【Langchain+Streamlit】旅游聊天机器人_langchain streamlit-CSDN博客
视频讲解地址:【Langchain Agent】带推销功能的旅游聊天机器人_哔哩哔哩_bilibili
体验地址: http://101.33.225.241:8503/
github地址:GitHub - jerry1900/langchain_chatbot: langchain+streamlit打造的一个有memory的旅游聊天机器人,可以和你聊旅游相关的事儿
之前,我们介绍如何打算一款简单的旅游聊天机器人,而且之前我们介绍了SalesGPT,我们看能不能把这两个东西结合起来,让我们的旅游聊天机器人具有推销产品的功能。我们先来看看效果:
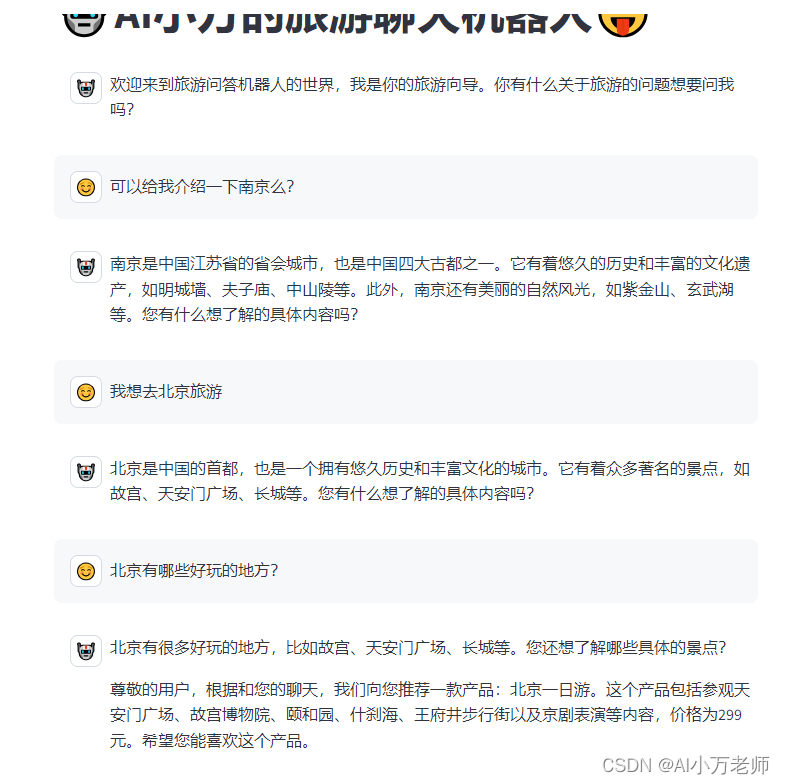
首先,你可以和机器人闲聊关于旅游的事儿(如果你问的问题和旅游无关的话,会提示你只回答旅游问题) ;其次,当你连续询问有关同一个地点时(比如北京),机器人会检查自己的本地知识库,看看产品库里有没有相关的旅游产品,如果有的话就推荐给客户,如果没有就输出一个空的字符串,用户是没有感知的,我们来看一下是如何实现的。
1. 项目结构
我们是在原来项目基础上逐步叠加的,主要增加了一个agent.py、my_tools.py、stages.py等文件。我们这次的项目是使用poetry来管理和运行的:
项目结构如图:
我们新加了一个产品文件用于存储旅游产品,下面是三个产品中的一个:
产品名称:北京一日游
产品价格:299元
产品内容:{
北京作为中国的首都和历史文化名城,有许多令人着迷的景点和活动。以下是一个充满活力和文化的北京一日游的建议:
早上:天安门广场: 开始您的一日游,您可以前往天安门广场,这是世界上最大的城市广场之一,也是中国的政治中心。您可以欣赏到天安门城楼,参观升国旗仪式(早上升旗时间)。
故宫博物院: 天安门广场北侧就是故宫,这是中国最大、最完整的古代皇家宫殿建筑群。在这里,您可以领略中国古代皇家建筑的壮丽和深厚的历史文化。
中午:午餐: 您可以选择在附近的餐馆品尝地道的北京菜,比如炸酱面、北京烤鸭等。
下午:颐和园: 中午过后,您可以前往颐和园,这是中国最大的皇家园林之一,也是清代的皇家园林。园内有美丽的湖泊、精致的建筑和独特的风景。
什刹海: 在下午的最后时段,您可以前往什刹海地区,这里是一个古老而又时尚的区域,有着许多酒吧、咖啡馆和特色小店。您可以漫步在湖边,欣赏夕阳下的美景,体验北京的悠闲氛围。
晚上:王府井步行街: 晚上,您可以前往王府井步行街,这是北京最繁华的购物街之一,有着各种商店、餐馆和娱乐场所。您可以尝试美食、购物或者观赏街头表演。
京剧表演: 如果时间允许,您还可以观看一场京剧表演,京剧是中国传统戏曲的代表之一,有着悠久的历史和独特的艺术魅力。
}
2. chat.py的改动,新增了欢迎词,添加了Agent构造的方法
这里构造一个专门负责提示词的Agent(其实就是一个LLMChain),并构造一个负责会话和判断功能的ConversationAgent,让这个agent初始化并构造一个负责判断阶段的内部agent,我们把他们都要放到session里:
#需要国内openai开发账号的请联系微信 15652965525if "welcome_word" not in st.session_state:st.session_state.welcome_word = welcome_agent()st.session_state.messages.append({'role': 'assistant', 'content': st.session_state.welcome_word['text']})st.session_state.agent = ConversationAgent()st.session_state.agent.seed_agent()st.session_state.agent.generate_stage_analyzer(verbose=True)在用户输入后的每一步,先进行一下阶段判断,然后调用agent的human_step方法,再调用agent的step()方法,完成一轮对话:
st.session_state.agent.determine_conversation_stage(prompt)st.session_state.agent.human_step(prompt)response = st.session_state.agent.step()
3. welcome_agent
这个比较简单,就是一个咱们学习过无数遍的一个简单的chain:
def welcome_agent():llm = OpenAI(temperature=0.6,# openai_api_key=os.getenv("OPENAI_API_KEY"),openai_api_key=st.secrets['api']['key'],# base_url=os.getenv("OPENAI_BASE_URL")base_url=st.secrets['api']['base_url'])prompt = PromptTemplate.from_template(WELCOME_TEMPLATE)chain = LLMChain(llm=llm,prompt=prompt,verbose=True,)response = chain.invoke("简短的欢迎词")return response这里我们希望每次调用它的时候,可以得到一些不一样的、有创意的欢迎词,所以我们的temperature调的比较高,这样它可能生成一些有创意的欢迎词。
4. ConversationAgent类
这个类是我们的核心类,里面有很多属性和方法,我们用python的dir()方法来看一下它里面的结构:
from agent import ConversationAgentagent = ConversationAgent()
print(dir(ConversationAgent))里面以_开头的是Object基本类自带的属性和方法,其他的是我们构造的属性和方法:
['__annotations__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_respond_without_tools', 'conversation_agent_with_tool', 'conversation_agent_without_tool', 'conversation_history', 'conversation_stage_id', 'current_conversation_stage', 'determine_conversation_stage', 'fake_step', 'generate_stage_analyzer', 'get_tools', 'human_step', 'llm', 'recommend_product', 'retrieve_conversation_stage', 'seed_agent', 'show_chat_history', 'stage_analyzer_chain', 'step']
