='https://www.baidu.com/img/flexible/logo/plus_logo_web_2.png')if resp.status_code == 200:with open('baidu_logo.png','wb') as file_obj:file_obj.write(resp.content)
else:print(resp.status_code)print('下载资源失败')
例子2: 下载全民k歌中的歌曲
import requests
r = requests.get(url='https://tx.stream.kg.qq.com/njc-kgsvp/njc_0_50111_1021_d4f824ebe3aaffb5547e47ef83f98ffc73818fad.f0.m4a?vkey=11FB169B35DA40E3E1D3B5E7C0F65A98B872A8DE4B3B8F11C2BD140CC8CAFFDFEBC046A4D9F867AD91BA0A36D3F30A9ECC0CD1B4DAC2ACB98D687ACD98D5A25648FCF46E54F5C9CDAA0FF082573630790AF61D33F038D244&dis_k=902041b3dac037587b8b0bf1188dbeb3&dis_t=1708249125&fromtag=1021&ugcid=251181046_1586058630_671&nr=1')if r.status_code == 200:
# 在pycharm中创建这个歌曲文件with open('song.m4a','wb') as song_k:
# 将歌曲内容写入创建的歌曲文件song_k.write(r.content)
else:print(r.status_code)print('失败')
7. 各种错误代码
'''
400 bad request 请求无法理解
401 unauthorized(未授权)
403 forbidden 禁止访问(理解请求但是拒绝你的请求)
404 not found 资源不存在
405 not allowed 服务器不允许
413 实体大小超出限制
418 I'm a teapot 你错了 ,牛头不对马嘴
'''8. 伪装爬取内容
因为豆瓣有些内容禁止爬取,但是未对百度禁止,可以伪装成百度,或者伪装成正常的网页进入两种方式
#伪装成百度进行爬取
import requests
r = requests.get(url='https://movie.douban.com/top250',headers={'User-Agent': 'Baiduspider'})
print(r.status_code)
print(r.text)# 伪装成正常网页, user-agent 后面的是网页检查中,network 中 header 最后面 user-agent中的内容
r = requests.get(url='https://movie.douban.com/top250',headers={'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36'})
print(r.status_code)
print(r.text)