我们先来看类的属性和一些简单的方法,注意我们这里构造了一个llm,之后下面有很多方法会用到这个llm:
class ConversationAgent():stage_analyzer_chain: StageAnalyzerChain = Field(...)conversation_agent_without_tool = Field()conversation_agent_with_tool = Field()conversation_history = []conversation_stage_id: str = "1"current_conversation_stage: str = CONVERSATION_STAGES.get("1")llm = OpenAI(temperature=0,openai_api_key=st.secrets['api']['key'],base_url=st.secrets['api']['base_url'])def seed_agent(self):self.conversation_history.clear()print("——Seed Successful——")def show_chat_history(self):return self.conversation_historydef retrieve_conversation_stage(self, key):return CONVERSATION_STAGES.get(key)我们继续来看:
def fake_step(self):input_text = self.conversation_history[-1]ai_message = self._respond_with_tools(str(input_text), verbose=True)print(ai_message,type(ai_message['output']))def step(self):input_text = self.conversation_history[-1]print(str(input_text)+'input_text****')if int(self.conversation_stage_id) == 1:ai_message = self._respond_without_tools(str(input_text),verbose=True)else:chat_message = self._respond_without_tools(str(input_text), verbose=True)recommend_message = self.recommend_product()print(recommend_message,len(recommend_message))if len(recommend_message)<=5:ai_message = chat_messageelse:ai_message = chat_message + '\n\n' + recommend_message# output_dic = self._respond_with_tools(str(input_text),verbose=True)# ai_message = str(output_dic['output'])print(ai_message,type(ai_message))ai_message = "AI:"+str(ai_message)self.conversation_history.append(ai_message)# print(f"——系统返回消息'{ai_message}',并添加到history里——")return ai_message.lstrip('AI:')
fake_step是一个模拟输出的方法,不用管,测试的时候用;step方法是接收用户的输入,从聊天记录里取出来(input_text = self.conversation_history[-1]) ,然后再根据不同的对话阶段进行不同的逻辑,如果是第二个阶段推销阶段,那么就调用recommend_product方法去生成一个推销产品的信息,并把两条信息拼接起来。
def human_step(self,input_text):human_message = input_texthuman_message = "用户: " + human_messageself.conversation_history.append(human_message)# print(f"——用户输入消息'{human_message}',并添加到history里——")return human_message
human_step方法比较简单,就是把用户的输入挂到conversation_history聊天记录里。然后是构造阶段判断的agent和阶段判断的方法,这些都是模仿SalesGPT里的,做了一些调整:
def generate_stage_analyzer(self,verbose: bool = False):self.stage_analyzer_chain = StageAnalyzerChain.from_llm(llm=self.llm,verbose=verbose)print("成功构造一个StageAnalyzerChain")def determine_conversation_stage(self,question):self.question = questionprint('-----进入阶段判断方法-----')self.conversation_stage_id = self.stage_analyzer_chain.run(conversation_history=self.conversation_history,question=self.question)print(f"Conversation Stage ID: {self.conversation_stage_id}")print(type(self.conversation_stage_id))self.current_conversation_stage = self.retrieve_conversation_stage(self.conversation_stage_id)print(f"Conversation Stage: {self.current_conversation_stage}")
然后是_respond_without_tools这么一个内部的方法,它在step里被调用:
def _respond_without_tools(self,input_text,verbose: bool = False):self.conversation_agent_without_tool = ConversationChain_Without_Tool.from_llm(llm=self.llm,verbose=verbose)response = self.conversation_agent_without_tool.run(question = input_text,conversation_history=self.conversation_history,)return response最后是get_tools方法和recommend_product方法,这里也都是模仿了SalesGPT里的写法:
def get_tools(self):file_path = r'C:\Users\Administrator\langchain_chatbot\product.txt'knowledge_base = build_knowledge_base(file_path)tools = get_tools(knowledge_base)return toolsdef recommend_product(self,verbose =True):tools = self.get_tools()prompt = CustomPromptTemplateForTools(template=RECOMMEND_TEMPLATE,tools_getter=lambda x: tools,# This omits the `agent_scratchpad`, `tools`, and `tool_names` variables because those are generated dynamically# This includes the `intermediate_steps` variable because that is neededinput_variables=["intermediate_steps", # 这是在调用tools时,会产生的中间变量,是一个list里面的一个tuple,一个是action,一个是observation"conversation_history",],)llm_chain = LLMChain(llm=self.llm, prompt=prompt, verbose=verbose)tool_names = [tool.name for tool in tools]# WARNING: this output parser is NOT reliable yet## It makes assumptions about output from LLM which can break and throw an erroroutput_parser = SalesConvoOutputParser()recommend_agent = LLMSingleActionAgent(llm_chain=llm_chain,output_parser=output_parser,stop=["\nObservation:"],allowed_tools=tool_names,)sales_agent_executor = AgentExecutor.from_agent_and_tools(agent=recommend_agent, tools=tools, verbose=verbose, max_iterations=5)inputs = {"conversation_history": "\n".join(self.conversation_history),}response = sales_agent_executor.invoke(inputs)return str(response['output'])
5. chain.py
chain这里有三个类,差异在于使用模板的不同还有部分传参的不同,这里写的有点冗余了,大家可以自己优化一下:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from template import STAGE_ANALYZER_INCEPTION_PROMPT,BASIC_TEMPLATE,RECOMMEND_TEMPLATEclass StageAnalyzerChain(LLMChain):"""通过查看聊天记录判断是否要转向推荐和销售阶段."""@classmethoddef from_llm(cls, llm, verbose: bool = True) -> LLMChain:"""Get the response parser."""stage_analyzer_inception_prompt_template = STAGE_ANALYZER_INCEPTION_PROMPTprompt = PromptTemplate(template=stage_analyzer_inception_prompt_template,input_variables=["conversation_history","question"],)return cls(prompt=prompt, llm=llm, verbose=verbose)class ConversationChain_Without_Tool(LLMChain):#当用户没有明确的感兴趣话题时,用这个chain和用户闲聊@classmethoddef from_llm(cls, llm, verbose: bool = True) -> LLMChain:"""Get the response parser."""conversation_without_tools_template = BASIC_TEMPLATEprompt = PromptTemplate(template=conversation_without_tools_template,input_variables=["conversation_history",],)return cls(prompt=prompt, llm=llm, verbose=verbose)class Recommend_Product(LLMChain):#当用户有明确的感兴趣话题时,用这个chain查询产品库,看是否命中,如果命中则生成一个产品推荐信息@classmethoddef from_llm(cls, llm, verbose: bool = True) -> LLMChain:"""Get the response parser."""conversation_without_tools_template = RECOMMEND_TEMPLATEprompt = PromptTemplate(template=conversation_without_tools_template,input_variables=["conversation_history",],)return cls(prompt=prompt, llm=llm, verbose=verbose)6. my_tools.py
这个文件里有有很多,是我把SalesGPT里的一些文件改写拿过来用的,有一些根据实际项目需要进行的微调:
import re
from typing import Unionfrom langchain.agents import Tool
from langchain.chains import RetrievalQA
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from typing import Callable
from langchain.prompts.base import StringPromptTemplate
from langchain.agents.agent import AgentOutputParser
from langchain.agents.conversational.prompt import FORMAT_INSTRUCTIONS
from langchain.schema import AgentAction, AgentFinish # OutputParserExceptiondef build_knowledge_base(filepath):with open(filepath, "r", encoding='utf-8') as f:product_catalog = f.read()text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=10)texts = text_splitter.split_text(product_catalog)llm = ChatOpenAI(temperature=0)embeddings = OpenAIEmbeddings()docsearch = Chroma.from_texts(texts, embeddings, collection_name="product-knowledge-base")knowledge_base = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever())return knowledge_basedef get_tools(knowledge_base):# we only use one tool for now, but this is highly extensible!tools = [Tool(name="ProductSearch",func=knowledge_base.invoke,description="查询产品库,输入应该是'请介绍一下**的旅游产品'",)]print('tools构造正常')return toolsclass CustomPromptTemplateForTools(StringPromptTemplate):# The template to usetemplate: strtools_getter: Callabledef format(self, **kwargs) -> str:# Get the intermediate steps (AgentAction, Observation tuples)# Format them in a particular wayintermediate_steps = kwargs.pop("intermediate_steps")thoughts = ""for action, observation in intermediate_steps:thoughts += action.logthoughts += f"\nObservation: {observation}\nThought: "# Set the agent_scratchpad variable to that valueprint('——thoughts——:'+thoughts+'\n End of ——thoughts——')kwargs["agent_scratchpad"] = thoughtstools = self.tools_getter([])# Create a tools variable from the list of tools providedkwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in tools])# Create a list of tool names for the tools providedkwargs["tool_names"] = ", ".join([tool.name for tool in tools])print('prompt构造正常')return self.template.format(**kwargs)class SalesConvoOutputParser(AgentOutputParser):ai_prefix: str = "AI" # change for salesperson_nameverbose: bool = Truedef get_format_instructions(self) -> str:return FORMAT_INSTRUCTIONSdef parse(self, text: str) -> Union[AgentAction, AgentFinish]:if self.verbose:print("TEXT")print(text)print("-------")if f"{self.ai_prefix}:" in text:if "Do I get the answer?YES." in text:print('判断Agent是否查到结果,yes')return AgentFinish({"output": text.split(f"{self.ai_prefix}:")[-1].strip()}, text)else:print('判断Agent是否查到结果,no')return AgentFinish({"output": {}}, text)regex = r"Action: (.*?)[\n]*Action Input: (.*)"match = re.search(regex, text)if not match:## TODO - this is not entirely reliable, sometimes results in an error.return AgentFinish({"output": "I apologize, I was unable to find the answer to your question. Is there anything else I can help with?"},text,)# raise OutputParserException(f"Could not parse LLM output: `{text}`")action = match.group(1)action_input = match.group(2)print('output_paserser构造正常')return AgentAction(action.strip(), action_input.strip(" ").strip('"'), text)@propertydef _type(self) -> str:return "sales-agent"7. 结束语
整个项目就是把之前的两个项目进行了一个组合拼装,在这个过程中可以更好地理解Sales
GPT这个项目,以及多Agent是怎么运行的。